
Presentamos una estructura de árbol de decisiones interactiva y personalizable escrita en Python. Esta implementación es adecuada para extraer conocimiento de los datos, probar la intuición, mejorar su comprensión del funcionamiento interno de los árboles de decisión y explorar relaciones alternativas de causa y efecto para su problema de aprendizaje. Puede usarse como parte de algoritmos, visualizaciones e informes más complejos, para cualquier propósito de investigación, y como una plataforma accesible para probar fácilmente sus ideas de algoritmos de árbol de decisión.
TL; DR
- Repositorio HDTree
- Cuaderno complementario en el interior
examples. El directorio del repositorio está aquí (todas las ilustraciones que veas aquí se generarán en el bloc de notas). Puede crear ilustraciones usted mismo.
¿De qué trata la publicación?
Otra implementación de árboles de decisión que escribí como parte de mi tesis. El trabajo se divide en tres partes de la siguiente manera:
- Intentaré explicar por qué decidí tomarme mi tiempo para idear mi propia implementación de árboles de decisión. Enumeraré algunas de sus características , pero también las desventajas de la implementación actual.
- Le mostraré el uso básico de HDTree con algunos fragmentos de código y algunos detalles explicados a lo largo del camino.
- Consejos sobre cómo personalizar y ampliar HDTree con sus ideas.
Motivación y antecedentes
Para mi tesis, comencé a trabajar con árboles de decisión. Mi objetivo ahora es implementar un modelo ML centrado en el ser humano donde HDTree (Human Decision Tree, para el caso) es un ingrediente adicional que se aplica como parte de la IU real para ese modelo. Aunque esta historia es exclusivamente sobre HDTree, podría escribir una secuela detallando los otros componentes.
Características de HDTree y comparación con los árboles de decisión de scikit learn
Naturalmente, me encontré con una implementación de árbol de decisiones
scikit-learn[4]. La implementación sckit-learntiene muchas ventajas:
- Es rápido y optimizado;
- Escrito en dialecto Cython. Cython compila en código C (que, a su vez, se compila en binario), mientras sigue interactuando con el intérprete de Python;
- Sencillo y conveniente;
- Mucha gente en ML sabe cómo trabajar con modelos
scikit-learn. Obtén ayuda en todas partes gracias a su base de usuarios; - Ha sido probado en condiciones de combate (es usado por muchos);
- Simplemente funciona;
- Admite una variedad de técnicas de pre-recorte y post-recorte [6] y proporciona muchas características (por ejemplo, recorte con un costo mínimo y pesos de muestra);
- Soporta renderizado básico [7].
Sin embargo, ciertamente tiene algunas desventajas:
- No es trivial cambiar, en parte debido al dialecto Cython bastante inusual (vea las ventajas arriba);
- No hay forma de tener en cuenta el conocimiento del usuario sobre el área temática o cambiar el proceso de aprendizaje;
- La visualización es bastante minimalista;
- No hay soporte para características categóricas;
- Sin soporte para valores perdidos;
- La interfaz para acceder a los nodos y atravesar el árbol es engorrosa y poco intuitiva;
- Sin soporte para valores perdidos;
- Solo particiones binarias (ver más abajo);
- No hay particiones multivariadas (ver más abajo).
Características de HDTree
HDTree ofrece una solución a la mayoría de estos problemas, pero sacrifica muchos de los beneficios de la implementación de scikit-learn. Volveremos a estos puntos más adelante, así que no se preocupe si aún no comprende la siguiente lista completa:
- Interactúa con el comportamiento de aprendizaje;
- Los componentes principales son modulares y bastante fáciles de ampliar (implementar una interfaz);
- Escrito en Python puro (más disponible)
- Tiene una visualización rica;
- Admite datos categóricos;
- Soporta valores perdidos;
- Admite la división multivariante;
- Tiene una interfaz de navegación conveniente a través de la estructura de árbol;
- Admite particiones n-arias (más de 2 nodos secundarios);
- Solución de representaciones textuales;
- Fomenta la explicabilidad imprimiendo texto legible por humanos.
Desventajas:
- Lento;
- No probado en batallas;
- La calidad del software es mediocre;
- No hay muchas opciones de recorte. Sin embargo, la implementación admite algunos parámetros básicos.
