
Imagine un registro de 2,5 gigabytes después de una compilación fallida. Son tres millones de líneas. Está buscando un error o regresión que aparece en la millonésima línea. Probablemente sea simplemente imposible encontrar una de esas líneas manualmente. Una opción es una diferencia entre las últimas compilaciones exitosas y fallidas con la esperanza de que el error escriba líneas inusuales en los registros. La solución de Netflix es más rápida y precisa que LogReduce: por debajo del límite.
Netflix y la línea en la pila de registros
La diferencia estándar de md5 es rápida, pero imprime al menos cientos de miles de líneas candidatas para su visualización porque muestra diferencias de línea. Una variación de logreduce es una diferencia difusa que utiliza una búsqueda de k vecino más cercano que encuentra unos 40.000 candidatos, pero tarda una hora. La siguiente solución encuentra 20.000 cadenas candidatas en 20 minutos. Gracias a la magia del código abierto, esto es solo alrededor de cien líneas de código Python.
Solución: una combinación de representaciones de palabras vectoriales que codifican la información semántica de palabras y oraciones, y un hash basado en la ubicación(LSH - Local Sensitive Hash), que distribuye de manera efectiva elementos aproximadamente cercanos en algunos grupos y elementos distantes en otros grupos. La combinación de representaciones vectoriales de palabras y LSH es una gran idea menos de diez años atrás .
Nota: ejecutamos Tensorflow 2.2 en la CPU y con ejecución inmediata para el aprendizaje de transferencia y scikit-learnNearestNeighborpara k vecinos más cercanos. Existen aproximaciones complejas de los vecinos más cercanos que serían mejores para resolver el problema del vecino más cercano basado en el modelo.
Representación de palabras vectoriales: ¿que es y por que?
La construcción de una bolsa de palabras con k categorías (codificación k-hot, una generalización de la codificación unitaria) es un punto de partida típico (y útil) para los problemas de deduplicación, búsqueda y similitud entre texto no estructurado y semiestructurado. Este tipo de bolsa de codificación de palabras se parece a un diccionario con palabras individuales y su número. Ejemplo con la frase "log in error, check log".
{"log": 2, "in": 1, "error": 1, "check": 1}
Dicha codificación también está representada por un vector, donde el índice corresponde a una palabra y el valor corresponde al número de palabras. A continuación se muestra la frase "log in error, check log" como un vector, donde la primera entrada está reservada para contar las palabras "log", la segunda para contar las palabras "in", y así sucesivamente:
[2, 1, 1, 1, 0, 0, 0, 0, 0, ...]
Tenga en cuenta: el vector consta de muchos ceros. Los ceros son todas las demás palabras del diccionario que no están en esta oración. El número total de posibles entradas vectoriales, o la dimensión de un vector, es el tamaño del vocabulario de su idioma, que a menudo es de millones de palabras o más, pero comprimido a cientos de miles con ingeniosos trucos .
Veamos el diccionario y las representaciones vectoriales de la frase "autenticación de problemas". Las palabras que coinciden con las cinco primeras entradas de vectores no aparecen en absoluto en la nueva oración.
{"problem": 1, "authenticating": 1}
Resulta:
[0, 0, 0, 0, 1, 1, 0, 0, 0, ...]
Las frases "autentificación de problemas" y "error de inicio de sesión, comprobar registro" son semánticamente similares. Es decir, son esencialmente lo mismo, pero léxicamente lo más diferentes posible. No tienen palabras en común. En términos de diferencia difusa, podríamos decir que son demasiado similares para distinguirlos, pero la codificación md5 y un documento procesado por k-hot con kNN no lo admiten.
