Desde hace aproximadamente un año, nuestra división de infraestructura ha estado migrando todos los servicios que se ejecutan en GitLab.com a Kubernetes. Durante este tiempo, encontramos problemas no solo con el traslado de servicios a Kubernetes, sino también con la gestión de la implementación híbrida durante la transición. Las valiosas lecciones que hemos aprendido se discutirán en este artículo.
Desde el comienzo de GitLab.com, sus servidores se ejecutaron en la nube en máquinas virtuales. Estas máquinas virtuales son administradas por Chef y se instalan usando nuestro paquete oficial de Linux . La estrategia de implementación en caso de que una aplicación deba actualizarse es simplemente actualizar la flota de servidores de una manera secuencial coordinada utilizando la canalización de CI. Este método, aunque lento y un poco aburrido , garantiza que GitLab.com utilice los mismos métodos de instalación y configuración que los usuarios de las instalaciones autogestionadas de GitLab que utilizan nuestros paquetes de Linux.
Usamos este método porque es extremadamente importante experimentar toda la tristeza y alegría que experimentan los miembros comunes de la comunidad al instalar y configurar sus copias de GitLab. Este enfoque funcionó bien durante algún tiempo, pero cuando la cantidad de proyectos en GitLab superó los 10 millones, nos dimos cuenta de que ya no satisfacía nuestras necesidades de escalamiento e implementación.
Primeros pasos hacia Kubernetes y GitLab nativo de la nube
En 2017, se creó el proyecto GitLab Charts para preparar GitLab para su implementación en la nube, así como para permitir a los usuarios instalar GitLab en clústeres de Kubernetes. Entonces sabíamos que trasladar GitLab a Kubernetes aumentaría la escalabilidad de la plataforma SaaS, simplificaría las implementaciones y mejoraría la eficiencia informática. Al mismo tiempo, muchas características de nuestra aplicación dependían de particiones NFS montadas, lo que ralentizaba la transición desde máquinas virtuales.
La búsqueda de la nube nativa y Kubernetes permitió a nuestros ingenieros planificar una transición gradual, durante la cual abandonamos algunas de las dependencias de NAS de la aplicación mientras continuamos desarrollando nuevas funciones en el camino. Desde que comenzamos a planificar la migración en el verano de 2019, muchas de estas restricciones se han eliminado y el proceso de migración de GitLab.com a Kubernetes está ahora en pleno apogeo.
Características del trabajo de GitLab.com en Kubernetes
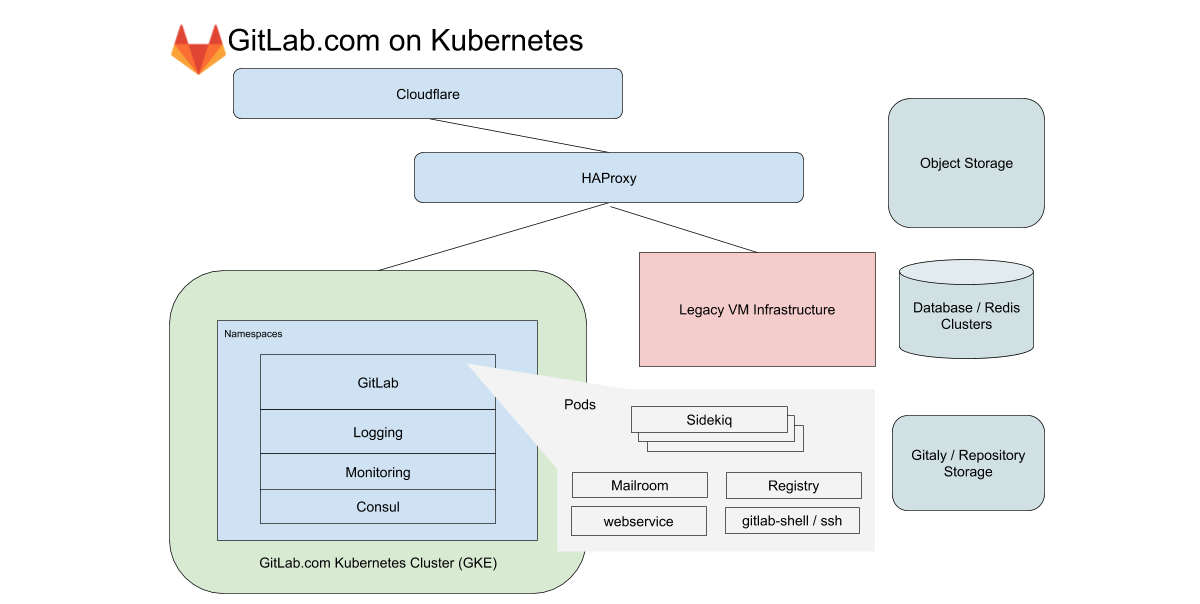
Para GitLab.com, usamos un solo clúster de GKE regional que maneja todo el tráfico de aplicaciones. Para minimizar la complejidad de la migración (ya complicada), nos centramos en servicios que no dependen del almacenamiento local o NFS. GitLab.com utiliza una base de código Rails predominantemente monolítica, y enrutamos el tráfico en función de las características de la carga de trabajo a varios puntos finales aislados en nuestros propios grupos de nodos.
