Todos tienen sus libros favoritos sobre magia. Alguien tiene a Tolkien, alguien tiene a Pratchett, alguien, como yo, tiene a Max Fry. Hoy les contaré sobre mi magia de TI favorita: sobre BPF y la infraestructura moderna que lo rodea.
BPF está en su apogeo en este momento. La tecnología se está desarrollando a pasos agigantados, penetrando en los lugares más inesperados y volviéndose cada vez más accesible para el usuario medio. Hoy en día, en casi todas las conferencias populares se puede escuchar un informe sobre este tema, y la GopherCon Rusia no es una excepción: les presento una versión de texto de mi informe .
No habrá descubrimientos únicos en este artículo. Intentaré mostrarte qué es BPF, qué puede hacer y cómo puede ayudarte personalmente. También echaremos un vistazo a las funciones relacionadas con Go.
Después de leer mi artículo, realmente me gustaría que tus ojos se iluminaran de la misma manera que se iluminan los ojos de un niño que lee el libro de Harry Potter por primera vez, para que vuelvas a casa o al trabajo y pruebes un nuevo "juguete" en acción.
¿Qué es eBPF?
Entonces, ¿de qué tipo de magia te va a contar un hombre barbudo de 34 años con ojos ardientes?
Vivimos contigo en 2020. Si abre Twitter, leerá los tweets de caballeros gruñones que afirman que el software ahora se está escribiendo con una calidad tan terrible que es más fácil tirarlo todo y empezar de nuevo. Algunos incluso amenazan con dejar la profesión, porque no pueden soportarlo más: todo se rompe constantemente, es incómodo, lento.
Quizás tengan razón: sin mil comentarios, no lo sabremos. Pero lo que definitivamente estoy de acuerdo es que la pila de software moderna es más compleja que nunca.
BIOS, EFI, sistema operativo, controladores, módulos, bibliotecas, redes, bases de datos, cachés, orquestadores como K8, contenedores como Docker, finalmente, nuestro software con tiempos de ejecución y recolectores de basura. Un verdadero profesional puede responder a la pregunta de qué sucede después de escribir ya.ru en su navegador durante varios días.
Es muy difícil comprender lo que está sucediendo en su sistema, especialmente si algo va mal en este momento y está perdiendo dinero. Este problema ha llevado a la aparición de líneas de negocio diseñadas para ayudarlo a comprender lo que sucede dentro de su sistema. Las grandes empresas tienen departamentos completos de Sherlock que saben dónde martillar y qué tuerca apretar para ahorrar millones de dólares.
En las entrevistas, a menudo le pregunto a las personas cómo solucionarán los problemas si se despiertan a las cuatro de la mañana.
Un enfoque es analizar los registros . Pero el problema es que solo están disponibles los que el desarrollador puso en su sistema. No son flexibles.
El segundo enfoque popular es estudiar métricas . Los tres sistemas de métricas más populares están escritos en Go. Las métricas son muy útiles, pero no siempre le ayudan a comprender las causas al permitirle ver los síntomas.
El tercer enfoque que está ganando popularidad es el llamado observabilidad: la capacidad de formular preguntas arbitrariamente complejas sobre el comportamiento del sistema y obtener respuestas. Dado que la pregunta puede ser muy compleja, la respuesta puede requerir una amplia variedad de información y, hasta que se haga la pregunta, no sabremos qué. Esto significa que la flexibilidad es vital para la observabilidad.
¿Dar la posibilidad de cambiar el nivel de registro sobre la marcha? ¿Conectarse con un depurador a un programa en ejecución y hacer algo allí sin interrumpir su trabajo? ¿Comprender qué solicitudes ingresan al sistema, visualizar las fuentes de las solicitudes lentas, ver en qué memoria se gasta a través de pprof y obtener un gráfico de su cambio a lo largo del tiempo? ¿Mide la latencia de una función y la dependencia de la latencia de los argumentos? Todos estos enfoques me referiré a la observabilidad. Este es un conjunto de utilidades, enfoques, conocimientos, experiencia, que juntos le darán la oportunidad de hacer, si no todo, mucho "beneficio", directamente en el sistema de trabajo. Cuchillo informático suizo moderno.

