La historia descrita no es una fantasía, sino una descripción colectiva de un par de eventos en 2020. En las grandes empresas, un plan de recuperación ante desastres (DRP) siempre está disponible para este caso. En las corporaciones, los especialistas en continuidad del negocio son responsables de esto. Pero en las empresas medianas y pequeñas, la solución a este tipo de problemas recae en el departamento de TI. Debe comprender la lógica empresarial por sí mismo, comprender qué puede caer y dónde, idear protección e implementar.
Es genial si el profesional de TI logra negociar con la empresa y discutir la necesidad de protección. Pero he visto más de una vez cómo la empresa economizó una solución de recuperación ante desastres (DR), ya que la consideraba redundante. Cuando ocurrió un accidente, una recuperación prolongada amenazó con pérdidas y el negocio no estaba listo. Puede repetir todo lo que quiera: "Pero ya le dije": el servicio de TI aún tendrá que restaurar los servicios.

Desde la perspectiva de un arquitecto, te diré cómo evitar esta situación. En la primera parte del artículo mostraré el trabajo preparatorio: cómo discutir tres preguntas con el cliente para elegir herramientas de protección:
- ¿Qué estamos protegiendo?
- ¿De qué nos protegemos?
- ¿Qué tan fuerte estamos protegiendo?
En la segunda parte, hablaremos de las opciones para responder a la pregunta: con qué defender. Daré ejemplos de casos de cómo diferentes clientes construyen su protección.
Lo que protegemos: aclarar las funciones comerciales críticas
Es mejor comenzar la preparación discutiendo el plan de desastre con el cliente comercial. La principal dificultad aquí es encontrar un idioma común. Por lo general, al cliente no le importa cómo funciona la solución de TI. Le importa si el servicio puede realizar funciones comerciales y generar ingresos. Por ejemplo: si el sitio está funcionando y el sistema de pago está “mintiendo”, no hay recibos de los clientes y los “extremos” siguen siendo especialistas en TI.
Un profesional de TI puede tener dificultades para negociar por varias razones:
- El servicio de TI no es plenamente consciente del papel del sistema de información en los negocios. Por ejemplo, si no hay una descripción disponible de los procesos comerciales o un modelo comercial transparente.
- No todo el proceso depende del departamento de TI. Por ejemplo, cuando parte del trabajo lo realizan contratistas y los especialistas en TI no tienen influencia directa sobre ellos.
Estructuraría la conversación así:
- Explicamos a las empresas que los accidentes le ocurren a todo el mundo y que la recuperación lleva tiempo. Lo mejor es demostrar la situación, cómo ocurre y qué consecuencias son posibles.
- Demostramos que no todo depende del servicio de TI, pero estás listo para ayudar con un plan de acción en tu área de responsabilidad.
- Le pedimos al cliente empresarial que responda: si ocurre un apocalipsis, ¿qué proceso debería restaurarse primero? ¿Quién participa y cómo?
El negocio necesita una respuesta simple, por ejemplo: es necesario que el call center continúe registrando aplicaciones 24/7.
- - .
, .
: - , . 1 -, .
- , . :
- ( ),
- , ( ),
- ( ).
- ( ),
- Descubrimos los posibles puntos de falla: los nodos del sistema de los que depende el desempeño del servicio. Por separado, marcamos los nodos que son compatibles con otras empresas: operadores de telecomunicaciones, proveedores de hosting, centros de datos, etc. Con esto, puede volver al cliente comercial para el siguiente paso.
De qué protegemos: riesgos
Luego, averiguamos del cliente comercial contra qué riesgos estamos protegiendo en primer lugar. Dividiremos condicionalmente todos los riesgos en dos grupos:
- pérdida de tiempo debido al tiempo de inactividad del servicio;
- pérdida de datos por impacto físico, factores humanos, etc.
Las empresas tienen miedo de perder tanto tiempo como datos; todo esto conduce a una pérdida de dinero. Entonces nuevamente hacemos preguntas sobre cada grupo de riesgo:
- ¿Podemos estimar para este proceso cuánto valen la pérdida de datos y el tiempo perdido?
