¡Hola! Mi nombre es Igor Narazin, soy el líder del equipo de logística del Delivery Club. Quiero contarte cómo construimos y transformamos nuestra arquitectura y cómo afecta a nuestros procesos de desarrollo.
Ahora Delivery Club (como todo el mercado de foodtech) está creciendo muy rápidamente, lo que crea una gran cantidad de desafíos para el equipo técnico, que se pueden resumir en dos de los criterios más importantes:
- Es necesario garantizar una alta estabilidad y disponibilidad de todas las partes de la plataforma.
- Al mismo tiempo, mantenga un alto ritmo de desarrollo de nuevas funciones.
Parece que estos dos problemas son mutuamente excluyentes: o transformamos la plataforma, tratando de hacer nuevos cambios lo menos posible hasta que terminamos, o desarrollamos rápidamente nuevas funciones sin cambios drásticos en el sistema.
Pero lo logramos (hasta ahora) ambos. Cómo hacemos esto se discutirá más a fondo.
En primer lugar, te contaré sobre nuestra plataforma : cómo la transformamos teniendo en cuenta los volúmenes de datos en constante crecimiento, qué criterios aplicamos a nuestros servicios y qué problemas enfrentamos en el camino.
En segundo lugar, compartiré cómo resolvemos el problema de entregar funciones sin entrar en conflicto con los cambios en la plataforma y sin una degradación innecesaria del sistema.
Empecemos por la plataforma.
Al principio había un monolito
Las primeras líneas del código de Delivery Club se escribieron hace 11 años, y en las mejores tradiciones del género, la arquitectura era un monolito en PHP. Durante 7 años se llenó de funcionalidad cada vez mayor hasta que se enfrentó a los problemas clásicos de la arquitectura monolítica.
Al principio, estábamos completamente satisfechos con él: era fácil de mantener, probar e implementar. Y hizo frente a las cargas iniciales sin problemas. Pero, como suele ser el caso, en algún momento alcanzamos tasas de crecimiento tales que nuestro monolito se convirtió en un cuello de botella muy peligroso:
- cualquier falla o problema en el monolito afectará absolutamente todos nuestros procesos;
- el monolito está rígidamente ligado a una pila específica que no se puede cambiar;
- teniendo en cuenta el crecimiento del equipo de desarrollo, resulta difícil realizar cambios: la alta conectividad de los componentes no permite la entrega rápida de funciones;
- el monolito no se puede escalar de forma flexible.
Esto nos llevó a la arquitectura de microservicios (sorpresa): mucho se ha dicho y escrito sobre sus méritos y deméritos. Lo principal es que resuelve uno de nuestros principales problemas y nos permite conseguir la máxima disponibilidad y tolerancia a fallos de todo el sistema. No me detendré en esto en este artículo, en su lugar te contaré con ejemplos cómo lo hicimos y por qué.
Nuestro principal problema era el tamaño del código base monolítico y la escasa experiencia del equipo en él (la plataforma es lo que llamamos antigua). Por supuesto, al principio solo queríamos tomar y cortar el monolito para resolver completamente el problema. Pero nos dimos cuenta muy rápidamente de que tomará más de un año, y la cantidad de cambios que se están realizando allí nunca permitirá que esto termine.
Por tanto, fuimos al revés: lo dejamos como está, y decidimos construir el resto de los servicios alrededor del monolito. Sigue siendo el punto principal de la lógica de procesamiento de pedidos y el maestro de datos, pero comienza a transmitir datos para otros servicios.
Ecosistema
Como dijo Andrey Evsyukov en un artículo sobre nuestros equipos, hemos destacado las principales áreas de áreas de dominio: I + D, Logística, Consumidor, Proveedor, Interno, Plataforma. Dentro de estas áreas, las principales áreas de dominio con las que trabajan los servicios ya se concentran: por ejemplo, para Logística, estos son mensajeros y pedidos, y para Vendor - restaurantes y puestos.
A continuación, necesitamos subir a un nivel superior y construir un ecosistema de nuestros servicios alrededor de la plataforma: el procesamiento de pedidos está en el centro y es el maestro de datos, el resto de los servicios se construyen alrededor de él. Al mismo tiempo, es importante para nosotros hacer que nuestras direcciones sean autónomas: si una parte falla, el resto continúa funcionando.
Con cargas bajas, construir el ecosistema necesario es bastante simple: nuestros procesos de procesamiento y almacenamiento de datos, y los servicios de referencia los solicitan según sea necesario.
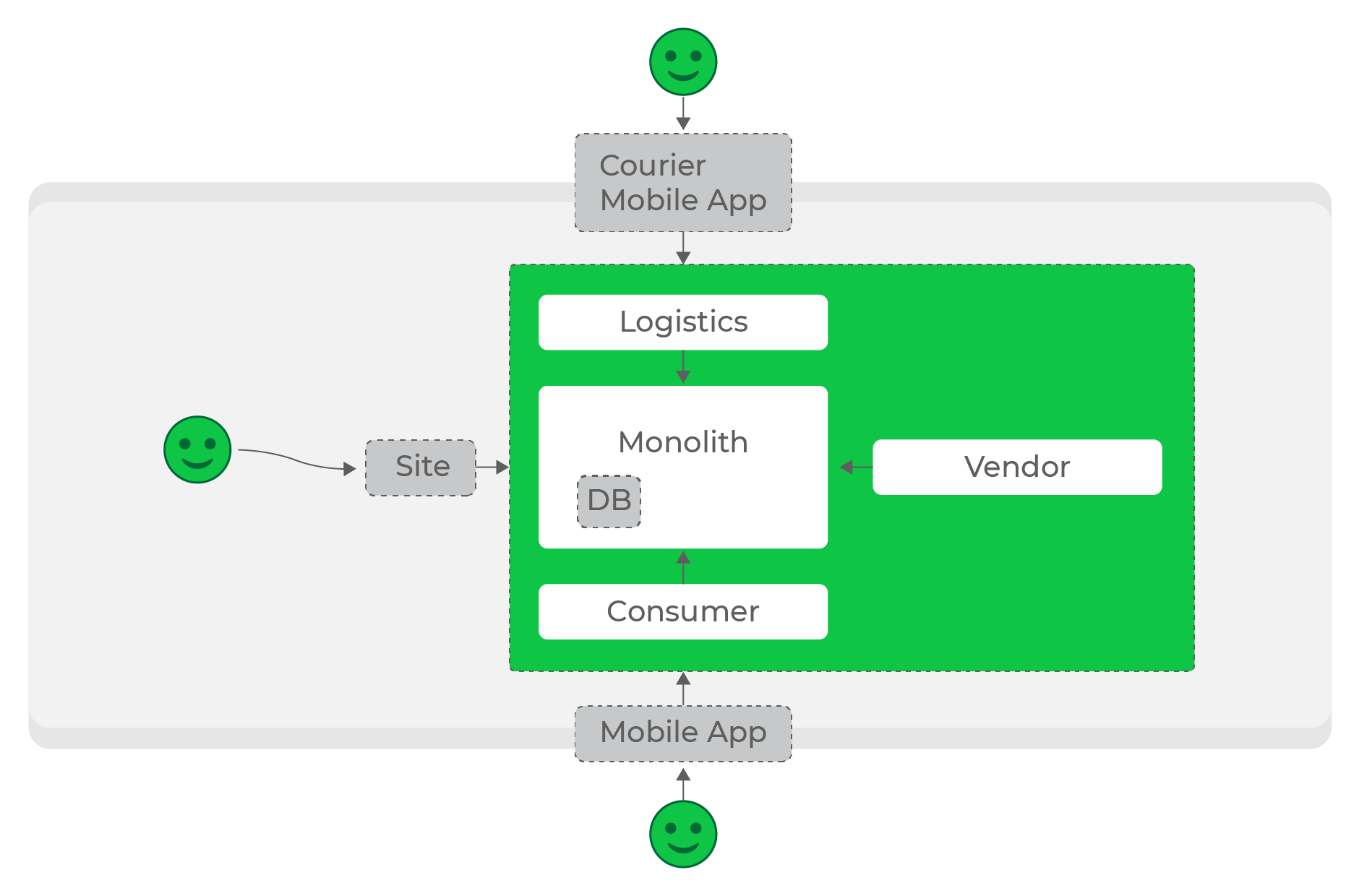 Cargas bajas, solicitudes sincrónicas, todo funciona muy bien.