Pero, ¿cómo se puede hacer esto? Había y hay muchos instrumentos en el mercado: simples, complejos, peligrosos, lentos. Pero el tema del artículo de hoy es BPF.
El kernel de Linux está controlado por eventos. Casi todo lo que sucede en el kernel, y en el sistema en su conjunto, puede representarse como un conjunto de eventos. La interrupción es un evento, recibir un paquete a través de la red es un evento, la transferencia de un procesador a otro proceso es un evento, el lanzamiento de una función es un evento.
Entonces, BPF es un subsistema del kernel de Linux que hace posible escribir pequeños programas que serán lanzados por el kernel en respuesta a eventos. Estos programas pueden arrojar luz sobre lo que está sucediendo en su sistema y controlarlo.
Fue una introducción muy larga. Acerquémonos a la realidad.
1994 vio la primera versión de BPF, que algunos de ustedes pueden haber encontrado al escribir reglas simples para la utilidad tcpdump para ver o rastrear paquetes de red. tcpdump, puede configurar "filtros" para ver no todos, sino solo los paquetes que le interesan. Por ejemplo, "solo el protocolo tcp y solo el puerto 80". Para cada paquete que pasaba, se ejecutaba una función para decidir si guardar ese paquete en particular o no. Puede haber muchos paquetes, lo que significa que nuestra función debe ser muy rápida. Nuestros filtros tcpdump se estaban convirtiendo en funciones BPF, un ejemplo de las cuales se muestra en la imagen a continuación.
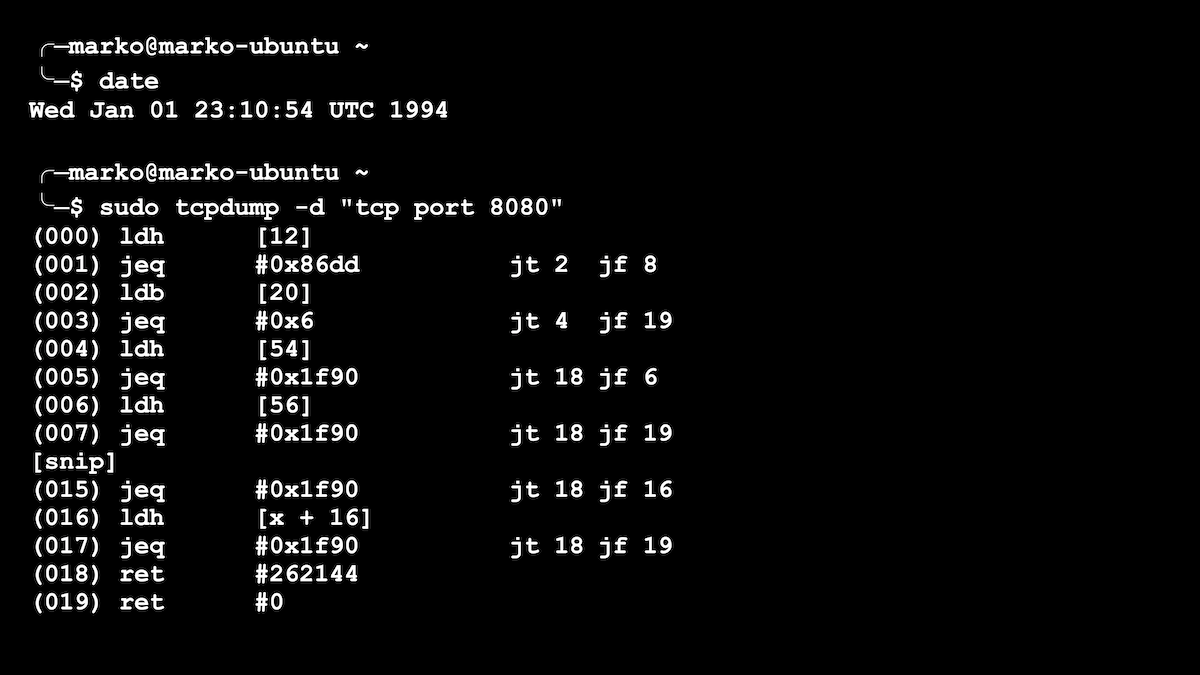
Un filtro simple para tcpdump se presenta como un programa BPF
El BPF original era una máquina virtual muy simple con varios registros. Pero, sin embargo, BPF ha acelerado significativamente el filtrado de paquetes de red. En un momento, este fue un gran paso adelante.

En 2014, Alexey Starovoitov amplió la funcionalidad de BPF. Aumentó el número de registros y el tamaño permitido del programa, agregó la compilación JIT e hizo un verificador que verificaba la seguridad de los programas. Pero lo más impresionante fue que se podían lanzar nuevos programas BPF no solo al procesar paquetes, sino también en respuesta a numerosos eventos del kernel, y pasar información entre el kernel y el espacio de usuario.
Estos cambios abrieron el camino para nuevos casos de uso de BPF. Algunas cosas que antes se hacían escribiendo módulos de kernel complejos y peligrosos ahora son relativamente fáciles de hacer a través de BPF. ¿Por qué es esto genial? Sí, porque cualquier error al escribir un módulo a menudo provocaba pánico. No para el pánico esponjoso de Go-shnoy, sino para el pánico del kernel, después de lo cual, solo reinicie.
El usuario medio de Linux ahora tiene una capacidad superpoderosa para mirar bajo el capó, que anteriormente solo estaba disponible para desarrolladores de kernel expertos o cualquier otra persona. Esta opción es comparable a la capacidad de escribir sin esfuerzo un programa para iOS o Android: en teléfonos más antiguos era imposible o mucho más difícil.
La nueva versión de BPF de Alexey se denominó eBPF (de la palabra extendida - extendida). Pero ahora ha reemplazado todas las versiones antiguas de BPF y se ha vuelto tan popular que todo el mundo lo llama simplemente BPF por simplicidad.
¿Dónde se usa BPF?
Entonces, ¿cuáles son estos eventos, o desencadenantes, a los que se pueden adjuntar los programas de BPF, y cómo comenzó la gente a aprovechar este nuevo poder?
Actualmente hay dos grandes grupos de factores desencadenantes.
El primer grupo se utiliza para procesar paquetes de red y gestionar el tráfico de red. Estos son XDP, eventos de control de tráfico y algunos más.
Estos eventos son necesarios para:
- , . Cloudflare Facebook BPF- DDoS-. ( BPF- ), . .
- , , — , , . . Facebook, , , .
- Construye equilibradores inteligentes. El ejemplo más destacado es el proyecto Cilium , que se utiliza con mayor frecuencia en el clúster K8s como una red de malla. Cilium gestiona el tráfico: lo equilibra, lo redirecciona y lo analiza. Y todo esto se hace con la ayuda de pequeños programas BPF que el kernel ejecuta en respuesta a un evento relacionado con paquetes de red o sockets.
Este fue el primer grupo de desencadenantes asociados con problemas de redes con la capacidad de influir en el comportamiento. El segundo grupo está relacionado con la observabilidad más general; los programas de este grupo a menudo no tienen la capacidad de influir en algo, sino que sólo pueden "observar". Ella me interesa mucho más.
Este grupo contiene desencadenantes como:
- perf events — , Linux- perf: , , minor/major- . . , , , - . , , , , .
- tracepoints — ( ) , (, ). , — , , , , . - , tracepoints :
- ;
- , ;
- API, , , , , API.
, , , , , pprof .
- ;
- USDT — , tracepoints, user space-. . : MySQL, , PHP, Python. enable-dtrace . , Go . -, , DTrace . , , Solaris: , , GC -, .
Bueno, entonces comienza otro nivel de magia:
- Los disparadores ftrace nos dan la capacidad de ejecutar un programa BPF al comienzo de casi cualquier función del kernel. Totalmente dinámico. Esto significa que el núcleo llamará a su función BPF antes de ejecutar cualquier función del núcleo que elija. O todas las funciones del kernel, lo que sea. Puede adjuntar todas las funciones del kernel y obtener una buena visualización de todas las llamadas en la salida.
- kprobes / uprobes dan casi lo mismo que ftrace, solo que tenemos la capacidad de ajustarnos a cualquier lugar al ejecutar una función, tanto en el kernel como en el espacio de usuario. En el medio de la función, ¿hay algún tipo de if en una variable y necesita trazar un histograma de los valores de esta variable? No es un problema.
- kretprobes/uretprobes — , user space. , , . , , PID fork.
Lo más notable de todo esto, repito, es que, al ser llamado en cualquiera de estos desencadenantes, nuestro programa BPF puede echar un buen vistazo: leer argumentos de función, cronometrar, leer variables, variables globales, realizar un seguimiento de pila, guardar eso luego, para más tarde, transferir datos al espacio de usuario para su procesamiento, obtener datos del espacio de usuario para filtrar o algunos comandos de control. ¡Belleza!
No sé ustedes, pero para mí la nueva infraestructura es como un juguete que he estado esperando ansiosamente durante mucho tiempo.
API, o cómo usarlo
Está bien, Marco, nos convenciste de mirar hacia BPF. Pero, ¿cómo abordarlo?
Echemos un vistazo a en qué consiste un programa BPF y cómo interactuar con él.

