Introducción
Una pérdida de memoria generalmente se denomina situación en la que la cantidad de memoria ocupada en el montón aumenta durante el funcionamiento a largo plazo de la aplicación y no disminuye después de que sale el recolector de basura. Como sabe, la memoria jvm se divide en montón y pila. La pila almacena los valores de variables de tipos simples y referencias a objetos en el contexto de la secuencia, y el montón almacena los objetos en sí. También en el montón hay un espacio llamado Metaspace, que almacena datos sobre clases cargadas y datos vinculados a las clases mismas, y no a sus instancias, en particular, los valores de variables estáticas. El recolector de basura (en adelante GC), lanzado periódicamente por la máquina java, encuentra objetos en el montón a los que ya no se hace referencia y libera la memoria ocupada por estos objetos. Los algoritmos de trabajo de GC son diferentes y complejos, en particular,la próxima vez que se inicia el GC, no "examina" todo el montón cada vez para encontrar objetos no utilizados, por lo que no vale la pena confiar en el hecho de que cualquier objeto no utilizado se eliminará de la memoria después de un inicio del GC, pero si la cantidad de memoria utilizada por la aplicación es constante crece sin razón aparente durante mucho tiempo, entonces es hora de pensar en qué podría haber llevado a tal situación.
Jvm incluye una utilidad multifuncional Visual VM (en lo sucesivo, VM). VM le permite observar visualmente la dinámica de los indicadores clave de jvm en los gráficos, en particular, la cantidad de memoria libre y ocupada en el montón, el número de clases cargadas, hilos, etc. Además, al utilizar la máquina virtual, puede realizar y examinar volcados de memoria. Por supuesto, la VM también permite el volcado de subprocesos y la creación de perfiles de aplicaciones, pero una descripción general de estas características está más allá del alcance de este artículo. Todo lo que necesitamos de la máquina virtual en este ejemplo es conectarnos a la máquina virtual y ver primero la imagen general del uso de la memoria. Me gustaría señalar que para conectar una máquina virtual a un servidor remoto, los parámetros de jmxremote deben configurarse en él, ya que la conexión es a través de jmx.Para obtener una descripción de estos parámetros, puede consultar la documentación oficial de Oracle o numerosos artículos sobre Habré.
Entonces, supongamos que nos hemos conectado con éxito al servidor de aplicaciones utilizando la VM y echemos un vistazo a los gráficos.
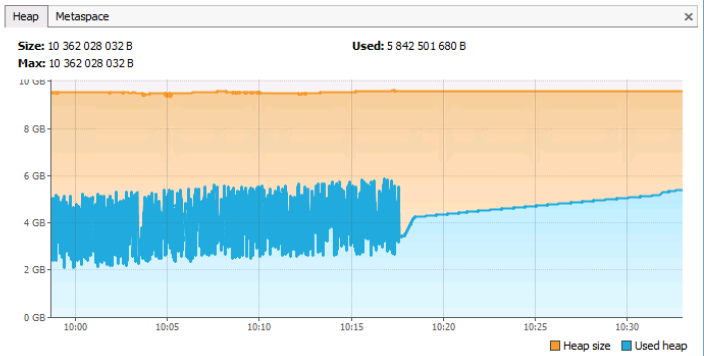
En la pestaña Heap, puede ver la memoria total y utilizada de jvm. Cabe señalar que esta pestaña también tiene en cuenta la memoria del tipo Metaspace (bueno, de qué otra manera, porque esto también es un montón). La pestaña Metaspace muestra información solo sobre la memoria ocupada por los metadatos (por las propias clases y los objetos vinculados a ellos).
Mirando el gráfico, podemos ver que la memoria del montón total es ~ 10GB, el espacio ocupado actual es ~ 5.8GB. Las crestas en el gráfico corresponden a llamadas GC, una línea casi recta (sin crestas) que comienza alrededor de las 10:18 puede (¡pero no necesariamente!) Indicar que el servidor de aplicaciones apenas se ha estado ejecutando desde ese momento, ya que no hubo asignación activa y desasignación. memoria. En general, este gráfico corresponde al funcionamiento normal del servidor de aplicaciones (si, por supuesto, para juzgar el trabajo solo desde la memoria). El diagrama del problema sería uno en el que una línea azul horizontal recta sin bordes estaría aproximadamente en la línea naranja, que representa la cantidad máxima de memoria en el montón.