Cargas bajas, solicitudes sincrónicas, todo funciona muy bien.
En las primeras etapas, hicimos precisamente eso: la mayoría de los servicios se comunicaban entre sí mediante solicitudes HTTP sincrónicas. Con cierta carga, esto estaba permitido, pero cuanto más crecía el proyecto y la cantidad de servicios, más problema se volvía.
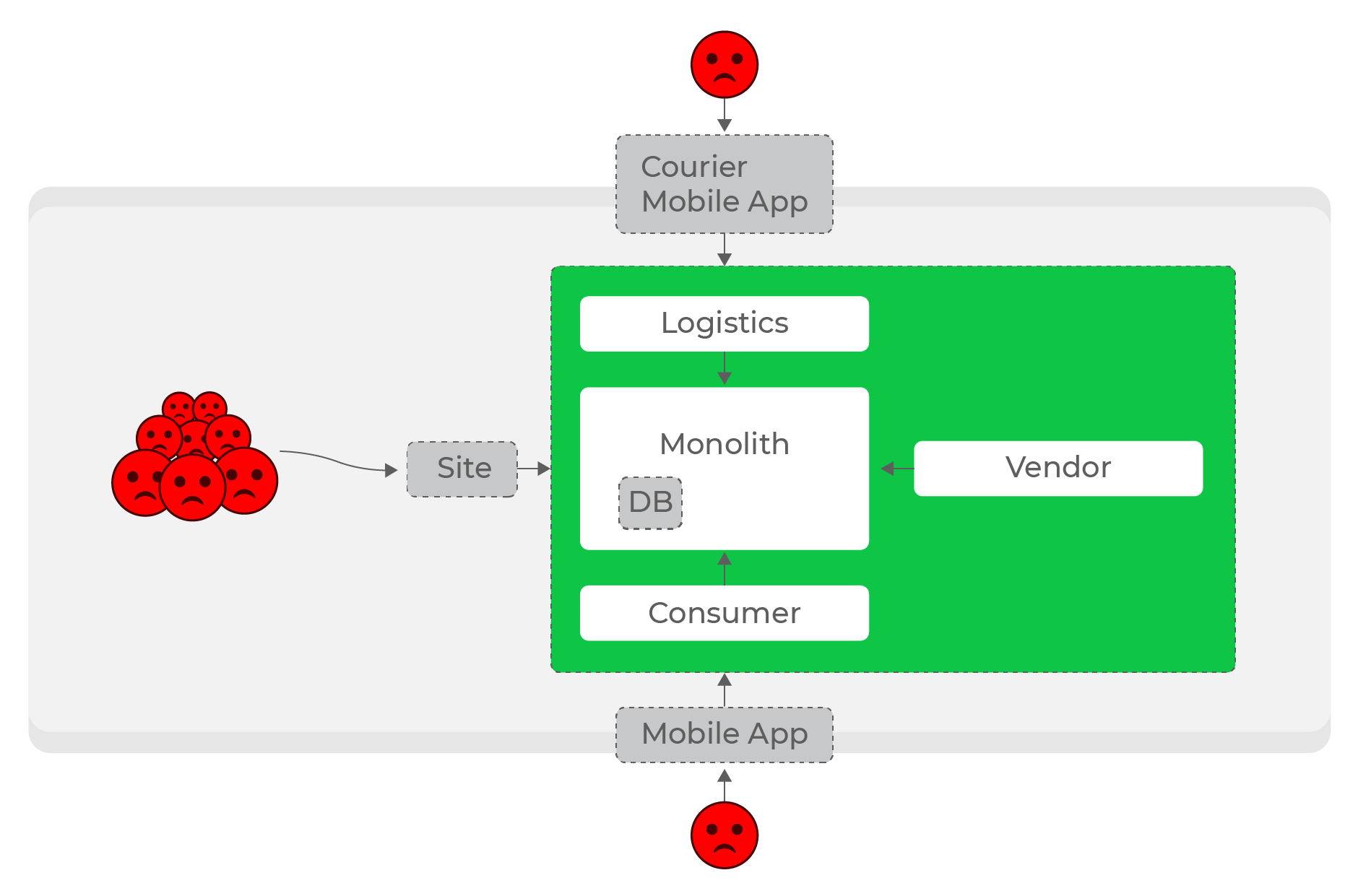
Altas cargas, solicitudes sincrónicas: todo el mundo sufre, incluso los usuarios de dominios completamente diferentes: los mensajeros.
Es aún más difícil hacer que los servicios sean autónomos dentro de las direcciones: por ejemplo, un aumento en la carga de la logística no debería afectar al resto del sistema. Con cualquier número de solicitudes síncronas, este es un problema sin solución. Evidentemente, era necesario abandonar las solicitudes sincrónicas y pasar a la comunicación asincrónica.
Bus de datos
Por lo tanto, obtuvimos muchos cuellos de botella en los que accedimos a los datos en modo síncrono. Estos lugares eran muy peligrosos en términos de aumento de carga.
He aquí un ejemplo. Quien haya realizado un pedido a través de Delivery Club al menos una vez sabe que después de que el mensajero recoge el pedido, la tarjeta se vuelve visible. En él puede seguir el movimiento del mensajero en tiempo real. Para esta característica se involucran varios microservicios, los principales son:
mobile-gatewayque es un backend para frontend para una aplicación móvil;courier-tracker, que almacena la lógica de recibir y enviar coordenadas;logistics-couriersque almacena estas coordenadas. Se envían desde aplicaciones móviles de mensajería.
