Este artículo es una traducción de una de las publicaciones de neptune.ai y destaca las herramientas de aprendizaje profundo más interesantes presentadas en la conferencia de aprendizaje automático ICLR 2020.

¿Dónde se crea y se discute el aprendizaje profundo avanzado?
Uno de los principales temas de discusión sobre Deep Learning es ICLR , la principal conferencia de deep learning que tuvo lugar del 27 al 30 de abril de 2020. Con más de 5.500 asistentes y casi 700 presentaciones y charlas, este es un gran éxito para un evento completamente online. Puede encontrar información completa sobre la conferencia aquí , aquí o aquí .
Las reuniones sociales virtuales fueron uno de los aspectos más destacados de la ICLR 2020. Los organizadores decidieron lanzar un proyecto llamado “Herramientas y prácticas de código abierto en la investigación de DL de última generación”. El tema fue elegido debido al hecho de que el conjunto de herramientas correspondiente es una parte inevitable del trabajo de un investigador de aprendizaje profundo. Los avances en este ámbito han propiciado la proliferación de grandes ecosistemas (TensorFlow , PyTorch , MXNet), así como herramientas específicas más pequeñas que abordan las necesidades específicas de los investigadores.
El propósito del mencionado evento fue reunirse con los creadores y usuarios de herramientas de código abierto, así como compartir experiencias e impresiones entre la comunidad de Deep Learning. En total, se reunieron más de 100 personas, incluidos los principales inspiradores y líderes de proyectos, a quienes les dimos breves períodos de tiempo para presentar su trabajo. Los participantes y organizadores quedaron sorprendidos por la gran variedad y creatividad de las herramientas y bibliotecas presentadas.
Este artículo contiene proyectos brillantes presentados desde un escenario virtual.
Herramientas y bibliotecas
Las siguientes son ocho herramientas que se demostraron en ICLR con una descripción detallada de las capacidades.
Cada sección presenta respuestas a una serie de puntos de una manera muy sucinta:
- ¿Qué problema resuelve la herramienta / biblioteca?
- ¿Cómo ejecuto o creo un caso de uso mínimo?
- Recursos externos para profundizar en la biblioteca / herramienta.
- Perfil de los representantes del proyecto en caso de que se desee contactar con ellos.
Puede saltar a una sección específica a continuación o simplemente explorarlas todas una por una. ¡Disfruta leyendo!
AmpliGraph
Tema: Modelos de incrustación basados en gráficos de conocimiento.
Lenguaje de programación: Python
Por: Luca Costabello
Twitter | LinkedIn | GitHub | Los gráficos de conocimiento del sitio web
son una herramienta versátil para representar sistemas complejos. Ya sea una red social, un conjunto de datos bioinformáticos o datos de compras minoristas, el modelado de conocimiento gráfico permite a las organizaciones identificar conexiones importantes que de otro modo se pasarían por alto.
Revelar las relaciones entre los datos requiere modelos especiales de aprendizaje automático especialmente diseñados para trabajar con gráficos.
AmpliGraphEs un conjunto de modelos de aprendizaje automático con licencia de Apache2 para extraer incrustaciones de gráficos de conocimiento. Estos modelos codifican los nodos y los bordes del gráfico en forma vectorial y los combinan para predecir los hechos faltantes. Las incorporaciones de gráficos se utilizan en tareas como la parte superior del gráfico de conocimiento, el descubrimiento de conocimiento, la agrupación en clústeres basada en enlaces y otras.
AmpliGraph reduce la barrera de entrada para el tema de incrustación de gráficos para investigadores al hacer que estos modelos estén disponibles para usuarios sin experiencia. Aprovechando la API de código abierto, el proyecto apoya a una comunidad de entusiastas que utilizan gráficos en el aprendizaje automático. El proyecto le permite aprender cómo crear y visualizar incrustaciones a partir de gráficos de conocimiento basados en datos del mundo real y cómo usarlos en tareas posteriores de aprendizaje automático.
Para comenzar, a continuación se muestra un fragmento mínimo de código que entrena un modelo en uno de los conjuntos de datos de referencia y predice los enlaces faltantes:


AmpliGraph se desarrolló originalmente en Accenture Labs Dublin , donde se utiliza en varios proyectos industriales.
Automunge
Plataforma de preparación de datos tabulares
Lenguaje de programación: Python
Publicado por Nicholas Teague
Twitter | LinkedIn | GitHub | Sitio web de
AutomungeEs una biblioteca de Python que ayuda a preparar datos tabulares para su uso en el aprendizaje automático. A través del kit de herramientas del paquete, es posible realizar transformaciones simples para que la tecnología engeenering normalice, codifique y llene los vacíos. Las transformaciones se aplican a la submuestra de entrenamiento y luego se aplican de la misma manera a los datos de la submuestra de prueba. Las conversiones pueden realizarse automáticamente, asignarse desde una biblioteca interna o configurarse de manera flexible por el usuario. Las opciones de población incluyen "relleno basado en aprendizaje automático", en el que los modelos se entrenan para predecir la información faltante para cada columna de datos.
En pocas palabras:
automunge (.) Prepara datos tabulares para su uso en aprendizaje automático,
postmunge (.)los datos adicionales se procesan secuencialmente y con alta eficiencia.
Automunge está disponible para su instalación a través de pip:

Después de la instalación, simplemente importe la biblioteca a Jupyter Notebook para la inicialización:

Para procesar automáticamente los datos de la muestra de entrenamiento con los parámetros predeterminados, es suficiente usar el comando:

Además, para el procesamiento posterior de datos de la submuestra de prueba, es suficiente ejecutar un comando usando el diccionario postprocess_dict obtenido al llamar a automunge (.) Arriba:

Los parámetros assigncat y assigninfill en la llamada automunge (.) Se pueden usar para definir los detalles de conversión y los tipos de datos para llenar los vacíos. Por ejemplo, a un conjunto de datos con columnas 'columna1' y 'columna2' se le puede asignar una escala basada en valores mínimos y máximos ('mnmx') con relleno ML para columna1 y codificación one-hot ('texto') con relleno basado en el valor más común para column2. Los datos de otras columnas no especificadas explícitamente se procesarán automáticamente.