Ahora echemos un vistazo a otro gráfico.
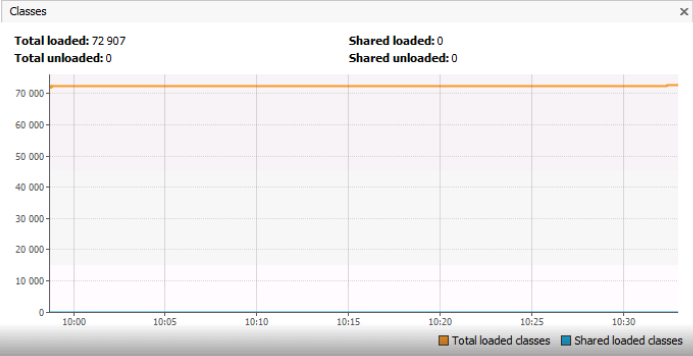
Aquí llegamos directamente al análisis del ejemplo, que es el tema principal de este artículo. El gráfico de Clases muestra el número de clases cargadas en Metaspace, y es ~ 73 mil objetos. Me gustaría llamar su atención sobre el hecho de que no estamos hablando de instancias de clase, sino de las clases en sí mismas, es decir, objetos de tipo Class <?>. No está claro en el gráfico cuántas instancias de cada tipo individual ClassA o ClassB se cargan en la memoria. ¿Quizás el número de clases idénticas de tipo ClassA por alguna razón se multiplica? Debo decir que en el ejemplo que se describirá a continuación, 73.000 clases únicas fue una situación absolutamente normal.
El caso es que en uno de los proyectos en los que participó el autor de este artículo, se desarrolló un mecanismo para la descripción universal de entidades de dominio (como en 1C) denominado sistema de diccionario, y analistas que personalizan el sistema para un cliente específico o para un área de negocio específica. tuvo la oportunidad, a través de un editor especial, de modelar un modelo de negocio creando entidades nuevas y cambiantes existentes, operando no a nivel de tablas, sino con conceptos tales como "Documento", "Cuenta", "Empleado", etc. El kernel del sistema creó tablas en un DBMS relacional para los datos de la entidad, y se podrían crear varias tablas para cada entidad, ya que el sistema universal permitió almacenar históricamente valores de atributos y mucho más, requiriendo la creación de tablas de servicio adicionales en la base de datos.
Creo que quienes tuvieron que trabajar con frameworks ORM ya adivinaron de qué se trataba el autor, distraídos del tema principal del artículo hablando de tablas. El proyecto usó Hibernate y para cada tabla tenía que haber una clase de bean Entity. Al mismo tiempo, dado que los analistas crearon nuevas tablas dinámicamente durante el trabajo del sistema, las clases de bean de Hibernate fueron generadas y no escritas manualmente por los desarrolladores. Y con cada nueva generación, se crearon entre 50 y 60 mil nuevas clases. Hubo significativamente menos tablas en el sistema (alrededor de 5-6 mil), pero para cada tabla, no solo se generó la clase Entity bean, sino también muchas clases auxiliares, que finalmente llevaron a una cifra común.
El mecanismo de trabajo fue el siguiente. Al inicio del sistema, las clases de bean de entidad y las clases auxiliares (en lo sucesivo, simplemente clases de bean) se generaron basándose en los metadatos de la base de datos. Cuando el sistema estaba en ejecución, la fábrica de sesiones de Hibernate creaba sesiones, las sesiones creaban instancias de objetos de clase bean. Al cambiar la estructura (agregar, cambiar tablas), las clases de bean se regeneraron y se creó una nueva fábrica de sesiones. Después de la regeneración, la nueva fábrica creó nuevas sesiones que usaban las nuevas clases de bean, la fábrica y las sesiones antiguas se cerraron y el GC descargó las antiguas clases de bean, ya que ya no se hacía referencia a ellas desde los objetos de infraestructura de Hibernate.