- ¿Qué datos no podemos perder?
- ¿Dónde no podemos permitir el tiempo de inactividad?
- ¿Qué eventos son más probables y más amenazantes para nosotros?
Después de la discusión, entenderemos cómo priorizar los puntos de falla.
Qué tan fuerte protegemos: RPO y RTO
Cuando se comprenden los puntos críticos de falla, calculamos las métricas de RTO y RPO.
Permítanme recordarles que RTO (objetivo de tiempo de recuperación) es el tiempo permitido desde el momento del accidente hasta la recuperación total del servicio. En el lenguaje comercial, este es el tiempo de inactividad aceptable. Si sabemos cuánto dinero generó el proceso, podemos calcular las pérdidas de cada minuto de inactividad y calcular la pérdida admisible.
RPO (objetivo de punto de recuperación) es un punto de recuperación de datos válido. Determina el tiempo en el que podemos perder datos. Desde el punto de vista empresarial, la pérdida de datos puede conllevar, por ejemplo, multas. Estas pérdidas también se pueden convertir en dinero.
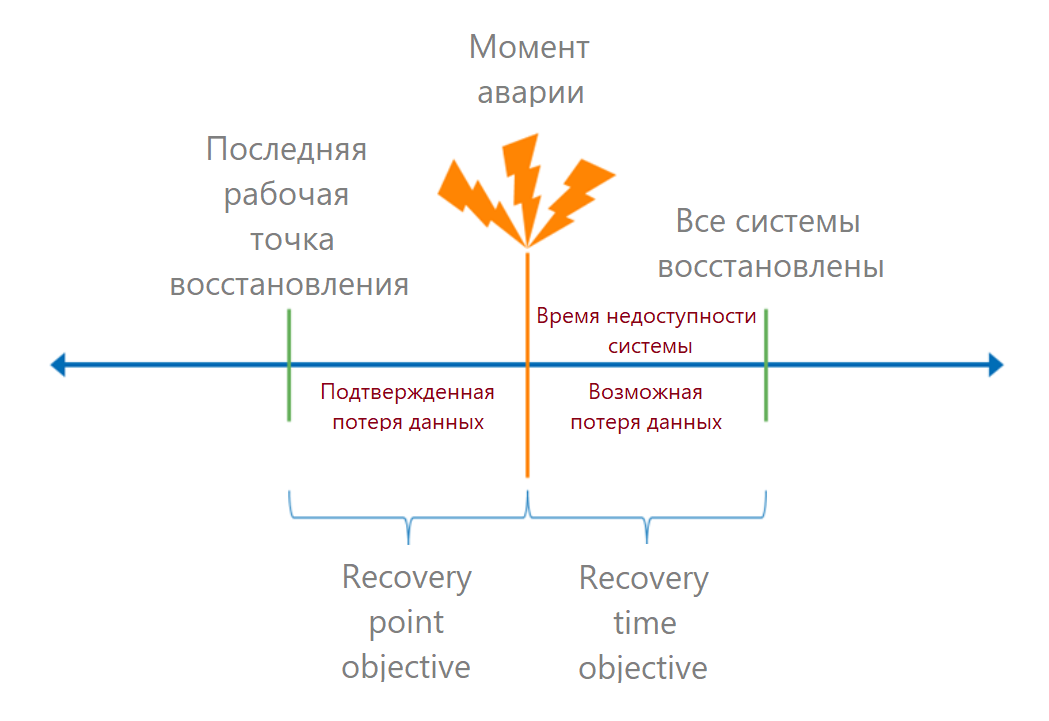
El tiempo de recuperación debe calcularse para el usuario final: cuánto tardará en iniciar sesión en el sistema. Entonces, primero agregamos los tiempos de recuperación de todos los eslabones de la cadena. Aquí a menudo cometen un error: toman el proveedor RTO del SLA y se olvidan de los otros términos.