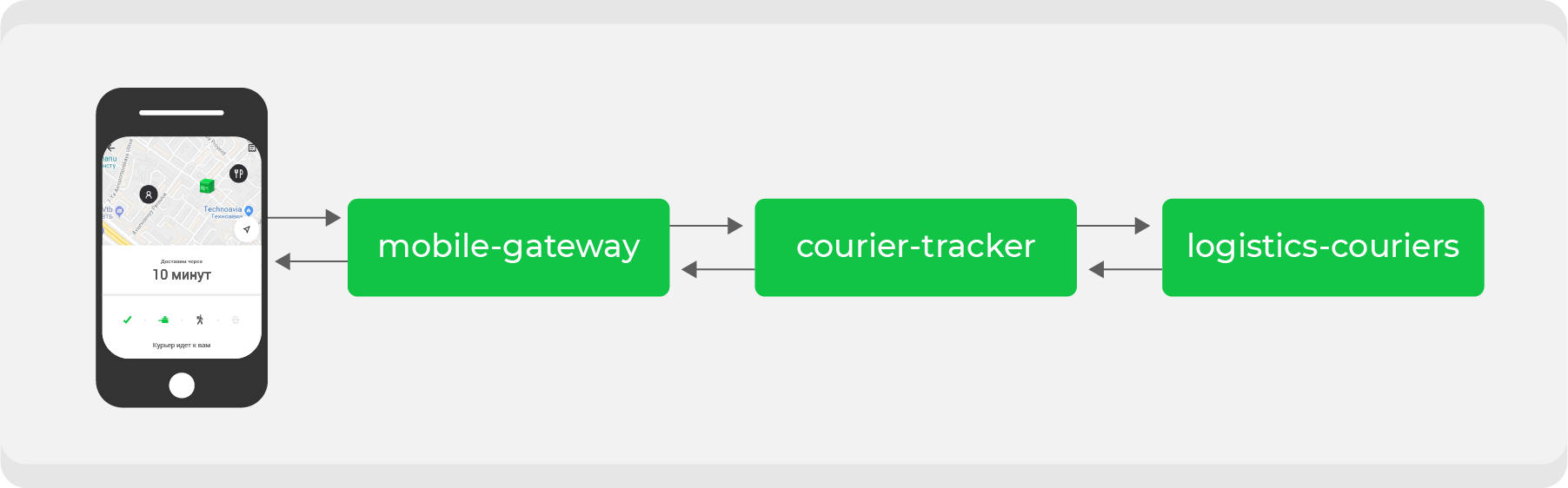
En el esquema original, todo esto funcionaba sincrónicamente: las solicitudes de la aplicación móvil una vez por minuto pasaban
mobile-gatewayal servicio courier-trackerque accedía logistics-couriersy recibía las coordenadas. Por supuesto, no todo fue tan simple en este esquema, pero al final todo se redujo a una simple conclusión: cuantas más órdenes activas tenemos, más solicitudes de coordenadas recibidas logistics-couriers.
Nuestro crecimiento es a veces impredecible y, lo que es más importante, rápido; es cuestión de tiempo antes de que este plan fracase. Esto significa que necesitamos rehacer el proceso para la interacción asincrónica: hacer que la solicitud de coordenadas sea lo más barata posible. Para hacer esto, necesitamos transformar nuestros flujos de datos.
Transporte
Ya hemos utilizado RabbitMQ, incluso para la comunicación entre servicios. Pero como principal medio de transporte, nos decidimos por la herramienta ya probada: Apache Kafka. Escribiremos un artículo detallado por separado al respecto, pero ahora me gustaría hablar brevemente sobre cómo lo usamos.
Cuando comenzamos a implementar Kafka como transporte, lo usamos en su forma original, conectándonos directamente con los corredores y enviándoles mensajes. Este enfoque nos permitió probar rápidamente Kafka en combate y decidir si continuar usándolo como nuestro principal medio de transporte.
Pero este enfoque tiene un inconveniente importante: los mensajes no tienen escritura ni validación; no sabemos con certeza qué formato de mensaje leemos del tema.
Esto aumenta el riesgo de errores e inconsistencias entre los servicios que brindan los datos y los que los consumen.
Para resolver este problema, escribimos un contenedor: un microservicio en Go, que oculta a Kafka detrás de su API. Esto agregó dos beneficios:
- validación de datos en el momento del envío y recepción. De hecho, estos son los mismos DTO, por lo que siempre confiamos en el formato de los datos esperados.
- rápida integración de nuestros servicios con este transporte.
Por lo tanto, trabajar con Kafka se ha vuelto lo más abstracto posible para nuestros servicios: solo funcionan con la API de nivel superior de este contenedor.
Volvamos al ejemplo
Al transferir la comunicación síncrona al bus de eventos, necesitamos invertir el flujo de datos: lo que pedimos ahora debería llegarnos a través de Kafka. En el ejemplo, estamos hablando de las coordenadas del mensajero, para lo cual ahora crearemos un tema especial y las produciremos a medida que las recibamos de los mensajeros por el servicio
logistics-couriers.
El servicio
courier-trackersolo tiene que acumular coordenadas en la cantidad requerida y por el período requerido. Como resultado, nuestro punto final se vuelve lo más simple posible: tomar datos de la base de datos del servicio y enviarlos a una aplicación móvil. El aumento de la carga sobre él ahora es seguro para nosotros.