No hay muchas desventajas, pero son críticas. Seamos claros de inmediato: no proporcione grandes datos a esta implementación. Esperarás por siempre. No lo utilice en un entorno de producción. Puede romperse inesperadamente. ¡Has sido advertido! Algunos de los problemas anteriores se pueden resolver con el tiempo. Sin embargo, es probable que la tasa de aprendizaje se mantenga baja (aunque la inferencia es válida). Deberá encontrar una solución mejor para solucionar este problema. Los invito a contribuir. Sin embargo, ¿cuáles son las posibles aplicaciones?
- Extraer conocimiento de los datos;
- Comprobación de la vista intuitiva de los datos;
- Comprender el funcionamiento interno de los árboles de decisión;
- Explore relaciones causales alternativas en relación con su problema de aprendizaje;
- Úselo como parte de algoritmos más complejos;
- Creación de informes y visualización;
- Utilizar para fines de investigación;
- Como una plataforma accesible para probar fácilmente sus ideas para algoritmos de árboles de decisión.
Estructura de árbol de decisión
Aunque los árboles de decisión no se tratarán en detalle en este documento, resumiremos sus componentes básicos. Esto proporcionará una base para comprender los ejemplos más adelante y también destacará algunas de las características de HDTree. La siguiente figura muestra la salida real de HDTree (excluyendo marcadores).
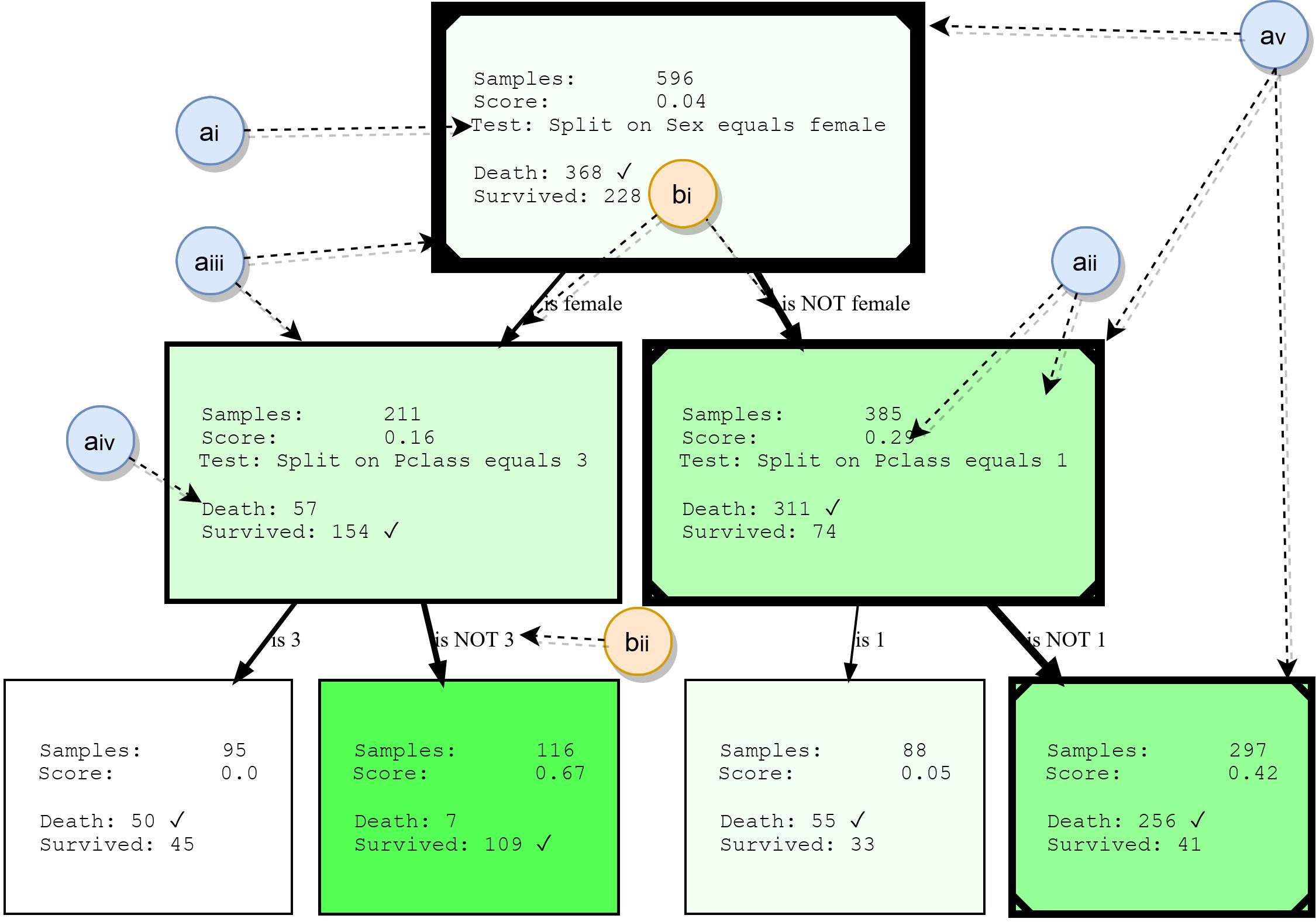
Nodos
- ai: , . . * * . . 3.
