
Desde la invención de su primera GPU en 1999, NVIDIA ha estado a la vanguardia de los gráficos 3D y la computación acelerada por GPU. Cada arquitectura de NVIDIA está cuidadosamente diseñada para ofrecer niveles revolucionarios de rendimiento y eficiencia.
La A100, la primera GPU con arquitectura NVIDIA Ampere, se lanzó en mayo de 2020. Proporciona una tremenda aceleración para el entrenamiento de IA, HPC y análisis de datos. El A100 se basa en el chip GA100, que es puramente computacional y, a diferencia del GA102, todavía no es un juego.
Las GPU GA10x se basan en la arquitectura de GPU NVIDIA Turing. Turing es la primera arquitectura del mundo que ofrece trazado de rayos en tiempo real de alto rendimiento, gráficos acelerados por IA y renderizado de gráficos profesionales, todo en un solo dispositivo.
En este artículo analizaremos los principales cambios en la arquitectura de las nuevas tarjetas de video NVIDIA en comparación con su predecesora.

Figura 1. Arquitectura Ampere GA10x
Características principales de GA102
GA102 está fabricado con tecnología patentada de NVIDIA de 8 nm: 8N NVIDIA Custom. El chip contiene 28,3 mil millones de transistores en un dado de 628,4 mm2. Como ocurre con todas las GeForce RTX, la GA102 se basa en un procesador que contiene tres tipos diferentes de recursos informáticos:
- Núcleos CUDA para sombreado programable;
- RT-, (BVH) ;
- , .
Ampere
GPC, TPC SM
Al igual que sus predecesores, el GA102 consta de grupos de procesamiento de gráficos (GPC), grupos de procesamiento de texturas (TPC), multiprocesadores de transmisión (SM), unidades de rasterización de operador de ráster (ROP) y controladores de memoria. El chip completo tiene siete unidades GPC, 42 TPC y 84 SM.
El GPC es el bloque de alto nivel dominante que contiene todos los gráficos clave. Cada GPC tiene un motor de ráster dedicado y ahora también tiene dos secciones ROP de ocho bloques cada una, lo cual es una innovación en la arquitectura Ampere. Además, el GPC contiene seis TPC, cada uno con dos multiprocesadores y un motor PolyMorph.
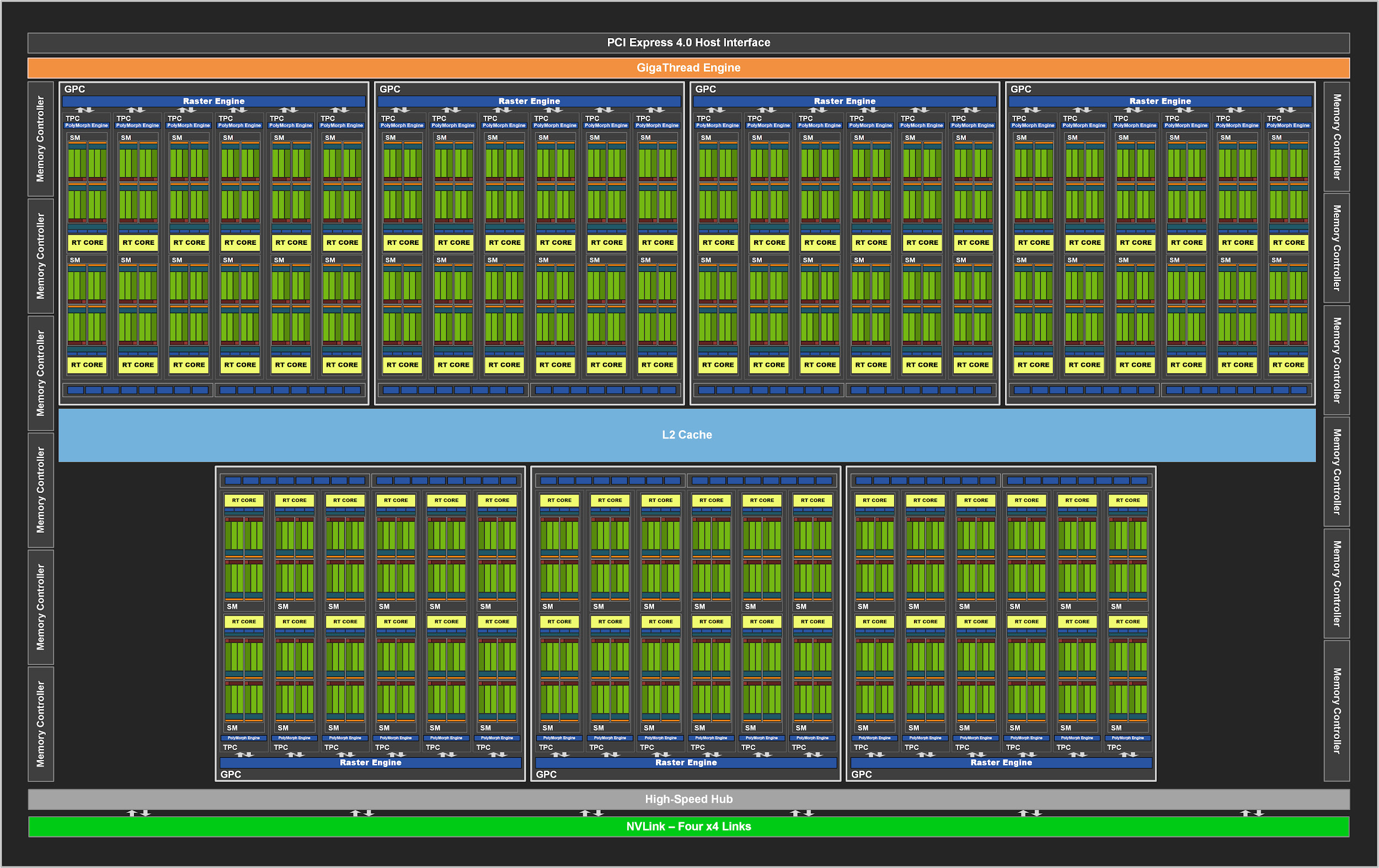
Figura 2. GPU GA102 completa con 84 bloques SM
A su vez, cada SM en el GA10x contiene 128 núcleos CUDA, cuatro núcleos Tensor de la tercera generación, un archivo de registro de 256 KB, cuatro unidades de textura, un núcleo de trazado de rayos de la segunda generación y 128 KB L1 / memoria compartida, que se pueden configurar para diferentes capacidades. dependiendo de las necesidades de las tareas informáticas o gráficas.
Optimización de ROP
En las GPU NVIDIA anteriores, los ROP estaban vinculados a un controlador de memoria y una caché L2. A partir de GA10x, son parte del GPC, que mejora el rendimiento de la trama al aumentar el número total de ROP.
En total, con siete GPC y 16 ROP en cada GPC, la GPU GA102 consta de 112 ROP en lugar de 96, por ejemplo, en el TU102. Todo esto tiene un efecto positivo en el suavizado multimuestra, la tasa de relleno de píxeles y la combinación.
NVLink de tercera generación
Las GPU GA102 son compatibles con la interfaz NVIDIA NVLink de tercera generación, que incluye cuatro carriles x4, cada uno de los cuales proporciona 14.0625 GB / s de ancho de banda entre dos GPU en cualquier dirección. Los cuatro canales juntos dan 56,25 GB / s de ancho de banda en cada dirección y 112,5 GB / s en general entre las dos GPU. Entonces, usando NVLink, puede conectar dos GPU RTX 3090.
PCIe Gen 4
Las GPU GA10x están equipadas con PCI Express 4.0, que ofrece el doble de ancho de banda que PCIe 3.0, velocidades de transferencia de hasta 16G Transferencias por segundo y, gracias a la ranura x16 PCIe 4.0, el ancho de banda máximo alcanza los 64GB / s.
Arquitectura multiprocesador GA10x
La arquitectura de multiprocesador de Turing fue la primera en NVIDIA en tener núcleos separados para acelerar las operaciones de trazado de rayos. Luego, Volta introdujo los primeros núcleos tensoriales y Turing introdujo los núcleos tensoriales avanzados de segunda generación. Otra innovación en Turing y Volta es la capacidad de ejecutar simultáneamente operaciones FP32 e INT32. El multiprocesador en GA10x es compatible con todas las funciones anteriores y también tiene varias mejoras propias.
A diferencia del TU102, que tiene ocho núcleos tensores de segunda generación, el multiprocesador GA10x tiene cuatro núcleos tensoriales de tercera generación, con cada núcleo tensor GA10x dos veces más poderoso que Turing.