Primero, tenemos un programa BPF que, si se verifica, se cargará en el kernel. Allí se compilará JIT en código de máquina y se ejecutará en modo kernel cuando se active el disparador.
El programa BPF tiene la capacidad de interactuar con la segunda parte: el programa espacial del usuario. Hay dos maneras de hacer esto. Podemos escribir en un búfer circular, y la parte del espacio de usuario puede leer desde él. También podemos escribir y leer en el almacenamiento clave-valor, que se llama mapa BPF, y la parte del espacio del usuario, respectivamente, puede hacer lo mismo y, en consecuencia, pueden transferirse cierta información entre sí.
Camino recto
La forma más fácil de trabajar con BPF, con la que en ningún caso debería comenzar, es escribir programas BPF similares al lenguaje C y compilar este código usando el compilador Clang en código de máquina virtual. Luego cargamos este código usando la llamada al sistema BPF directamente e interactuamos con nuestro programa BPF también usando la llamada al sistema BPF.
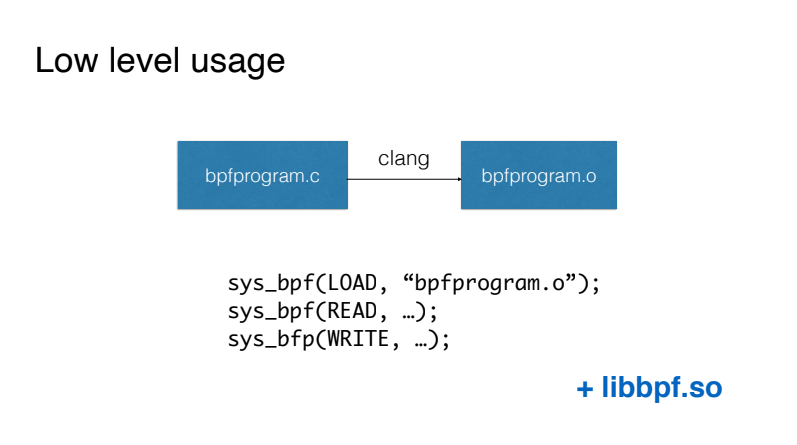
La primera simplificación disponible es utilizar la biblioteca libbpf, que viene con las fuentes del kernel y le permite no trabajar directamente con la llamada al sistema BPF. De hecho, proporciona envoltorios convenientes para cargar código, trabajando con los llamados mapas para transferir datos desde el kernel al espacio del usuario y viceversa.
bcc
Está claro que tal uso está lejos de ser amigable para los humanos. Afortunadamente, bajo la marca iovizor, apareció el proyecto BCC, que simplifica enormemente nuestra vida.

De hecho, prepara todo el entorno de compilación y nos da la oportunidad de escribir programas BPF individuales, donde la parte C se ensamblará y cargará en el kernel automáticamente, y la parte del espacio de usuario se puede hacer en Python simple y comprensible.
bpftrace
Pero BCC parece complicado por muchas cosas. Por alguna razón, a la gente especialmente no le gusta escribir partes en C.
Los mismos chicos de iovizor introdujeron la herramienta bpftrace, que le permite escribir scripts BPF en un lenguaje de scripting simple a la AWK (o generalmente de una sola línea).

