
Mi nombre es Ilya Gulyaev, soy ingeniero de automatización de pruebas en el equipo de verificación posterior a la implementación de DINS.
En DINS, utilizamos Jenkins en muchos procesos: desde la creación de compilaciones hasta la ejecución de implementaciones y pruebas automáticas. En mi equipo, utilizamos Jenkins como plataforma para realizar pruebas de humo de manera uniforme después de implementar cada uno de nuestros servicios desde los entornos de desarrollo hasta la producción.
Hace un año, otros equipos decidieron usar nuestras canalizaciones no solo para verificar un servicio después de actualizarlo, sino también para verificar el estado de todo el entorno antes de ejecutar grandes lotes de prueba. La carga en nuestra plataforma se ha multiplicado por diez y Jenkins ha dejado de hacer frente a la tarea en cuestión y acaba de empezar a caer. Rápidamente nos dimos cuenta de que agregar recursos y ajustar el recolector de basura solo podría retrasar el problema, pero no resolverlo por completo. Por lo tanto, decidimos encontrar los cuellos de botella de Jenkins y optimizarlos.
En este artículo, explicaré cómo funciona Jenkins Pipeline y compartiré mis hallazgos que pueden ayudarlo a agilizar sus pipelines. El material será útil para los ingenieros que ya hayan trabajado con Jenkins y quieran conocer mejor la herramienta.
Qué bestia tubería de Jenkins
Jenkins Pipeline es una poderosa herramienta que le permite automatizar varios procesos. Jenkins Pipeline es un conjunto de complementos que le permiten describir acciones en forma de Groovy DSL, y es el sucesor del complemento Build Flow.
El script para el complemento Build Flow se ejecutó directamente en el maestro en un hilo de Java separado que ejecutaba código Groovy sin barreras que impidieran el acceso a la API interna de Jenkins. Este enfoque planteaba un riesgo de seguridad, que luego se convirtió en una de las razones para abandonar Build Flow, y sirvió como requisito previo para crear una herramienta segura y escalable para ejecutar scripts: Jenkins Pipeline.
Puede obtener más información sobre la historia de la creación de Jenkins Pipeline en el artículo del autor Build Flow oCharla de Oleg Nenashev sobre Groovy DSL en Jenkins .
Cómo funciona Jenkins Pipeline
Ahora averigüemos cómo funcionan las tuberías desde adentro. Por lo general, dicen que Jenkins Pipeline es un tipo de trabajo completamente diferente en Jenkins, a diferencia de los viejos trabajos de estilo libre en los que se puede hacer clic en la interfaz web. Desde el punto de vista del usuario, puede verse así, pero desde el lado de Jenkins, las canalizaciones son un conjunto de complementos que le permiten transferir la descripción de las acciones al código.
Similitudes de trabajos de Pipeline y Freestyle
- La descripción del trabajo (no los pasos) se almacena en el archivo config.xml
- Los parámetros se almacenan en config.xml
- Los disparadores también se almacenan en config.xml
- E incluso algunas opciones se almacenan en config.xml
Entonces. Detener. La documentación oficial dice que los parámetros, disparadores y opciones se pueden configurar directamente en el Pipeline. ¿Dónde está la verdad?
La verdad es que los parámetros descritos en el Pipeline se agregarán automáticamente a la sección de configuración en la interfaz web cuando se inicie el trabajo. Puede confiar en mí porque escribí esta funcionalidad en la última edición , pero más sobre esto en la segunda parte del artículo.
Diferencias entre trabajos Pipeline y Freestyle
- En el momento del inicio del trabajo, Jenkins no sabe nada sobre el agente para ejecutar el trabajo.
- Las acciones se describen en un guión maravilloso.
