
Recientemente, las grandes empresas rusas buscan cada vez más soluciones de almacenamiento asequibles. Los DBMS de código abierto se convierten en competidores de Oracle, SAP HANA, Sybase, Informix: PostgreSQL, MySQL, MariaDB, etc. Los gigantes occidentales (Alibaba, Instagram, Skype) los han utilizado durante mucho tiempo en sus entornos de TI.
En el proyecto para la Unión Rusa de Aseguradoras de Automóviles (RSA), donde Jet Infosystems estaba construyendo la infraestructura de TI para el nuevo AIS OSAGO, los desarrolladores utilizaron el DBMS PostgreSQL. Y pensamos en cómo garantizar la máxima disponibilidad de la base de datos y la mínima pérdida de datos en caso de fallas de hardware. Y esta descripción “en papel” de la solución parece tan simple como 2 + 2, de hecho, nuestro equipo tuvo que trabajar duro para lograr la tolerancia a fallas.
Hay varias herramientas de agrupación en clústeres de conmutación por error para PostgreSQL. Estos son Stolon, Patroni, Repmgr, Pacemaker + Corosync, etc.
Elegimos Patroni porque este proyecto se está desarrollando activamente, a diferencia de proyectos similares, tiene una documentación clara y se está convirtiendo cada vez más en la elección de los administradores de bases de datos.
La composición del "juego de sopa"
Patroni es un conjunto de scripts de Python para automatizar el cambio de la función principal de un servidor de base de datos PostgreSQL a una réplica. También puede almacenar, modificar y aplicar parámetros del propio DBMS de PostgreSQL. Resulta que no es necesario mantener actualizados los archivos de configuración de PostgreSQL en cada servidor por separado.
PostgreSQL es una base de datos relacional de código abierto. Ha demostrado su eficacia en procesos analíticos grandes y complejos.
Keepalived: en una configuración de varios nodos, se utiliza para habilitar una dirección IP dedicada en el mismo nodo del clúster donde se utiliza actualmente la función del nodo PostgreSQL principal. La dirección IP sirve como punto de entrada para aplicaciones y usuarios.
DCS es un almacenamiento de configuración distribuido. Patroni lo utiliza para almacenar información sobre la composición del clúster, los roles de los servidores del clúster, así como para almacenar sus propios parámetros de configuración y PostgreSQL. Este artículo se centrará en etcd.
Experimentos con matices
En busca de la solución óptima para la tolerancia a fallos y con el fin de probar nuestras hipótesis sobre el funcionamiento de diferentes opciones, creamos varios bancos de pruebas. Inicialmente, consideramos soluciones que eran diferentes de la arquitectura de destino: por ejemplo, usamos Haproxy ya que el nodo principal de PostgreSQL o DCS estaba ubicado en los mismos servidores que PostgreSQL. Organizamos hackatones internos, estudiamos cómo se comportaría Patroni en caso de falla de los componentes del servidor, indisponibilidad de la red, desbordamiento del sistema de archivos, etc. Es decir, resolvieron varios escenarios de falla. Como resultado de estos "estudios científicos", se formó la arquitectura final de la solución tolerante a fallas.
Plato de alta cocina informática
Hay roles de servidor en PostgreSQL: primario: una instancia con la capacidad de escribir / leer datos; réplica: una instancia de solo lectura, sincronizada constantemente con el archivo primario. Estos roles son estáticos cuando se ejecuta PostgreSQL, y si falla un servidor con el rol principal, el DBA debe elevar manualmente el rol de réplica a primario.
Patroni crea clústeres de conmutación por error, es decir, combina servidores con las funciones principal y de réplica. Hay un cambio de rol automático entre ellos en caso de falla.

La ilustración anterior muestra cómo los servidores de aplicaciones se conectan a uno de los servidores del clúster Patroni. Esta configuración utiliza un nodo principal y dos réplicas, una de las cuales es sincrónica. Con la replicación sincrónica, PostgreSQL funciona de tal manera que el primario siempre espera a que se escriban los cambios en la réplica. Si la réplica síncrona no está disponible, la principal no escribirá los cambios en sí misma, será de solo lectura. Esta es la arquitectura de PostgreSQL. Para "cambiar su naturaleza", se utiliza la segunda réplica: asíncrona (si no se requiere la réplica síncrona, puede limitarse a una réplica).
Cuando se utilizan dos o más réplicas y se habilita la réplica sincrónica, Patroni siempre hace solo una réplica sincrónica. Si el nodo principal falla, Patroni aumenta el nivel de la réplica sincrónica.
La siguiente ilustración muestra la funcionalidad adicional de Patroni que es vital en las soluciones empresariales industriales: replicación de datos en un sitio de respaldo.
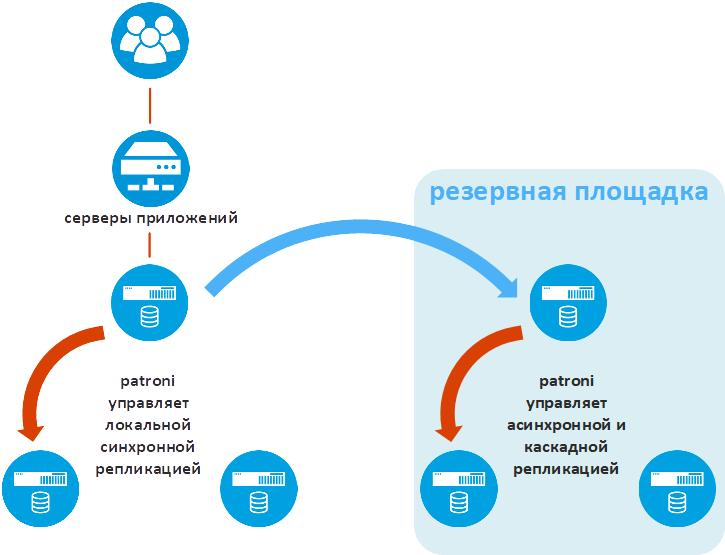
Patroni llama a esta funcionalidad standby_cluster. Permite que un clúster de Ratroni se utilice en un sitio remoto como una réplica asincrónica. Si se pierde el sitio principal, el clúster Patroni comenzará a funcionar como si fuera el sitio principal.
Uno de los nodos del clúster del sitio de respaldo se llama Líder en espera. Es una réplica asincrónica del nodo principal del sitio principal. Los dos nodos restantes del clúster del sitio de respaldo reciben datos del líder en espera. Así es como se implementa la replicación en cascada, lo que reduce el volumen de tráfico entre sitios tecnológicos.
Composición de las aplicaciones del clúster Patroni
Una vez lanzado, Patroni crea un puerto TCP separado. Una vez realizada una solicitud HTTP a este puerto, puede comprender qué nodo del clúster es principal y cuál es la réplica.

En keepalived, hemos especificado un pequeño script hecho en casa como objeto de monitorización que sondea el puerto TCP de Patroni. El script espera una respuesta HTTP GET 200. El nodo del clúster que responde es el nodo principal, en el que keepalived inicia la dirección IP dedicada para conectarse al clúster.
Si configura la segunda instancia keepalived para esperar una respuesta HTTP GET 200 de una réplica síncrona, keepalived en el mismo nodo del clúster lanzará otra dirección IP dedicada. La aplicación puede utilizar esta dirección para leer datos de la base de datos. Esta opción es útil, por ejemplo, para preparar informes.
Dado que Patroni es un conjunto de scripts, sus instancias en cada nodo no se "comunican" directamente entre sí, sino que utilizan el almacén de configuración para ello. Usamos etcd, que es un quórum para el propio Patroni: el nodo principal actual actualiza constantemente la clave en el repositorio etcd, lo que indica que es el principal. El resto de los nodos del clúster leen constantemente esta clave y "comprenden" que son réplicas. El servicio etcd se encuentra en servidores dedicados en una cantidad de 3 o 5. La sincronización de los datos del almacenamiento etcd entre estos servidores se realiza mediante el propio servicio etcd.
En el curso de nuestros experimentos, descubrimos que el servicio etcd debe trasladarse a servidores separados. En primer lugar, etcd es extremadamente sensible a la latencia de la red y la capacidad de respuesta del subsistema de disco, y los servidores dedicados no se cargarán. En segundo lugar, con una posible separación de la red de los nodos del clúster Patroni, puede ocurrir una "división cerebral": aparecerán dos nodos primarios, que no sabrán nada entre sí, ya que el clúster etcd también se "desintegrará".
Prueba de práctica
En la escala de un proyecto para construir una infraestructura de TI para AIS OSAGO, lograr la tolerancia a fallas de PostgreSQL es una de las tareas de "implantar" un DBMS abierto en el panorama de TI corporativo. Junto a él, están los problemas relacionados con la integración del clúster PostgreSQL con sistemas de respaldo, monitoreo de infraestructura y herramientas de seguridad de la información, y seguridad de datos confiable en el sitio de respaldo. Cada una de estas direcciones tiene sus propias dificultades y formas de evitarlas. Ya hemos escrito sobre uno de ellos: hablamos sobre la copia de seguridad de PostgreSQL utilizando soluciones empresariales .

La arquitectura tolerante a fallos de PostgreSQL, pensada y probada en nuestros stands, ha demostrado su eficacia en la práctica. La solución está lista para "transferir" varios fallos lógicos y del sistema. Ahora se ejecuta en 10 clústeres Patroni altamente cargados y soporta cargas de procesamiento de PostgreSQL de cientos de gigabytes de datos por hora.
Autor: Dmitry Erykin, e ingeniero-diseñador de sistemas informáticos de Jet Infosystems