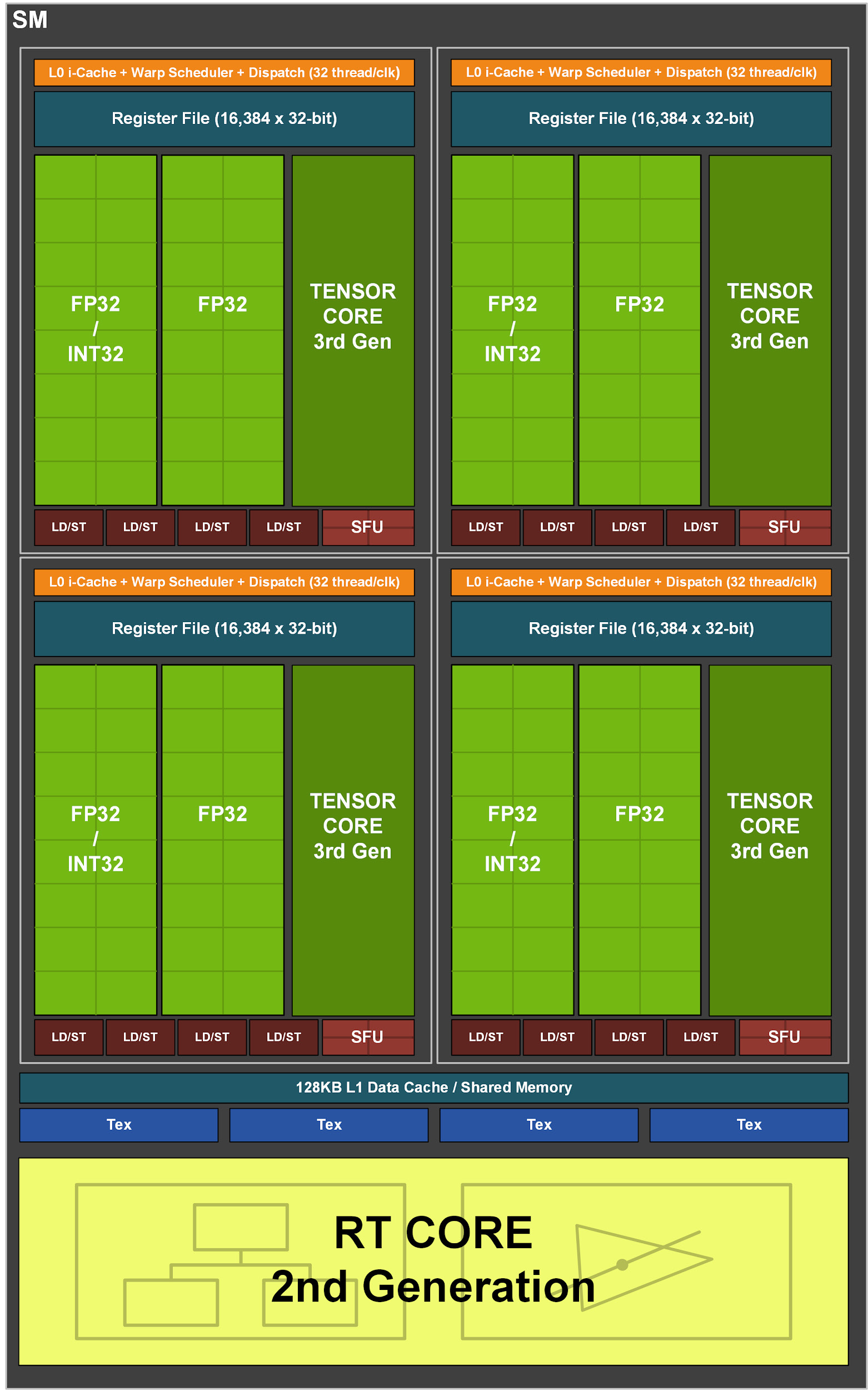
Figura 3. Multiprocesador de transmisión GA10x
Duplica la velocidad de la computación FP32
La mayoría de los cálculos gráficos son operaciones de coma flotante de 32 bits (FP32). El multiprocesador de transmisión Ampere GA10x ofrece el doble de velocidad que las operaciones del FP32 en ambos canales de datos. Como resultado, en el contexto de FP32, la GeForce RTX 3090 proporciona más de 35 teraflops, que es más del doble de las capacidades de Turing.
El GA10X puede ejecutar 128 operaciones FP32 o 64 operaciones FP32 y 64 operaciones INT32 por reloj, que es el doble de la velocidad de los cálculos de Turing.
Las tareas de juego modernas tienen una amplia gama de necesidades de procesamiento. Muchos cálculos requieren un montón de operaciones FP32 (como FFMA, suma de punto flotante (FADD) o multiplicación de punto flotante (FMUL)), así como muchos cálculos enteros más simples.
Los multiprocesadores GA10x continúan admitiendo operaciones FP16 de doble velocidad (HFMA), que también eran compatibles con Turing. Y, de forma similar a las GPU TU102, TU104 y TU106, en la GA10x, las operaciones FP16 estándar también se manejan mediante núcleos tensoriales.
Memoria compartida y caché de datos L1
GA10x tiene una arquitectura unificada para memoria compartida, caché de datos L1 y caché de texturas. Este diseño unificado se puede modificar según la carga de trabajo y las necesidades.
El chip GA102 contiene 10,752 KB de caché L1 (en comparación con 6912 KB en el TU102). Aparte de esto, el GA10x también tiene el doble del ancho de banda de memoria compartida de Turing (128 bytes / ciclo frente a 64 bytes / ciclo). El ancho de banda L1 total para la GeForce RTX 3080 es de 219 GB / s frente a los 116 GB / s de la GeForce RTX 2080 Super.
Rendimiento por vatio
Todas las arquitecturas de NVIDIA Ampere están diseñadas para mejorar la eficiencia, desde la lógica, la memoria, la gestión de energía y térmica hasta el diseño de PCB, software y algoritmos. Al mismo nivel de rendimiento, las GPU Ampere son hasta 1,9 veces más eficientes en energía que los dispositivos Turing comparables.
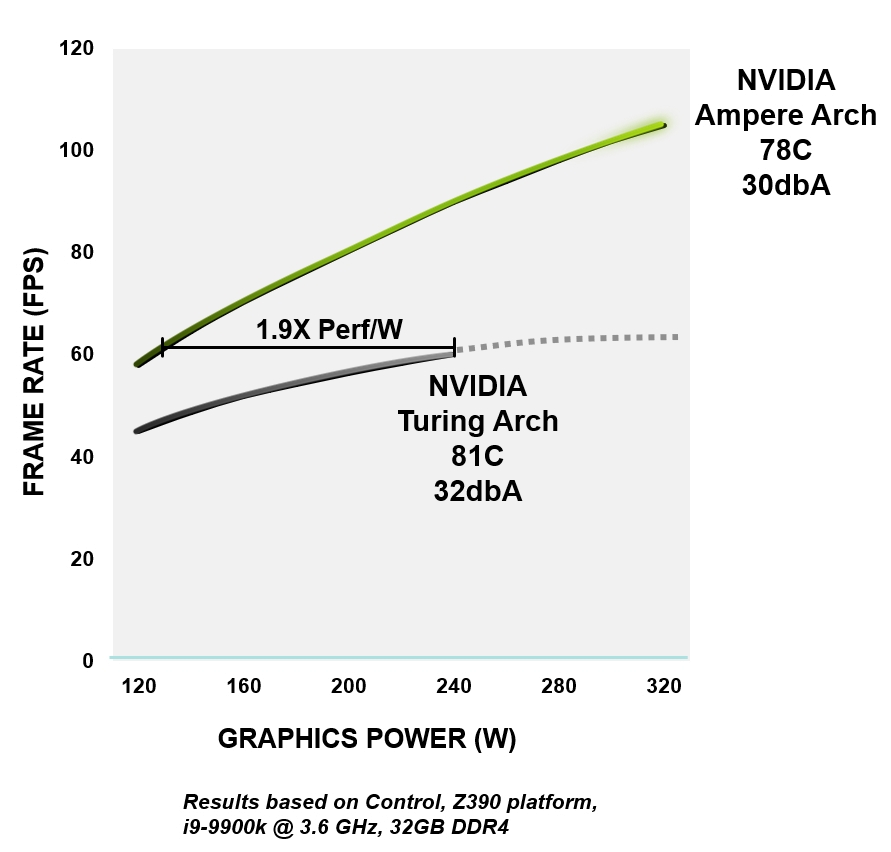
Figura 4. Eficiencia energética de RTX 3080 versus arquitectura GeForce RTX 2080 Super
Núcleos RT de segunda generación
Los nuevos núcleos RT cuentan con una serie de mejoras que, cuando se combinan con los sistemas de almacenamiento en caché actualizados, duplican efectivamente el rendimiento del trazado de rayos de los procesadores Ampere sobre Turing. Además, el GA10x permite que otros procesos se ejecuten simultáneamente con la computación RT, lo que acelera significativamente muchas tareas.
Trazado de rayos de segunda generación en GA10x
Las GeForce RTX basadas en la arquitectura de Turing fueron las primeras GPU con las que el trazado de rayos cinematográfico se convirtió en una realidad en los juegos de PC. El GA10x está equipado con tecnología de trazado de rayos de segunda generación. Al igual que Turing, los multiprocesadores del GA10x tienen bloques de hardware especializados para verificar si hay intersecciones de rayos con BVH y triángulos. Al mismo tiempo, los núcleos de los multiprocesadores Ampere tienen el doble de velocidad para probar la intersección de rayos y triángulos en comparación con Turing.
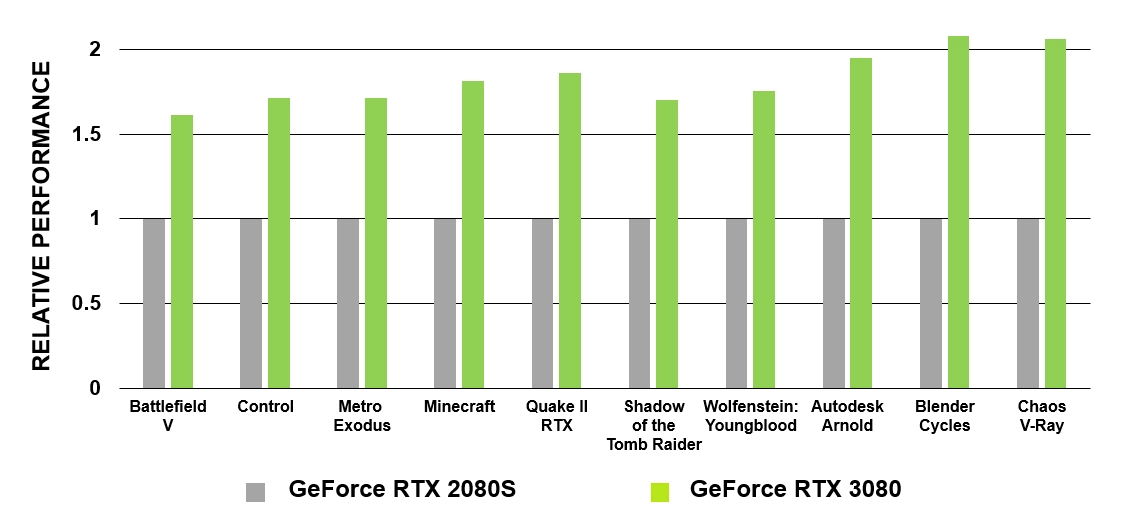
Figura 5. Comparación del rendimiento de los núcleos RT de GeForce RTX 3080 y GeForce RTX 2080 Super
El multiprocesador GA10x puede realizar operaciones simultáneamente y no se limita a cómputo y gráficos, como era el caso en generaciones anteriores de GPU. Entonces, por ejemplo, en el GA10x, el algoritmo de reducción de ruido se puede ejecutar simultáneamente con el trazado de rayos.

Figura 6. Núcleo RT de segunda generación en GPU GA10x
Tenga en cuenta que las cargas de trabajo intensivas en RT no aumentan significativamente la carga en los núcleos multiprocesador, lo que permite que la potencia de procesamiento del multiprocesador se utilice para otras tareas. Esta es una gran ventaja sobre otras arquitecturas de la competencia que no tienen núcleos RT dedicados y, por lo tanto, tienen que usar sus componentes básicos tanto para gráficos como para trazado de rayos.
Procesadores Ampere RTX en acción
El trazado de rayos y los sombreadores son intensivos en computación. Pero sería mucho más caro ejecutar todo solo con núcleos CUDA, por lo que incluir núcleos tensores y RT ayuda a acelerar el procesamiento de manera significativa. La Figura 7 muestra un ejemplo de Wolfenstein: Youngblood con trazado de rayos habilitado en varios escenarios.
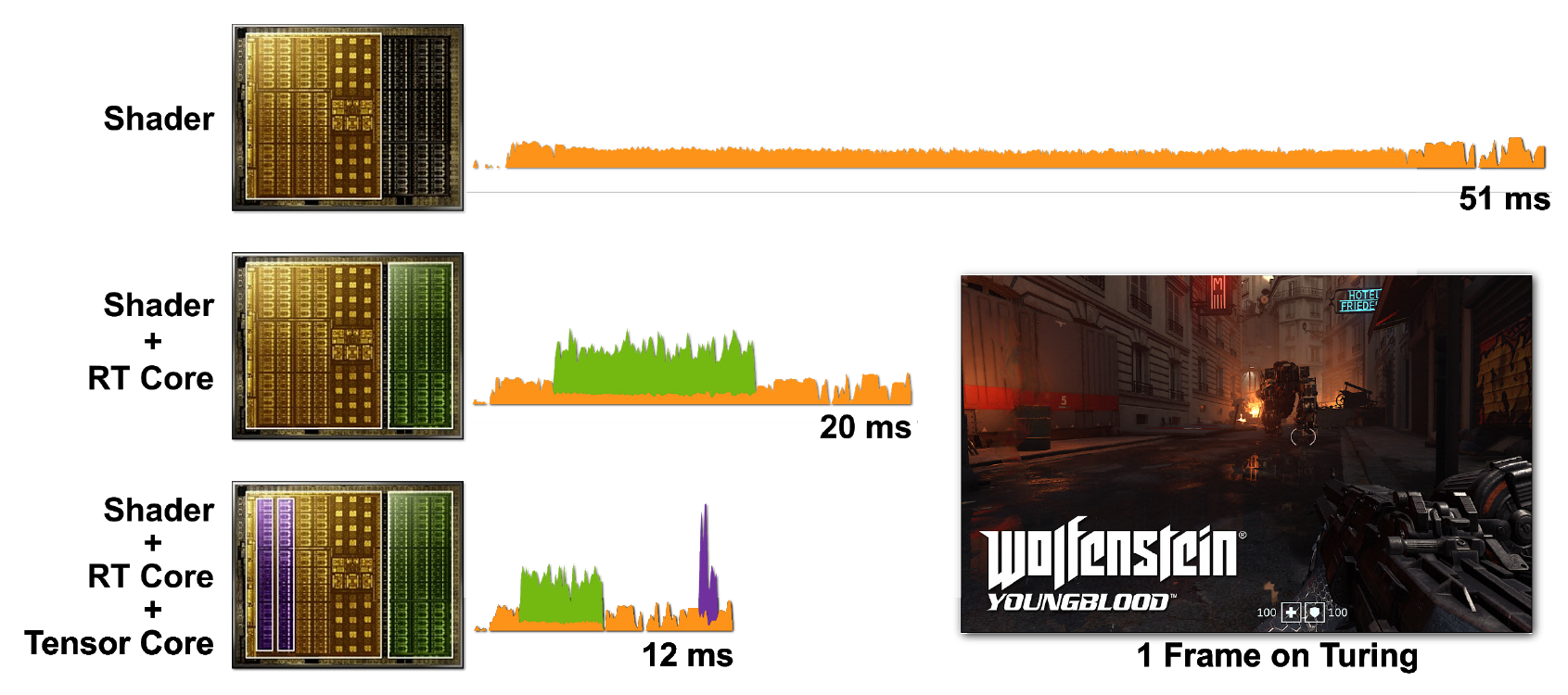
Figura 7. Representación de un solo fotograma de Wolfenstein: Youngblood en una Super GPU RTX 2080 usando a) núcleos shader (CUDA), b) núcleos shader y núcleos RT, c) núcleos shader, núcleos tensores y núcleos RT. Tenga en cuenta los tiempos de fotogramas que disminuyen progresivamente a medida que agrega la potencia de los distintos núcleos del procesador RTX.
En el primer caso, se necesitan 51 ms (~ 20 fps) para iniciar un cuadro. Cuando se activan los núcleos RT, el fotograma se procesa mucho más rápido, en 20 ms (50 fps). El uso de DLSS en núcleos tensoriales reduce el tiempo de fotograma a 12 ms (~ 83 fps).
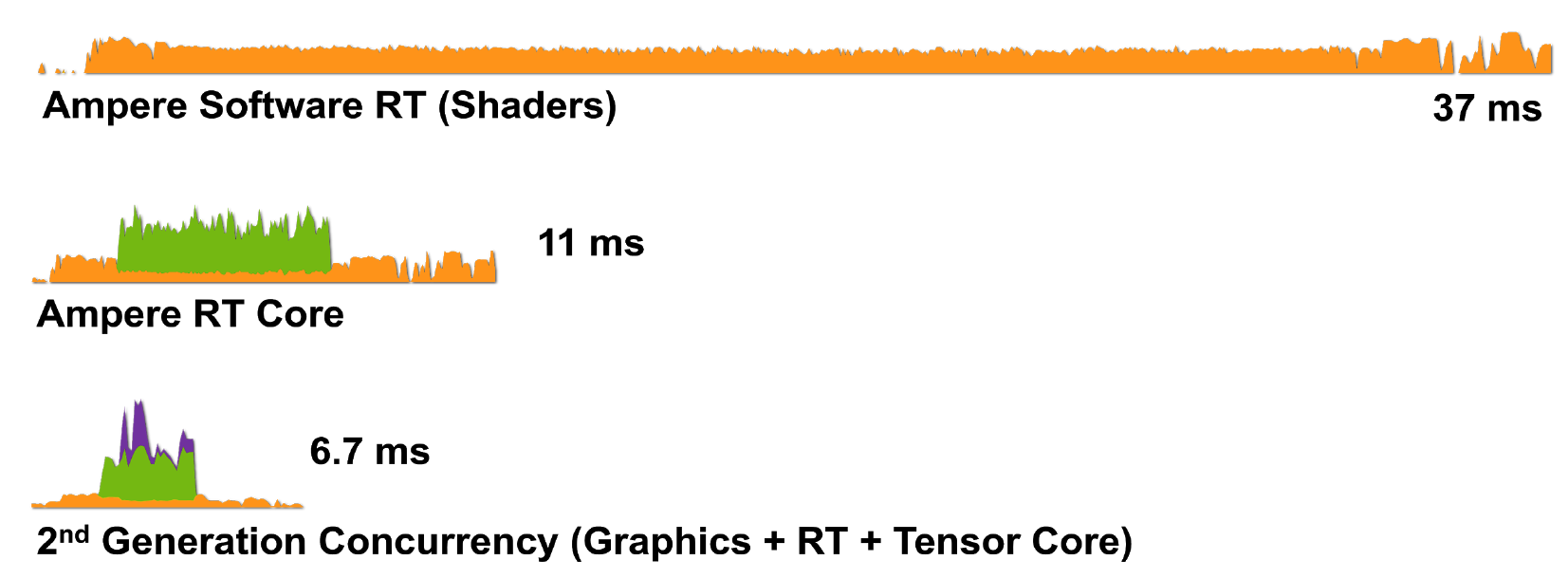
Figura 8. Representación de un solo fotograma de Wolfenstein: Youngblood en un RTX 3080 utilizando a) núcleos de sombreado (CUDA), b) núcleos de sombreado y núcleos de RT, c) núcleos de sombreado, tensor y núcleos de RT.
Por lo tanto, la tecnología RTX con arquitectura Ampere es aún más eficiente en el manejo de tareas de renderizado: el RTX 3080 renderiza un fotograma en 6.7 ms (150 fps), lo cual es una gran mejora con respecto al RTX 2080.
Trazado de rayos acelerado por hardware mediante el desenfoque de movimiento
El desenfoque de movimiento es un movimiento que se usa a menudo en gráficos por computadora. Una imagen fotográfica no se crea instantáneamente, sino exponiendo la película a la luz durante un período de tiempo limitado. Los sujetos que se muevan lo suficientemente rápido en comparación con el tiempo de exposición de la cámara aparecerán en la foto como rayas o puntos. Para que la GPU cree un desenfoque de movimiento de aspecto realista cuando los objetos de una escena se mueven rápidamente frente a una cámara estática, debe poder simular cómo funcionan la cámara y la película con tales escenas. El desenfoque de movimiento es especialmente importante en la realización de películas porque las películas se reproducen a 24 fotogramas por segundo y una escena sin desenfoque de movimiento aparecerá nítida y entrecortada.
Las GPU de Turing hacen un buen trabajo acelerando el desenfoque de movimiento en general. Sin embargo, en el caso de la geometría en movimiento, la tarea puede resultar más difícil, ya que la información sobre el BVH cambia con la posición de los objetos en el espacio.
Como puede ver en la Figura 9, el núcleo de Turing RT realiza un recorrido por hardware de la jerarquía BVH, verificando la intersección de rayos con BBox y triángulos. El GA10x puede hacer todo lo mismo, pero además tiene un nuevo bloque Interpolate Triangle Position, que acelera el desenfoque de movimiento en el trazado de rayos.
Tanto los núcleos Turing como los GA10x RT implementan la arquitectura MIMD (Multiple Instruction Multiple Data), que permite procesar múltiples haces simultáneamente.
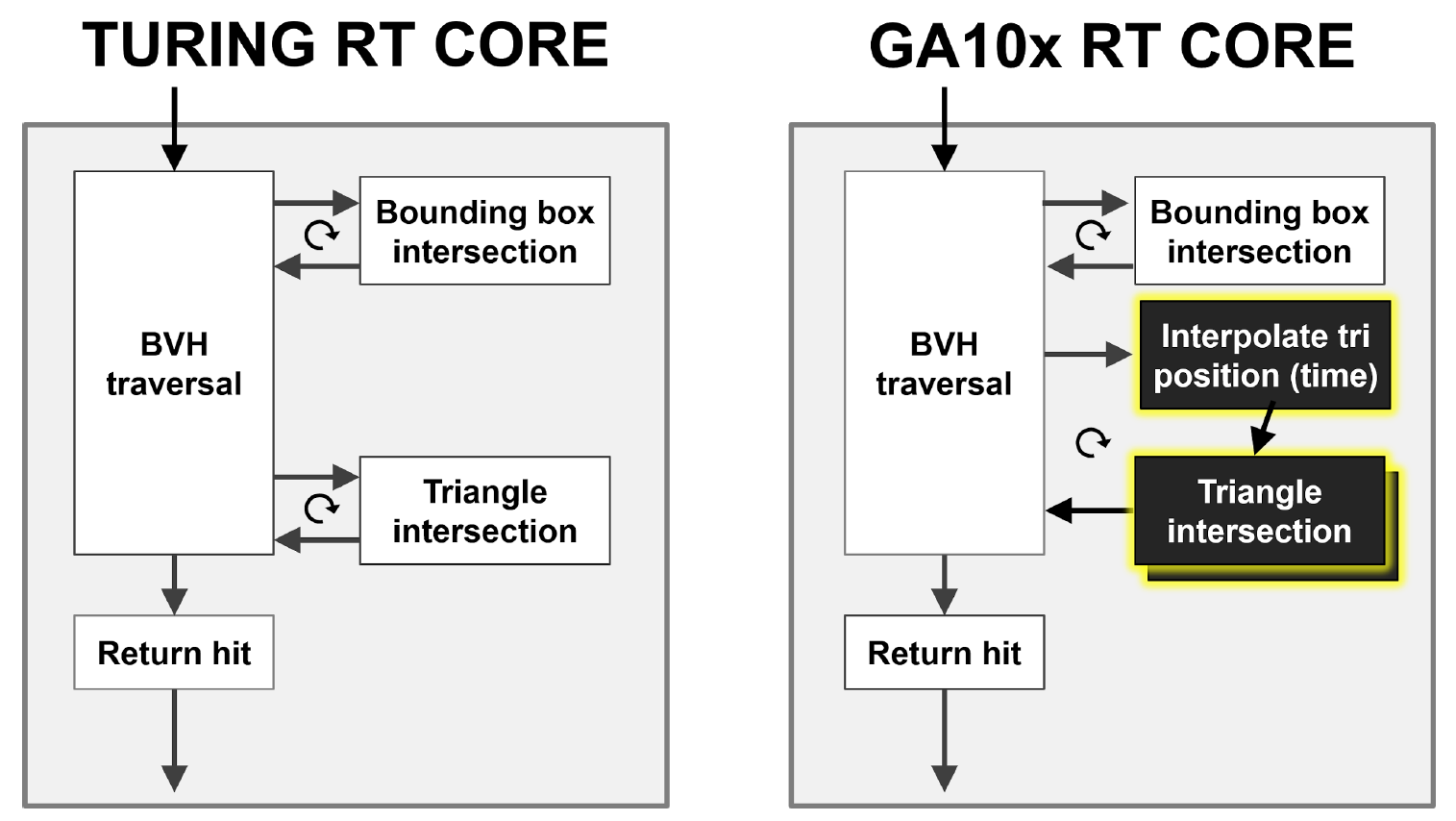
Figura 9. Comparación de la aceleración por hardware del desenfoque de movimiento en el caso de Turing y Ampere
El principal problema con el desenfoque de movimiento es que los triángulos de la escena no están fijos en el tiempo. En el trazado de rayos básico, se realizan pruebas de intersección estática y, cuando un rayo golpea un triángulo, devuelve información sobre ese golpe. Como se muestra en la Figura 10, con el desenfoque de movimiento, ninguno de los triángulos tiene coordenadas fijas. Cada rayo tiene una marca de tiempo para indicar su tiempo de seguimiento, y la posición del triángulo y la intersección del rayo se determinan a partir de la ecuación BVH.
Si este proceso no es acelerado por hardware, puede causar muchos problemas, incluso debido a su no linealidad.