Lanzamiento del canal declarativo de Jenkins
El proceso de inicio de Jenkins Pipeline consta de los siguientes pasos:
- Cargar la descripción del trabajo desde el archivo config.xml
- Inicie un hilo separado (ejecutante ligero) para completar la tarea
- Cargando el script de la canalización
- Construir y verificar un árbol de sintaxis
- Actualizaciones de configuración de trabajos
- Combinando parámetros y propiedades especificados en la descripción del trabajo y en el script
- Guardar descripciones de trabajos en el sistema de archivos
- Ejecutando un script en un entorno sandbox maravilloso
- Solicitud de agente para un trabajo completo o un solo paso
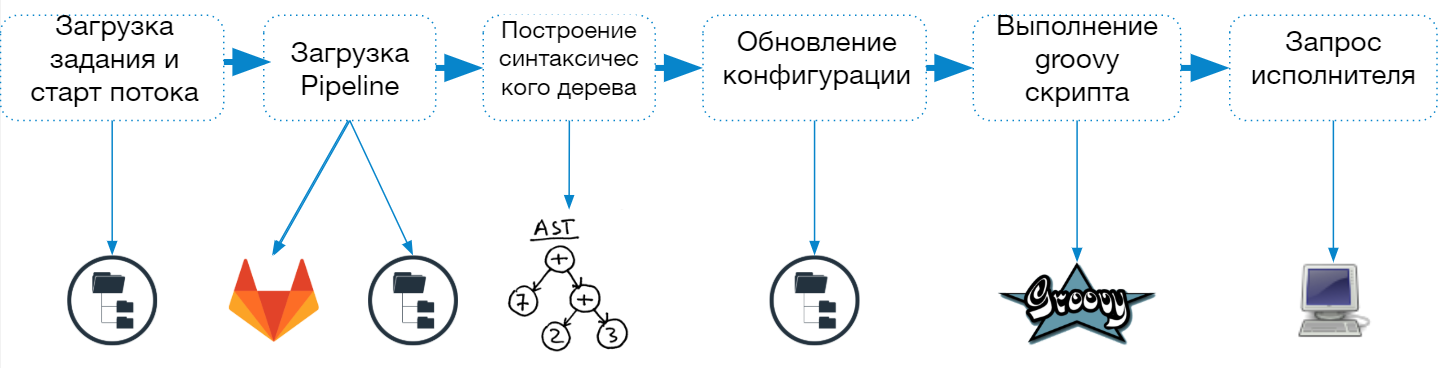
Cuando se inicia un trabajo de canalización, Jenkins crea un subproceso independiente y envía el trabajo a la cola para su ejecución, y después de cargar el script, determina qué agente se necesita para completar la tarea.
Para admitir este enfoque, se utiliza un grupo de subprocesos especial de Jenkins (ejecutores ligeros). Puede ver que se ejecutan en el maestro, pero no afectan al grupo habitual de ejecutores: el
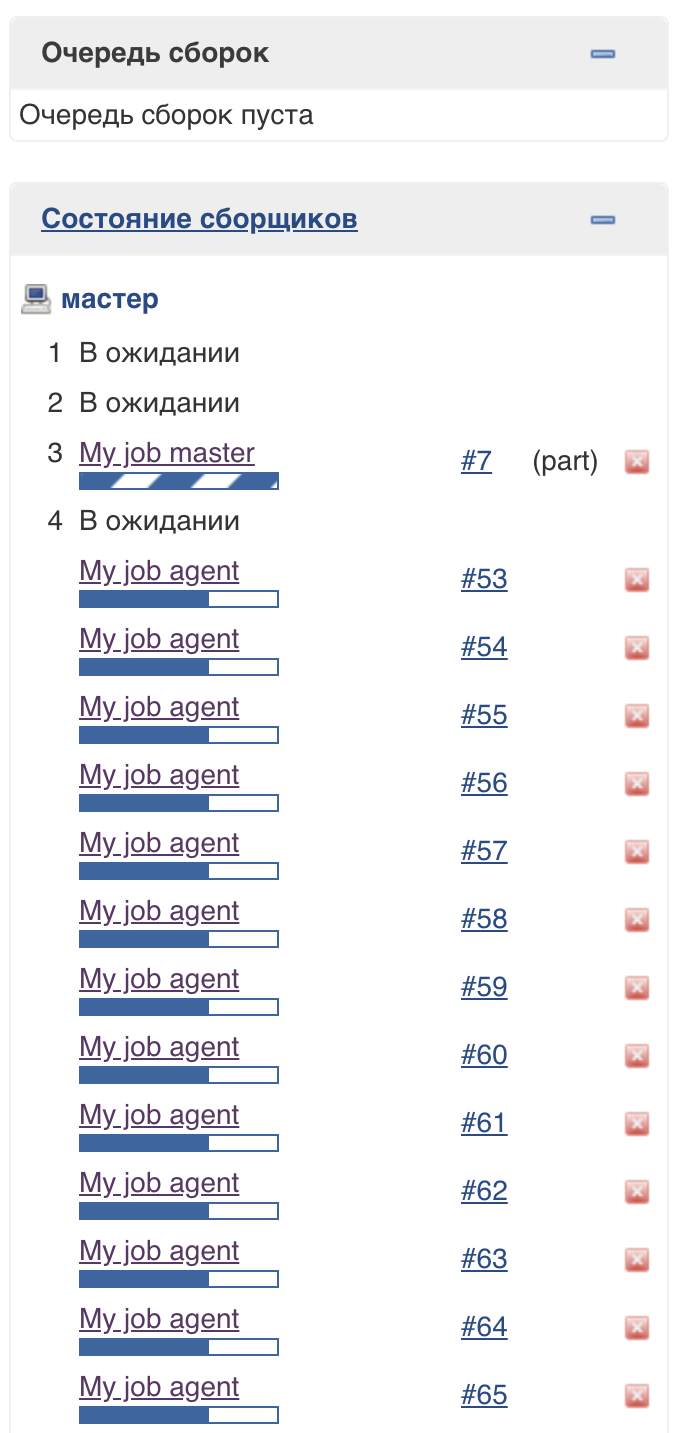
número de subprocesos en este grupo no está limitado (en el momento de escribir este artículo).