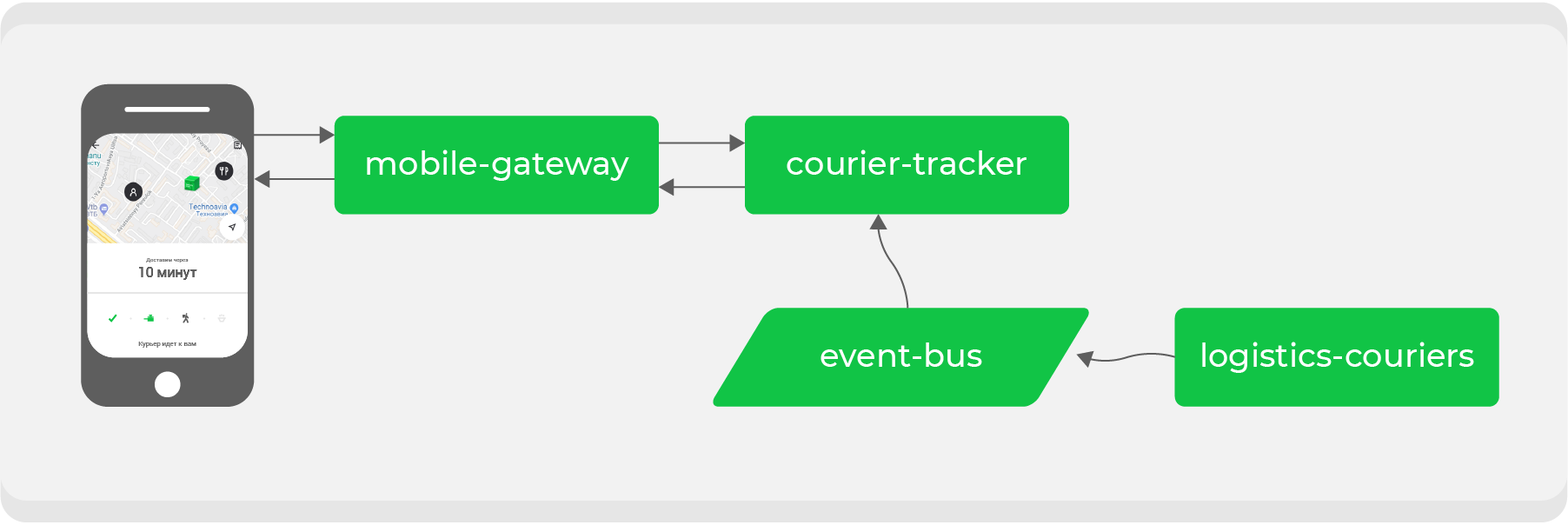
Además de resolver un problema específico, al final obtenemos un tema de datos con las coordenadas reales de los mensajeros, que cualquiera de nuestros servicios puede utilizar para sus propios fines.
Eventualmente consistencia
En este ejemplo, todo funciona bien, excepto que las coordenadas de los mensajeros no siempre estarán actualizadas en comparación con la opción sincrónica: en la arquitectura construida sobre la interacción asincrónica, surge la pregunta sobre la relevancia de los datos en cada momento. Pero no tenemos muchos datos críticos que debamos mantener siempre actualizados, por lo que este esquema es ideal para nosotros: sacrificamos la relevancia de cierta información para aumentar el nivel de disponibilidad del sistema. Pero garantizamos que al final, en todas las partes del sistema, todos los datos serán relevantes y consistentes (eventualmente coherencia).
Esta desnormalización de datos es necesaria cuando se trata de un sistema de alta carga y una arquitectura de microservicios: cada servicio en sí mismo asegura el almacenamiento de los datos que necesita para funcionar. Por ejemplo, una de las principales entidades de nuestro dominio es el mensajero. Muchos servicios operan con él, pero todos necesitan un conjunto de datos diferente: alguien necesita datos personales y alguien solo necesita información sobre el tipo de movimiento. El maestro de datos de este dominio producirá la entidad completa en el flujo, y los servicios acumularán las partes necesarias: por lo
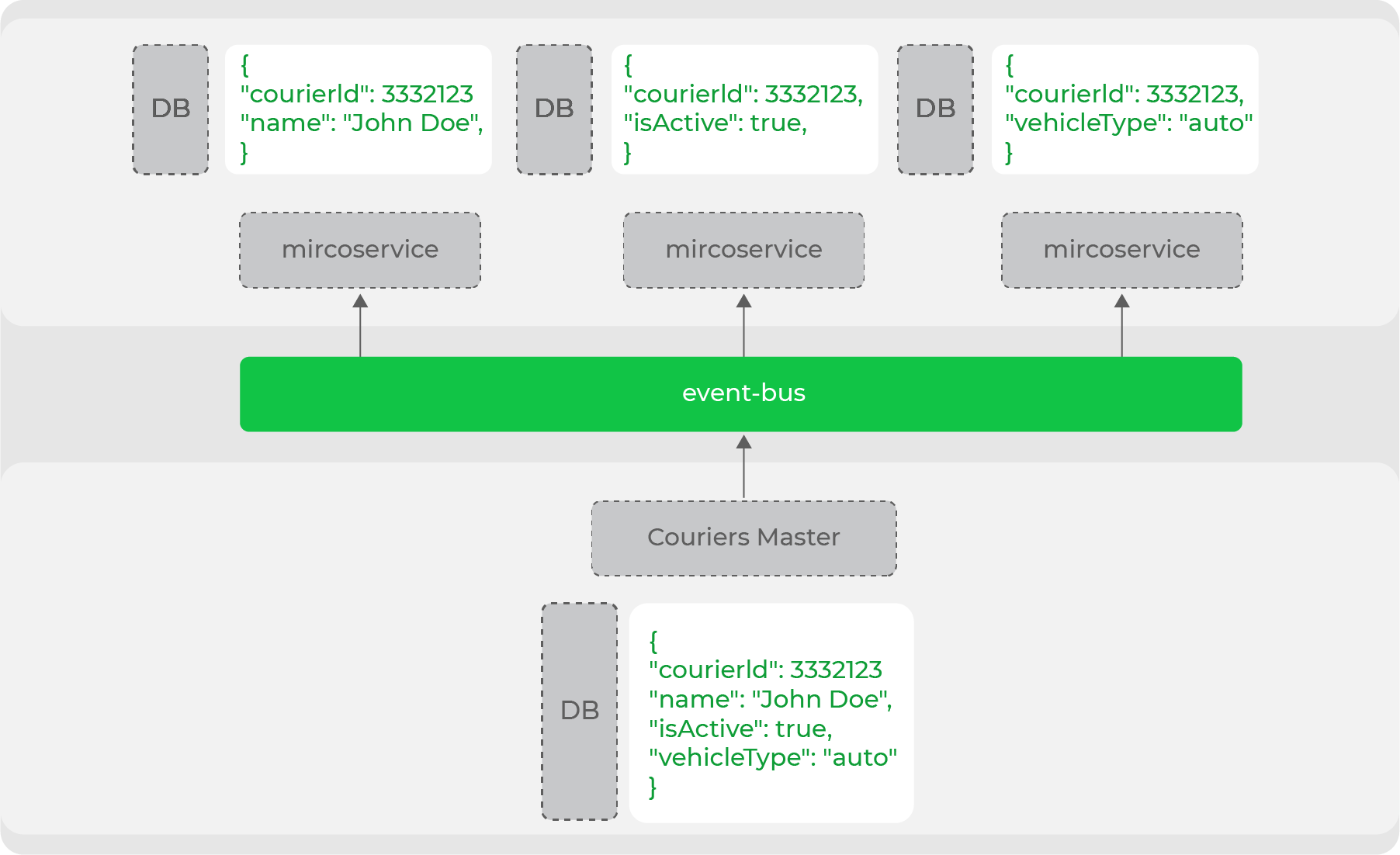
tanto, dividimos claramente nuestros servicios en los que son maestros de datos y los que usan estos datos. De hecho, este es un comercio sin cabeza de la arquitectura evolutiva : hemos separado claramente todos los "escaparates" (sitios web, aplicaciones móviles) de los productores de estos datos.