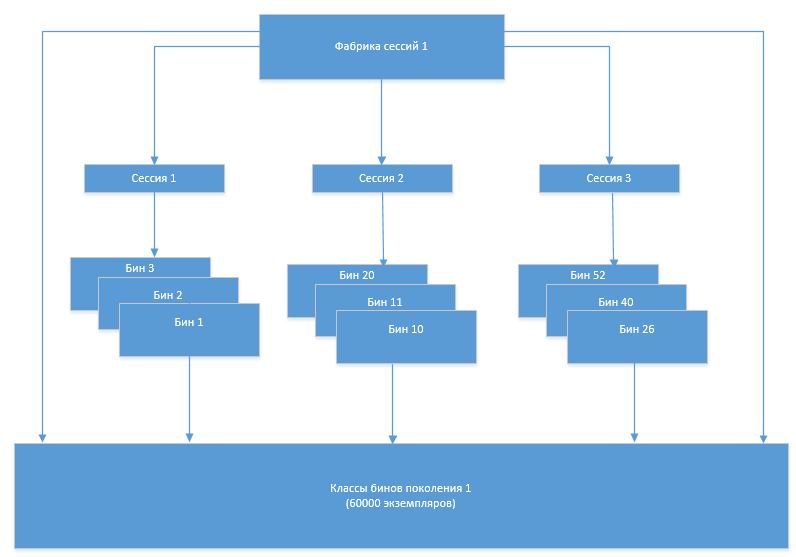
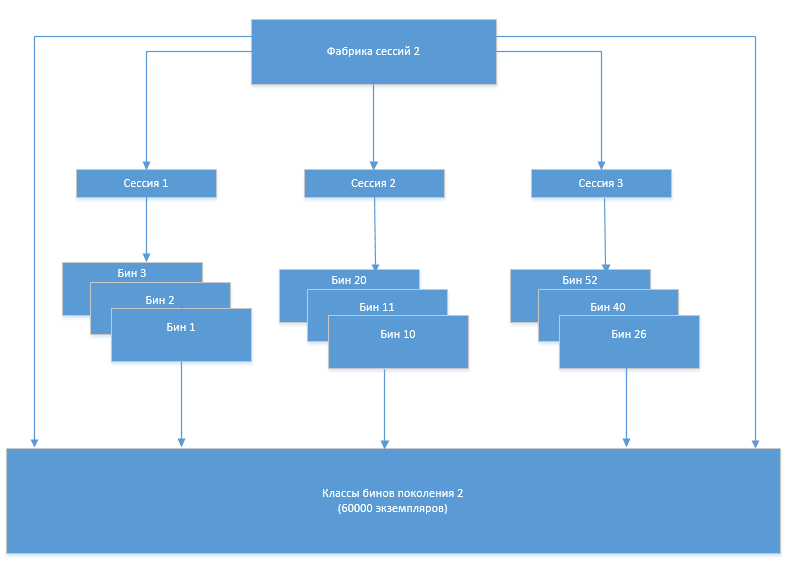
En algún momento, surgió el problema de que el número de clases de contenedores comenzó a aumentar después de cada siguiente regeneración. Obviamente, esto se debió al hecho de que el antiguo conjunto de clases, que ya no debería usarse, por alguna razón no se descargó de la memoria. Para comprender las razones de este comportamiento del sistema, el Eclipse Memory Analizer (MAT) acudió en nuestra ayuda.
Encontrar una pérdida de memoria
MAT sabe cómo trabajar con volcados de memoria, encontrando problemas potenciales en ellos, pero primero necesita obtener este volcado de memoria, pero en entornos reales hay ciertos matices al obtener un volcado.
Eliminar un volcado de memoria
Como se mencionó anteriormente, el volcado de memoria se puede eliminar directamente de la VM presionando el botón
Pero, debido al gran tamaño del volcado, es posible que la VM simplemente no pueda hacer frente a esta tarea y se congele un tiempo después de presionar el botón Heap Dump. Además, no es en absoluto un hecho que será posible conectarse a través de jmx al servidor de aplicaciones del producto requerido para la VM. En este caso, otra utilidad jvm llamada jMap viene a nuestro rescate. Se ejecuta en la línea de comando, directamente en el servidor donde se está ejecutando jvm, y le permite establecer parámetros de volcado adicionales:
jmap -dump: live, format = b, file = / tmp / heapdump.bin 14616
El parámetro –dump: live es extremadamente importante, ya que le permite reducir significativamente su tamaño, excluyendo objetos a los que ya no se hace referencia.
Otra situación común es cuando el volcado manual no es posible debido al hecho de que jvm se bloquea con OutOfMemoryError. En esta situación, viene al rescate la opción -XX: + HeapDumpOnOutOfMemoryError y, además, -XX: HeapDumpPath , que permite especificar la ruta al volcado capturado.