Parámetros de trabajo en el Pipeline. Además de disparadores y algunas opciones
El procesamiento de parámetros se puede describir mediante la fórmula:

A partir de los parámetros del trabajo que vemos en el inicio, primero se eliminan los parámetros del Pipeline del inicio anterior, y solo luego se agregan los parámetros especificados en el Pipeline del inicio actual. Esto permite eliminar los parámetros del trabajo si se eliminaron de la canalización.
¿Cómo funciona de adentro hacia afuera?
Veamos un config.xml de ejemplo (el archivo que almacena la configuración del trabajo):
<?xml version='1.1' encoding='UTF-8'?>
<flow-definition plugin="workflow-job@2.35">
<actions>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobAction plugin="pipeline-model-definition@1.5.0"/>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction plugin="pipeline-model-definition@1.5.0">
<jobProperties>
<string>jenkins.model.BuildDiscarderProperty</string>
</jobProperties>
<triggers/>
<parameters>
<string>parameter_3</string>
</parameters>
</org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction>
</actions>
<description></description>
<keepDependencies>false</keepDependencies>
<properties>
<hudson.model.ParametersDefinitionProperty>
<parameterDefinitions>
<hudson.model.StringParameterDefinition>
<name>parameter_1</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_2</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
<hudson.model.StringParameterDefinition>
<name>parameter_3</name>
<description></description>
<defaultValue></defaultValue>
<trim>false</trim>
</hudson.model.StringParameterDefinition>
</parameterDefinitions>
</hudson.model.ParametersDefinitionProperty>
<jenkins.model.BuildDiscarderProperty>
<strategy class="org.jenkinsci.plugins.BuildRotator.BuildRotator" plugin="buildrotator@1.2">
<daysToKeep>30</daysToKeep>
<numToKeep>10000</numToKeep>
<artifactsDaysToKeep>-1</artifactsDaysToKeep>
<artifactsNumToKeep>-1</artifactsNumToKeep>
</strategy>
</jenkins.model.BuildDiscarderProperty>
<com.sonyericsson.rebuild.RebuildSettings plugin="rebuild@1.28">
<autoRebuild>false</autoRebuild>
<rebuildDisabled>false</rebuildDisabled>
</com.sonyericsson.rebuild.RebuildSettings>
</properties>
<definition class="org.jenkinsci.plugins.workflow.cps.CpsScmFlowDefinition" plugin="workflow-cps@2.80">
<scm class="hudson.plugins.filesystem_scm.FSSCM" plugin="filesystem_scm@2.1">
<path>/path/to/jenkinsfile/</path>
<clearWorkspace>true</clearWorkspace>
</scm>
<scriptPath>Jenkinsfile</scriptPath>
<lightweight>true</lightweight>
</definition>
<triggers/>
<disabled>false</disabled>
</flow-definition>
La sección de propiedades contiene parámetros, disparadores y opciones con las que se lanzará el trabajo. Una sección adicional, DeclarativeJobPropertyTrackerAction, se usa para almacenar los parámetros establecidos solo en la canalización.
Cuando se elimina un parámetro de la canalización, se eliminará tanto de DeclarativeJobPropertyTrackerAction como de las propiedades , ya que Jenkins sabrá que el parámetro se definió solo en la canalización.
Al agregar un parámetro, la situación se invierte, el parámetro se agregará DeclarativeJobPropertyTrackerAction y propiedades , pero solo en el momento de la ejecución del pipeline.