Veamos un ejemplo específico. El usuario ingresa 1C, el sistema se abre con un error de base de datos. Se pone en contacto con el administrador del sistema. La base está en la nube, el administrador del sistema informa del problema al proveedor de servicios. Digamos que todas las comunicaciones tardan 15 minutos. En la nube, una base de datos de este tamaño se restaurará a partir de una copia de seguridad en una hora, por lo tanto, el RTO del lado del proveedor de servicios tardará una hora. Pero este no es el plazo final, para el usuario se le agregaron 15 minutos para detectar el problema.Estos cálculos mostrarán a la empresa de qué factores externos depende el período de recuperación. Por ejemplo, si la oficina está inundada, primero debe detectar la fuga y repararla. Llevará un tiempo que no dependa de TI.
A continuación, el administrador del sistema debe verificar que la base de datos sea correcta, conectarla a 1C e iniciar los servicios. Tarda otra hora, lo que significa que el RTO del lado del administrador ya es de 2 horas y 15 minutos. El usuario necesita otros 15 minutos: inicia sesión, comprueba que han aparecido las transacciones necesarias. 2 horas 30 minutos es el tiempo total de recuperación del servicio en este ejemplo.
Cómo protegemos: elección de herramientas para diferentes riesgos
Después de discutir todos los puntos, el cliente ya comprende el costo del accidente para la empresa. Ahora puede elegir herramientas y discutir el presupuesto. Mostraré mediante ejemplos de casos de clientes qué herramientas ofrecemos para diferentes tareas.
Comencemos con el primer grupo de riesgos: pérdidas debido al tiempo de inactividad del servicio. Las soluciones para esta tarea deben proporcionar un buen RTO.
-
— . , , , - .
, . . , 2 . , .
RTO: . .
: .
: , , - .
-
RTO, .
active-passive active-active. , . . , .
RTO: .
: , .
: - . .
: - . . DR , . .
. . -
, , 2 -. - , --. , .
RTO: 0.
: .
: , , .
: . :
- .
- . : «» «». «» , . «» . . .
, . . - .
-
, : . , . DR: VMware vCloud Availability (vCAV). on-premise . vCAV .
RPO RTO: 5 .
: , , . vCAV, , PAYG (10% ).
: 6 . : , — . , .
VMware vCloud Availability. - 5 . , - .
Todas las soluciones consideradas brindan alta disponibilidad, pero no lo salvan de la pérdida de datos debido a un virus de cifrado o un error accidental del empleado. En este caso, necesitamos copias de seguridad que proporcionen el RPO requerido.
5. No se olvide de las copias de seguridad
Todo el mundo sabe que necesita hacer copias de seguridad, incluso si tiene la mejor solución de recuperación ante desastres. Por tanto, recordaré brevemente algunos puntos.
Estrictamente hablando, la copia de seguridad no es DR. Y es por eso:
- Toma mucho tiempo. Si los datos se miden en terabytes, tardará más de una hora en recuperarse. Necesita restaurar, asignar una red, verificar qué se enciende, ver que los datos estén en orden. Por lo tanto, solo puede lograr un buen RTO si hay pocos datos.
- Es posible que los datos no se restauren la primera vez y debe reservar tiempo para una segunda acción. Por ejemplo, hay ocasiones en las que no sabemos exactamente cuándo se perdieron los datos. Digamos que la pérdida se notó a las 15.00 horas y se hacen copias cada hora. A partir de las 15.00 horas vigilamos todos los puntos de recuperación: 14:00, 13:00, etc. Si el sistema es crítico, intentamos minimizar la antigüedad del punto de restauración. Pero si no se encontraron los datos necesarios en la copia de seguridad nueva, tomamos el siguiente punto: este es un tiempo adicional.
Dicho esto, el programa de respaldo puede proporcionar el RPO requerido . Para las copias de seguridad, es importante proporcionar redundancia geográfica en caso de problemas con el sitio principal. Se recomienda mantener algunas de las copias de seguridad por separado.
El plan final de recuperación ante desastres debe incluir al menos 2 herramientas:
- Una de las opciones 1-4, que protegerá los sistemas de caídas y caídas.
- Copia de seguridad para proteger los datos contra pérdidas.
También vale la pena cuidar un canal de comunicación de respaldo en caso de que el proveedor principal de Internet falle. ¡Y voilá! - La RD sobre salarios mínimos ya está lista.