- aii: , , , , . , . . , ( , .. ). HDTree.
- aiii: el borde de los nodos indica cuántos puntos de datos pasan por este nodo. Cuanto más grueso es el borde, más datos fluyen a través del nodo.
- aiv: lista de objetivos de predicción y etiquetas que tienen puntos de datos que pasan por este nodo. La clase más común está marcada.
- av: opcionalmente, la visualización puede marcar la ruta que siguen los puntos de datos individuales (ilustrando la decisión que se toma cuando el punto de datos atraviesa el árbol). Esto está marcado con una línea en la esquina del árbol de decisiones.
Costillas
- bi: una flecha conecta cada posible resultado de división (ai) con sus nodos secundarios. Cuantos más datos relativos a los "flujos" principales alrededor del borde, más grueso se muestra.
- bii: cada borde tiene una representación textual legible por humanos del resultado de división correspondiente.
¿De dónde provienen los diferentes conjuntos divididos y pruebas?
En este punto, es posible que ya se esté preguntando en qué se diferencia HDTree de un árbol
scikit-learn(o de cualquier otra implementación) y por qué podríamos querer tener diferentes tipos de particiones. Intentemos aclarar esto. Tal vez tenga una comprensión intuitiva del espacio de funciones . Todos los datos con los que trabajamos están en un cierto espacio multidimensional, que está determinado por la cantidad y el tipo de características en sus datos. La tarea del algoritmo de clasificación ahora es dividir este espacio en áreas no superpuestas y asignarestas áreas son de clase. Visualicemos esto. Dado que nuestros cerebros tienen dificultades para jugar con la alta dimensionalidad, nos quedaremos con un ejemplo 2D y un problema de dos clases muy simple, así:

Verá un conjunto de datos muy simple compuesto por dos dimensiones (rasgos / atributos) y dos clases. Los puntos de datos generados se distribuyeron normalmente en el centro. Una calle que es solo una función lineal
f(x) = ysepara las dos clases: Clase 1 (abajo a la derecha) y Clase 2 (arriba a la izquierda). También se ha agregado algo de ruido aleatorio (puntos de datos azules en naranja y viceversa) para ilustrar los efectos del sobreajuste más adelante. El trabajo de un algoritmo de clasificación como HDTree (aunque también se puede usar para problemas de regresión ) es averiguar a qué clase pertenece cada punto de datos. En otras palabras, dados un par de coordenadas (x, y)como(6, 2)... El objetivo es averiguar si esta coordenada pertenece a la clase 1 naranja o clase 2 azul. El modelo discriminante intentará dividir el espacio del objeto (aquí son los ejes (x, y)) en territorios azules y naranjas, respectivamente.