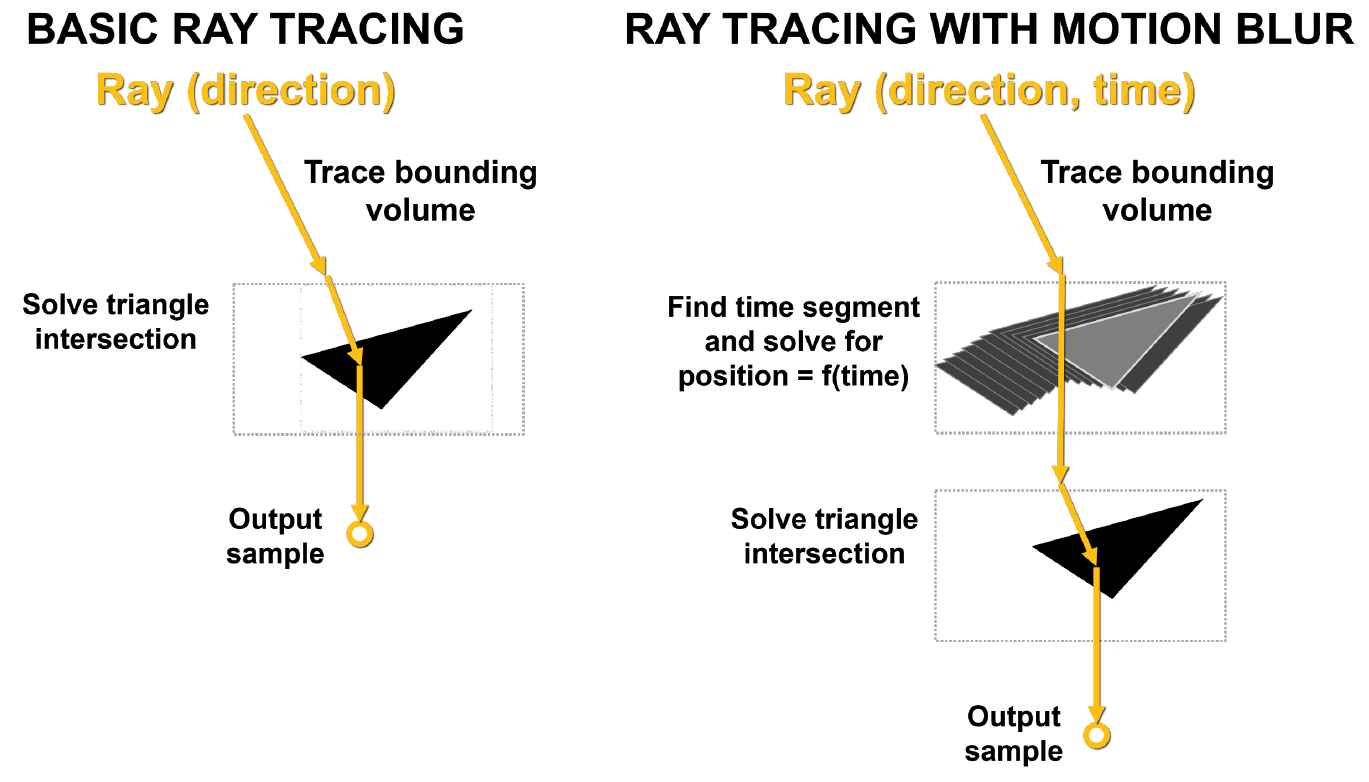
Dibujo. 10. Trazado de rayos básico y trazado de rayos con desenfoque de movimiento
En el lado izquierdo de la Figura 11, los rayos enviados a una escena estática golpean el mismo triángulo al mismo tiempo. Los puntos blancos muestran el lugar del impacto, este resultado se devuelve. En el caso del desenfoque de movimiento, cada rayo existe en su propio momento en el tiempo. A cada haz se le asigna aleatoriamente una marca de tiempo diferente. Por ejemplo, los rayos naranjas intentan cruzar los triángulos naranjas al mismo tiempo, y luego los rayos verde y azul hacen lo mismo. Al final, las muestras se mezclan, produciendo un resultado borroso más matemáticamente correcto.
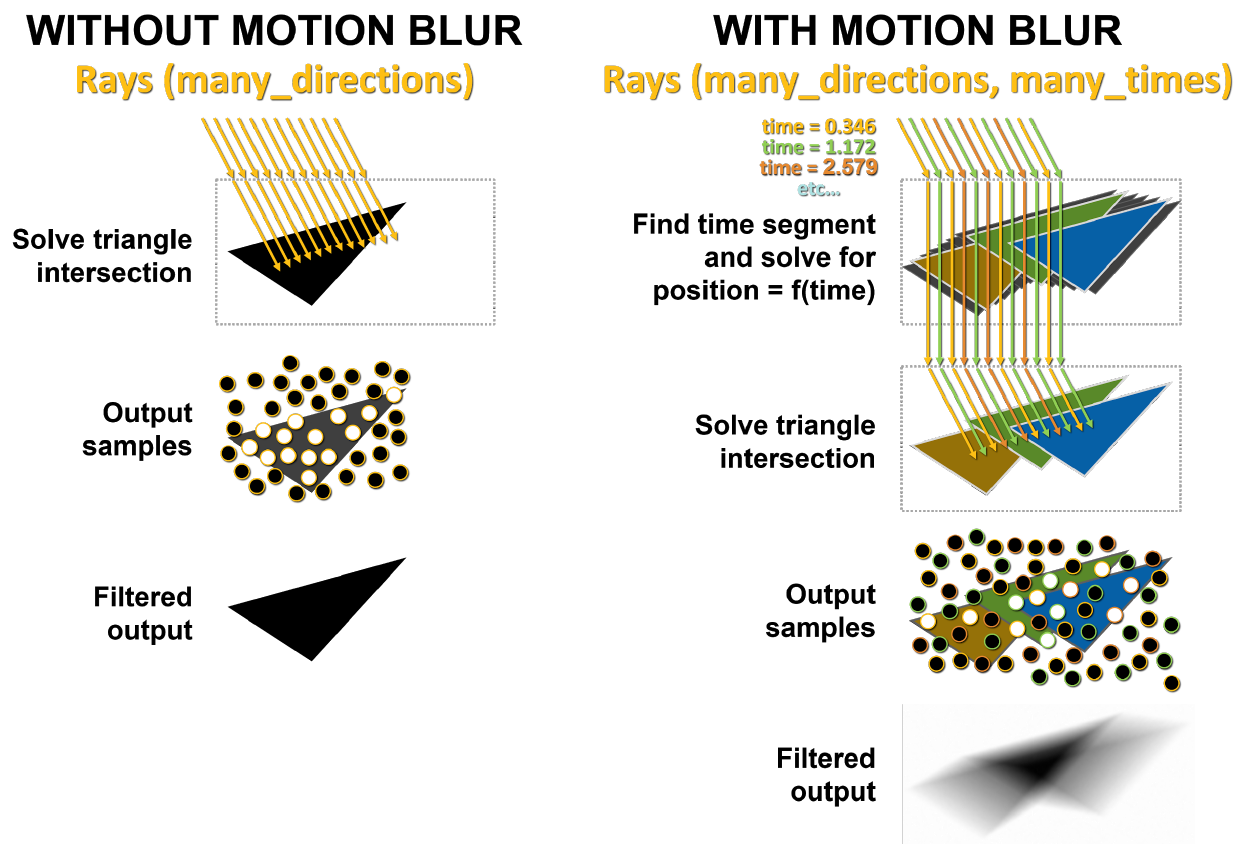
Figura 11. Renderizado sin desenfoque de movimiento y con desenfoque en GA10x
El bloque Interpolate Triangle Position interpola los triángulos en BVH entre los triángulos ya existentes en función del movimiento del objeto, de modo que los rayos los intersecarán en las ubicaciones esperadas en los momentos especificados por las marcas de tiempo de los rayos. Este enfoque permite una representación precisa del desenfoque de movimiento con trazado de rayos hasta ocho veces más rápido que Turing.
El desenfoque de movimiento acelerado por hardware GA10x es compatible con Blender 2.90, Chaos V-Ray 5.0, Autodesk Arnold y Redshift Renderer 3.0.X mediante la API de NVIDIA OptiX 7.0.
La velocidad de renderizado del desenfoque de movimiento es hasta 5 veces más rápida en el RTX 3080 en comparación con el RTX 2080 Super.
Núcleos de tensor de tercera generación en GPU GA10x
El GA10x incluye nuevos núcleos tensores NVIDIA de tercera generación, que ofrecen compatibilidad con nuevos tipos de datos, rendimiento mejorado, eficiencia y flexibilidad de programación. La nueva característica de escasez duplica el rendimiento de Tensor Cores sobre la generación anterior de Turing. Las funciones de IA como NVIDIA DLSS para superresolución de IA (ahora con soporte 8K), NVIDIA Broadcast para procesamiento de voz y video y NVIDIA Canvas para dibujar también son más rápidas.
Los núcleos tensoriales son unidades de ejecución especializadas diseñadas para realizar operaciones de tensor / matriz, la principal función computacional en el aprendizaje profundo. Son necesarios para mejorar la calidad de los gráficos con DLSS (Deep Learning Super Sampling), reducción de ruido basada en IA, eliminación del ruido de fondo dentro de los chats de voz en el juego usando RTX Voice y muchas más aplicaciones.