Desnormalización
Otro ejemplo: tenemos un mecanismo para notificaciones dirigidas a los mensajeros: estos son mensajes que les llegarán en la aplicación. En el lado del backend, hay una poderosa API para enviar tales notificaciones. En él se pueden configurar filtros de correo: desde un mensajero específico hasta grupos de mensajeros según determinados criterios.
El servicio es responsable de estas notificaciones
logistics-courier-notifications. Después de recibir una solicitud de envío, su tarea es generar mensajes para los mensajeros que han sido atacados. Para ello, necesita conocer la información necesaria sobre todos los mensajeros del Delivery Club. Y tenemos dos opciones para resolver este problema:
- cree un punto final en el lado del servicio: el asistente de datos de mensajería (
logistics-couriers), que podrá filtrar y devolver los mensajeros necesarios por los campos transmitidos; - almacenar toda la información necesaria directamente en el servicio, consumiéndola del tema correspondiente y guardando los datos por los que necesitaremos filtrar en el futuro.
Parte de la lógica para generar mensajes y filtrar mensajeros no se carga, se ejecuta en segundo plano, por lo que no se trata de cargas de servicio
logistics-couriers. Pero si elegimos la primera opción, nos enfrentamos a una serie de problemas:
- tendrá que soportar un endpoint altamente especializado en un servicio de terceros, que, muy probablemente, solo necesitaremos nosotros;
- Si selecciona un filtro que es demasiado ancho, entonces todos los mensajeros que simplemente no encajan en la respuesta HTTP se incluirán en la muestra y tendrá que implementar la paginación (e iterar sobre ella al sondear el servicio).
Obviamente, nos detuvimos en almacenar datos en el propio servicio. De forma autónoma y aislada realiza todo el trabajo, no accediendo a ningún lado, sino acumulando todos los datos necesarios de su tema de Kafka. Existe el riesgo de que recibamos un mensaje sobre la creación de un nuevo servicio de mensajería más adelante, y no se incluirá en alguna selección. Pero esta desventaja de una arquitectura asincrónica es inevitable.
Como resultado, hemos formulado varios principios importantes para diseñar servicios:
- El servicio debe tener una responsabilidad específica. Si todavía se necesita un servicio para su pleno funcionamiento, entonces se trata de un error de diseño, deben combinarse o la arquitectura debe revisarse.
- Observamos críticamente cualquier llamada sincrónica. Para los servicios en una dirección, esto es aceptable, pero para la comunicación entre servicios en diferentes direcciones, no
- No compartas nada. No vamos a la base de datos de servicios sin pasarlos por alto. Todas las solicitudes solo a través de la API.
- Especificación primero. Primero, describimos y aprobamos los protocolos.
Por lo tanto, al transformar iterativamente nuestro sistema de acuerdo con los principios y enfoques aceptados, llegamos a la siguiente arquitectura:
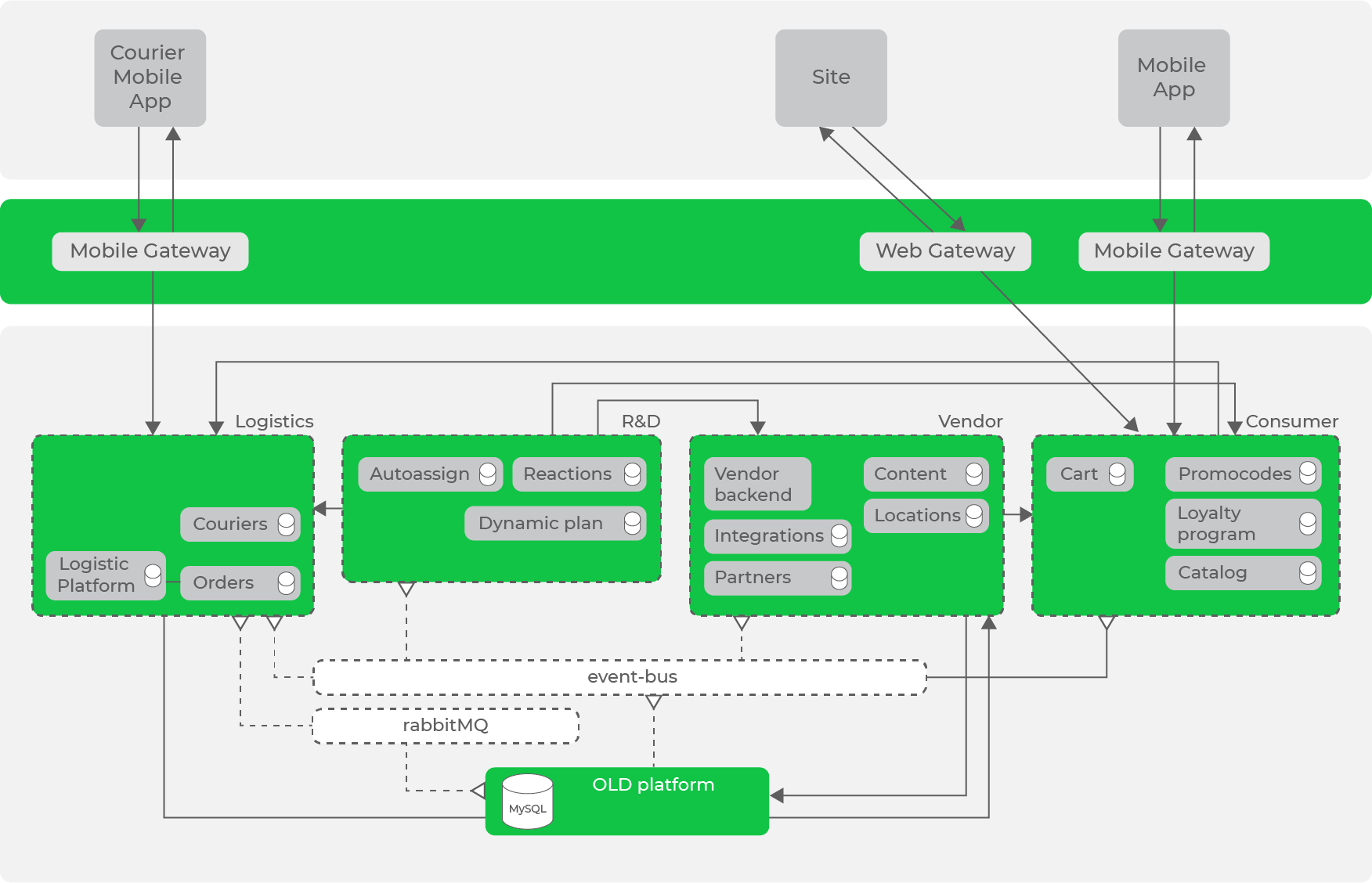
Ya tenemos un bus de datos en forma de Kafka, que ya tiene un número significativo de flujos de datos, pero todavía hay solicitudes sincrónicas entre direcciones.