Dados estos datos, la decisión (reglas) sobre cómo se clasificarán los datos parece muy simple. Una persona razonable diría "primero piensa por ti mismo"."Esta es la clase 1 si x> y, de lo contrario, la clase 2." La función de
y=xpuntos creará una separación perfecta . De hecho, un clasificador de margen máximo como las máquinas de vectores de soporte [8] sugeriría una solución similar. Pero veamos qué árboles de decisión resuelven la pregunta de manera diferente:

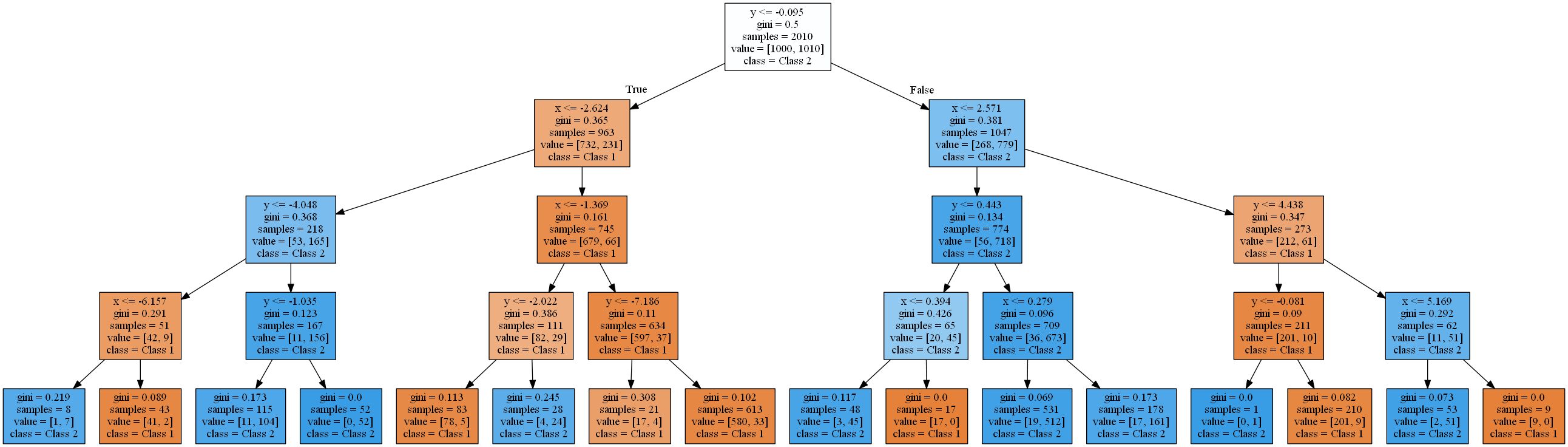
La imagen muestra las áreas donde un árbol de decisión estándar con una profundidad creciente clasifica un punto de datos como clase 1 (naranja) o clase 2 (azul).
Un árbol de decisión se aproxima a una función lineal usando una función escalonada.Esto se debe al tipo de regla de validación y partición que utilizan los árboles de decisión. Todos trabajan en un patrón
attribute < thresholdque dará como resultado hiperplanos que son paralelos a los ejes . En el espacio 2D, los rectángulos se "cortan". En 3D, estos serían cuboides y así sucesivamente. Además, el árbol de decisiones comienza a modelar el ruido en los datos cuando ya hay 8 niveles, es decir, se produce un sobreajuste. Sin embargo, nunca encuentra una buena aproximación a una función lineal real. Para verificar esto, utilicé una división típica de 2 a 1 de datos de entrenamiento y prueba y calculé la precisión de los árboles. Es 93,84%, 93,03%, 90,81% para el conjunto de prueba y 94,54%, 96,57%, 98,81% para el conjunto de entrenamiento(ordenados por profundidad de árbol 4, 8, 16). Mientras que la precisión en la prueba disminuye , la precisión del entrenamiento aumenta .
Un aumento en la eficiencia del entrenamiento y una disminución en los resultados de las pruebas es un signo de sobreentrenamiento.Los árboles de decisión resultantes son bastante complejos para una función tan simple. El más simple de estos (profundidad 4) renderizado con scikit learn ya se ve así:
Te libraré de los árboles más difícil. En la siguiente sección, comenzaremos resolviendo este problema usando el paquete HDTree. HDTree permitirá al usuario aplicar conocimientos sobre los datos (al igual que el conocimiento sobre separación lineal en el ejemplo). También le permitirá encontrar soluciones alternativas al problema.
Aplicación del paquete HDTree
Esta sección le presentará los conceptos básicos de HDTree. Intentaré tocar algunas partes de su API. No dude en preguntar en los comentarios o contácteme si tiene alguna pregunta sobre esto. Estaré encantado de responder y, si es necesario, complementar el artículo. Instalar HDTree es un poco más complicado que
pip install hdtree. Lo siento. Primero necesitas Python 3.5 o más reciente.
- Cree un directorio vacío y dentro de él una carpeta llamada hdtree (
your_folder/hdtree) - Clone el repositorio en el directorio hdtree (no en otro subdirectorio).
- Instalar las dependencias necesarias:
numpy,pandas,graphviz,sklearn. - Agregar
your_folderaPYTHONPATH. Esto incluirá el directorio en el motor de importación de Python. Podrá usarlo como un paquete Python normal.