A continuación, abra el volcado capturado con el analizador de memoria Eclipse. El archivo puede ser de gran tamaño (varios gigabytes), por lo que debe proporcionar suficiente memoria en el archivo
MemoryAnalyzer.ini : -Xmx4096m
Localizando el problema usando MAT
Entonces, consideremos una situación en la que el número de clases cargadas se multiplica en comparación con el nivel inicial y no disminuye incluso después de una llamada forzada a la recolección de basura (esto se puede hacer presionando el botón correspondiente en la VM).
Arriba, se describió conceptualmente el proceso de regeneración de las clases de frijoles y su uso. En un nivel más técnico, se veía así:
- Todas las sesiones de Hibernate están cerradas (clase SessionImpl)
- Se cierra la fábrica de sesiones anterior (SessionFactoryImpl) y se restablece la referencia a ella desde LocalSessionFactoryBean
- ClassLoader se vuelve a crear
- Las referencias a las clases de frijoles antiguas en la clase del generador se anulan
- Las clases de frijoles se regeneran
En ausencia de referencias a clases de frijoles antiguas, el número de clases no debería aumentar después de la recolección de basura.
Ejecute MAT y abra el archivo de volcado de memoria obtenido anteriormente. Después de abrir el volcado, MAT muestra las cadenas de objetos más grandes en la memoria.
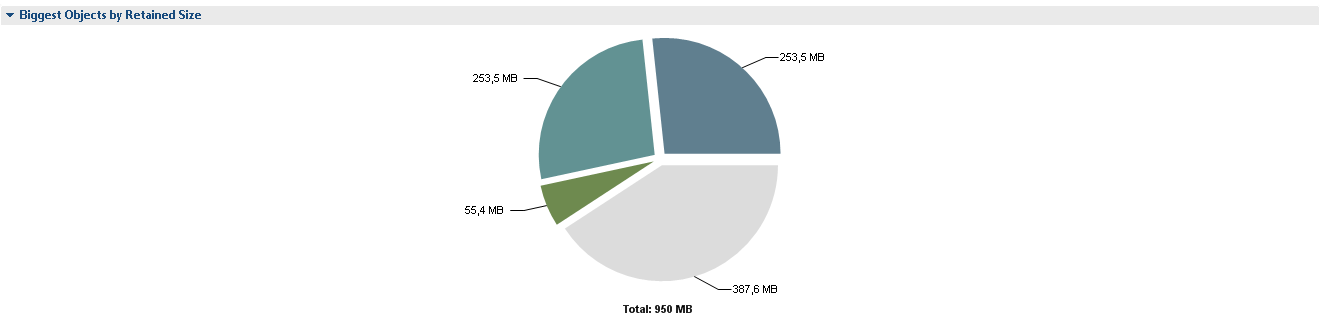
Después de hacer clic en Leak Suspects, vemos los detalles:
2 segmentos de un círculo de 265 M cada uno son 2 instancias de SessionFactoryImpl. No está claro por qué hay 2 instancias de ellos y, lo más probable, cada una de las instancias contiene referencias al conjunto completo de clases de beans de entidad. MAT nos informa sobre posibles problemas de la siguiente manera.

Noto de inmediato que el problema sospechoso 3 no es realmente un problema. El proyecto ha implementado un analizador de su propio lenguaje, que es un complemento multiplataforma sobre SQL y le permite operar no con tablas, sino con entidades del sistema, y 121M ocupa su caché de consultas.
Volvamos a dos instancias de SessionFactoryImpl. Haga clic en Clases duplicadas y vea que en realidad hay 2 instancias de cada clase de bean Entity. Es decir, los enlaces a las clases antiguas de los beans de entidad permanecen y, muy probablemente, estos son enlaces de SesssionFactoryImpl. Según el código fuente de esta clase, las referencias a las clases de bean deben almacenarse en el campo classMetaData.
Haga clic en Problem Suspect 1, luego en la clase SessionFactoryImpl y seleccione List Objects-> With outgouing referencias en el menú contextual. De esta forma podemos ver todos los objetos referenciados por SessionFactoryImpl.
