Sentí que todo saldría bien para mí y emprendí un viaje por el mundo de Linux. En ese número de #IBelieveinDoing, había tutoriales no solo sobre Linux, sino también sobre Git. Se pueden establecer algunos paralelismos entre estos sistemas. Linux es un sistema operativo de código abierto utilizado por los programadores, y Git es un sistema de control de versiones que se utiliza para realizar un seguimiento de los cambios en el código fuente al desarrollar programas. Cabe señalar que aprender Linux y Git resultó ser una experiencia muy emocionante. Pero Git es un sistema bastante complejo, por lo que los conceptos básicos fueron más difíciles de dominar que los conceptos básicos de Linux. En este artículo, quiero compartir con ustedes lo que aprendí mientras dominaba Linux y Git.

Comandos básicos de Linux
pwd: Este comando se utiliza para mostrar información sobre el directorio de trabajo.
ls: Con este comando puede mostrar información sobre el contenido de un directorio. Si se ejecuta de esta forma, sin argumentos de línea de comando, proporciona información en el formato predeterminado.
cd: este comando es para cambiar de directorio.
Experimentar con comandos de Linux
cp : este comando sirve para copiar archivos y carpetas.
mv: Con este comando, puede cambiar el nombre o mover archivos y carpetas.
touch: Este comando se utiliza para crear archivos vacíos y cambiar la marca de tiempo de los archivos.
cat: este comando le permite ver el contenido de los archivos, con su ayuda puede crear copias de archivos, adjuntar el contenido de unos archivos a otros.
tree: Este comando le permite mostrar la información del directorio en un formato de árbol. El comando, de forma predeterminada, muestra información sobre carpetas y archivos e información sobre la cantidad de archivos y carpetas en su estructura de salida. Aquí hay un ejemplo de su uso.
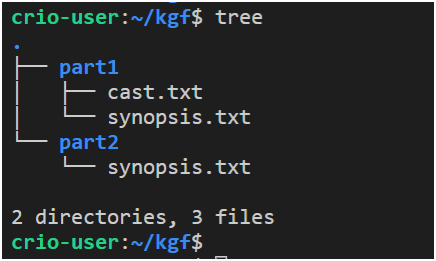
Ejemplo de uso del comando de árbol
Aquí los nombres de las carpetas están resaltados en azul, los nombres de los archivos son blancos. Se utilizan otros colores en las estructuras mostradas por este comando.
echo: Este comando se utiliza para mostrar los datos que se le pasan en la pantalla.
grep: Este comando es para trabajar con datos de texto. En particular, le permite buscar cadenas.
tail: Este comando imprime las últimas 10 líneas de un archivo.
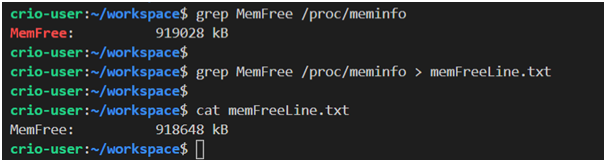
Ejemplos de uso de comandos grep y cat
awk : este comando está destinado a funcionar con la utilidad correspondiente, lo que nos brinda herramientas poderosas para procesar cadenas, cuyas capacidades son comparables a las disponibles en lenguajes de programación completos.
En Linux, puede utilizar canalizaciones, que son canalizaciones unidireccionales que puede utilizar para comunicarse entre procesos. Al describir tuberías,
|se usael símbolo (). Con este símbolo, puede, por ejemplo, enrutar la salida de un comando a la entrada de otro.

Un ejemplo de uso de la canalización
ssh : este comando le permite trabajar con un cliente ssh, que se usa para conectarse a sistemas remotos y ejecutar comandos en ellos. El protocolo SSH tiene como objetivo organizar la interacción segura de las computadoras.
rm: Este comando se utiliza para eliminar archivos y carpetas. Por ejemplo, llamarlo en el formulariorm fileconduce a la eliminación del archivo, y en el formulariorm -r directory, a la eliminación del directorio y todo su contenido.
Estructura de directorios de Linux
Linux usa una estructura de directorios en forma de árbol. El comienzo de esta estructura jerárquica está en el directorio raíz. Todos los demás directorios están anidados en este directorio. La barra inclinada (
/) se utiliza para separar los nombres de los directorios al especificar rutas a archivos y carpetas .
Así es como podría verse la estructura del sistema de archivos en un sistema Linux.