Alternativamente, agregue
hdtreea site-packagessu carpeta de instalación python. Puedo agregar el archivo de instalación más tarde. En el momento de escribir este artículo, el código no está disponible en el repositorio de pip. Todo el código que genera los gráficos y la salida a continuación (así como el que se mostró anteriormente) está en el repositorio y se publica directamente aquí . Resolver un problema lineal con un árbol hermano
Comencemos de inmediato con el código:
from hdtree import HDTreeClassifier, SmallerThanSplit, EntropyMeasure
hdtree_linear = HDTreeClassifier(allowed_splits=[SmallerThanSplit.build()], # Split rule in form a < b
information_measure=EntropyMeasure(), # Use Information Gain for the scores attribute_names=['x', 'y' ]) # give the
attributes some interpretable names # standard sklearn-like interface hdtree_linear.fit(X_street_train,
y_street_train) # create tree graph hdtree_linear.generate_dot_graph() 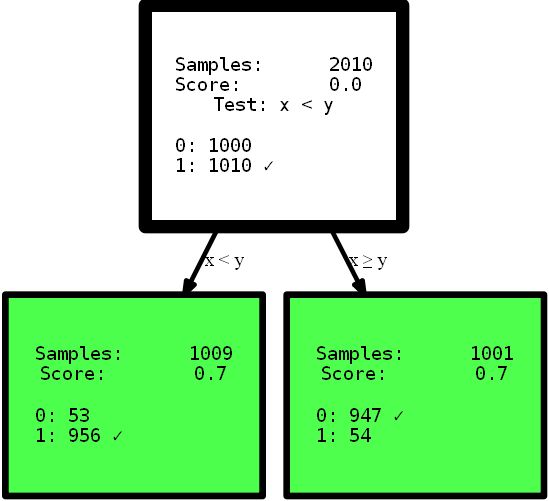
Sí, el árbol resultante tiene solo un nivel de altura y ofrece la solución perfecta a este problema. Este es un ejemplo artificial para mostrar el efecto. Sin embargo, espero que aclare el punto: tenga una vista intuitiva de los datos o simplemente proporcione un árbol de decisiones con diferentes opciones para dividir el espacio de funciones, lo que puede ofrecer una solución más simple y, a veces, incluso más precisa . Imagine que necesita interpretar las reglas de los árboles que se presentan aquí para encontrar información útil. Qué interpretación puede comprender primero y en cuál confía más? ¿Una interpretación compleja que utiliza funciones de varios pasos o un árbol pequeño y preciso? Creo que la respuesta es bastante simple. Pero profundicemos un poco más en el código en sí. Al inicializar, lo
HDTreeClassifiermás importante que debe proporcionar es allowed_splits. Aquí proporciona una lista que contiene las posibles reglas de partición que el algoritmo intenta durante el entrenamiento para cada nodo para encontrar una buena partición local de los datos. En este caso, hemos proporcionado exclusivamente SmallerThanSplit. Esta división hace exactamente lo que ve: toma dos atributos (intenta cualquier combinación) y divide los datos de acuerdo con el esquema a_i < a_j. Que (no demasiado al azar) coincide con nuestros datos lo mejor posible.
Este tipo de división se conoce como división multivarianteSignifica que la separación usa más de una característica para tomar una decisión. Esto no es como la partición unidireccional utilizada en la mayoría de los otros árboles, como
scikit-tree(ver más arriba para obtener más detalles) que tiene en cuenta exactamente un atributo . Por supuesto, HDTreetambién tiene opciones para lograr una "partición normal" como las de los árboles scikit: la familia QuantileSplit. Te mostraré más a medida que avanza el artículo. Otra cosa desconocida que puede ver en el código es el hiperparámetro information_measure. El parámetro representa una dimensión que se utiliza para evaluar el valor de un solo nodo o una división completa (nodo padre con sus hijos). La opción elegida se basa en la entropía [10]. Es posible que también hayas oído hablar deel coeficiente de Gini , que sería otra opción válida. Por supuesto, puede proporcionar su propia dimensión simplemente implementando la interfaz adecuada. Si lo desea, implemente un gini-Index , que puede usar en el árbol sin volver a implementar nada más. Simplemente cópielo EntropyMeasure()y adáptelo usted mismo. Profundicemos en el desastre del Titanic . Me encanta aprender de mis propios ejemplos. Ahora verá algunas funciones más de HDTree con un ejemplo específico, no en los datos generados.