Cómo planeamos desarrollar nuestra arquitectura
Delivery Club, como dije al principio, está creciendo rápidamente, estamos lanzando una gran cantidad de nuevas funciones a producción. Y experimentamos aún más ( Nikolay Arkhipov habló sobre esto en detalle ) y probamos hipótesis. Todo esto da lugar a una gran cantidad de fuentes de datos e incluso más opciones para su uso. Y la correcta gestión de los flujos de datos, que es muy importante para construir correctamente, esta es nuestra tarea.
A partir de ahora, continuaremos implementando los enfoques desarrollados para todos los servicios del Delivery Club: construir ecosistemas de servicios alrededor de una plataforma con transporte en forma de bus de datos.
La tarea principal es garantizar que la información sobre todos los dominios del sistema se suministre al bus de datos. Para nuevos servicios con nuevos datos, esto no es un problema: en la etapa de preparación del servicio, se verá obligado a transmitir sus datos de dominio a Kafka.
Pero además de los nuevos, contamos con grandes servicios heredados con datos sobre nuestros principales dominios: pedidos y mensajería. Es problemático transmitir estos datos "tal cual", ya que se almacenan repartidos en docenas de tablas, y será muy costoso construir la entidad final para producir todos los cambios cada vez.
Por lo tanto, decidimos utilizar Debezium para servicios antiguos ., que le permite transmitir información directamente desde tablas basadas en bin-log: como resultado, obtiene un tema listo para usar con datos sin procesar de la tabla. Pero no son adecuados para su uso en su forma original, por lo que a través de los transformadores a nivel de Kafka, se convertirán en un formato comprensible para los consumidores y se introducirán en un nuevo tema. Así, tendremos un conjunto de temas privados con datos brutos de tablas, que serán transformados a un formato conveniente y transmitidos a un tema público para uso de los consumidores.
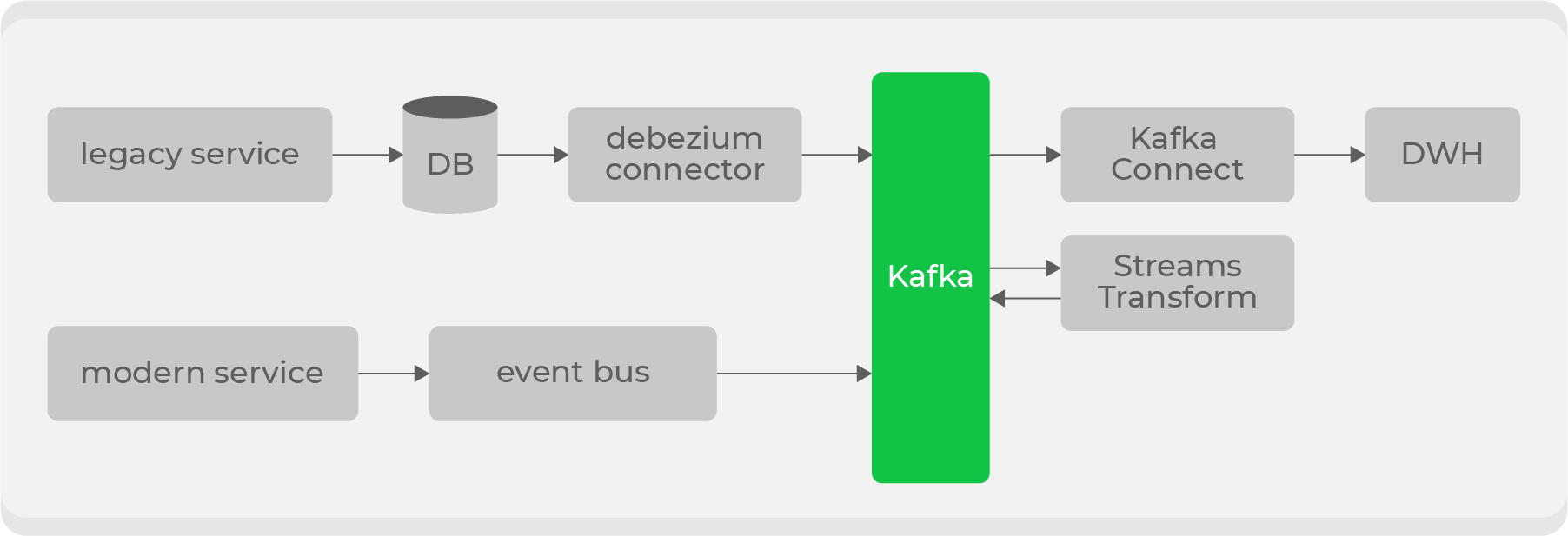
Habrá varios puntos de entrada para escribir a Kafka y diferentes tipos de temas, por lo que implementaremos derechos de acceso por rol en el lado del almacenamiento y agregaremos la validación del esquema en el lado del bus de datos a través de Confluent .
Más allá del bus de datos, los servicios consumirán datos de los temas necesarios. Y nosotros mismos usaremos estos datos para nuestros sistemas: por ejemplo, transmitir a través de Kafka Connect a ElasticSearch o DWH. Con esto último, el proceso será más complicado: para que la información que contiene esté disponible para todos, debe eliminarse cualquier dato personal.
También necesitamos resolver finalmente el problema con el monolito: todavía hay procesos críticos que soportaremos en el futuro cercano. Más recientemente, ya hemos implementado un servicio separado que se ocupa de la primera etapa de creación de un pedido: formación de una cesta, recibo y pago. Luego envía estos datos al monolito para su posterior procesamiento. Bueno, todas las demás operaciones ya no requieren sincronización.
Cómo hacer esta refactorización de forma transparente para los clientes
Te cuento un ejemplo más: un catálogo de restaurante. Obviamente, este es un lugar muy concurrido y decidimos trasladarlo a un servicio separado en Go. Para acelerar el desarrollo, hemos dividido la comida para llevar en dos etapas:
- Primero, dentro del servicio, vamos directamente a una réplica de la base de nuestro monolito y obtenemos datos de allí.
- Luego comenzamos a transmitir los datos que necesitamos a través de Debezium y a acumularlos en la base de datos del propio servicio.