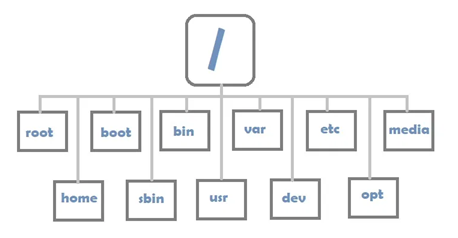
Estructura de directorios en Linux
Estas son las características de algunas carpetas importantes.
| Ruta de directorio | Notas |
|
Directorio raíz. |
|
El directorio donde se almacenan los materiales del usuario. |
|
Aquí es donde se almacenan los archivos necesarios para ejecutar Linux. |
|
Los ejecutables se encuentran aquí. |
|
Contiene varios archivos utilizados por el sistema y los programas instalados. Estos pueden ser archivos de registro, bases de datos, contenido de páginas web en caché. |
Direccionamiento absoluto y relativo
Las rutas de archivo absolutas siempre contienen la ruta completa desde el directorio raíz hasta los directorios que contienen los archivos necesarios.
Las rutas relativas son relativas al directorio actual.
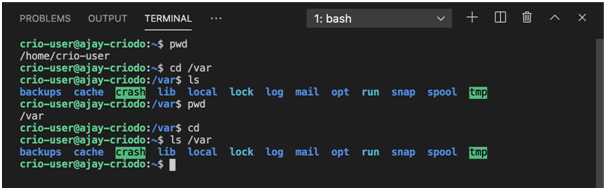
Experimentar con rutas
Hay rutas relativas especiales, que se describen en la siguiente tabla.
| Camino relativo | Descripción | Ejemplo | Notas de ejemplo |
|
Directorio de trabajo actual. | |
Muestra información sobre el contenido del directorio actual. |
|
Directorio de padres. | |
Sube un nivel hasta el directorio principal. |
|
Directorio de trabajo anterior. | |
Regrese al directorio de trabajo anterior. |
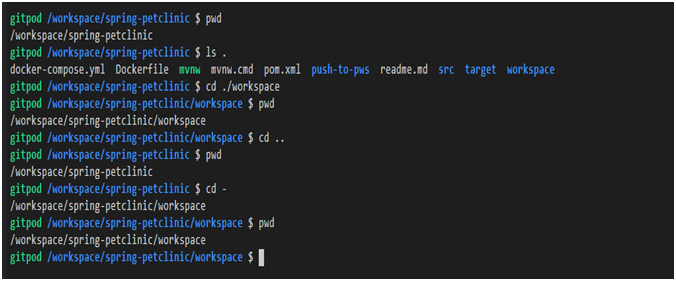
Ejemplos de uso de rutas relativas especiales
Vínculos blandos y duros a archivos
Un enlace de archivo suave (simbólico) contiene un puntero al nombre del archivo. Estos enlaces se asemejan a accesos directos que se utilizan para acceder rápidamente a un archivo desde diferentes directorios. Si se elimina un archivo que tiene un enlace flexible, el enlace permanece, pero deja de funcionar.
Un vínculo físico es un vínculo a la ubicación en el disco duro donde se encuentra el archivo. El sistema considera que el archivo existe siempre que haya al menos un enlace fijo al mismo. De hecho, si un archivo tiene varios vínculos físicos, se puede comparar con un archivo que tenga varios nombres.
El comando se utiliza para crear vínculos físicos y blandos a archivos
ln. Aquí hay un ejemplo de cómo crear un vínculo simbólico con él:
ln -s /path/to/file linkname
Control de comportamiento de comando
El comportamiento de los comandos de Linux se puede controlar pasándoles argumentos de línea de comando (conmutadores, opciones, banderas) cuando se invocan. Por lo general, se ven como un guión (
-) seguido de un nombre de clave de una letra (por ejemplo, tal construcción podría verse así -a). También pueden verse como dos guiones ( --) seguidos de un nombre de clave más largo (más o menos --all).
Para obtener más información sobre los comandos de Linux, puede utilizar el sistema de ayuda integrado, al que se accede a través del comando
man. Por ejemplo, lspuede utilizar el comando para obtener ayuda sobre un comando man ls. A continuación se muestra el resultado de dicho comando.
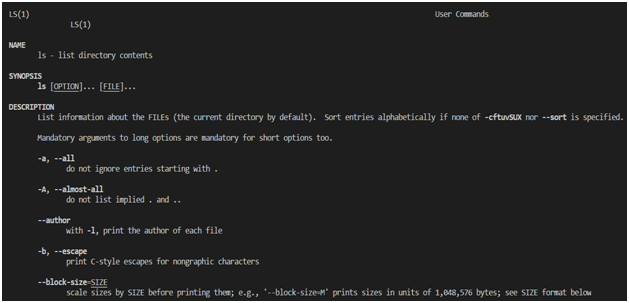
Ls Command
Reference Las páginas de referencia de comandos se dividen en varias secciones. Entre ellos se encuentran los siguientes:
NAME(nombre). Contiene el nombre del comando y una breve descripción de lo que hace.SYNOPSIS(resumen de sintaxis de comandos). Aquí hay un diagrama de cómo usar el comando.DESCRIPTION(descripción). Esta sección proporciona una descripción detallada del comando y los modificadores de línea de comando que admite.