Conjunto de datos
Trabajaremos con el famoso conjunto de datos de aprendizaje automático para el curso para jóvenes combatientes: el conjunto de datos de desastres del Titanic. Este es un conjunto bastante simple, que no es demasiado grande, pero contiene varios tipos de datos diferentes y valores faltantes, aunque no del todo trivial. Además, es comprensible para los humanos y muchas personas ya han trabajado con él. Los datos se ven así:

puede ver que hay todo tipo de atributos. Tipos numéricos, categóricos, enteros e incluso valores perdidos (mire la columna Cabina). El desafío es predecir si un pasajero sobrevivió al desastre del Titanic en función de la información disponible sobre pasajeros. Puede encontrar una descripción de los atributos de valor aquí . Al estudiar los tutoriales de AA y aplicar este conjunto de datos, está haciendo todo tipo depreprocesamiento para ser capaz de trabajar con la máquina común modelos de aprendizaje, por ejemplo, la eliminación de los valores perdidos
NaNpor los valores en sustitución de [12], dejando caer filas / columnas, la codificación unitaria [13] Los datos categóricos (por ejemplo, Embarkedy Sexo agrupación de datos para obtener un conjunto de datos válido que acepta el modelo ML. Este tipo de limpieza no es técnicamente requerido por HDTree. Puede entregar los datos como están y el modelo los aceptará con gusto. Cambie los datos solo al diseñar objetos reales. Simplifiqué todo para comenzar.
Entrenando el primer HDTree con datos del Titanic
Tomemos los datos tal como están y transmítalos al modelo. El código básico es similar al código anterior, pero este ejemplo permitirá muchas más divisiones de datos.
hdtree_titanic = HDTreeClassifier(allowed_splits=[FixedValueSplit.build(), # e.g., Embarked = 'C'
SingleCategorySplit.build(), # e.g., Embarked -> ['C', 'Q', 'S']
TwentyQuantileRangeSplit.build(), # e.g., IN Quantile 3-5
TwentyQuantileSplit.build()], # e.g., BELOW Quantile 7
information_measure=EntropyMeasure(),
attribute_names=col_names,
max_levels=3) # restrict to grow to a max of 3 levels
hdtree_titanic.fit(X_titanic_train.values, y_titanic_train.values)
hdtree_titanic.generate_dot_graph()
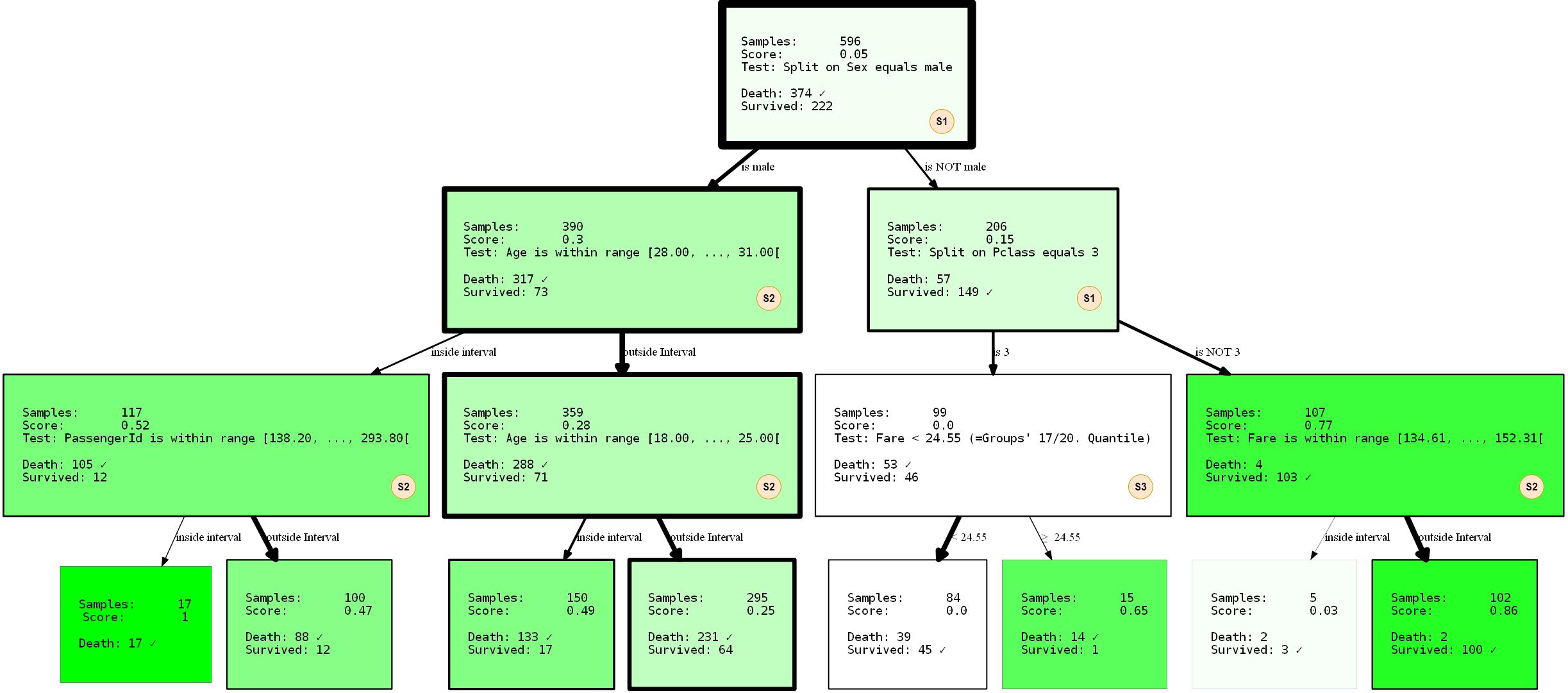
Echemos un vistazo más de cerca a lo que está sucediendo. Hemos creado un árbol de decisiones que tiene tres niveles, que elegimos para usar 3 de 4 SplitRules posibles . Están marcados con las letras S1, S2, S3. Explicaré brevemente lo que hacen.