El reconocido experto en rendimiento y observabilidad Brendan Gregg preparó la siguiente visualización de las formas disponibles de trabajar con BPF:

Verticalmente, tenemos la simplicidad de la herramienta, y horizontalmente, su poder. Se puede ver que BCC es una herramienta muy poderosa, pero no súper simple. bpftrace es mucho más simple, pero menos poderoso.
Ejemplos de uso de BPF
Pero veamos las habilidades mágicas que están disponibles para nosotros, con ejemplos específicos.
Tanto BCC como bpftrace contienen una carpeta Tools, que contiene una gran cantidad de scripts útiles e interesantes listos para usar. También son el Stack Overflow local desde el que puede copiar fragmentos de código para sus scripts.
Por ejemplo, aquí hay una secuencia de comandos que muestra la latencia de las consultas de DNS:
╭─marko@marko-home ~
╰─$ sudo gethostlatency-bpfcc
TIME PID COMM LATms HOST
16:27:32 21417 DNS Res~ver #93 3.97 live.github.com
16:27:33 22055 cupsd 7.28 NPI86DDEE.local
16:27:33 15580 DNS Res~ver #87 0.40 github.githubassets.com
16:27:33 15777 DNS Res~ver #89 0.54 github.githubassets.com
16:27:33 21417 DNS Res~ver #93 0.35 live.github.com
16:27:42 15580 DNS Res~ver #87 5.61 ac.duckduckgo.com
16:27:42 15777 DNS Res~ver #89 3.81 www.facebook.com
16:27:42 15777 DNS Res~ver #89 3.76 tech.badoo.com :-)
16:27:43 21417 DNS Res~ver #93 3.89 static.xx.fbcdn.net
16:27:43 15580 DNS Res~ver #87 3.76 scontent-frt3-2.xx.fbcdn.net
16:27:43 15777 DNS Res~ver #89 3.50 scontent-frx5-1.xx.fbcdn.net
16:27:43 21417 DNS Res~ver #93 4.98 scontent-frt3-1.xx.fbcdn.net
16:27:44 15580 DNS Res~ver #87 5.53 edge-chat.facebook.com
16:27:44 15777 DNS Res~ver #89 0.24 edge-chat.facebook.com
16:27:44 22099 cupsd 7.28 NPI86DDEE.local
16:27:45 15580 DNS Res~ver #87 3.85 safebrowsing.googleapis.com
^C%
La utilidad muestra el tiempo de ejecución de las consultas DNS en tiempo real, por lo que puede detectar, por ejemplo, algunos valores atípicos inesperados.
Y este es un script que "espía" lo que otros escriben en sus terminales:
╭─marko@marko-home ~
╰─$ sudo bashreadline-bpfcc
TIME PID COMMAND
16:51:42 24309 uname -a
16:52:03 24309 rm -rf src/badooEste tipo de script se puede utilizar para atrapar a un mal vecino o auditar la seguridad de los servidores de una empresa.
Script para ver llamadas de flujo de lenguajes de alto nivel:
╭─marko@marko-home ~/tmp
╰─$ sudo /usr/sbin/lib/uflow -l python 20590
Tracing method calls in python process 20590... Ctrl-C to quit.
CPU PID TID TIME(us) METHOD
5 20590 20590 0.173 -> helloworld.py.hello
5 20590 20590 0.173 -> helloworld.py.world
5 20590 20590 0.173 <- helloworld.py.world
5 20590 20590 0.173 <- helloworld.py.hello
5 20590 20590 1.174 -> helloworld.py.hello
5 20590 20590 1.174 -> helloworld.py.world
5 20590 20590 1.174 <- helloworld.py.world
5 20590 20590 1.174 <- helloworld.py.hello
5 20590 20590 2.175 -> helloworld.py.hello
5 20590 20590 2.176 -> helloworld.py.world
5 20590 20590 2.176 <- helloworld.py.world
5 20590 20590 2.176 <- helloworld.py.hello
6 20590 20590 3.176 -> helloworld.py.hello
6 20590 20590 3.176 -> helloworld.py.world
6 20590 20590 3.176 <- helloworld.py.world
6 20590 20590 3.176 <- helloworld.py.hello
6 20590 20590 4.177 -> helloworld.py.hello
6 20590 20590 4.177 -> helloworld.py.world
6 20590 20590 4.177 <- helloworld.py.world
6 20590 20590 4.177 <- helloworld.py.hello
^C%Este ejemplo muestra la pila de llamadas de un programa Python.
El mismo Brendan Gregg realizó una imagen en la que recopiló todos los scripts existentes con flechas indicando aquellos subsistemas que cada utilidad permite "observar". Como puede ver, ya tenemos una gran cantidad de utilidades listas para usar disponibles, para casi cualquier ocasión.

No intente ver algo aquí. La imagen se utiliza como referencia.
¿Y nosotros con Go?
Ahora hablemos de Go. Tenemos dos preguntas principales:
- ¿Puedes escribir programas BPF en Go?
- ¿Es posible analizar programas escritos en Go?
Vayamos en orden.
Hasta la fecha, el único compilador que puede compilar en un formato comprendido por la máquina BPF es Clang. Otro compilador popular, GCC, aún no tiene un backend BPF. Y el único lenguaje de programación que se puede compilar en BPF es una versión muy limitada de C.
Sin embargo, el programa BPF tiene una segunda parte, que está en el espacio del usuario. Y se puede escribir en Go.
Como mencioné anteriormente, BCC le permite escribir esta parte en Python, que es el idioma principal de la herramienta. Al mismo tiempo, en el repositorio principal, BCC también es compatible con Lua y C ++, y en un repositorio de terceros también es compatible con Go .