Sitio web de recursos y enlaces | GitHub | Breve presentación
DynaML
Aprendizaje automático para el
lenguaje de programación Scala : Scala
Publicado por: Mandar Chandorkar
Twitter | LinkedIn | GitHub
DynaML es una caja de herramientas de investigación y aprendizaje automático basada en Scala. Su objetivo es proporcionar al usuario un entorno de extremo a extremo que puede ayudar en:
- desarrollo / prototipado de modelos,
- trabajar con tuberías voluminosas y complejas,
- visualización de datos y resultados,
- reutilización de código en forma de scripts y cuadernos.
DynaML aprovecha las fortalezas del lenguaje y el ecosistema de Scala para crear un entorno que ofrece rendimiento y flexibilidad. Se basa en proyectos excelentes como Ammonite scala, Tensorflow-Scala y la biblioteca de cálculo numérico de alto rendimiento Breeze .
El componente clave de DynaML es REPL / shell, que tiene resaltado de sintaxis y un sistema avanzado de autocompletado.
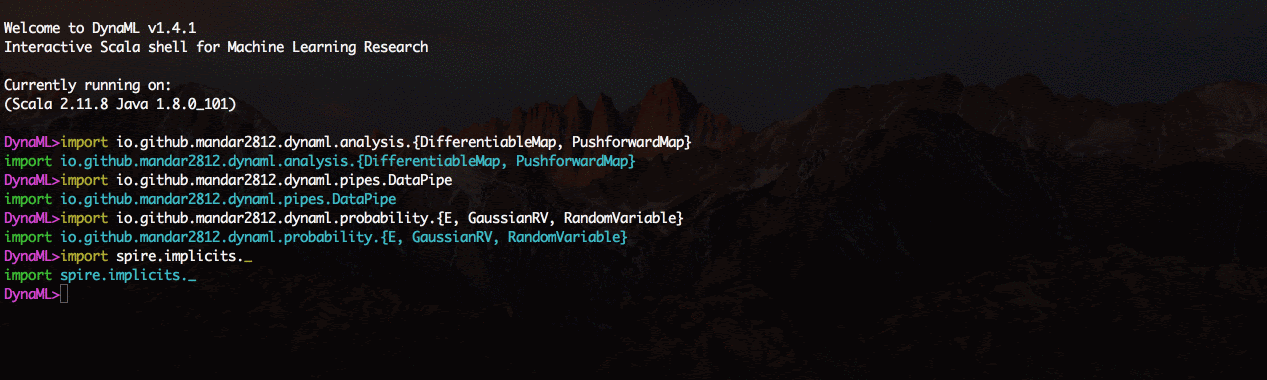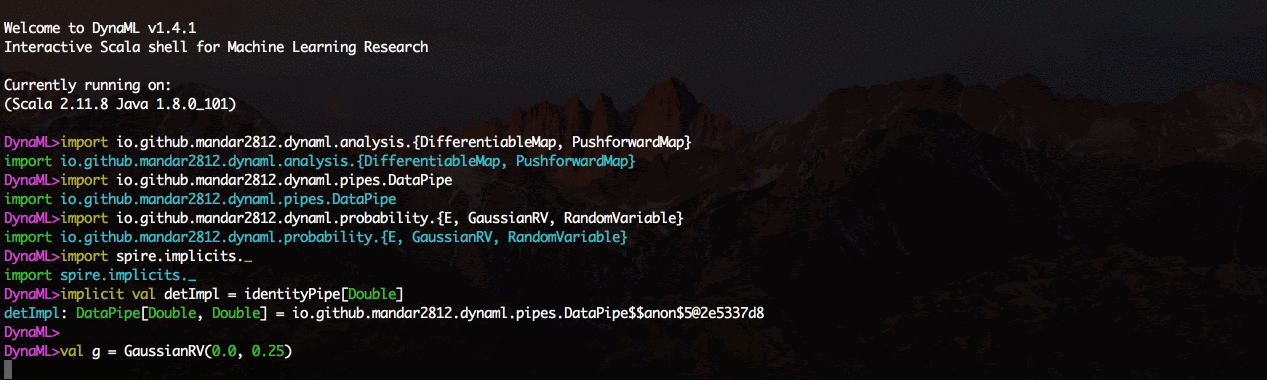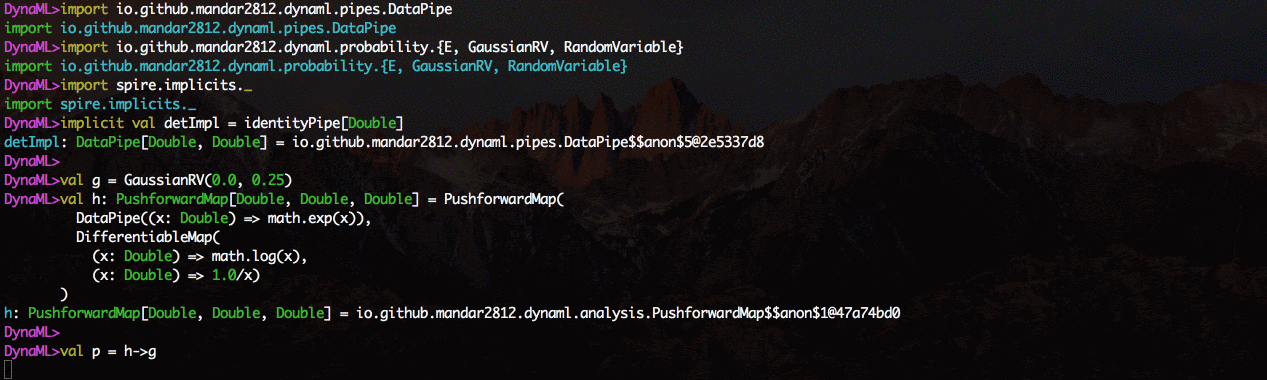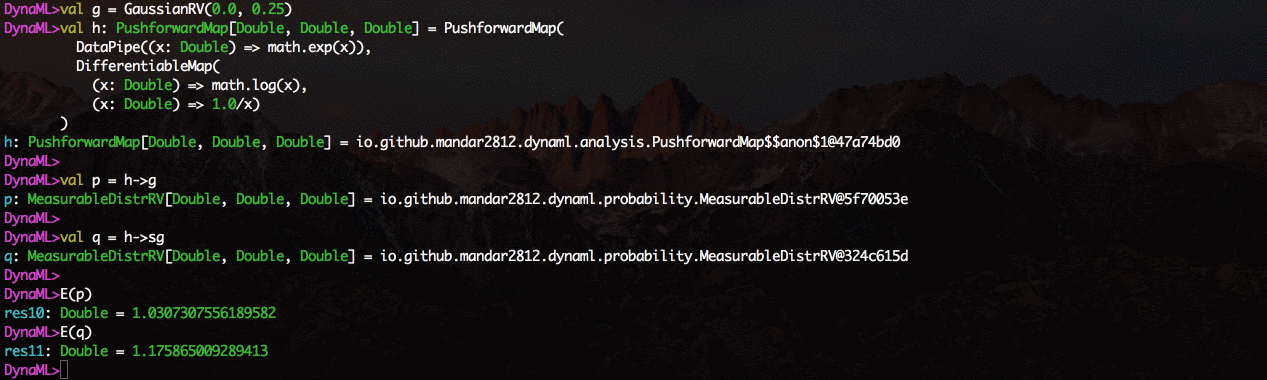
El entorno viene con soporte para visualización 2D y 3D, los resultados se pueden mostrar directamente desde el shell de comandos.