Por eso, si establece los parámetros solo en la canalización,no estará disponible en el primer lanzamiento .
Ejecución Jenkins Pipeline
Una vez descargado y compilado el script Pipeline, comienza el proceso de ejecución. Pero este proceso no solo implica hacer cosas maravillosas. He resaltado las principales operaciones pesadas que se realizan en el momento de la ejecución del trabajo:
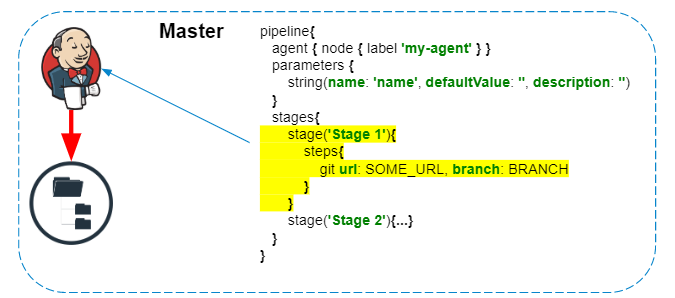
Ejecución de código Groovy
El script de canalización siempre se ejecuta en el maestro; no debemos olvidarnos de esto, para no crear una carga innecesaria en Jenkins. En el agente solo se ejecutan los pasos que interactúan con el sistema de archivos del agente o las llamadas al sistema.
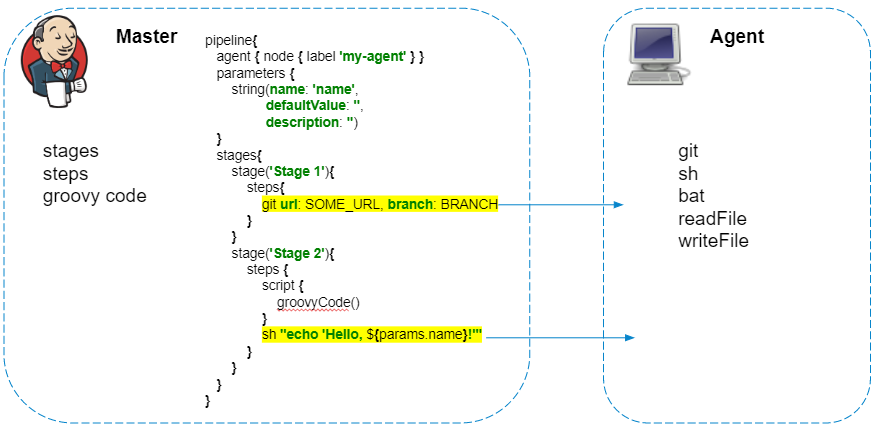
Las canalizaciones tienen un gran complemento que le permite realizar solicitudes HTTP . Además, la respuesta se puede guardar en un archivo.
httpRequest url: 'http://localhost:8080/jenkins/api/json?pretty=true', outputFile: 'result.json'
Inicialmente, puede parecer que este código debería ejecutarse completamente en el agente, enviar una solicitud del agente y guardar la respuesta en el archivo result.json. Pero todo sucede al revés, y la solicitud se ejecuta desde el propio Jenkins, y para guardar el contenido del archivo se copia al agente. Si no se requiere un procesamiento adicional de la respuesta en la canalización, le aconsejo que reemplace dichas solicitudes con curl:
sh 'curl "http://localhost:8080/jenkins/api/json?pretty=true" -o "result.json"'
Trabajar con registros y artefactos
Independientemente del agente en el que se ejecuten los comandos, los registros y artefactos se procesan y guardan en el sistema de archivos del maestro en tiempo real.
Si se utilizan secretos (credenciales) en la canalización, antes de guardar los registros se filtran adicionalmente en el maestro .
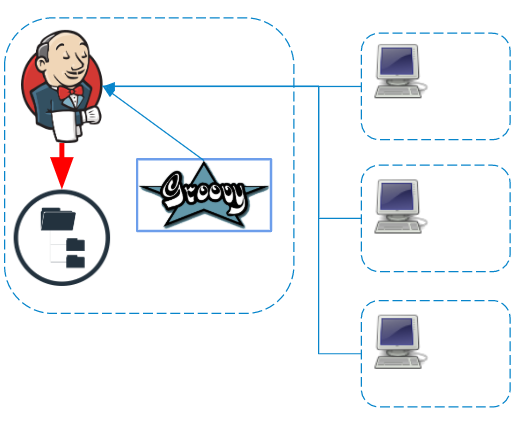
Pasos de ahorro (durabilidad de la tubería)
Jenkins Pipeline se posiciona como una tarea que consta de piezas separadas que son independientes y se pueden reproducir cuando el maestro falla. Pero debe pagar por esto con escrituras adicionales en el disco, porque, según la configuración de la tarea, los pasos con diversos grados de detalle se serializan y guardan en el disco.