La introducción de Tensor Cores en las GPU de juegos GeForce ha permitido el aprendizaje profundo en tiempo real en aplicaciones de juegos por primera vez. El diseño del núcleo tensorial de tercera generación en las GPU GA10x aumenta aún más el rendimiento sin procesar y aprovecha los nuevos modos de precisión computacional como TF32 y BFloat16. Esto juega un papel importante en las aplicaciones de servicios neuronales NVIDIA NGX basadas en IA para mejorar los gráficos, la representación y otras características.
Comparación de núcleos tensores de Turing y amperios
Ampere Tensor Cores se han reorganizado en Turing para mejorar la eficiencia y reducir el consumo de energía. La arquitectura del núcleo de Ampere SM tiene menos núcleos tensoriales, pero cada uno es más poderoso.
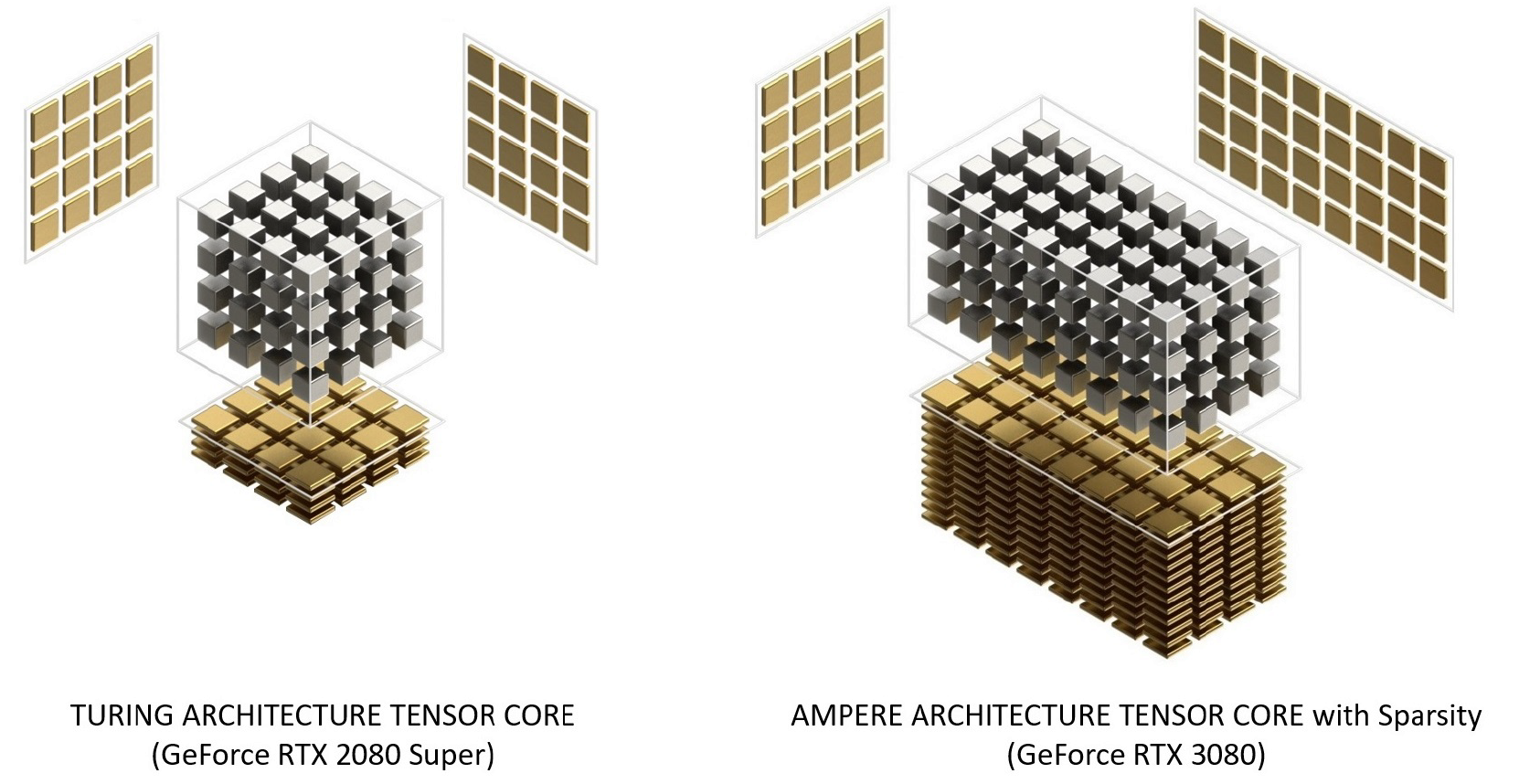
Figura 12. Núcleos tensoriales con arquitectura Turing y Ampere. GeForce RTX 3080 ofrece un ancho de banda máximo de FP16 Tensor Core 2.7 veces más rápido que GeForce RTX 2080 Super
Escasa estructura de grano fino
Con la GPU A100, NVIDIA presenta la dispersión estructurada de grano fino, un nuevo enfoque para duplicar el ancho de banda computacional para redes neuronales profundas. Esta función también es compatible con las GPU GA10x y ayuda a acelerar algunas operaciones de representación de gráficos basadas en IA.
Dado que las redes de aprendizaje profundo pueden adaptar pesos a través del aprendizaje por retroalimentación, en general, las restricciones estructurales no afectan la precisión de los modelos entrenados.
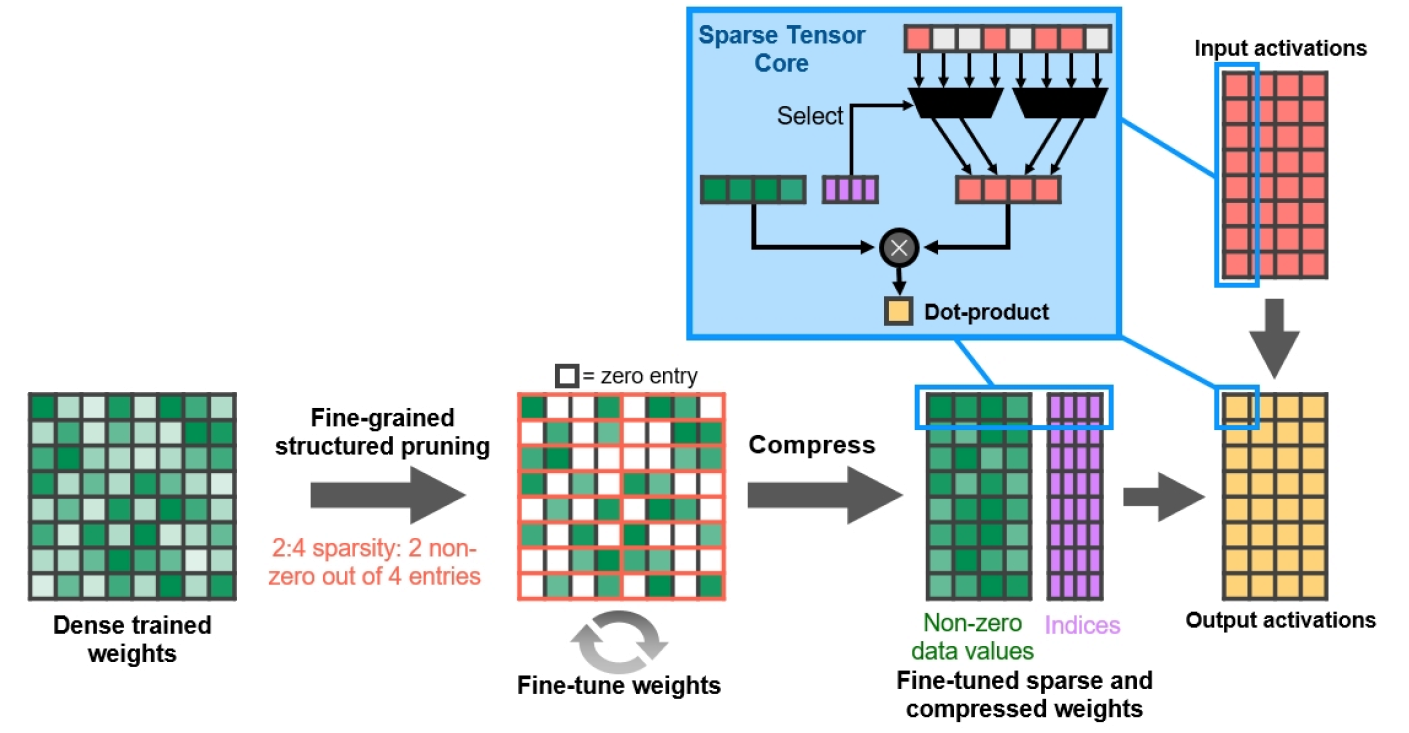
Figura 13. Esparcimiento estructurado de grano fino
NVIDIA ha desarrollado un algoritmo de dispersión de redes neuronales profundas simple y versátil que utiliza un patrón de dispersión estructurado 2: 4. La red se entrena primero con pesos densos, luego se produce la poda estructurada de grano fino, después de lo cual se pueden descartar los valores cero y se comprimen las matemáticas restantes para aumentar el rendimiento. El algoritmo no afecta la precisión de la red entrenada para la inferencia, solo la acelera.
NVIDIA DLSS 8K
Procesar una imagen con trazado de rayos a una alta velocidad de fotogramas es extremadamente costoso computacionalmente. Antes de la llegada de NVIDIA Turing, se creía que su implementación llevaría años. Para ayudar a resolver este problema, NVIDIA ha creado Deep Learning Supersampling (DLSS).

Figura 14. Watch Dogs: Legion con DLSS a 1080p, 4K y 8K. Tenga en cuenta que el texto más nítido y los detalles proporcionados por DLSS en 8K
DLSS solo están mejorando en NVIDIA Ampere mediante el uso de núcleos tensores de tercera generación y un factor de escala de superresolución 9x, que por primera vez hace posible ejecutar un juego con trazado de rayos a 8K a 60 fps.
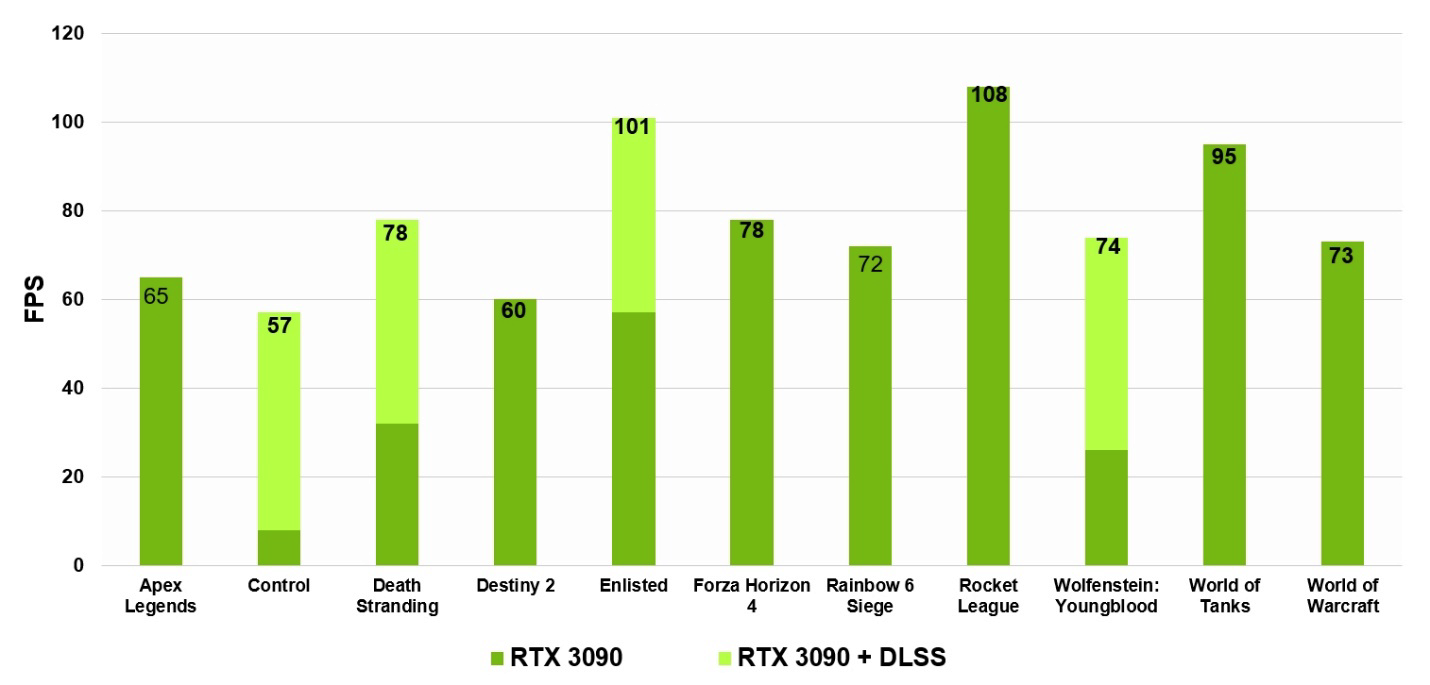
15. GeForce RTX 3090 60 fps 8K DLSS . , . Core i9-10900K
GDDR6X
Los juegos de PC modernos y las aplicaciones creativas requieren mucho más ancho de banda de memoria para manejar una geometría de escena cada vez más compleja, texturas más finas, trazado de rayos, inferencia de IA y, por supuesto, sombreado y supermuestreo.
GDDR6X es la primera memoria gráfica que supera los 900 GB / s. Para lograr esto, se ha utilizado tecnología de señalización innovadora y modulación de amplitud de pulso de cuatro niveles (PAM4), revolucionando colectivamente la forma en que se mueven los datos en la memoria. Con el algoritmo PAM4, GDDR6X transfiere más datos a una velocidad mucho más rápida, moviendo dos bits de datos a la vez, lo que duplica la velocidad de datos de E / S del esquema PAM2 / NRZ anterior.
La GDDR6X admite actualmente 19,5 Gbps para la GeForce RTX 3090 y 19 Gbps para la GeForce RTX 3080. Gracias a esto, la GeForce RTX 3080 ofrece 1,5 veces el rendimiento de memoria de su predecesora, la RTX 2080 Super. ...
La Figura 16 muestra una comparación de la estructura de GDDR6 (izquierda) y GDDR6X (derecha). GDDR6X transmite los mismos datos a la mitad de la frecuencia que GDDR6. O, alternativamente, GDDR6X puede duplicar su ancho de banda efectivo mientras mantiene la misma frecuencia.

Figura 16. GDDR6X con señales PAM4 muestra un mejor rendimiento y eficiencia que GDDR6
Se ha desarrollado un nuevo esquema de codificación MTA (máxima prevención de transición) para abordar los problemas de SNR asociados con la señalización PAM4. El MTA evita que las señales de alta velocidad vayan de la más alta a la más baja y viceversa.

Figura 17. Nueva codificación en GDDR6X Al admitir
velocidades de datos de hasta 19,5 Gbps en chips GA10x, GDDR6X ofrece un ancho de banda de memoria máximo de hasta 936 GB / s, un 52% más que la GPU TU102 utilizada en GeForce RTX 2080 Ti. GDDR6X tiene el mayor salto de ancho de banda en 10 años después de las GPU de la serie GeForce 200.
RTX IO
Los juegos modernos contienen mundos enormes. Con el desarrollo de tecnologías como la fotogrametría, estas imitan cada vez más la realidad y, como resultado, están contenidas en archivos con un volumen cada vez mayor. Los proyectos de juegos más grandes ocupan más de 200 GB, que es 3 veces más que hace cuatro años, y este número solo crecerá con el tiempo.
Los jugadores recurren cada vez más a los SSD para reducir los tiempos de carga del juego: mientras que los discos duros están limitados a un ancho de banda de 50-100 MB / s, los últimos SSD M.2 PCIe Gen4 leen datos a una velocidad de hasta 7 GB / s.