En el caso de la interfaz, estos tipos se dividen en solicitudes a la web, API, Git SSH / HTTPS y Registro. En el caso del backend, ponemos en cola los trabajos de acuerdo con diferentes características según los límites de recursos predefinidos que nos permiten establecer objetivos de nivel de servicio (SLO) para diferentes cargas de trabajo.
Todos estos servicios de GitLab.com se configuran mediante un gráfico de GitLab Helm sin modificar. La configuración se realiza en subgráficos, que se pueden habilitar de forma selectiva a medida que migramos gradualmente los servicios al clúster. Aunque se decidió no incluir algunos de nuestros servicios con estado, como Redis, Postgres, GitLab Pages y Gitaly, en la migración, Kubernetes reduce drásticamente la cantidad de VM que Chef administra actualmente.
Gestión de la configuración y la transparencia de Kubernetes
Todas las configuraciones están controladas por el propio GitLab. Para ello se utilizan tres proyectos de configuración basados en Terraform y Helm. Intentamos usar GitLab siempre que sea posible para ejecutar GitLab, pero para las tareas operativas tenemos una instalación de GitLab separada. Es necesario que sea independiente de la disponibilidad de GitLab.com para las implementaciones y actualizaciones de GitLab.com.
Aunque nuestras canalizaciones para el clúster de Kubernetes se ejecutan en una instalación de GitLab separada, los repositorios de código tienen espejos disponibles públicamente en las siguientes direcciones:
- k8s-workloads / gitlab-com : enlace de configuración de GitLab.com para el gráfico de GitLab Helm;
- k8s-workloads/gitlab-helmfiles — , GitLab . , PlantUML;
- Gitlab-com-infrastructure — Terraform Kubernetes (legacy) VM-. , , , , , IP-.

Cuando se realizan cambios, se muestra un breve resumen disponible públicamente con un enlace a una diferencia detallada, que SRE analiza antes de realizar cambios en el clúster.
Para los SRE, el enlace apunta a una diferencia detallada en la instalación de GitLab que se está utilizando para la producción y el acceso es limitado. Esto permite a los empleados y la comunidad sin acceso al proyecto operativo (está abierto solo para la SRE) ver los cambios de configuración propuestos. Al combinar una instancia pública de GitLab para código con una instancia privada para canalizaciones de CI, mantenemos un único flujo de trabajo al tiempo que garantizamos la independencia de GitLab.com para las actualizaciones de configuración.
Lo que descubrimos durante la migración
Durante la mudanza se ha acumulado experiencia, que aplicamos a nuevas migraciones e implementaciones en Kubernetes.