La reducción de dimensiones usa álgebra lineal o redes neuronales artificiales para colocar palabras, oraciones o líneas de registro semánticamente similares una al lado de la otra en un nuevo espacio vectorial. Se utilizan representaciones vectoriales. En nuestro ejemplo, "log in error, check log" puede tener un vector de cinco dimensiones para representar:
[0.1, 0.3, -0.5, -0.7, 0.2]
La frase "autenticación de problemas" puede ser
[0.1, 0.35, -0.5, -0.7, 0.2]
Estos vectores están cerca unos de otros en términos de medidas como la similitud del coseno , a diferencia de sus vectores de bolsa de palabras. Las vistas densas y de dimensiones reducidas son realmente útiles para documentos cortos como líneas de montaje o syslog.
De hecho, reemplazaría miles o más de las dimensiones del diccionario con solo una representación de 100 dimensiones que sea rica en información (no cinco). Los enfoques modernos para la reducción de la dimensionalidad incluyen la descomposición de valores singulares de la matriz de co-ocurrencia de palabras ( GloVe ) y redes neuronales especializadas ( word2vec , BERT , ELMo ).
¿Qué pasa con la agrupación? Volvamos al registro de compilación
Bromeamos con que Netflix es un servicio de producción de registros que ocasionalmente transmite videos. Registro, transmisión, manejo de excepciones: son cientos de miles de solicitudes por segundo. Por lo tanto, el escalado es necesario cuando queremos aplicar ML aplicado en telemetría y registro. Por esta razón, tenemos cuidado al escalar la deduplicación de texto, buscar similitudes semánticas y detectar valores atípicos de texto. Cuando los problemas empresariales se resuelven en tiempo real, no hay otra forma.
Nuestra solución implica representar cada fila en un vector de baja dimensión y, opcionalmente, "ajustar" o actualizar simultáneamente el modelo de inserción, asignarlo a un grupo y definir las líneas en diferentes grupos como "diferentes". Hash con reconocimiento de ubicación- un algoritmo probabilístico que le permite asignar clústeres en tiempo constante y buscar vecinos más cercanos en tiempo casi constante.
LSH funciona mapeando una representación vectorial a un conjunto de escalares. Los algoritmos de hash estándar tienden a evitar colisiones entre dos entradas coincidentes. LSH busca evitar colisiones si las entradas están muy separadas y las promueve si son diferentes pero cercanas entre sí en el espacio vectorial.
El vector que representa la frase "log in error, check error" se puede emparejar con un número binario
01. Luego01representa un grupo. El vector de "autenticación de problemas" con una alta probabilidad también se puede mostrar en 01. Por lo tanto, LSH proporciona una comparación difusa y resuelve el problema inverso: una diferencia difusa. Las primeras aplicaciones de LSH se realizaron en espacios vectoriales multidimensionales de un conjunto de palabras. No podíamos pensar en una sola razón por la que no trabajaría con espacios de representación vectorial de palabras. Hay indicios de que otros pensaron lo mismo .

Lo anterior muestra el uso de LSH al colocar personajes en el mismo grupo, pero al revés.
El trabajo que hemos realizado para aplicar LSH y cortes vectoriales mediante la detección de valores atípicos de texto en los registros de compilación ahora permite al ingeniero ver una pequeña parte de las líneas de registro para identificar y corregir posibles errores críticos para el negocio. También le permite lograr la agrupación semántica de casi cualquier línea de registro en tiempo real.
Este enfoque ahora funciona en todas las versiones de Netflix. La parte semántica le permite agrupar elementos aparentemente diferentes en función de su significado y mostrar estos elementos en informes de emisiones.