Por ejemplo, el comando se
lsusa a menudo con una opción -lque le permite mostrar detalles sobre el contenido de un directorio.
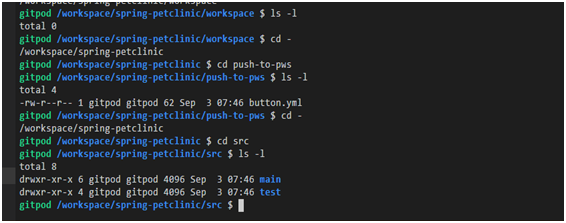
Usando el comando ls -l
En la imagen anterior, es posible que haya notado las construcciones de la vista
drwxr-xr-x. Esta es una descripción de los permisos de archivos.
Permisos de archivo
Supongamos que tenemos la siguiente construcción que describe los permisos de archivo:
- rwx r-- r--
Tenga en cuenta que en él se pueden distinguir cuatro grupos de símbolos:
- El primer símbolo indica exactamente con qué estamos tratando. Es decir, si hay un signo (
-) aquí , entonces tenemos un archivo frente a nosotros. La letra (d) indica un directorio. La letra (l) es para un enlace. - Los siguientes tres símbolos le permiten saber qué permisos tiene su propietario para trabajar con un archivo determinado:
r- leer,w- escribir,x- ejecutar. El conjunto completo de permisos está representado por una secuenciarwx, si un determinado permiso está ausente, se coloca un símbolo (-) en la posición correspondiente . - , ( , ). , .
- , , , , .
El comando se usa para administrar los permisos de archivos
chmod. Por ejemplo, para añadir a las reglas actuales de acceso al permiso de archivo para que se ejecute, puede utilizar el siguiente esquema se llama: chmod +x <filename>. El diseño +xindica que este permiso se agrega para todos los usuarios.
Hablemos de algunos de los aspectos específicos de la configuración de permisos de archivos mediante
chmod. Entonces, para asignar un determinado permiso a todos los usuarios, se utilizan construcciones similares a la descrita anteriormente +x. El operador ( +) se usa para agregar permisos, el operador ( -) le permite eliminar permisos, el operador ( =) se usa para establecer ciertos derechos para el usuario propietario del archivo ( u, usuario), para el grupo (g, grupo), para otros usuarios ( o, otros) y para todos los usuarios ( a, todos). Esto se hace en construcciones de vista chmod u=rwx,g=rx,o=rx filename.
Al asignar permisos, a menudo se escriben en forma numérica. Los códigos octales corresponden a ciertos derechos. Así, el
xcódigo correspondiente 1, wel código apropiado 2y rel código correspondiente 4. El código0corresponde a la ausencia total de permisos para trabajar con el archivo. Los permisos de archivos se describen mediante un número de tres dígitos, el orden de los números en el que corresponde al orden descrito anteriormente de los grupos de permisos. Es decir, el primer número describe los permisos del propietario del archivo, el segundo describe los permisos del grupo y el tercero describe los permisos de otros usuarios. Cada uno de estos números es la suma de los códigos de autorización r, wy x.
Por ejemplo, un comando del formulario
chmod 444 filenamesignifica que todos solo tendrán derecho a leer el archivo ( r--r--r--), y un comando del formulario chmod 700 filenameindica que el propietario tendrá derecho a leer, escribir y ejecutar el archivo ( rwx, 4+2+1), y nadie más tiene derecho a realizar ninguna acción con el archivo. ( rwx------).
Trabajando con Git
Cuando se trabaja con Git, generalmente se usa la siguiente secuencia de acciones:
- Modificar un archivo en el directorio de trabajo local.
- Indexación de archivos (comando
git add). - Guardar una instantánea de los datos indexados en la base de datos interna (
git commit). - Envío de cambios del repositorio local al remoto (
git push). - Cargando cambios de un repositorio remoto a uno local (
git pull).
Aquí hay un diagrama que ilustra esta secuencia de pasos.
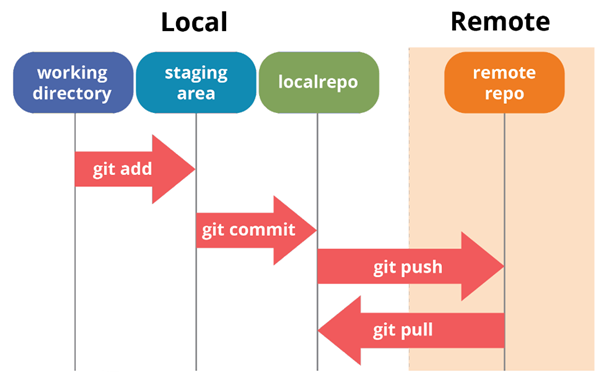
Los
archivos de flujo de trabajo de Git típicos pueden estar en diferentes estados cuando se trabaja con Git.