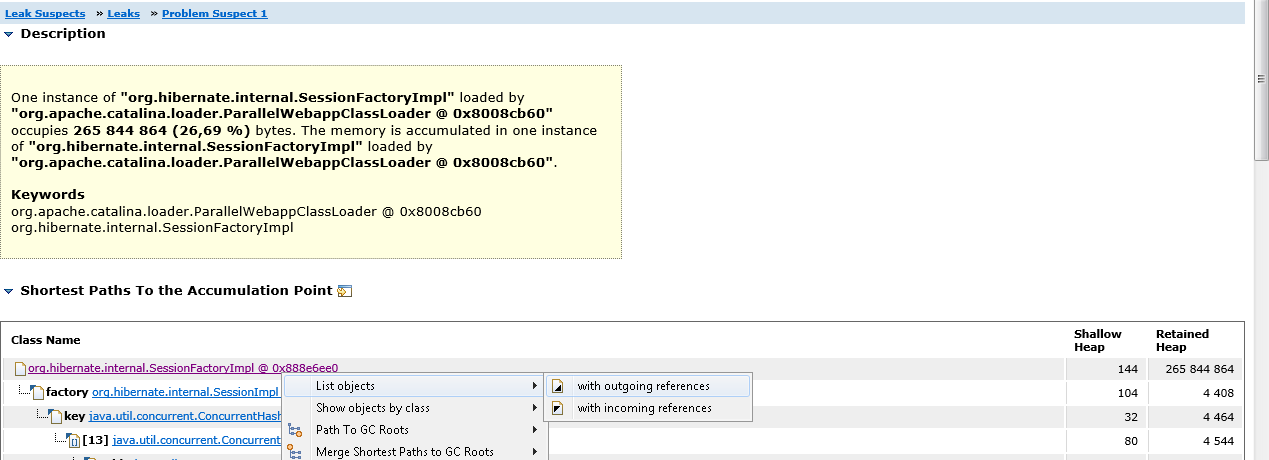
Expanda el objeto classMetaData y asegúrese de que realmente almacene una matriz de clases de beans de entidad.
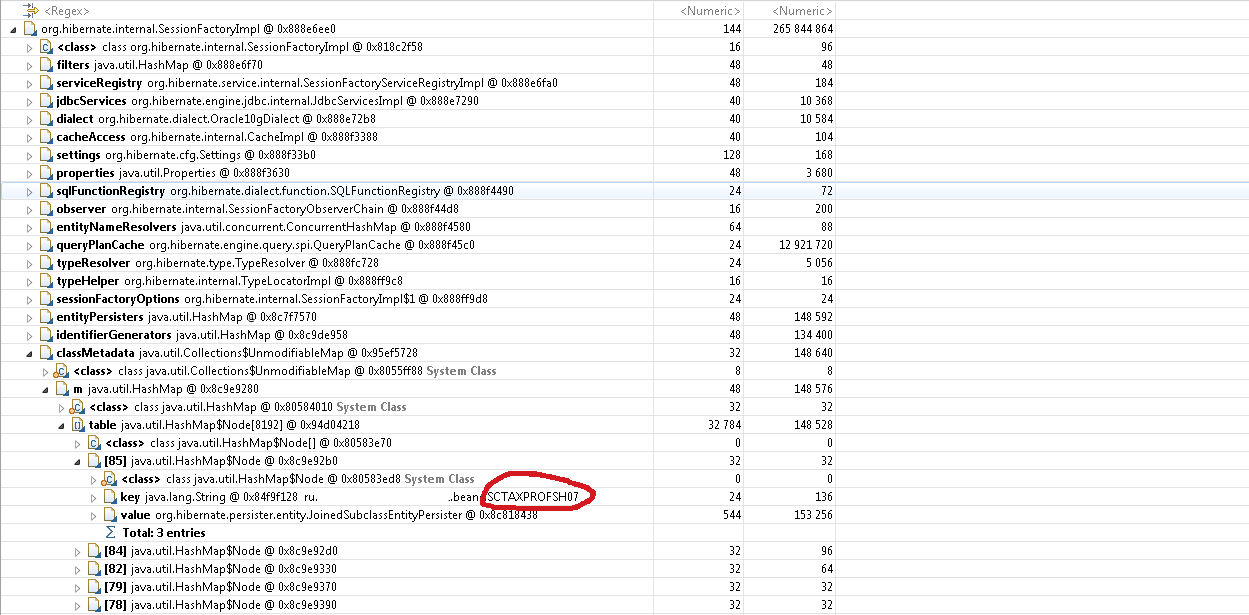
Ahora debemos comprender qué impide que el recolector de basura elimine una sola instancia de SessionFactoryImpl. Si volvemos a Leak Suspects-> Leaks-> Problem Suspect 1, veremos una pila de enlaces que llevan a un enlace a SessionFactoryImpl.