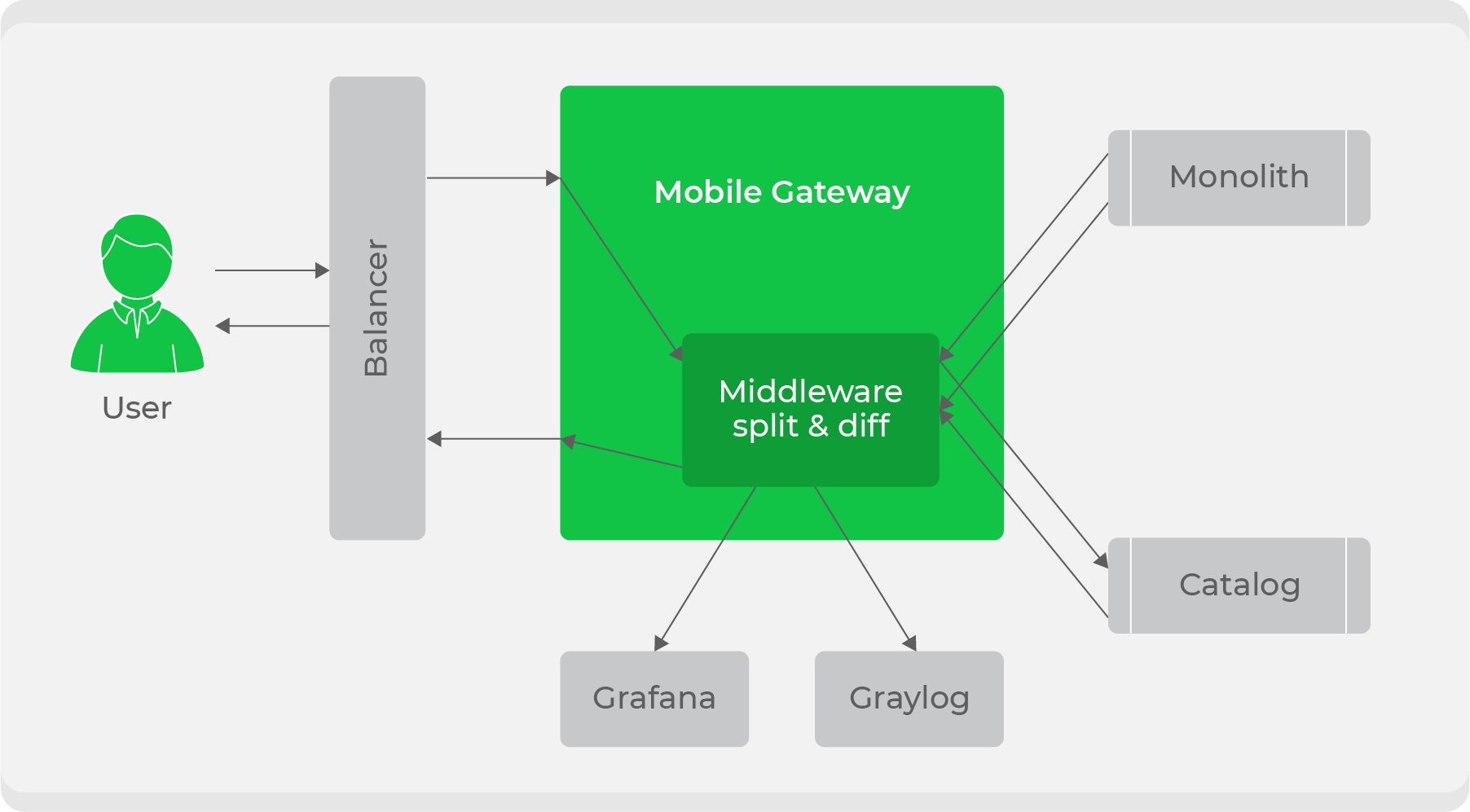
Cuando el servicio está listo, surge la pregunta de cómo integrarlo de manera transparente en el flujo de trabajo actual. Usamos un esquema de división de tráfico: todo el tráfico de los clientes se dirigía al servicio
mobile-gatewayy luego se dividía entre el monolito y el nuevo servicio. Inicialmente, continuamos procesando todo el tráfico a través del monolito, pero duplicamos algunos de ellos en un nuevo servicio, comparamos sus respuestas y anotamos registros sobre las discrepancias en nuestras métricas. Con esto, aseguramos la transparencia de probar el servicio en condiciones de combate. Después de eso, solo quedó cambiar gradualmente y aumentar el tráfico hasta que el nuevo servicio reemplace por completo el monolito.
En general, tenemos muchos planes e ideas ambiciosos. Estamos solo al comienzo de desarrollar nuestra estrategia adicional, mientras que su forma final no está clara y no se sabe si todo funcionará como esperamos. Tan pronto como implementemos y saquemos conclusiones, definitivamente compartiremos los resultados.
Junto con todos estos cambios conceptuales, continuamos desarrollando activamente y brindando funciones al producto, lo que lleva la mayor parte del tiempo. Aquí llegamos al segundo problema, del que hablé al principio: teniendo en cuenta el número de desarrolladores (180 personas), surge el tema de validar la arquitectura y la calidad de los nuevos servicios. Lo nuevo no debe degradar el sistema, debe integrarse correctamente desde el principio. Pero, ¿cómo controlar esto a escala industrial?
Comité de Arquitectura
La necesidad no surgió de inmediato. Cuando el equipo de desarrollo era pequeño, cualquier cambio en el sistema era fácil de controlar. Pero cuanta más gente hay, más difícil es hacerlo.
Esto da lugar tanto a problemas reales (el servicio no pudo soportar la carga debido a un diseño inadecuado) como conceptuales (“caminemos sincrónicamente aquí, la carga es pequeña”).
Está claro que la mayoría de los problemas se resuelven a nivel de equipo. Pero si estamos hablando de algún tipo de integración compleja en el sistema actual, es posible que el equipo simplemente no tenga suficiente experiencia. Por eso, quería crear algún tipo de asociación de personas de todas las direcciones, a las que se pudiera acudir con cualquier pregunta sobre arquitectura y obtener una respuesta exhaustiva.
Entonces llegamos a la creación de un comité de arquitectura, que incluye líderes de equipo, líderes de dirección y CTO. Nos reunimos cada dos semanas y discutimos los cambios importantes planificados en el sistema o simplemente resolvemos problemas específicos.
Como resultado, cerramos el problema con el control de grandes cambios, la cuestión del enfoque general de la calidad del código en Delivery Club permanece: los problemas específicos del código o marco en diferentes equipos se pueden resolver de diferentes maneras. Llegamos a los gremios en el modelo de Spotify: son uniones de personas que no son indiferentes a alguna tecnología. Por ejemplo, existen los gremios Go, PHP y Frontend.
Desarrollan estilos de programación uniformes, enfoques de diseño y arquitectura, ayudan a formar y mantener una cultura de ingeniería.al más alto nivel. También tienen su propio backlog, dentro del cual mejoran herramientas internas, por ejemplo, nuestra plantilla Go para microservicios.
Código de producto
Además del hecho de que los cambios importantes pasan por el comité de arquitectura y los gremios monitorean la cultura del código en general, todavía tenemos una etapa importante en la preparación del servicio para la producción: la elaboración de una lista de verificación en Confluence. Primero, al elaborar una lista de verificación, el desarrollador vuelve a evaluar su decisión; en segundo lugar, este es un requisito operativo, ya que necesitan comprender qué tipo de nuevo servicio aparece en producción.