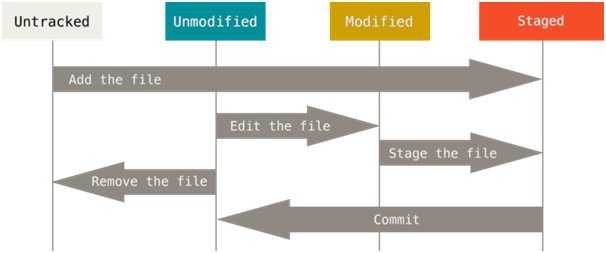
Estados de archivo
- Untracked es un archivo que Git no busca cambios. Este archivo se puede agregar al índice y estar en estado Preparado.
- Sin modificar: un archivo que se ha supervisado, pero cuyo contenido no ha cambiado. Si elimina este archivo, ya no se supervisará. Si lo cambia, pasará al estado Modificado.
- Modificado: el archivo que se está viendo, cuyo contenido ha cambiado. Se puede indexar y poner en estado por etapas.
- En etapas es el archivo que se supervisa e incluye en el índice. Los cambios correspondientes se pueden incorporar a la base de datos de Git.
Veamos algunos de los comandos de Git.
git init: Este comando crea un repositorio Git vacío en el directorio. Este es el primer paso para crear un nuevo repositorio. Después de ejecutar este comando, puede usar los comandos git addy git commit.

git addComando Git init : este comando agrega archivos al índice. Admite, en el formulariogit add ., agregar todos los archivos no indexados al índice, en el formulariogit add filename: agregar un archivo específico al índice, en el formulariogit add dirname: agregar un directorio al índice.

git commitComando Git add : este comando escribe cambios en el repositorio local. Estos cambios se denominan, por analogía con el nombre del comando, "confirmaciones". Cada confirmación tiene un identificador único, lo que facilita el trabajo con las confirmaciones.

git statusComando de confirmación de Git : este comando le permite obtener información sobre el estado actual del repositorio.
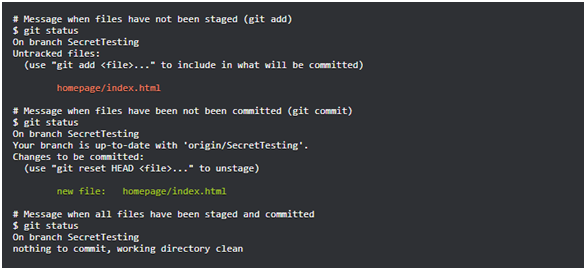
git configComando de estado de Git : este comando le permite personalizar Git. Entre las configuraciones se pueden señalar Gituser.nameyuser.email. Contienen el nombre del usuario y la dirección de correo electrónico utilizados en las confirmaciones e indican quién las realizó. Sise usaunagit configbanderaal llamar al comando, la--globalconfiguración se aplica a todos los repositorios locales. Sin esta marca, la configuración se aplica solo al repositorio actual.

git checkoutComando de configuración de Git : este comando se usa para cambiar entre las ramas del repositorio (comogit checkout <branch_name>). Con su ayuda, puede crear una nueva rama y cambiar a ella (git checkout -b <new_branch>).
git merge: Este comando le permite fusionar las ramas del repositorio. Toma los cambios en una rama y los fusiona en la otra rama. Por ejemplo, hay una rama que está trabajando en una nueva función de proyecto. Una vez que se completa esta función, los cambios se envían a la sucursal que almacena las funciones estables.
git clone: Este comando se usa para crear una copia de trabajo local de un repositorio remoto. Cuando se ejecuta, los materiales del repositorio remoto se descargan a la computadora. La clonación de un repositorio existente es comparable a la creación de un nuevo repositorio con el comandogit init... Pero a la hora de clonar, tenemos un repositorio a nuestra disposición, en el que ya hay algo, y cuando git initse ejecuta el comando , un repositorio vacío.
git pull: Este comando es para descargar datos nuevos desde un repositorio remoto.
git push: Este comando se puede utilizar para enviar confirmaciones locales al repositorio remoto. Al llamar a este comando, debe pasarle información sobre el repositorio remoto y sobre la rama del repositorio local, que debe enviarse al repositorio remoto.
Salir
Les conté todo lo que aprendí durante mi viaje al mundo de Linux y Git. Fue muy emocionante. Con suerte, querrás hacer algo similar y aprender algo nuevo, algo que amplíe tus horizontes profesionales.
Si ha dominado algo interesante recientemente, cuéntenoslo.