Según la durabilidad de la canalización, los pasos del gráfico de canalización se almacenarán en uno o más archivos para cada ejecución de trabajo. Extracto de la documentación :
El complemento de soporte de flujo de trabajo para almacenar pasos (FlowNode) usa la clase FlowNodeStorage y sus implementaciones SimpleXStreamFlowNodeStorage y BulkFlowNodeStorage.
- FlowNodeStorage utiliza el almacenamiento en caché en memoria para agregar escrituras en disco. El búfer se escribe automáticamente en tiempo de ejecución. Por lo general, no necesita preocuparse por esto, pero tenga en cuenta que guardar un FlowNode no garantiza que se escribirá en el disco inmediatamente.
- SimpleXStreamFlowNodeStorage usa un archivo XML pequeño para cada FlowNode; aunque usamos un caché en memoria de referencia suave para los nodos, esto da como resultado un rendimiento mucho peor cuando se pasan por primera vez los pasos (FlowNodes).
- BulkFlowNodeStorage utiliza un archivo XML más grande con todos los FlowNodes en él. Esta clase se utiliza en el modo de vida PERFORMANCE_OPTIMIZED, que escribe con mucha menos frecuencia. Esto generalmente es mucho más eficiente porque un registro de transmisión grande es más rápido que un grupo de registros pequeños y minimiza la carga en el sistema operativo para administrar todos los archivos pequeños.
Original
Storage: in the workflow-support plugin, see the 'FlowNodeStorage' class and the SimpleXStreamFlowNodeStorage and BulkFlowNodeStorage implementations.
- FlowNodeStorage uses in-memory caching to consolidate disk writes. Automatic flushing is implemented at execution time. Generally, you won't need to worry about this, but be aware that saving a FlowNode does not guarantee it is immediately persisted to disk.
- The SimpleXStreamFlowNodeStorage uses a single small XML file for every FlowNode — although we use a soft-reference in-memory cache for the nodes, this generates much worse performance the first time we iterate through the FlowNodes (or when)
- The BulkFlowNodeStorage uses a single larger XML file with all the FlowNodes in it. This is used in the PERFORMANCE_OPTIMIZED durability mode, which writes much less often. It is generally much more efficient because a single large streaming write is faster than a bunch of small writes, and it minimizes the system load of managing all the tiny files.
Los pasos guardados se pueden encontrar en el directorio:
$JENKINS_HOME/jobs/$JOB_NAME/builds/$BUILD_ID/workflow/
Archivo de ejemplo:
<?xml version='1.1' encoding='UTF-8'?>
<Tag plugin="workflow-support@3.5">
<node class="cps.n.StepStartNode" plugin="workflow-cps@2.82">
<parentIds>
<string>4</string>
</parentIds>
<id>5</id>
<descriptorId>org.jenkinsci.plugins.workflow.support.steps.StageStep</descriptorId>
</node>
<actions>
<s.a.LogStorageAction/>
<cps.a.ArgumentsActionImpl plugin="workflow-cps@2.82">
<arguments>
<entry>
<string>name</string>
<string>Declarative: Checkout SCM</string>
</entry>
</arguments>
<isUnmodifiedBySanitization>true</isUnmodifiedBySanitization>
</cps.a.ArgumentsActionImpl>
<wf.a.TimingAction plugin="workflow-api@2.40">
<startTime>1600855071994</startTime>
</wf.a.TimingAction>
</actions>
</Tag>
Salir
Espero que este material haya sido interesante y haya ayudado a comprender mejor qué son las tuberías y cómo funcionan desde adentro. Si aún tiene preguntas, compártalas a continuación, ¡estaré encantado de responder!
En la segunda parte del artículo, consideraré casos separados que lo ayudarán a encontrar problemas con Jenkins Pipeline y acelerar sus tareas. Aprenderemos cómo resolver problemas de lanzamiento simultáneo, analizaremos las opciones de supervivencia y discutiremos por qué se debe perfilar Jenkins.