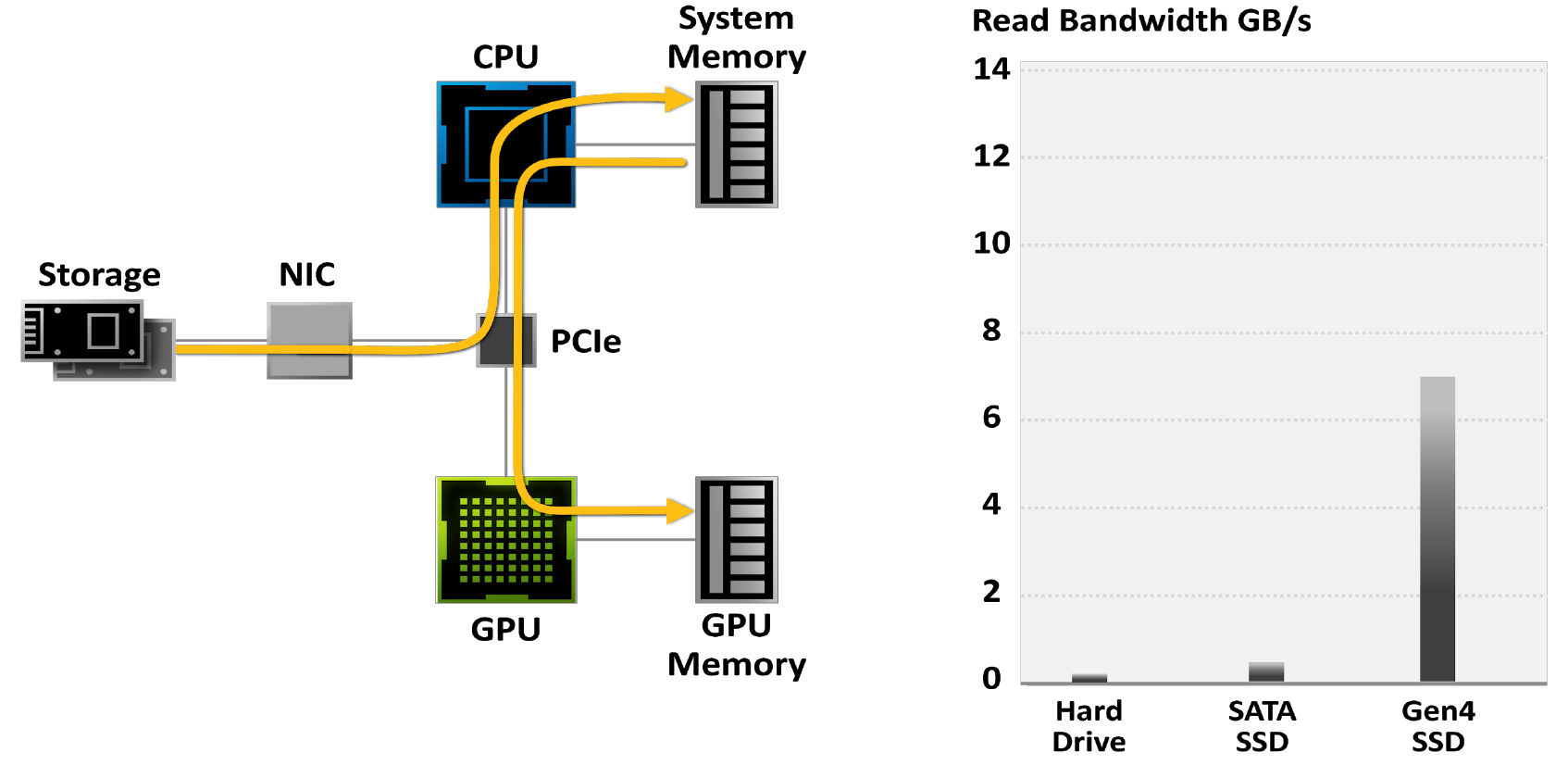
Figura 18. Juegos limitados por sistemas de E / S tradicionales

Figura 19. Con el modelo de almacenamiento tradicional, desempaquetar un juego puede ocupar los 24 núcleos del procesador. Los motores de juegos modernos han superado las capacidades de las API de almacenamiento tradicionales. Es por eso que se necesita una nueva generación de arquitectura de E / S. Aquí, las barras grises indican la velocidad de transferencia de datos, bloques negros y azules: los núcleos de CPU necesarios para ello.
NVIDIA RTX IO es un conjunto de tecnologías que proporcionan una carga y un desempaquetado rápidos de recursos basados en GPU y ofrecen un rendimiento de E / S hasta 100 veces más rápido que los discos duros y las API de almacenamiento tradicionales.
NVIDIA RTX IO funciona junto con la API de Microsoft DirectStorage, el almacenamiento de próxima generación diseñado específicamente para las PC de juegos NVMe SSD actuales. NVIDIA RTX IO ofrece descompresión sin pérdidas, lo que permite que los datos se lean en forma comprimida a través de DirectStorage y se envíen a la GPU. Esto descarga la carga de la CPU al mover los datos del almacenamiento a la GPU en una forma comprimida más eficiente y duplicar el rendimiento de E / S.

Figura 20. RTX IO ofrece 100 veces más rendimiento y 20 veces menos uso de CPU. Las barras grises y verdes indican la velocidad en baudios, se requieren bloques negros y azules para este núcleo de CPU.
Motor de visualización y video
DisplayPort 1.4a con DSC 1.2a
Continúa la marcha hacia resoluciones cada vez más altas y velocidades de cuadro más altas, y las GPU NVIDIA Ampere se esfuerzan por mantenerse a la vanguardia de la industria para ofrecer ambas. Los jugadores ahora pueden jugar en pantallas 4K (3820 x 2160) a 120Hz y 8K (7680 x 4320) a 60Hz, cuatro veces la cantidad de píxeles de 4K.
El motor de arquitectura Ampere está diseñado para admitir muchas de las nuevas tecnologías incluidas en las interfaces de pantalla más rápidas disponibles en la actualidad. Esto incluye DisplayPort 1.4a, que ofrece 8K a 60Hz con VESA Display Stream Compression (DSC) 1.2a. Las nuevas GPU Ampere se pueden conectar a dos pantallas de 8K 60Hz con solo un cable por pantalla.
HDMI 2.1 con DSC 1.2a
La arquitectura NVIDIA Ampere agrega soporte para HDMI 2.1, la última actualización de la especificación HDMI, por primera vez para GPU discretas. HDMI ha aumentado el ancho de banda máximo a 48 Gbps, lo que también permite formatos HDR dinámicos. La compatibilidad con 8K a 60 Hz con HDR requiere compresión DSC 1.2a o formato de píxeles 4: 2: 0.
NVDEC de quinta generación: decodificación de video acelerada por hardware
Las GPU NVIDIA incluyen la decodificación de video acelerada por hardware de quinta generación (NVDEC), que proporciona decodificación de video de hardware completo para una variedad de códecs populares.

Figura 21. Formatos de codificación y decodificación de video compatibles con las
GPU GA10x El decodificador NVIDIA de quinta generación en GA10x admite la decodificación acelerada por hardware de los siguientes códecs de video en plataformas Windows y Linux: MPEG-2, VC-1, H.264 (AVCHD), H.265 (HEVC), VP8, VP9 y AV1.
NVIDIA es el primer fabricante de GPU que proporciona soporte de hardware para la decodificación AV1.
Decodificación de hardware AV1
Aunque AV1 es muy eficiente en la compresión de video, la decodificación es computacionalmente intensiva. Los decodificadores de software modernos causan una alta utilización de la CPU y dificultan la reproducción de video de ultra alta definición. En las pruebas de NVIDIA, el procesador Intel i9 9900K promedió 28 cuadros por segundo en YouTube en 8K60 HDR, con una utilización de la CPU superior al 85%. Las GPU GA10x pueden reproducir AV1 pasando la decodificación a NVDEC, que es capaz de reproducir contenido HDR de hasta 8K60 con un uso de CPU muy bajo (~ 4% en la misma CPU que en la prueba anterior).
NVENC de séptima generación: codificación de vídeo acelerada por hardware
La codificación de video puede ser una tarea computacional compleja, pero si lo carga en NVENC, el motor gráfico y la CPU quedan libres para otras operaciones. Por ejemplo, al transmitir juegos a Twitch.tv usando Open Broadcaster Software (OBS), la descarga de la codificación de video a NVENC asignará el motor gráfico de la GPU para renderizar el juego y la CPU para otras tareas del usuario.
NVENC permite:
- Codificación de latencia ultrabaja de alta calidad y transmisión de juegos y aplicaciones sin usar la CPU;
- codificación de muy alta calidad para archivo, transmisión OTT, video web;
- Codificación de potencia ultrabaja por flujo (W / flujo).
Con la configuración de transmisión compartida para Twitch y YouTube, la codificación de hardware basada en NVENC en las GPU GA10x supera a los codificadores de software x264 que usan el ajuste preestablecido Rápido y está a la par con x264 Medio, un ajuste preestablecido que generalmente requiere la potencia de dos computadoras. Esto reduce drásticamente la carga de la CPU. La codificación 4K es demasiada carga de trabajo para una configuración típica de CPU, pero el codificador GA10x NVENC proporciona una codificación de alta resolución sin interrupciones hasta 4K en H.264 e incluso 8K en HEVC.
Conclusión
Con cada nueva arquitectura de procesador, NVIDIA se esfuerza por ofrecer un rendimiento revolucionario a la próxima generación al tiempo que presenta nuevas funciones que mejoran la calidad de la imagen. Turing fue la primera GPU en introducir el trazado de rayos acelerado por hardware, una característica que alguna vez se consideró el santo grial de los gráficos por computadora. Hoy en día, se están agregando efectos de trazado de rayos increíblemente realistas y físicamente precisos a muchos juegos nuevos de AAA para PC, y el trazado de rayos acelerado por GPU se considera una característica imprescindible para la mayoría de los jugadores de PC. Las nuevas GPU NVIDIA GA10x Ampere ofrecen las funciones y el rendimiento que necesita para disfrutar de estos nuevos juegos con trazado de rayos con velocidades de cuadro hasta 2 veces más rápidas que las disponibles actualmente.Otra característica de Turing, el procesamiento de inteligencia artificial acelerado por CPU mejorado que mejora la cancelación de ruido, el renderizado y otras aplicaciones gráficas, también se lleva al siguiente nivel gracias a la arquitectura Ampere.
Finalmente, un enlace al documento completo .