La lista de verificación generalmente indica:
- responsable del servicio (suele ser el líder técnico del servicio);
- enlaces al tablero con alertas personalizadas;
- descripción del servicio y enlace a Swagger;
- una descripción de los servicios con los que interactuará;
- carga estimada en el servicio;
- health-check. URL, . Health-check - : 200, , - . , health check URL’ , , , PostgreSQL Redis.
Las alertas de servicio se diseñan en la etapa de aprobación arquitectónica. Es importante que el desarrollador comprenda que el servicio está vivo y tenga en cuenta no solo las métricas técnicas, sino también las del producto. Esto no significa conversiones comerciales, sino métricas que muestran que el servicio está funcionando como debería.
Por ejemplo, puede tomar el servicio ya mencionado anteriormente
courier-tracker, que rastrea a los mensajeros en el mapa. Una de las principales métricas que contiene es la cantidad de mensajeros cuyas coordenadas se actualizan. Si de repente algunas rutas no se actualizan durante mucho tiempo, aparece una alerta "algo salió mal". Tal vez en algún lugar no fueron a buscar los datos, o ingresaron incorrectamente a la base de datos, o algún otro servicio se cayó. Esta no es una métrica técnica o de producto, pero muestra la viabilidad del servicio.
Para las métricas, usamos Graylog y Prometheus, creamos paneles y configuramos alertas en Grafana.
A pesar del volumen de preparación, la entrega de servicios a producción es bastante rápida: todos los servicios se empaquetan inicialmente en Docker, se implementan en el escenario automáticamente después de que se forma el gráfico escrito para Kubernetes, y luego todo se decide con un botón en Jenkins.
El despliegue de un nuevo servicio a prod consiste en asignar una tarea a los administradores en Jira, que proporciona toda la información que preparamos anteriormente.
Bajo el capó
Ahora tenemos 162 microservicios escritos en PHP y Go. Se distribuyeron entre servicios aproximadamente del 50% al 50%. Inicialmente, reescribimos algunos servicios de alta carga en Go. Luego quedó claro que Go es más fácil de mantener y monitorear en producción, tiene un umbral de entrada bajo, por lo que recientemente hemos estado escribiendo servicios solo en él. No hay ningún propósito para reescribir los servicios PHP restantes en Go: hace frente a sus funciones con bastante éxito.
En los servicios PHP, tenemos Symfony, además del cual usamos nuestro propio pequeño marco. Impone una arquitectura común a los servicios, gracias a la cual bajamos el umbral para ingresar el código fuente de los servicios: no importa qué servicio abra, siempre estará claro qué hay en él y dónde. Y el marco también encapsula la capa de transporte de comunicación entre servicios, para el desarrollador, una solicitud a un servicio de terceros se ve en un alto nivel de abstracción:
Aquí formamos el DTO de la solicitud ($courierResponse = $this->courierProtocol->get($courierRequest);
$courierRequest), llamamos al método del objeto de protocolo de un servicio específico, que es un envoltorio sobre un punto final específico. Bajo el capó, nuestro objeto se $courierRequestconvierte en un objeto de solicitud, que se llena con campos del DTO. Todo esto es flexible: los campos se pueden insertar tanto en los encabezados como en la propia URL de la solicitud. A continuación, la solicitud se envía a través de cURL, obtenemos el objeto Respuesta y lo transformamos nuevamente en el objeto que esperamos $courierResponse.
Esto permite a los desarrolladores centrarse en la lógica empresarial, sin detalles de interacción en un nivel bajo. Los objetos de los protocolos, las solicitudes y las respuestas de los servicios se encuentran en un repositorio separado: el SDK de este servicio. Gracias a esto, cualquier servicio que quiera utilizar sus protocolos recibirá todo el paquete de protocolos mecanografiados después de importar el SDK.
Pero este proceso tiene un gran inconveniente: los repositorios con el SDK son difíciles de mantener, porque todos los DTO se escriben manualmente y la generación de código conveniente no es fácil de hacer: hubo intentos, pero al final, dada la transición a Go, no invirtieron tiempo en él.
Como resultado, los cambios en el protocolo de servicio pueden convertirse en varias solicitudes de extracción: en el servicio en sí, en su SDK y en un servicio que necesita este protocolo. En este último, necesitamos aumentar la versión del SDK importado para que los cambios lleguen allí. Esto a menudo genera preguntas de los nuevos desarrolladores: "Acabo de cambiar el parámetro, ¿por qué necesito hacer tres solicitudes a tres repositorios diferentes?"
En Go, todo es mucho más simple: tenemos un excelente generador de código (Sergey Popov escribió un artículo detallado sobre esto), gracias a lo cual se escribe todo el protocolo, y ahora se está discutiendo incluso la opción de almacenar todas las especificaciones en un repositorio separado. Por lo tanto, si alguien cambia la especificación, todos los servicios que dependen de ella comenzarán a usar inmediatamente la versión actualizada.
Radar técnico
Además de los ya mencionados Go y PHP, utilizamos una gran cantidad de otras tecnologías. Varían de una dirección a otra y dependen de tareas específicas. Básicamente, en el backend usamos:
Python, sobre el que escribe el equipo de Data Science.KotlinySwift- para el desarrollo de aplicaciones móviles.PostgreSQLcomo base de datos, pero algunos servicios más antiguos todavía ejecutan MySQL. En microservicios, utilizamos varios enfoques: cada servicio tiene su propia base de datos y no comparte nada; no vamos a las bases de datos sin pasar por los servicios, solo a través de su API.ClickHouse- para servicios altamente especializados relacionados con la analítica.RedisyMemcachedcomo almacenamiento en memoria.
Al elegir una tecnología, nos guiamos por principios especiales . Uno de los principales requisitos es la facilidad de uso: utilizamos la tecnología más simple y comprensible para el desarrollador, adhiriéndonos al stack aceptado siempre que sea posible. Para aquellos que quieran conocer toda la pila de tecnologías específicas, hemos compilado un radar técnico muy detallado .
Larga historia corta
Como resultado, cambiamos de una arquitectura monolítica a una de microservicio, y ahora ya tenemos grupos de servicios unidos por direcciones (áreas de dominio) alrededor de la plataforma, que es el núcleo y el maestro de datos.
Tenemos una visión de cómo reorganizar nuestros flujos de datos y cómo hacerlo sin afectar la velocidad del desarrollo de nuevas funciones. En el futuro, definitivamente le diremos adónde nos llevó esto.
Y gracias a la transferencia activa de conocimiento y un proceso formalizado de realizar cambios, somos capaces de entregar una gran cantidad de funcionalidades que no ralentizan el proceso de transformación de nuestra arquitectura.
Eso es todo para mí, ¡gracias por leer!