1. -

Estadísticas de salida diarias (bytes por día) para el parque de repositorios de Git en GitLab.com
Google divide su red en regiones. Éstos, a su vez, se dividen en zonas de disponibilidad (AZ). El alojamiento Git está asociado con grandes cantidades de datos, por lo que es importante para nosotros controlar la salida de la red. Para el tráfico interno, la salida es gratuita solo si permanece dentro de la misma zona de disponibilidad. En el momento de escribir este artículo, proporcionamos aproximadamente 100 TB de datos en un día hábil típico (y eso es solo para los repositorios de Git) Los servicios que, en nuestra antigua topología basada en VM, estaban en las mismas máquinas virtuales, ahora se ejecutan en diferentes pods de Kubernetes. Esto significa que parte del tráfico que antes era local en la máquina virtual puede salir potencialmente fuera de las zonas de disponibilidad.
Los clústeres regionales de GKE te permiten abarcar varias zonas de disponibilidad para obtener redundancia. Estamos considerando dividir el clúster de GKE regional en clústeres de una sola zona para los servicios que generan grandes volúmenes de tráfico. Esto reducirá los costos de salida mientras se mantiene la redundancia del clúster.
2. Límites, solicitudes de recursos y escala

El número de réplicas que procesan el tráfico de producción en registry.gitlab.com. El tráfico alcanza su punto máximo a las ~ 15:00 UTC.
Nuestra historia de migración comenzó en agosto de 2019, cuando trasladamos nuestro primer servicio, GitLab Container Registry, a Kubernetes. Este servicio de misión crítica de alto tráfico fue muy adecuado para la primera migración porque es una aplicación sin estado con pocas dependencias externas. El primer problema que encontramos fue la gran cantidad de pods interrumpidos debido a la memoria insuficiente en los nodos. Debido a esto, tuvimos que cambiar las solicitudes y los límites.
Se encontró que en el caso de una aplicación en la que el consumo de memoria aumenta con el tiempo, valores bajos para request'ov (para cada pod'a de memoria redundante) junto con un límite rígido "generoso" para usar conducen a unidades de saturación (saturación) y un alto nivel de desplazamiento. Para hacer frente a este problema, se decidió aumentar las solicitudes y reducir los límites . Esto eliminó la presión de los nodos y aseguró un ciclo de vida del pod que no ejerció demasiada presión sobre el nodo. Ahora comenzamos las migraciones con valores límite y de solicitud generosos (y casi idénticos), ajustándolos según sea necesario.
3. Métricas y registros

La división de infraestructura se centra en la latencia, las tasas de error y la saturación con objetivos de nivel de servicio (SLO) establecidos vinculados a la disponibilidad general de nuestro sistema .
Durante el año pasado, uno de los desarrollos clave en la división de infraestructura ha sido la mejora en el monitoreo y el trabajo con los SLO. Los SLO nos permitieron establecer objetivos para servicios individuales, que monitoreamos de cerca durante la migración. Pero incluso con tal observabilidad mejorada, no siempre es posible ver los problemas de inmediato utilizando métricas y alertas. Por ejemplo, al centrarnos en la latencia y las tasas de error, no cubrimos por completo todos los casos de uso de un servicio en proceso de migración.
Este problema se descubrió casi inmediatamente después de mover algunas de las cargas de trabajo al clúster. Se volvió especialmente agudo cuando era necesario verificar funciones, cuyo número de solicitudes es pequeño, pero que tienen dependencias de configuración muy específicas. Una de las lecciones clave de los resultados de la migración fue la necesidad de tener en cuenta al monitorear no solo las métricas, sino también los registros y la "cola larga" (estamos hablando de su distribución en el gráfico - aprox. Transl.) . Ahora, para cada migración, incluimos una lista detallada de consultas de registro y planificamos procedimientos de reversión claros que se pueden pasar de un turno a otro en caso de problemas.
