Pero, ¿qué pasa si comienza a usar algún producto que no sea de SAP y preferiblemente de código abierto como almacenamiento? En X5 Retail Group elegimos GreenPlum. Esto, por supuesto, resuelve el problema de los costos, pero al mismo tiempo, surgen preguntas de inmediato que, al usar SAP BW, se resolvieron casi por defecto.

En particular, ¿cómo recuperar datos de los sistemas de origen, que en su mayoría son soluciones de SAP?
HR Metrics fue el primer proyecto en abordar este problema. Nuestro objetivo era crear un almacén de datos de RR.HH. y generar informes analíticos en el área de trabajo con los empleados. En este caso, la principal fuente de datos es el sistema transaccional SAP HCM, en el que se llevan a cabo todas las actividades de personal, organizativas y salariales.
Extracción de datos
Hay extractores de datos estándar en SAP BW para sistemas SAP. Estos extractores pueden recopilar automáticamente los datos necesarios, realizar un seguimiento de su integridad y determinar los deltas de los cambios. Por ejemplo, aquí hay una fuente de datos estándar para atributos de empleado 0EMPLOYEE_ATTR:

Resultado de la extracción de datos de un empleado a la vez:
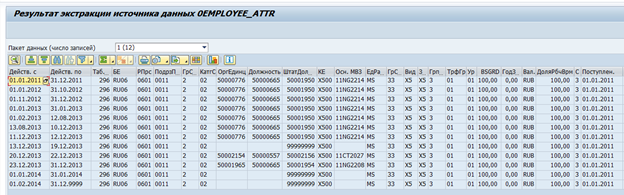
si es necesario, dicho extractor se puede modificar para adaptarlo a sus propios requisitos, o se puede crear su propio extractor.
La primera idea surgió sobre la posibilidad de su reutilización. Desafortunadamente, esto resultó ser una tarea imposible. La mayor parte de la lógica se implementa en el lado de SAP BW, y no fue posible separar sin problemas el extractor en la fuente de SAP BW.
Resultó obvio que sería necesario desarrollar un mecanismo personalizado para extraer datos de los sistemas SAP.
Estructura de almacenamiento de datos en SAP HCM
Para comprender los requisitos de dicho mecanismo, primero debe determinar qué tipo de datos necesitamos.
La mayoría de los datos de SAP HCM se almacenan en tablas SQL planas. Con base en estos datos, las aplicaciones de SAP visualizan las estructuras organizativas, los empleados y otra información de recursos humanos para el usuario. Por ejemplo, así es como se ve una estructura organizativa en SAP HCM:
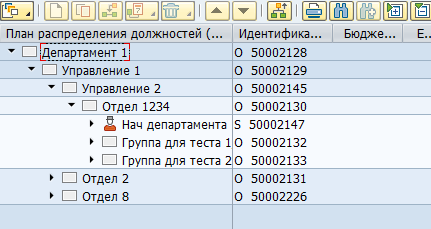
Físicamente, dicho árbol se almacena en dos tablas: en los objetos hrp1000 y en hrp1001 los enlaces entre estos objetos.
Objetos "Departamento 1" y "Oficina 1":

Comunicación entre objetos:

Puede haber una gran cantidad de ambos tipos de objetos y tipos de comunicación entre ellos. Hay enlaces estándar entre objetos y personalizados para sus propias necesidades específicas. Por ejemplo, la relación estándar B012 entre una unidad organizativa y un puesto de tiempo completo indica el jefe del departamento.
Mapeo del administrador en SAP:
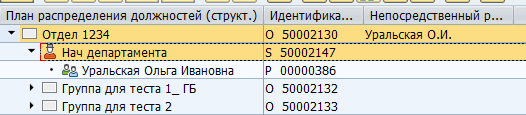
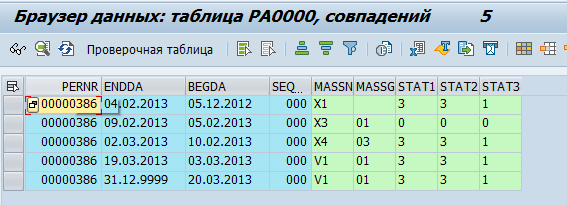
Almacenamiento en la tabla de base de

datos : Los datos de los empleados se almacenan en tablas pa *. Por ejemplo, los datos sobre las actividades de personal de un empleado se almacenan en la tabla pa0000.
Hemos decidido que GreenPlum tomará datos "sin procesar", es decir, simplemente cópielos de las tablas de SAP. Y ya directamente en GreenPlum, se procesarán y convertirán en objetos físicos (por ejemplo, Departamento o Empleado) y métricas (por ejemplo, plantilla promedio).
Se definieron alrededor de 70 tablas, cuyos datos deben transferirse a GreenPlum. Después de eso, comenzamos a encontrar una forma de transferir estos datos.
SAP ofrece una gran cantidad de mecanismos de integración. Pero la forma más fácil: el acceso directo a la base de datos está prohibido debido a restricciones de licencia. Por tanto, todos los flujos de integración deben implementarse en el nivel del servidor de aplicaciones.
El siguiente problema fue la falta de datos sobre los registros eliminados en la base de datos de SAP. Cuando se elimina una fila de la base de datos, se elimina físicamente. Aquellos. la formación de un delta de cambios durante el tiempo de cambio no fue posible.
Por supuesto, SAP HCM tiene mecanismos para confirmar cambios de datos. Por ejemplo, para la transmisión posterior a los sistemas, los destinatarios tienen punteros de cambio que registran cualquier cambio y sobre la base de los cuales se forma un Idoc (un objeto para la transmisión a sistemas externos).
Ejemplo de un IDOC para cambiar el infotipo 0302 para el empleado con número de personal 1251445:
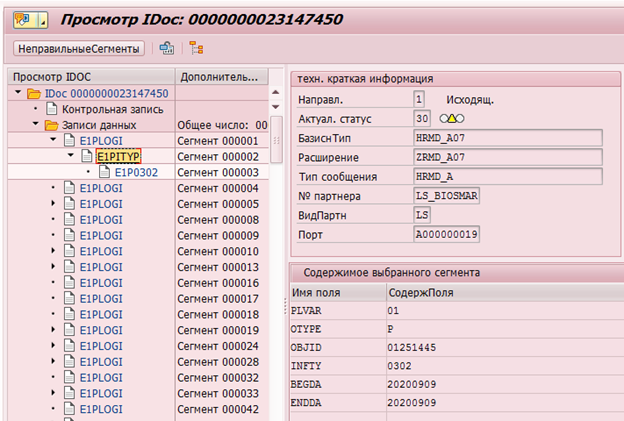
o actualizar registros de cambios de datos en la tabla DBTABLOG.
Un ejemplo de un registro para eliminar una entrada con la clave QK53216375 de la tabla hrp1000:

pero estos mecanismos no están disponibles para todos los datos necesarios y su procesamiento a nivel del servidor de aplicaciones puede consumir muchos recursos. Por lo tanto, la inclusión masiva del registro en todas las tablas necesarias puede conducir a una degradación notable del rendimiento del sistema.
Las tablas agrupadas fueron el siguiente gran problema. La estimación de tiempo y los datos de nómina en la versión RDBMS de SAP HCM se almacenan como un conjunto de tablas lógicas por empleado por nómina. Estas tablas lógicas se almacenan como datos binarios en la tabla pcl2.
Clúster de nómina: los
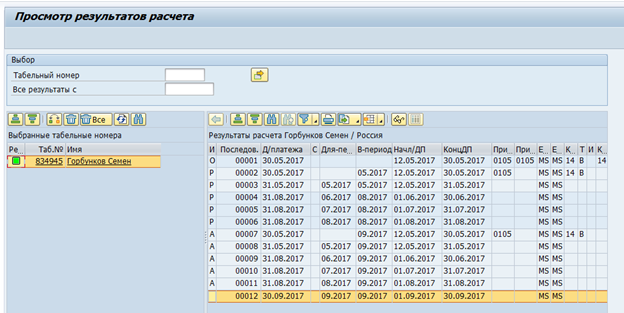
datos de las tablas agrupadas no se pueden leer mediante un comando SQL y requieren el uso de macros de SAP HCM o módulos de funciones especiales. En consecuencia, la velocidad de lectura de tales tablas será bastante baja. Por otro lado, estos grupos almacenan datos que solo se necesitan una vez al mes: la nómina final y la estimación de tiempo. Entonces, la velocidad en este caso no es tan crítica.
Al evaluar las opciones con la formación de un delta de cambio de datos, decidimos considerar también la opción con descarga completa. La opción de transferir gigabytes de datos sin cambios entre sistemas todos los días no puede parecer bonita. Sin embargo, también tiene una serie de ventajas: no hay necesidad de implementar el delta en el lado de la fuente ni de implementar la incrustación de este delta en el lado del receptor. En consecuencia, se reducen el costo y el tiempo de implementación y se aumenta la confiabilidad de la integración. Al mismo tiempo, se determinó que casi todos los cambios en SAP HR ocurren en el horizonte de tres meses antes de la fecha actual. Por lo tanto, se decidió detenerse en una descarga completa diaria de datos de SAP HR N meses antes de la fecha actual y en una descarga completa mensual. El parámetro N depende de la tabla específica
y va de 1 a 15.
Para la extracción de datos, se propuso el siguiente esquema:

El sistema externo genera una solicitud y la envía a SAP HCM, donde se verifica esta solicitud para verificar la integridad de los datos y la autorización para acceder a las tablas. Si la verificación es exitosa, SAP HCM ejecuta un programa que recopila los datos necesarios y los transfiere a la solución de integración Fuse. Fuse define el tema requerido en Kafka y pasa los datos allí. A continuación, los datos de Kafka se transfieren al Stage Area GP.
En esta cadena, nos interesa el tema de la extracción de datos de SAP HCM. Detengámonos en ello con más detalle.
Diagrama de interacción SAP HCM-FUSE.
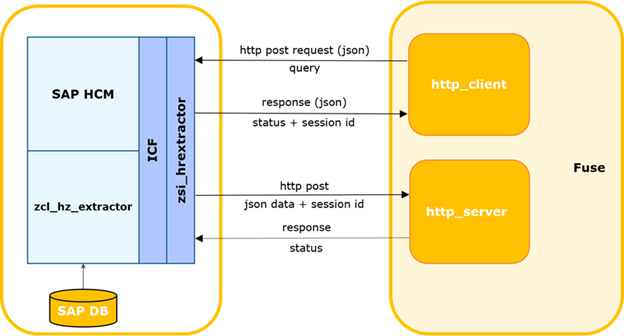
El sistema externo determina la hora de la última solicitud exitosa a SAP.
El proceso puede iniciarse mediante un temporizador u otro evento, incluido un tiempo de espera para esperar una respuesta con datos de SAP y el inicio de una solicitud repetida. Luego genera una solicitud delta y la envía a SAP.
Los datos de la solicitud se pasan al cuerpo en formato json.
El método http: POST.
Solicitud de muestra:

el servicio de SAP verifica que la solicitud esté completa, que cumpla con la estructura actual de SAP y que esté disponible el permiso para acceder a la tabla solicitada.
En caso de errores, el servicio devuelve una respuesta con el código y la descripción correspondientes. Si el control tiene éxito, crea un proceso en segundo plano para generar una selección, genera y devuelve sincrónicamente una identificación de sesión única.
El sistema externo lo registrará en caso de error. En caso de una respuesta exitosa, transmite el ID de sesión y el nombre de la tabla para la que se realizó la solicitud.
El sistema externo registra la sesión actual como abierta. Si hay otras sesiones para esta tabla, se cierran con una advertencia registrada.
El trabajo en segundo plano de SAP genera un cursor de acuerdo con los parámetros especificados y un paquete de datos del tamaño especificado. Tamaño del paquete: el número máximo de registros que el proceso lee de la base de datos. Por defecto, se asume que es 2000. Si hay más registros en la muestra de la base de datos que el tamaño del paquete usado, después de que se transmite el primer paquete, el siguiente bloque se forma con el desplazamiento correspondiente y el número de paquete incrementado. Los números se incrementan en 1 y se envían estrictamente secuencialmente.
A continuación, SAP pasa el paquete como entrada al servicio web del sistema externo. Y es el sistema el que controla el paquete entrante. Una sesión con la identificación recibida debe estar registrada en el sistema y debe estar en estado abierto. Si el número de paquete es> 1, el sistema debe registrar la recepción exitosa del paquete anterior (package_id-1).
En caso de un control exitoso, el sistema externo analiza y guarda los datos de la tabla.
Además, si el indicador final está presente en el paquete y la serialización fue exitosa, se notifica al módulo de integración sobre la finalización exitosa del procesamiento de la sesión y el módulo actualiza el estado de la sesión.
En caso de un error de control / análisis, el error se registra y los paquetes de esta sesión serán rechazados por el sistema externo.
Asimismo, en el caso contrario, cuando el sistema externo devuelve un error, se registra y se detiene la transmisión de paquetes.
Se implementó un servicio de integración para solicitar datos en el lado de SAP HM. El servicio se implementa en el marco ICF (SAP Internet Communication Framework - help.sap.com/viewer/6da7259a6c4b1014b7d5e759cc76fd22/7.01.22/en-US/488d6e0ea6ed72d5e10000000a42189c.html ). Le permite consultar datos del sistema SAP HCM en tablas específicas. Al realizar una solicitud de datos, es posible especificar una lista de campos específicos y parámetros de filtrado para obtener los datos necesarios. Sin embargo, la implementación del servicio no implica ninguna lógica empresarial. Los algoritmos para calcular delta, parámetros de solicitud, control de integridad, etc. también se implementan en el lado del sistema externo.
Este mecanismo le permite recopilar y transferir todos los datos necesarios en unas pocas horas. Esta velocidad está al borde de lo aceptable, por lo que consideramos esta solución como temporal, lo que permitió cubrir la necesidad de una herramienta de extracción en el proyecto.
En la imagen de destino para resolver el problema de extracción de datos, se están elaborando las opciones para usar sistemas CDC como Oracle Golden Gate o herramientas ETL como SAP DS.