Un programa de este tipo se ve exactamente igual que un programa de Python. Al principio hay una línea en la que aparece un programa BPF en C, y luego le decimos dónde adjuntar este programa, y de alguna manera interactuar con él, por ejemplo, obtenemos datos del mapa EPF.
De hecho, eso es todo. Puedes ver el ejemplo con más detalle en Github .
Probablemente el principal inconveniente es que la biblioteca C libbcc o libbpf se usa para trabajar, y construir un programa Go con tal biblioteca no parece en absoluto un agradable paseo por el parque.
Además de iovisor / gobpf, encontré tres proyectos más actuales que te permiten escribir una parte de usuario en Go.
- https://github.com/dropbox/goebpf
- https://github.com/cilium/ebpf
- https://github.com/andrewkroh/go-ebpf
La versión de Dropbox no requiere ninguna biblioteca C, pero debes compilar la parte del kernel del programa BPF tú mismo usando Clang y luego cargarlo en el kernel con el programa Go.
La versión de Cilium tiene las mismas características que la versión de Dropbox. Pero vale la pena mencionarlo, aunque solo sea porque lo hacen los chicos del proyecto Cilium, lo que significa que está condenado al éxito.
Traje el tercer proyecto para completar la imagen. Como los dos anteriores, no tiene dependencias externas de C, requiere el ensamblaje manual de un programa BPF C, pero no parece ser muy prometedor.
De hecho, hay otra pregunta: ¿por qué escribir programas BPF en Go? Después de todo, si observa BCC o bpftrace, los programas BPF generalmente toman menos de 500 líneas de código. ¿No es más fácil escribir un script en bpftrace-language o descubrir un poco de Python? Veo dos razones aquí.
Primero, realmente amas Go y prefieres hacer todo en él. Además, los programas potencialmente Go son más fáciles de transferir de una máquina a otra: enlaces estáticos, binarios simples, etc. Pero todo está lejos de ser tan obvio, ya que estamos atados a un núcleo específico. Me detendré aquí, de lo contrario, mi artículo se extenderá por otras 50 páginas.
La segunda opción: no está escribiendo un script simple, sino un sistema a gran escala que también usa BPF internamente. Incluso tengo un ejemplo de un sistema de este tipo en Go :

El proyecto Scope parece un binario que, cuando se lanza en la infraestructura de K8s u otra nube, analiza todo lo que sucede a su alrededor y muestra qué son los contenedores, servicios, cómo interactúan, etc. Y mucho de esto se hace usando BPF. Un proyecto interesante.
Analizar programas de Go
Si recuerdas, teníamos otra pregunta: ¿podemos analizar programas escritos en Go usando BPF? Primer pensamiento, ¡por supuesto! ¿Qué diferencia hace en qué idioma está escrito el programa? Después de todo, esto es solo un código compilado que, como todos los demás programas, calcula algo en el procesador, come memoria como si no fuera por sí mismo, interactúa con el hardware a través del kernel y con el kernel a través de llamadas al sistema. En principio, esto es correcto, pero hay características de diferentes niveles de complejidad.
Pasando argumentos
Una de las características es que Go no usa la ABI como la mayoría de los otros idiomas. Dio la casualidad de que los padres fundadores decidieron tomar el ABI del sistema Plan 9 , que conocían bien.
ABI es como una API, un acuerdo de interoperabilidad, solo a nivel de bits, bytes y código de máquina.
El principal elemento ABI que nos interesa es cómo se pasan sus argumentos a la función y cómo se devuelve la respuesta desde la función. Mientras que la ABI x86-64 estándar usa registros de procesador para pasar argumentos y respuestas, la ABI de Plan 9 usa una pila para esto.
Rob Pike y su equipo no planeaban hacer otro estándar: ya tenían un compilador de C casi listo para usar para el sistema Plan 9, tan simple como dos-dos, que rápidamente convirtieron en un compilador para Go. Enfoque de ingeniería en acción.
Pero este, de hecho, no es un problema muy crítico. En primer lugar, es posible que pronto veamos en Go pasar argumentos a través de registros y, en segundo lugar, obtener argumentos de la pila desde BPF no es difícil: el alias sargX ya se ha agregado a bpftrace , y lo mismo aparecerá en BCC , muy probablemente en un futuro próximo. ...
Upd : desde el momento en que hice el informe apareció incluso una propuesta oficial detallada para la transición al uso de registros en el ABI.
Identificador de hilo único
La segunda característica tiene que ver con la característica favorita de Go, goroutines. Una forma de medir la latencia de una función es ahorrar el tiempo que se tarda en llamar a la función, cronometrarla para salir de la función y calcular la diferencia; y guarde la hora de inicio con una tecla que contenga el nombre de la función y TID (número de hilo). El número de hilo es necesario, ya que la misma función puede ser llamada simultáneamente por diferentes programas o por diferentes hilos del mismo programa.

Pero en Go, las gorutinas caminan entre los subprocesos del sistema: ahora se ejecuta una goroutine en un subproceso y un poco más tarde en otro. Y en el caso de Go, no pondríamos el TID en la clave, sino el GID, es decir, el ID de la goroutine, pero no podemos conseguirlo. Técnicamente, esta identificación existe. Incluso puede sacarlo con trucos sucios, ya que está en algún lugar de la pila, pero hacerlo está estrictamente prohibido por las recomendaciones del grupo de desarrollo clave de Go. Sentían que nunca necesitaríamos tal información. Además del almacenamiento local de Goroutine, pero estoy divagando.
Expandiendo la pila
El tercer problema es el más grave. Tan grave que incluso si de alguna manera resolvemos el segundo problema, no nos ayudará de ninguna manera a medir la latencia de las funciones de Go.
Probablemente, la mayoría de los lectores entienden bien qué es una pila. La misma pila donde, a diferencia de la pila o el montón, puede asignar memoria para las variables y no pensar en liberarlas.
Si hablamos de C, entonces la pila tiene un tamaño fijo. Si superamos este tamaño fijo, se producirá el famoso desbordamiento de pila .
En Go, la pila es dinámica. En versiones anteriores, eran trozos de memoria concatenados. Ahora es un fragmento continuo de tamaño dinámico. Esto quiere decir que si la pieza seleccionada no nos alcanza, ampliaremos la actual. Y si no podemos expandir, seleccionamos otro más grande y movemos todos los datos del lugar anterior al nuevo. Es una historia fascinante que toca las garantías de seguridad, cgo, recolector de basura, pero ese es un tema para otro artículo.
Es importante saber que para que Go mueva la pila, necesita recorrer la pila de llamadas del programa, todos los punteros de la pila.
Aquí es donde radica el problema principal: uretprobes, que se utilizan para adjuntar una función BPF, cambian dinámicamente la pila al final de la ejecución de la función para hacer una llamada en línea a su controlador, el llamado trampolín. Y un cambio tan inesperado en la pila de Go en la mayoría de los casos termina con un bloqueo del programa. ¡Ups!