El módulo de canalizaciones de datos facilita la creación de canalizaciones de procesamiento de datos en una forma modular de fácil diseño. Cree funciones, envuélvalas usando el constructor DataPipe y construya bloques de funciones usando el operador>.
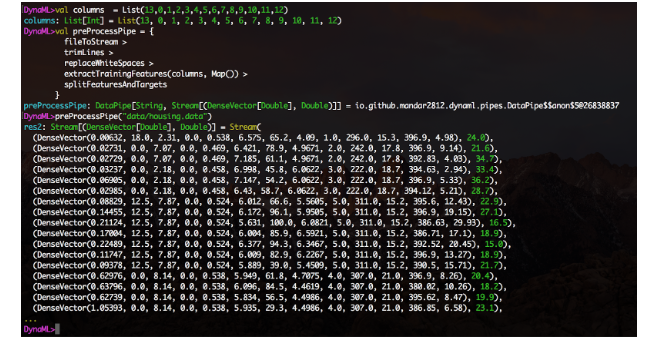
También está disponible una función experimental de integración de cuadernos de Jupyter, y el directorio de cuadernos del repositorio contiene varios ejemplos del uso del núcleo de DynaML-Scala Jupyter.

La Guía del usuario contiene una amplia referencia y documentación para ayudarlo a dominar y aprovechar al máximo el entorno DynaML.
A continuación se muestran algunas aplicaciones interesantes que destacan las fortalezas de DynaML:
- La física inspiró redes neuronales para resolver la ecuación de Burger y el sistema Fokker-Planck ,
- Entrenamiento de Deep Learning,
- Modelos de proceso gaussianos para el pronóstico de series de tiempo autorregresivas.
Recursos y enlaces de
GitHub | Manual de usuario
Hidra
Administrador de configuración y parámetros
Lenguaje de programación: Python
Publicado por Omry Yadan
Twitter | GitHub
Desarrollado por Facebook AI, Hydra es una plataforma Python que simplifica el desarrollo de aplicaciones de investigación al brindar la capacidad de crear y anular configuraciones a través de archivos de configuración y la línea de comandos. La plataforma también proporciona soporte para la expansión automática de parámetros, ejecución remota y paralela a través de complementos, administración automática de directorios de trabajo y sugerencias dinámicas de opciones de finalización presionando la tecla TAB.
El uso de Hydra también hace que su código sea más portátil en diferentes entornos de aprendizaje automático. Le permite cambiar entre estaciones de trabajo personales, clústeres públicos y privados sin cambiar su código. Lo anterior se logra mediante una arquitectura modular.
Ejemplo básico
Este ejemplo usa una configuración de base de datos, pero puede reemplazarla fácilmente con modelos, conjuntos de datos o cualquier otra cosa que necesite.
config.yaml:

my_app.py:

Puede anular cualquier cosa en la configuración desde la línea de comando:

Ejemplo de composición:
es posible que desee cambiar entre dos configuraciones de base de datos diferentes.
Cree esta estructura de directorio:

config.yaml:
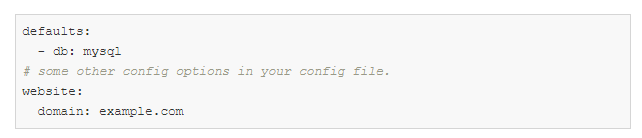
defaults es una directiva especial que le dice a Hydra que use db / mysql.yaml al componer un objeto de configuración.
Ahora puede elegir qué configuración de base de datos usar, así como anular los valores de los parámetros desde la línea de comando:

Consulte el tutorial para obtener más información.
Además, pronto llegarán nuevas funciones interesantes:
- configuraciones fuertemente tipadas (archivos de configuración estructurados),
- optimización de hiperparámetros utilizando complementos de Axe y Nevergrad,
- lanzar AWS con el complemento de iniciador de Ray,
- lanzamiento paralelo local a través del complemento joblib y mucho más.
Larq
Redes neuronales binarizadas
Lenguaje de programación: Python
Publicado por: Lucas Geiger
Twitter | LinkedIn | GitHub
Larq es un ecosistema de paquetes de Python de código abierto para construir, entrenar e implementar redes neuronales binarizadas (BNN). Los BNN son modelos de aprendizaje profundo en los que las activaciones y los pesos no se codifican con 32, 16 u 8 bits, sino solo con 1 bit. Esto puede acelerar drásticamente el tiempo de inferencia y reducir el consumo de energía, lo que hace que BNN sea ideal para aplicaciones móviles y periféricas.
El ecosistema de código abierto Larq tiene tres componentes principales.
- Larq — , . API, TensorFlow Keras. . Larq BNNs, .
- Larq Zoo BNNs, . Larq Zoo , BNN .
- Larq Compute Engine — BNNs. TensorFlow Lite MLIR Larq FlatBuffer, TF Lite. ARM64, , Android Raspberry Pi, , , BNN.
Los autores del proyecto están constantemente creando modelos más rápidos y expandiendo el ecosistema Larq a nuevas plataformas de hardware y aplicaciones de aprendizaje profundo. Por ejemplo, actualmente se está trabajando para integrar la cuantificación de 8 bits de un extremo a otro para poder entrenar e implementar combinaciones de redes binarias y de 8 bits utilizando Larq. Sitio web de
recursos y enlaces | GitHub larq / larq | GitHub larq / zoo | GitHub larq / compute-engine | Libros de texto | Blog | Gorjeo
McKernel
Métodos nucleares en tiempo logarítmicamente lineal
Lenguaje de programación: C / C ++
Publicado por J. de Curtó i Díaz
Twitter | Sitio web
La primera biblioteca C ++ de código abierto que proporciona una aproximación de características aleatorias de los métodos del kernel y un marco de aprendizaje profundo completo.
McKernel ofrece cuatro usos diferentes.
- Código Hadamard de código abierto autónomo y ultrarrápido. Para usar en áreas como compresión, cifrado o computación cuántica.
- Técnicas nucleares extremadamente rápidas. Se puede usar dondequiera que los métodos SVM (Método de vectores de soporte: ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%BE%D0%B4_%D0%BE%D0%BF%D0 % BE% D1% 80% D0% BD% D1% 8B% D1% 85_% D0% B2% D0% B5% D0% BA% D1% 82% D0% BE% D1% 80% D0% BE% D0% B2 ) son superiores al Deep Learning. Por ejemplo, algunas aplicaciones de robótica y algunos casos de uso de aprendizaje automático en la salud y otras áreas incluyen el aprendizaje federado y la selección de canales.
- La integración de Deep Learning y métodos nucleares permite el desarrollo de la arquitectura Deep Learning en una dirección antropomórfica / matemática a priori.
- Marco de investigación de aprendizaje profundo para resolver una serie de preguntas abiertas en el aprendizaje automático.
La ecuación que describe todos los cálculos se ve así:

Aquí los autores utilizan como pioneros el formalismo para explicar utilizando síntomas aleatorios como métodos de Deep Learning y técnicas nucleares . La base teórica se basa en cuatro gigantes: Gauss, Wiener, Fourier y Kalman. La base de esto fue establecida por Rahimi y Rekht (NIPS 2007) y Le et al. (ICML 2013).
Dirigirse al usuario típico
El público principal de McKernel son investigadores y profesionales en los campos de la robótica, el aprendizaje automático para la atención médica, el procesamiento de señales y las comunicaciones que necesitan una implementación eficiente y rápida en C ++. En este caso, la mayoría de las bibliotecas de aprendizaje profundo no cumplen las condiciones dadas, ya que se basan principalmente en implementaciones de Python de alto nivel. Además, la audiencia puede ser representantes de la comunidad más amplia de aprendizaje automático y aprendizaje profundo, que buscan mejorar la arquitectura de las redes neuronales utilizando métodos nucleares.
Un ejemplo visual súper simple para ejecutar una biblioteca sin perder tiempo se ve así:

¿Que sigue?
Aprendizaje integral, aprendizaje auto-supervisado, metaaprendizaje, integración con estrategias evolutivas, reducción significativa del espacio de búsqueda con NAS,…
Recursos y enlaces
GitHub | Presentación completa
Motor de entrenamiento SCCH
Rutinas de automatización para Deep Learning
Lenguaje de programación: Python
Publicado por: Natalya Shepeleva
Twitter | LinkedIn | Sitio web
Desarrollar una canalización típica para Deep Learning es bastante estándar: preprocesamiento de datos, diseño / implementación de tareas, entrenamiento de modelos y evaluación de resultados. Sin embargo, de un proyecto a otro, su uso requiere la participación de un ingeniero en cada etapa del desarrollo, lo que conduce a la repetición de las mismas acciones, duplicación de código y, finalmente, a errores.
El objetivo de SCCH Training Engine es unificar y automatizar el proceso de desarrollo de Deep Learning para los dos frameworks más populares, PyTorch y TensorFlow. La arquitectura de entrada única minimiza el tiempo de desarrollo y protege contra errores.
¿Para quien?
La arquitectura flexible de SCCH Training Engine tiene dos niveles de experiencia de usuario.
Principal. En este nivel, el usuario debe proporcionar datos para el entrenamiento y escribir los parámetros de entrenamiento del modelo en el archivo de configuración. Después de eso, todos los procesos, incluido el procesamiento de datos, el entrenamiento del modelo y la validación de los resultados, se realizarán automáticamente. El resultado será un modelo entrenado dentro de uno de los marcos principales.
Avanzado.Gracias al concepto de componente modular, el usuario puede modificar los módulos según sus necesidades, desplegando sus propios modelos y utilizando diversas funciones de pérdidas y métricas de calidad. Esta arquitectura modular le permite agregar características adicionales sin interferir con el funcionamiento de la tubería principal.
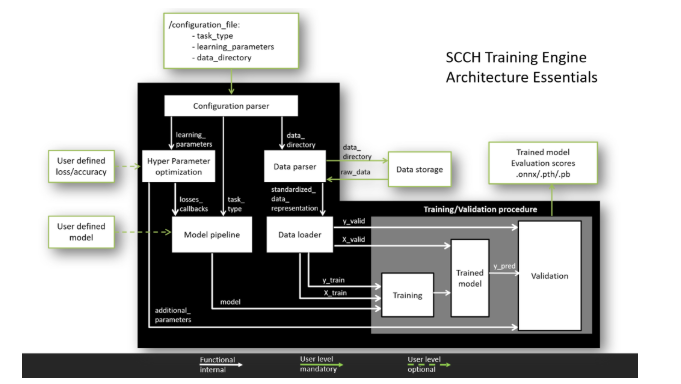
¿Qué puede hacer él?
Capacidades actuales:
- trabajar con TensorFlow y PyTorch,
- una canalización estandarizada para analizar datos de varios formatos,
- una canalización estandarizada para la formación de modelos y la validación de resultados,
- soporte para tareas de clasificación, segmentación y detección,
- soporte de validación cruzada.
Características en desarrollo:
- buscar hiperparámetros de modelo óptimos,
- carga de pesos del modelo y entrenamiento desde un punto de control específico,
- Soporte de arquitectura GAN.
¿Cómo funciona?
Para ver el motor de entrenamiento de SCCH en todo su esplendor, debe seguir dos pasos.
- Simplemente copie el repositorio e instale los paquetes requeridos usando el comando: pip install requirements.txt.
- Ejecute python main.py para ver un caso de estudio de MNIST con procesamiento y entrenamiento en un modelo LeNet-5.
Toda la información sobre cómo crear un archivo de configuración y cómo usar las funciones avanzadas se puede encontrar en la página de GitHub .
Lanzamiento estable con características principales: programado para finales de mayo de 2020.
Recursos y enlaces
GitHub | Sitio web
Tokenizadores
Tokenizadores de texto
Lenguaje de programación: Rust con Python API
Publicado por: Anthony Mua
Twitter | LinkedIn | GitHub
huggingface / tokenizers brinda acceso a los tokenizadores más modernos, con un enfoque en el rendimiento y el uso multipropósito. Tokenizers le permite entrenar y usar tokenizadores sin esfuerzo. Los tokenizadores pueden ayudarlo independientemente de si es un académico o un practicante en el campo de la PNL.
Características clave
- Velocidad extrema: la tokenización no debería ser un cuello de botella en su canalización y no es necesario que procese previamente sus datos. Gracias a la implementación nativa de Rust, la tokenización de gigabytes de texto solo lleva unos segundos.
- Desplazamientos / Alineación: proporciona control de desplazamiento incluso cuando se procesa texto con procedimientos de normalización complejos. Esto facilita la extracción de texto para tareas como NER o respuesta a preguntas.
- Preprocesamiento: se encarga de cualquier preprocesamiento necesario antes de introducir datos en su modelo de lenguaje (truncar, rellenar, agregar tokens especiales, etc.).
- Facilidad de aprendizaje: entrene a cualquier tokenizador en un nuevo chasis. Por ejemplo, aprender un tokenizador para BERT en un nuevo idioma nunca ha sido tan fácil.
- Varios idiomas: un paquete con varios idiomas. Puede comenzar a usarlo ahora mismo con Python, Node.js o Rust. ¡El trabajo en esta dirección continúa!
Ejemplo:

Y así:
- serialización en un solo archivo y carga en una línea para cualquier tokenizador,
- Soporte Unigram.
Hugging Face considera que su misión es ayudar a promover y democratizar la PNL.
Recursos y enlaces de
GitHub huggingface / transformers | GitHub huggingface / tokenizers | Gorjeo
Conclusión
En conclusión, cabe señalar que hay una gran cantidad de bibliotecas que son útiles para el Deep Learning y el aprendizaje automático en general, y no hay forma de describirlas todas en un solo artículo. Algunos de los proyectos descritos anteriormente serán útiles en casos específicos, algunos ya son bien conocidos y algunos proyectos maravillosos, desafortunadamente, no se incluyeron en el artículo.
En CleverDATA nos esforzamos por estar al día de las nuevas herramientas y bibliotecas útiles, y aplicamos activamente enfoques nuevos en nuestro trabajo relacionado con el uso de Deep Learning y Machine Learning. Por mi parte, me gustaría llamar la atención de los lectores sobre estas dos bibliotecas que no están incluidas en el artículo principal, pero que ayudan significativamente a trabajar con redes neuronales: Catalyst (https://catalyst-team.com ) y Albumentation ( https://albumentations.ai/ ).
Estoy seguro de que cada especialista en ejercicio tiene sus propias herramientas y bibliotecas favoritas, incluidas las poco conocidas por una amplia audiencia. Si le parece que alguna herramienta útil en su trabajo se ha pasado por alto innecesariamente, escríbala en los comentarios: incluso mencionarla en la discusión ayudará a proyectos prometedores a atraer nuevos seguidores, y el aumento de popularidad, a su vez, conduce a una mejora en la funcionalidad y el desarrollo de ellos mismos. Bibliotecas.
¡Gracias por su atención y espero que el conjunto de bibliotecas presentado sea de utilidad en su trabajo!