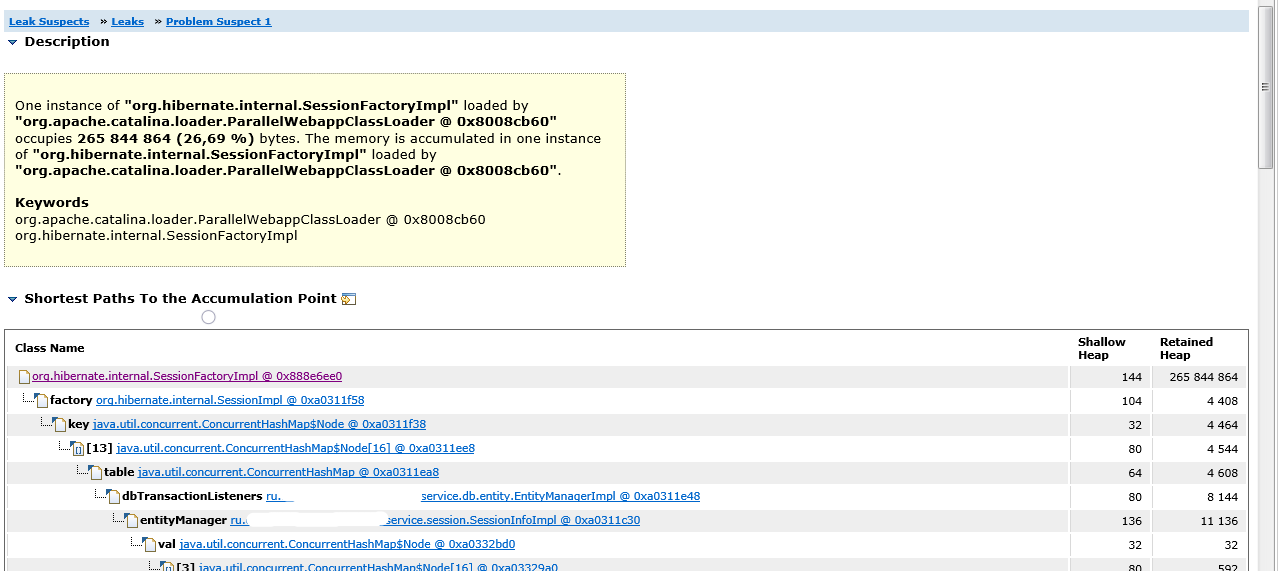
Vemos que la variable entityManager del bean SessionInfoImpl que contiene el contexto de la sesión HTTP tiene una matriz dbTransactionListeners que usa objetos SessionImpl de Hibernate como claves, y las sesiones hacen referencia a SessionFactoryImpl.
El hecho es que los objetos de sesión se almacenaron en caché en dbTransactionListeners para ciertos propósitos, y antes de que se regeneraran las clases de bean, las referencias a ellos podían permanecer en esta matriz. Las sesiones, a su vez, hacían referencia a la fábrica de sesiones, que almacenaba una matriz de referencias a todas las clases de beans. Además, las sesiones conservaban referencias a instancias de clases de entidad y hacían referencia a las propias clases de bean.
Así, se encontró el punto de entrada al problema. Resultó ser referencias a sesiones antiguas de dbTransactionListeners. Después de que se solucionó el error y la matriz dbTransactionListeners comenzó a borrarse, el problema se solucionó.
Características del analizador de memoria Eclipse
Entonces, Eclipse Memory Analyzer le permite:
- Averigüe qué cadenas de objetos ocupan la cantidad máxima de memoria y determine los puntos de entrada a estas cadenas (sospechosos de fuga)
- Ver un árbol de todas las referencias de objetos entrantes (rutas más cortas al punto de acumulación)
- Ver un árbol de todas las referencias superiores a un objeto (Objeto-> Lista de objetos-> Con referencias superiores)
- Ver clases duplicadas cargadas por diferentes ClassLoaders (clases duplicadas)