- El S1:
FixedValueSplit. Esta división trabaja con datos categóricos y elige uno de los valores posibles. Luego, los datos se dividen en una parte que tiene este valor y otra parte que no tiene ningún valor establecido. Por ejemplo, PClass = 1 y Pclass ≠ 1 . - S2: ()
QuantileRangeSplit. . , . 1 5 . ( ) (measure_information). (i) (ii) — . . - S3: (Veinte)
QuantileSplit. Similar a Split Range (S2), pero divide los datos por umbral. Esto es básicamente lo que hacen los árboles de decisión regulares, excepto que generalmente prueban todos los umbrales posibles en lugar de un número fijo.
Es posible que haya notado que no está
SingleCategorySplitinvolucrado. Aprovecharé la oportunidad para aclarar de todos modos, ya que la omisión de esta división aparecerá más adelante:
- S4:
SingleCategorySplitFuncionará de manera similarFixedValueSplit, pero creará un nodo secundario para cada valor posible, por ejemplo: para el atributo PClass serán 3 nodos secundarios (cada uno para Clase 1, Clase 2 y Clase 3 ). Tenga en cuenta queFixedValueSplites idénticoSingleValueSplitsi solo hay dos categorías posibles.
Las divisiones individuales son algo "inteligentes" con respecto a los tipos / valores de datos que "aceptan". Hasta alguna prórroga, saben bajo qué circunstancias se aplican y no se aplican. El árbol también se entrenó con una división de 2 a 1 de los datos de entrenamiento y prueba Rendimiento: 80,37% de precisión en los datos de entrenamiento y 81,69 en los datos de prueba. No es tan malo.
Limitar divisiones
Supongamos que no está muy satisfecho con las soluciones encontradas por alguna razón. Tal vez decida que la primera división en la parte superior del árbol es demasiado trivial (dividida por atributo
sex). HDTree resuelve el problema. La solución más simple sería evitar FixedValueSplit(y, en realidad, el equivalente SingleCategorySplit) que aparezcan en la parte superior. Es bastante sencillo. Cambie la inicialización de las divisiones de esta manera:
- SNIP -
...allowed_splits=[FixedValueSplit.build_with_restrictions(min_level=1),
SingleCategorySplit.build_with_restrictions(min_level=1),...],
- SNIP -
Presentaré el HDTree resultante en su totalidad, ya que podemos observar la división faltante (S4) dentro del árbol recién generado.