Sin embargo, esta historia no es única. El desenredador de "pila" de C ++ también se bloquea en el momento del manejo de excepciones.
No hay solución a este problema. Como es habitual en tales casos, las partes intercambian argumentos absolutamente razonables sobre la culpabilidad de la otra parte.
Pero si realmente necesita colocar uretprobe, entonces el problema puede evitarse. ¿Cómo? No ponga uretprobe. Podemos poner un albornoz en todos los lugares donde salgamos de la función. Puede haber uno de esos lugares, o tal vez 50.

Y aquí la singularidad de Go juega en nuestras manos.
Normalmente, tal truco no funcionaría. Un compilador lo suficientemente inteligente puede hacer la llamada optimización de la llamada de cola , cuando en lugar de regresar de una función y regresar a lo largo de la pila de llamadas, simplemente saltamos al comienzo de la siguiente función. Este tipo de optimización es fundamental para lenguajes funcionales como Haskell . Sin él, no podrían haber dado un paso sin el desbordamiento de la pila. Pero con tal optimización, simplemente no podemos encontrar todos los lugares a los que regresamos de la función.
La peculiaridad es que la versión 1.14 del compilador de Go aún no puede realizar la optimización de llamadas finales. Esto significa que el truco de adjuntar a todas las salidas explícitas de una función funciona, aunque es muy tedioso.
Ejemplos de
No crea que BPF es inútil para Go. Esto está lejos de ser el caso: todo lo demás que no toque los matices anteriores, podemos hacerlo. Y lo haremos.
Echemos un vistazo a algunos ejemplos.
Tomemos un programa simple para la preparación. Básicamente, es un servidor web que escucha en el puerto 8080 y tiene un controlador de solicitudes HTTP. El manejador obtendrá el parámetro de nombre, el parámetro Go de la URL y hará algún tipo de verificación del "sitio", y luego enviará las tres variables (nombre, año y estado de verificación) a la función prepareAnswer (), que preparará una respuesta como una cadena.

La validación del sitio es una solicitud HTTP que verifica si el sitio de la conferencia está en funcionamiento mediante una tubería y una goroutine. Y la función de preparar la respuesta simplemente lo convierte todo en una cadena legible.
Activaremos nuestro programa con una simple solicitud de curl:

Como primer ejemplo, usaremos bpftrace para imprimir todas las llamadas a funciones de nuestro programa. Adjuntamos aquí a todas las funciones que caen bajo main. En Go, todas sus funciones tienen un símbolo que se parece al nombre del paquete nombre-punto-función. Nuestro paquete es main y el tiempo de ejecución de la función sería el tiempo de ejecución.

Cuando hago curl, se lanzan el controlador, la función de validación del sitio y la subfunción goroutine, y luego la función de preparación de respuesta. ¡Clase!
A continuación, quiero mostrar no solo qué funciones se están ejecutando, sino también sus argumentos. Tomemos la función prepareAnswer (). Tiene tres argumentos. Intentemos imprimir dos int.
Tomamos bpftrace, solo que ahora no es una sola línea, sino un script. Adjuntamos a nuestra función y usamos los alias para los argumentos de la pila que mencioné.
En la salida, vemos lo que aprobamos en 2020, obtuvimos el estado 200 y aprobamos una vez en 2021.
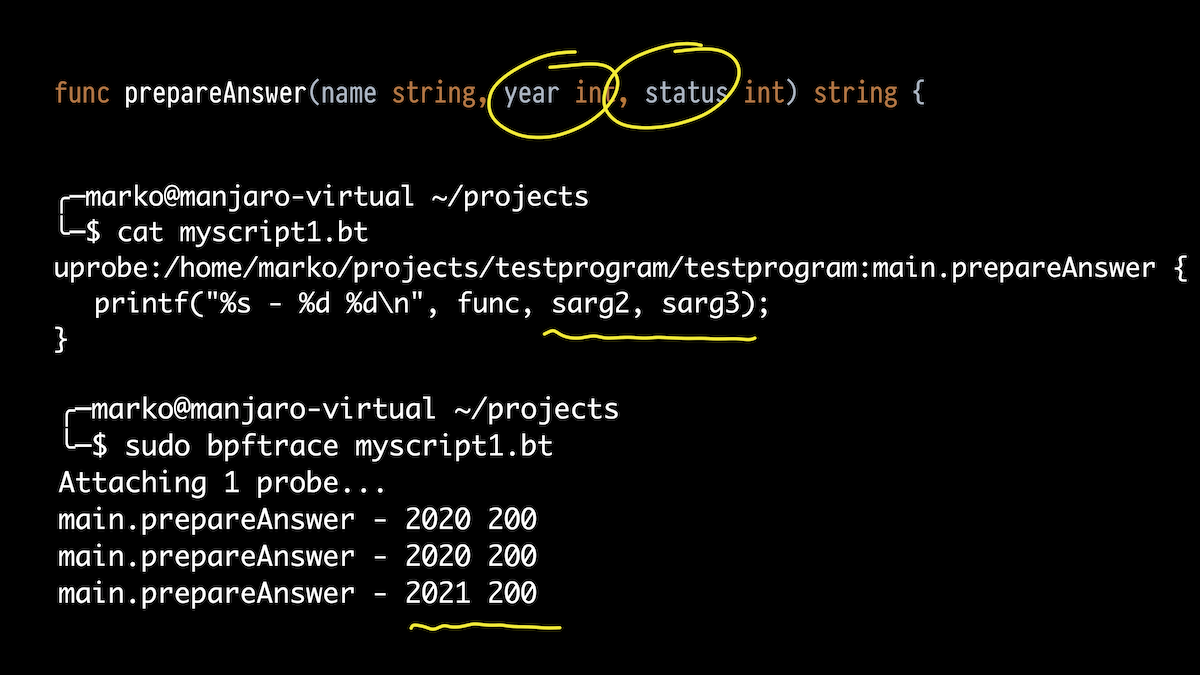
Pero la función tiene tres argumentos. El primero es una cuerda. ¿Qué hay de él?
Imprimamos todos los argumentos de la pila de 0 a 4. ¿Y qué vemos? Alguna cifra grande, alguna cifra menor y nuestros viejos 2021 y 200. ¿Cuáles son estos números extraños al principio?

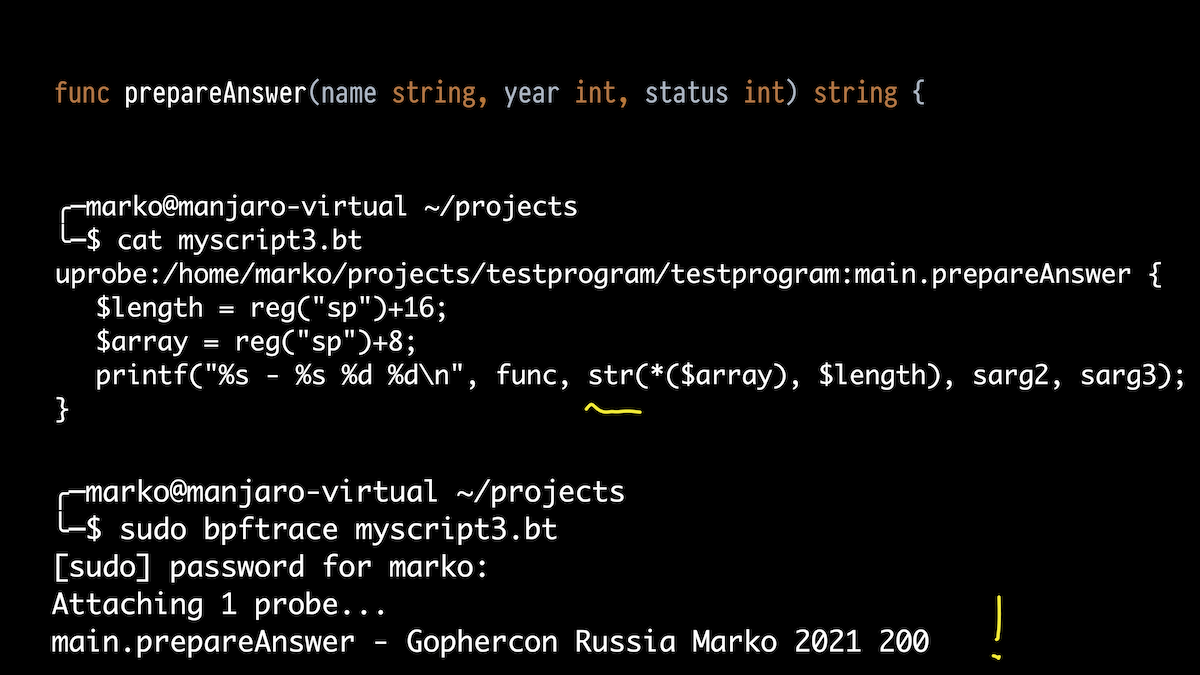
Aquí es donde resulta útil conocer el dispositivo Go. Si en C una cadena es solo una matriz de caracteres terminada en cero, entonces en Go una cadena es en realidad una estructura que consiste en un puntero a una matriz de caracteres (por cierto, no terminada en cero) y longitud.