Atender las mismas solicitudes en paralelo en la antigua infraestructura de VM y la nueva basada en Kubernetes fue un desafío único. A diferencia de la migración lift-and-shift (transferencia rápida de aplicaciones "tal cual" a una nueva infraestructura; puede leer más, por ejemplo, aquí - aprox. Transl.) , El trabajo paralelo en máquinas virtuales "antiguas" y Kubernetes requiere herramientas para Los sistemas de monitoreo eran compatibles con ambos entornos y pudieron combinar métricas en una sola vista. Es importante que usemos los mismos cuadros de mando y consultas de registro para lograr una observabilidad constante durante la transición.
4. Cambiar el tráfico a un nuevo clúster
Para GitLab.com, algunos de los servidores están asignados para la etapa canary . Canary Park se adapta a nuestros proyectos internos y también puede ser habilitado por los usuarios . Pero, ante todo, está destinado a validar los cambios realizados en la infraestructura y la aplicación. El primer servicio migrado comenzó aceptando una cantidad limitada de tráfico interno, y continuamos usando este método para asegurarnos de que se cumpla el SLO antes de reenviar todo el tráfico al clúster.
En el caso de la migración, esto significa que las primeras solicitudes a proyectos internos se envían a Kubernetes y luego cambiamos gradualmente el resto del tráfico al clúster cambiando el peso del backend a través de HAProxy. En el proceso de pasar de VM a Kubernetes, quedó claro que era muy beneficioso tener una forma sencilla de redirigir el tráfico entre la infraestructura antigua y la nueva y, en consecuencia, mantener la infraestructura antigua lista para la reversión en los primeros días después de la migración.
5. Reserva de energía de las vainas y su uso
Casi de inmediato, se identificó el siguiente problema: los módulos para el servicio de registro se iniciaron rápidamente, pero los módulos para Sidekiq tardaron hasta dos minutos en iniciarse . Los pods de larga ejecución para Sidekiq se convirtieron en un problema cuando comenzamos a migrar cargas de trabajo a Kubernetes para los trabajadores que necesitan procesar trabajos y escalar rápidamente.
En este caso, la lección fue que si bien el escalador automático horizontal de pods (HPA) en Kubernetes maneja bien el crecimiento del tráfico, es importante tener en cuenta las características de las cargas de trabajo y asignar la capacidad de los pods de repuesto (especialmente en un entorno de demanda desigual). En nuestro caso, hubo un aumento repentino en los trabajos, lo que implicó un escalado rápido, lo que llevó a la saturación de los recursos de la CPU antes de que tuviéramos tiempo para escalar el grupo de nodos.
Siempre existe la tentación de exprimir todo lo posible del clúster, sin embargo, inicialmente nos enfrentamos a problemas de rendimiento, ahora comenzamos con un generoso presupuesto de pod y lo reducimos más tarde, vigilando de cerca el SLO. El lanzamiento de pods para el servicio Sidekiq se ha acelerado significativamente y ahora lleva unos 40 segundos en promedio.Tanto GitLab.com como nuestros usuarios de instalaciones autogestionadas que trabajan con el gráfico oficial de GitLab Helm se han beneficiado de la reducción en los tiempos de lanzamiento de pod .
Conclusión
Después de migrar cada servicio, disfrutamos de los beneficios de usar Kubernetes en producción: implementación de aplicaciones más rápida y segura, escalado y asignación de recursos más eficiente. Además, las ventajas de la migración van más allá del servicio GitLab.com. Cada mejora del gráfico oficial de Helm también beneficia a sus usuarios.
Espero que haya disfrutado de la historia de nuestras aventuras de migración a Kubernetes. Continuamos migrando todos los servicios nuevos al clúster. Se puede obtener información adicional en las siguientes publicaciones:
- « ¿Por qué estamos migrando a Kubernetes <br> nosotros? ";
- " GitLab.com en Kubernetes ";
- Épico sobre la migración de GitLab.com a Kubernetes .
PD del traductor
Lea también en nuestro blog: