
Una de las primeras advertencias que recibe un joven padawan con acceso a los repositorios de git es: "nunca
git push -f". Dado que esta es una de las cientos de máximas que un ingeniero de software novato debe aprender, nadie se toma el tiempo para aclarar por qué no debe hacerse. Es como los bebés y el fuego: “los fósforos no son juguetes para niños” y eso es todo. Pero crecemos y nos desarrollamos como personas y como profesionales, y un día la pregunta "¿por qué, en realidad?" sube en pleno crecimiento. Este artículo está escrito en base a nuestra reunión interna, sobre el tema: "Cuándo puede y debe reescribir el historial de confirmaciones".

He escuchado que la capacidad de responder a esta pregunta en una entrevista en algunas empresas es un criterio para las entrevistas para puestos directivos. Pero para comprender mejor la respuesta, necesita comprender por qué reescribir la historia es malo en absoluto.
Para hacer esto, a su vez, necesitamos una rápida excursión a la estructura física del repositorio de git. Si está seguro de que sabe todo sobre el dispositivo de repositorio, puede omitir esta parte, pero incluso en el proceso de averiguarlo, aprendí muchas cosas nuevas por mí mismo, y algunas antiguas resultaron no ser del todo relevantes.
En el nivel más bajo, un repositorio de git es una colección de objetos y apuntadores a ellos. Cada objeto tiene su propio hash exclusivo de 40 dígitos (20 bytes hexadecimales), que se calcula en función del contenido del objeto.
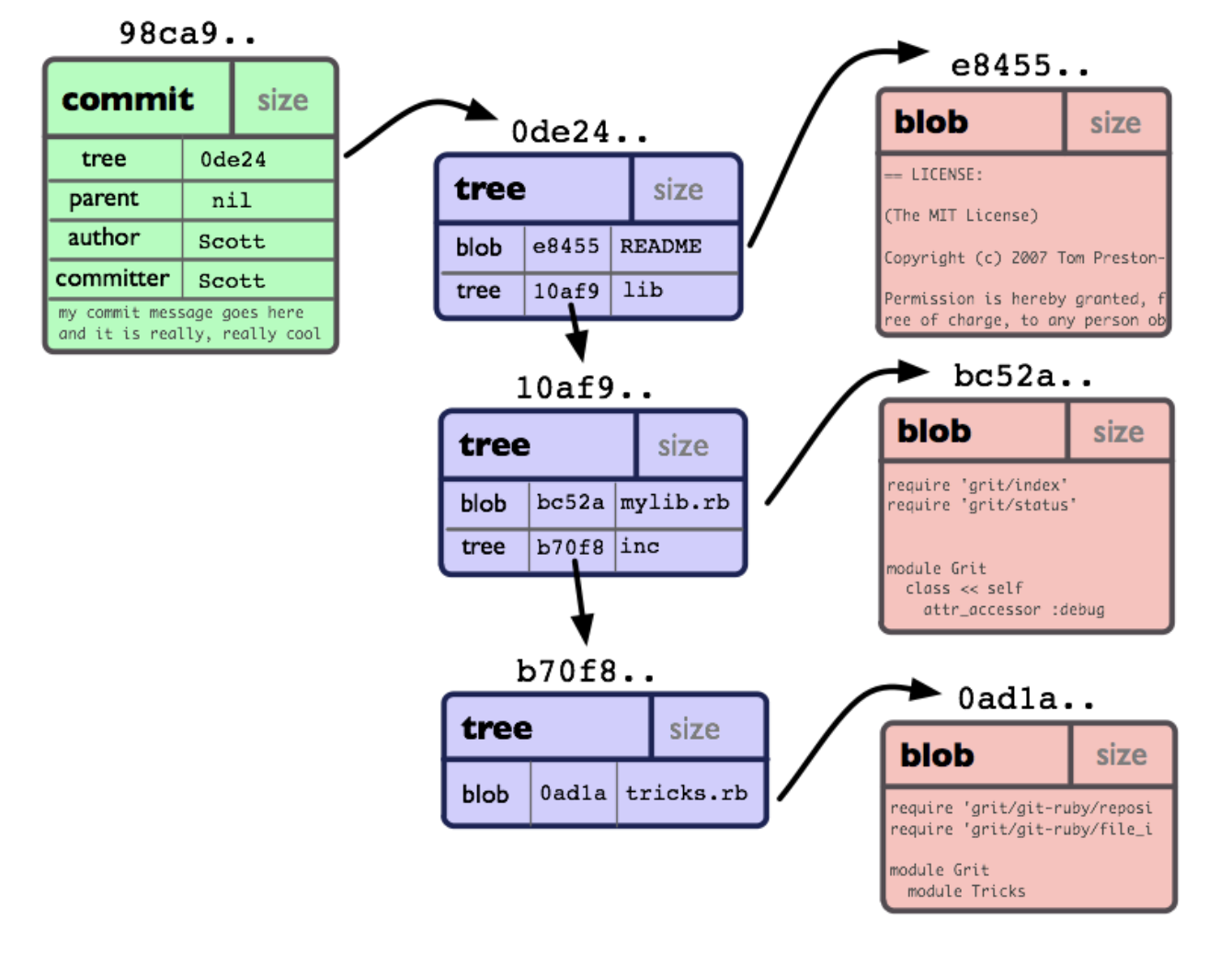
Ilustración tomada de The Git Community Book
Los principales tipos de objetos son blob (solo el contenido de un archivo), árbol (una colección de punteros a blobs y otros árboles) y commit. Un objeto de tipo confirmación es solo un puntero al árbol, a la confirmación anterior y a la información del servicio: fecha / hora, autor y comentario.
¿Dónde están las sucursales y etiquetas con las que estamos acostumbrados a operar? Y no son objetos, son solo punteros: una rama apunta a la última confirmación en ella, una etiqueta apunta a una confirmación arbitraria en el repositorio. Es decir, cuando vemos ramas bellamente dibujadas con círculos de confirmación en el cliente IDE o GUI, se construyen sobre la marcha, corriendo a lo largo de las cadenas de confirmación desde los extremos de las ramas hasta la "raíz". La primera confirmación en el repositorio no tiene una anterior, en lugar de un puntero hay un valor nulo.
Un punto importante a entender: la misma confirmación puede aparecer en varias ramas al mismo tiempo. Las confirmaciones no se copian cuando se crea una nueva rama, simplemente comienza a "crecer" desde donde estaba HEAD en el momento en que se emitió el comando
git checkout -b <branch-name>.
Entonces, ¿por qué es dañino reescribir el historial de un repositorio?

Primero, y esto es obvio, cuando carga una nueva historia en el repositorio con el que está trabajando el equipo de ingeniería, es posible que otras personas simplemente pierdan sus cambios. El comando
git push -f elimina de la rama en el servidor todas las confirmaciones que no están en la versión local y escribe nuevas.
Por alguna razón, pocas personas saben que durante mucho tiempo el equipo
git pushtiene una clave "segura"--force-with-leaselo que hace que el comando falle si hay confirmaciones agregadas por otros usuarios al repositorio remoto. Siempre recomiendo usarlo en su lugar -f/--force.
La segunda razón por la que el comando
git push -fse considera dañino es que cuando intentas fusionar una rama con el historial reescrito con las ramas donde se conservó (más precisamente, las confirmaciones eliminadas del historial reescrito se guardaron), obtendremos una gran cantidad de conflictos (por el número se compromete, en realidad). Hay una respuesta simple a esto: si sigues cuidadosamente Gitflow o Gitlab Flow , es muy probable que tales situaciones ni siquiera surjan.
Y finalmente, hay un lado desagradable de reescribir la historia: esas confirmaciones que están, por así decirlo, eliminadas de la rama, de hecho, no desaparecen en ningún lado y simplemente permanecen para siempre colgadas en el repositorio. Un poco, pero desagradable. Afortunadamente, los desarrolladores de git también han abordado este problema con el comando de recolección de basura
git gc --prune. La mayoría de los hosts de git, al menos GitHub y GitLab, hacen esto en segundo plano de vez en cuando.
Entonces, habiendo disipado los temores de cambiar la historia del repositorio, finalmente podemos pasar a la pregunta principal: ¿por qué es necesario y cuándo se justifica?
De hecho, estoy seguro de que casi todos los usuarios de git más o menos activos han cambiado el historial al menos una vez, cuando de repente resultó que algo salió mal en la última confirmación: un error tipográfico molesto se deslizó en el código, hizo que la confirmación fuera incorrecta. usuario (de correo electrónico personal en lugar de trabajo o viceversa), olvidó agregar un nuevo archivo (si a usted, como yo, le gusta usar
git commit -a). Incluso cambiar la descripción de una confirmación conlleva la necesidad de volver a escribirla, ¡porque el hash también se cuenta de la descripción!
Pero este es un caso trivial. Veamos otros más interesantes.
Supongamos que hizo una gran función, que vio durante varios días, enviando los resultados diarios del trabajo al repositorio en el servidor (4-5 confirmaciones) y envió sus cambios para su revisión. Dos o tres revisores incansables lo colmaron con recomendaciones grandes y pequeñas para ediciones, o incluso encontraron jambas (4-5 confirmaciones más). Luego, QA encontró varios casos extremos que también requieren correcciones (2-3 confirmaciones más). Y finalmente, durante la integración, se descubrieron algunas incompatibilidades o se ingresaron autotests, que también deben solucionarse.
Si ahora presiona el botón Fusionar sin mirar, entonces una docena y media de confirmaciones como "Mi función, día 1", "Día 2", "Reparar pruebas", "Reparar revisión" se agregarán a la rama principal (para muchos se le llama maestro a la antigua) etc. Esto, por supuesto, ayuda al modo squash, que ahora está tanto en GitHub como en GitLab, pero debes tener cuidado con él: en primer lugar, puede reemplazar la descripción de confirmación con algo impredecible y, en segundo lugar, reemplazar al autor de la función. en el que presionó el botón Fusionar (lo tenemos en general un robot que ayuda al ingeniero de lanzamiento a ensamblar la implementación de hoy). Por lo tanto, lo más simple será, antes de la integración final en la versión, colapsar todas las confirmaciones de la rama en un solo uso
git rebase.
Pero también sucede que ya se ha acercado a la revisión del código con un historial de repositorios que recuerda a la ensalada Olivier. Esto sucede si una función se ha cortado durante varias semanas, porque estaba mal descompuesta o, aunque se golpea con un candelabro a equipos decentes por esto, los requisitos han cambiado durante el proceso de desarrollo. Por ejemplo, aquí hay una solicitud de fusión real que me llegó para una revisión hace dos semanas:
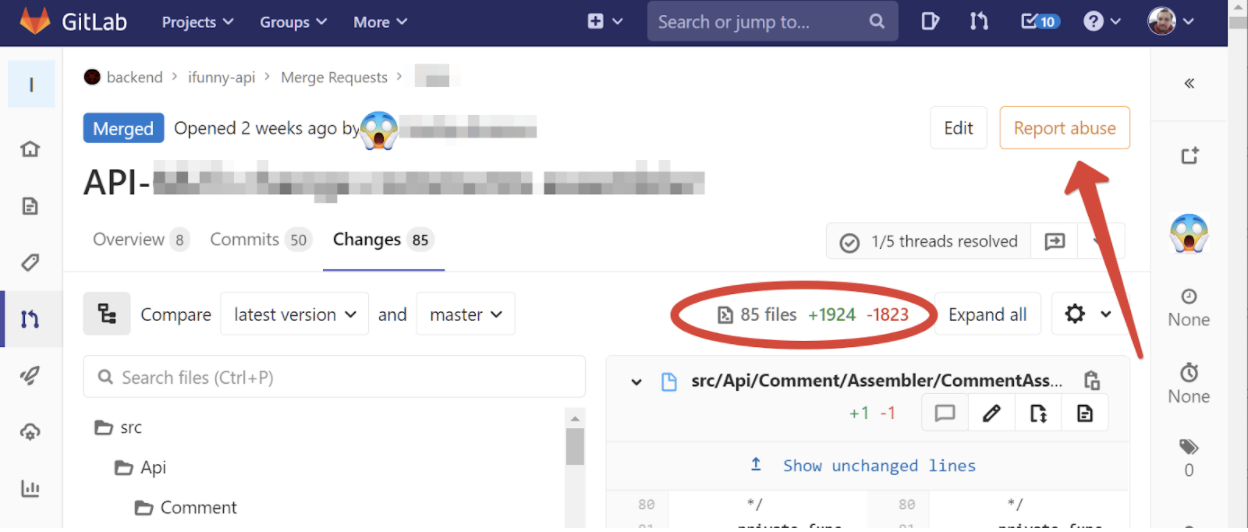
Mi mano alcanzó automáticamente el botón "Informar abuso", porque ¿de qué otra manera se puede caracterizar una solicitud con 50 confirmaciones con casi 2000 líneas cambiadas? ¿Y cómo, uno se pregunta, revisarlo?
Para ser honesto, me tomó dos días solo forzarme a comenzar esta revisión. Y esta es una reacción normal para un ingeniero; alguien en una situación similar, solo sin mirar, presiona Aprobar, dándose cuenta de que en un tiempo razonable aún no podrá hacer el trabajo de revisar este cambio con suficiente calidad.
Pero hay una manera de facilitarle la vida a un amigo. Además del trabajo preliminar para una mejor descomposición del problema, después de completar la escritura del código principal, puede traer el historial de su escritura en una forma más lógica, dividiéndolo en confirmaciones atómicas con pruebas verdes en cada una: "creó un nuevo servicio y una capa de transporte para él", "construyó modelos y escribió comprobación de invariantes "," validación añadida y manejo de excepciones "," pruebas escritas ".
Cada una de estas confirmaciones se puede revisar por separado (tanto GitHub como GitLab pueden hacer esto) y hacerlo en redadas al cambiar entre tareas o en descansos.
El mismo
git rebasecon la llave nos ayudará a hacer todo esto --interactive. Como parámetro, debe pasarle el hash de la confirmación, a partir del cual deberá volver a escribir el historial. Si estamos hablando de las últimas 50 confirmaciones, como en el ejemplo de la imagen, puede escribir git rebase --interactive HEAD~50(sustituya su número por “50”).
Por cierto, si se agregó la rama maestra en el proceso de trabajar en una tarea, primero deberá volver a establecer la base de esta rama para que las confirmaciones de fusión y las confirmaciones del maestro no se confundan bajo sus pies.