Pero el compilador Go, cuando se pasa una cadena como argumento, expande esta estructura y la pasa como dos argumentos. Y resulta que el primer dígito extraño es solo un puntero a nuestra matriz, y el segundo es la longitud.
Y la verdad: la longitud esperada de la cadena es 22. En
consecuencia, arreglamos nuestro script un poco para obtener estos dos valores a través de la pila de registros de puntero y el desplazamiento correcto, y usando la función incorporada str () lo mostramos como una cadena. Todo funciona:
Bueno, echemos un vistazo al tiempo de ejecución. Por ejemplo, quería saber qué rutinas lanza nuestro programa. Sé que las goroutines son activadas por las funciones newproc () y newproc1 (). Conectémonos con ellos. El primer argumento de la función newproc1 () es un puntero a la estructura funcval, que tiene un solo campo: un puntero a función:
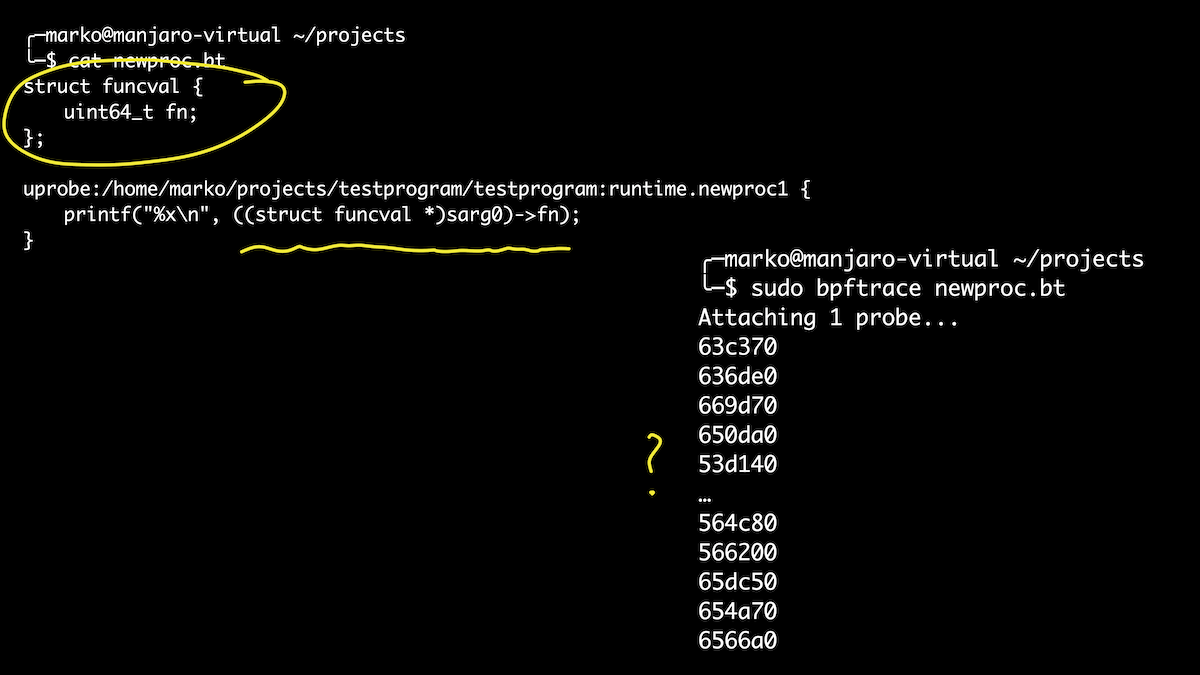
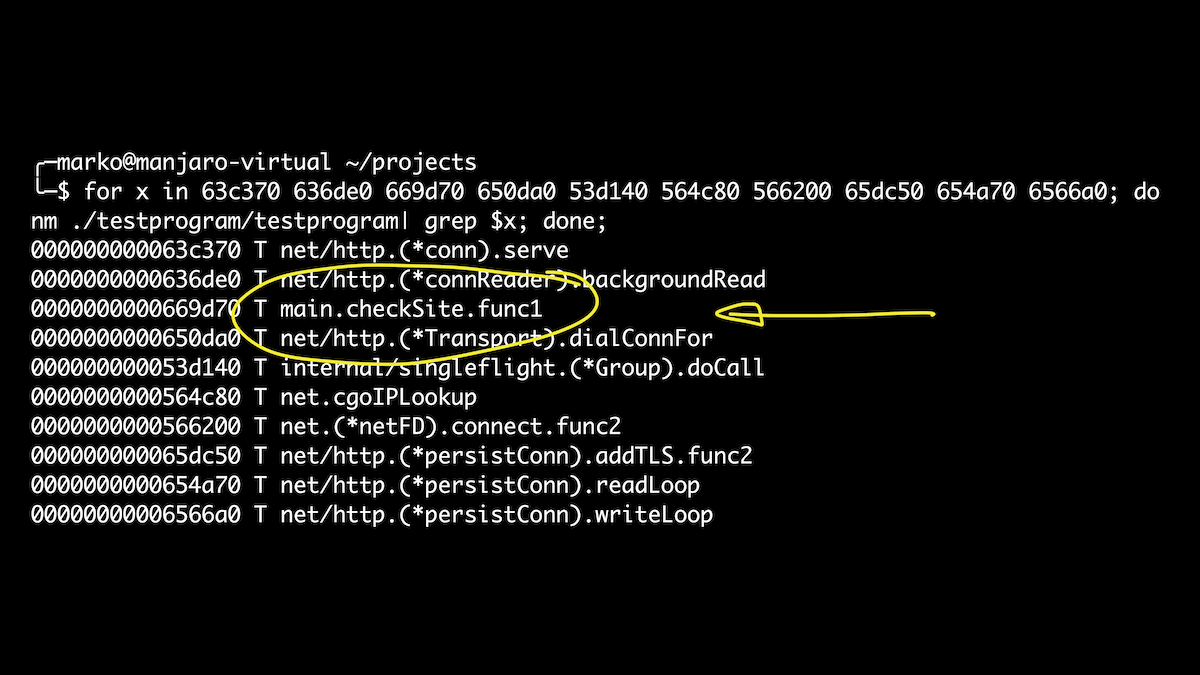
En este caso, aprovecharemos la oportunidad para definir estructuras directamente en el script. Es un poco más fácil que jugar con conjuntos compensados. Aquí hemos generado todas las goroutines que se lanzan cuando se llama a nuestro controlador. Y si después de eso obtenemos los nombres de los símbolos para nuestras compensaciones, entonces solo entre ellos veremos nuestra función checkSite. ¡Hurra!
Estos ejemplos son una gota en el océano de las capacidades de BPF, BCC y bpftrace. Con el conocimiento adecuado del interior y la experiencia, puede obtener casi cualquier información de un programa en ejecución sin detenerlo ni cambiarlo.
Conclusión
Eso es todo lo que quería contarte. Espero haber podido inspirarte.
BPF es una de las tendencias más prometedoras y de moda en Linux. Y estoy seguro de que en los próximos años veremos cosas mucho más interesantes no solo en la tecnología en sí, sino también en las herramientas y su distribución.
Antes de que sea demasiado tarde y no todo el mundo sepa sobre BPF, juega con él, conviértete en mago, resuelve problemas y ayuda a tus compañeros. Dicen que los trucos de magia solo funcionan una vez.
En cuanto a Go, resultó, como de costumbre, bastante único. Siempre tenemos algunos matices: o el compilador es diferente, luego el ABI, necesitamos algún tipo de GOPATH, un nombre que no puede ser Google. Pero nos hemos convertido en una fuerza a tener en cuenta, y creo que la vida solo mejorará.