Algunos ejemplos
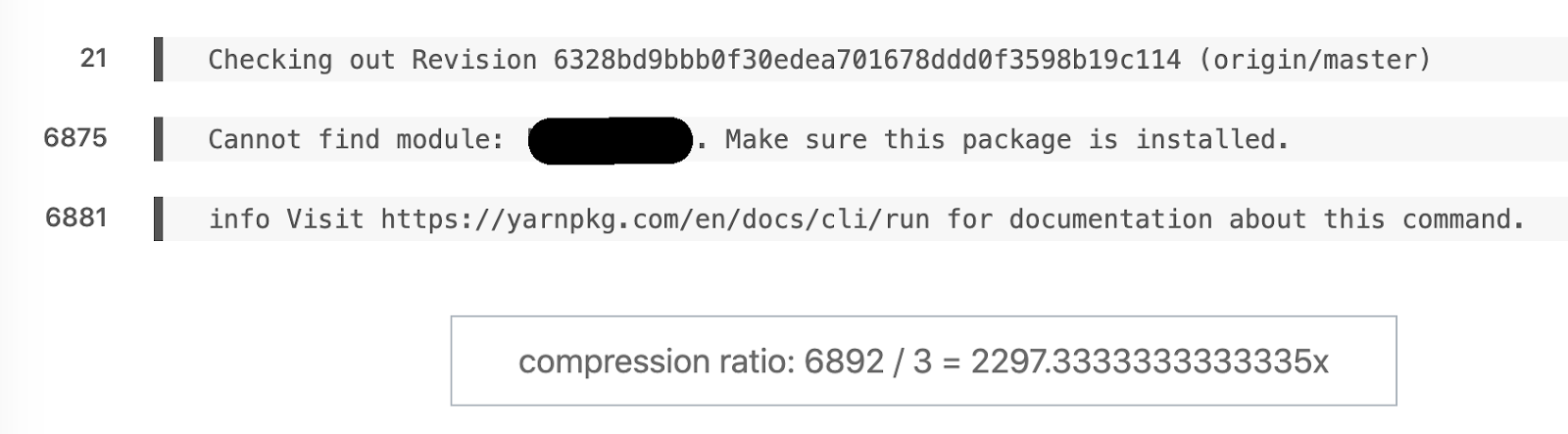
Ejemplo favorito de diferencia semántica. 6892 líneas se convirtieron en 3.
Otro ejemplo: este ensamblaje registró 6044 líneas, pero permanecieron 171 en el informe. El problema principal surgió casi inmediatamente en la línea 4036.

Por supuesto, es más rápido analizar 171 líneas que 6044. Pero, ¿cómo obtuvimos registros de ensamblaje tan grandes? Algunas de las miles de tareas de construcción que son pruebas de resistencia para la electrónica de consumo se realizan en modo de seguimiento. Es difícil trabajar con tal volumen de datos sin un procesamiento preliminar.

Relación de compresión: 91366/455 = 205,3.
Hay varios ejemplos que reflejan las diferencias semánticas entre marcos, lenguajes y scripts de compilación.
Conclusión
La madurez de los productos de aprendizaje de transferencia de código abierto y SDK ha resuelto el problema de la búsqueda semántica del vecino más cercano con LSH en muy pocas líneas de código. Estábamos interesados en los beneficios especiales que la transferencia de aprendizaje y el ajuste fino aportan a la aplicación. Estamos felices de poder resolver estos problemas y ayudar a las personas a hacer lo que hacen mejor y más rápido.
Esperamos que esté considerando unirse a Netflix y convertirse en uno de los grandes colegas cuyas vidas hacemos la vida más fácil con el aprendizaje automático. El compromiso es el valor central de Netflix y estamos particularmente interesados en fomentar diferentes perspectivas en los equipos de tecnología. Por lo tanto, si está en análisis, ingeniería, ciencia de datos o cualquier otro campo y tiene una experiencia que no es típica de la industria, ¡nos encantaría escucharlo especialmente!
Si tiene alguna pregunta sobre las funciones de Netflix, comuníquese con los colaboradores de LinkedIn: Stanislav Kirdey , William High ¿Cómo se resuelve el problema de búsqueda de registros
?
Descubra los detalles de cómo obtener una profesión de alto perfil desde cero o subir de nivel en habilidades y salario tomando cursos en línea de SkillFactory:
- Machine Learning (12 )
- «Machine Learning Pro + Deep Learning» (20 )
- « Machine Learning Data Science» (20 )
- Data Science (12 )
E