Armado con el conocimiento de los aspectos internos de un repositorio de git, debería ser fácil comprender cómo funciona rebase en master. Este comando toma todas las confirmaciones en nuestra rama y cambia el padre de la primera a la última confirmación en la rama maestra. Ver diagrama: las
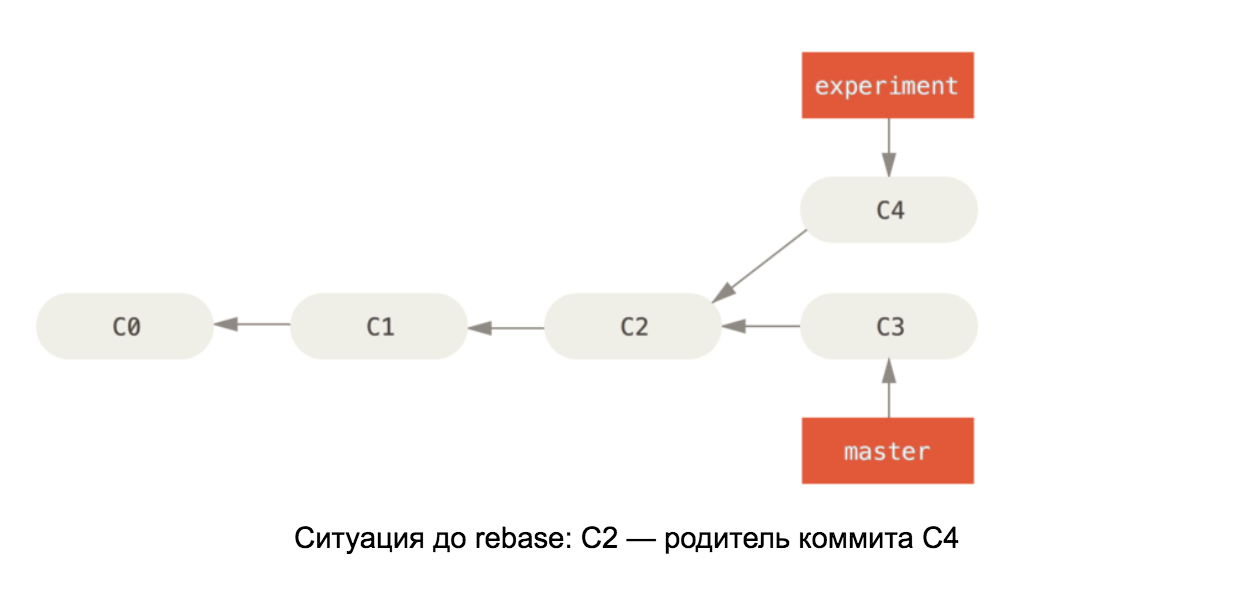
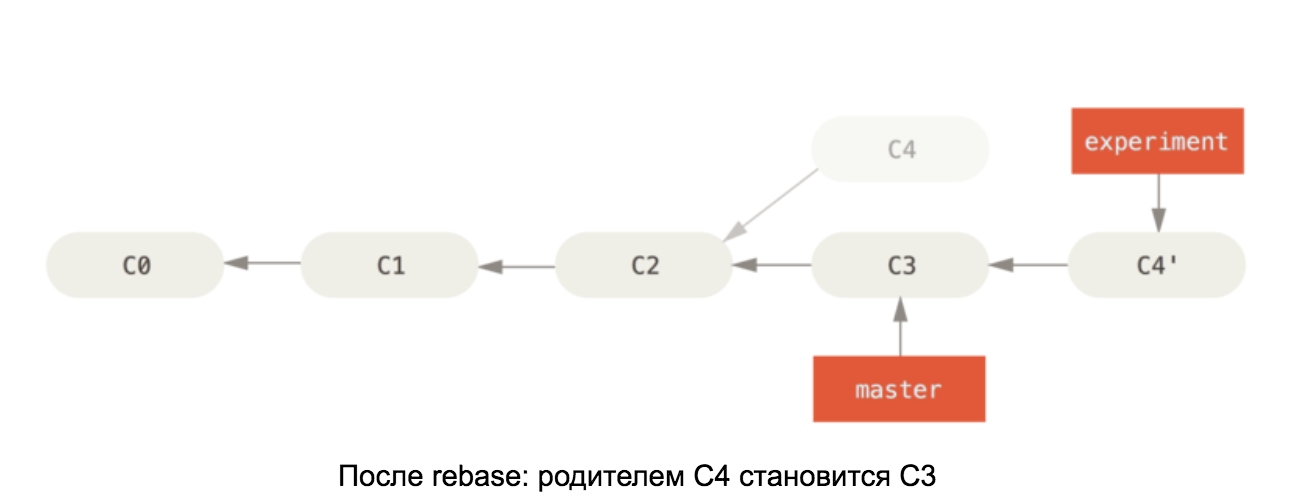
ilustraciones se han tomado del libro Pro Git
Si los cambios en C4 y C3 entran en conflicto, después de que se resuelva el conflicto, la confirmación C4 cambiará su contenido, por lo que en el segundo diagrama se cambia el nombre a C4 '.
De esta manera, terminará con una rama que consta solo de sus cambios y que crece desde la parte superior del maestro. Por supuesto, el maestro debe estar actualizado. Puede usar la versión del servidor:
git pull --rebase origin/master(como sabe, es git pullequivalente git fetch && git merge, y la clave --rebaseforzará a git a reabastecerse en lugar de fusionarse).
Finalmente volvamos a
git rebase --interactive... Fue hecho por programadores para programadores, y al darnos cuenta del estrés que experimentará la gente en el proceso, tratamos de preservar los nervios del usuario tanto como fuera posible y evitarlo de la necesidad de esforzarse demasiado. Esto es lo que verá en la pantalla:
Este es el repositorio del popular paquete Guzzle. Parece que le vendría bien una rebase ...
El archivo generado se abre en un editor de texto. A continuación, encontrará información detallada sobre qué hacer aquí. A continuación, en el modo de edición simple, decides qué hacer con las confirmaciones en tu rama. Todo es tan simple como un palo: elegir - dejarlo como está, volver a redactar - cambiar la descripción de confirmación, aplastar - fusionar con el anterior (el proceso funciona de abajo hacia arriba, es decir, el anterior es la línea de abajo), soltar - eliminar por completo, editar - y esto es lo interesante es detenerse y congelarse. Después de que git encuentra el comando de edición, tomará la posición donde los cambios en la confirmación ya se han agregado al modo por etapas. Puede cambiar cualquier cosa en esta confirmación, agregar algunas más encima y luego ordenar
git rebase --continuepara continuar el proceso de rebase.
Ah, y por cierto, puedes intercambiar confirmaciones. Esto puede crear conflictos, pero en general, el proceso de rebase rara vez está completamente libre de conflictos. Como dicen, habiéndoseles quitado la cabeza, no lloran por su cabello.
Si te confundes y parece que todo se ha ido, tienes un botón de expulsión de emergencia
git rebase --abortque inmediatamente devolverá todo a lo que era.
Puede repetir el rebase varias veces, tocando solo partes de la historia y dejando el resto intacto con el pico, dando a su historia un aspecto cada vez más acabado, como un alfarero a un lanzador. Es una buena práctica, como escribí anteriormente, asegurarse de que las pruebas en cada confirmación sean verdes (para esto, editar ayuda mucho y en la siguiente pasada, aplastar).
Otra acrobacia aérea, útil en caso de que necesite descomponer varios cambios en el mismo archivo en diferentes confirmaciones -
git add --patch. Puede ser útil por sí solo, pero en combinación con la directiva de edición, le permitirá dividir una confirmación en varias, y hacerlo a nivel de líneas individuales, lo que, si no me equivoco, ningún cliente GUI ni IDE no lo permite.
De nuevo asegurándose de que todo está en orden, puede finalmente con tranquilidad a hacer algo, lo que comenzó este tutorial:
git push --force. ¡Oh, claro que sí --force-with-lease!

Al principio, lo más probable es que dedique una hora a este proceso (incluido el rebase inicial en el maestro), o incluso dos si la función es realmente amplia. Pero incluso esto es mucho mejor que esperar dos días para que el revisor se obligue a sí mismo a aceptar finalmente su solicitud, y un par de días más hasta que la complete. En el futuro, lo más probable es que entre 30 y 40 minutos. Los productos IntelliJ con herramienta de resolución de conflictos incorporada (divulgación completa: FunCorp paga por estos productos a sus empleados) son especialmente útiles en esto.
Lo último que quiero advertirle es que no vuelva a escribir el historial de la rama durante la revisión del código. Recuerde que un revisor concienzudo puede clonar su código localmente para poder verlo a través del IDE y ejecutar pruebas.
¡Gracias a todos los que leyeron hasta el final! Espero que el artículo sea útil no solo para usted, sino también para los colegas que reciben su código para su revisión. Si tienes algunos trucos geniales para git, ¡compártelos en los comentarios!