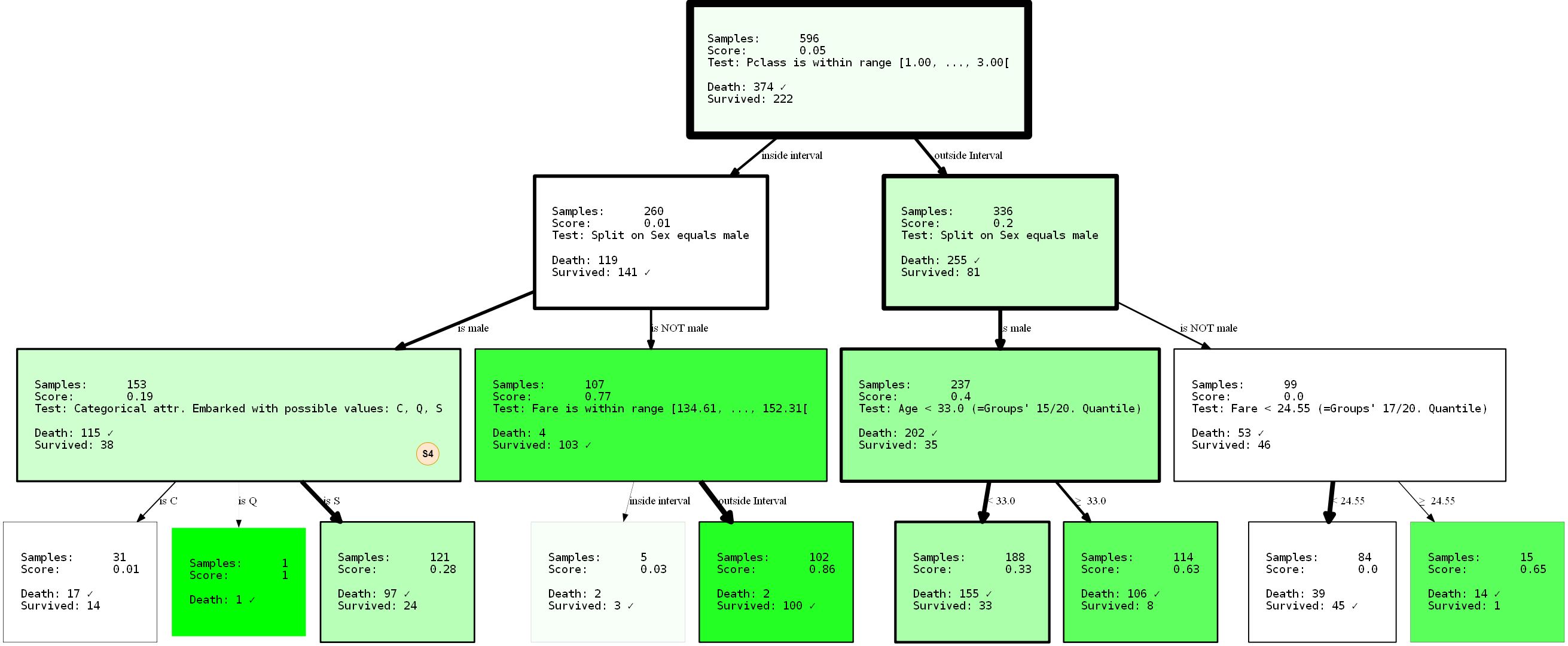
Al evitar que la división
sexaparezca en la raíz gracias al parámetro min_level=1(pista: por supuesto que también puede proporcionar max_level), hemos reestructurado completamente el árbol. Su rendimiento es ahora del 80,37% y del 81,69% (entrenamiento / prueba). No cambió en absoluto, incluso si tomamos la supuesta mejor separación en el nodo raíz.
Debido a que los árboles de decisión son codiciosos, solo encontrarán la _ mejor partición local para cada nodo, que no es necesariamente la _ mejor _ opción en absoluto. De hecho, encontrar una solución ideal a un problema de árbol de decisión es un problema NP-completo, como se demostró en [15].Así que lo mejor que podemos pedir son las heurísticas. Volviendo al ejemplo: ¿te das cuenta de que ya tenemos una representación no trivial de los datos? Aunque es trivial. Al decir que los hombres solo tendrán una baja probabilidad de supervivencia, en menor medida, se puede concluir que ser una persona de primer o segundo grado
PClassvolando fuera de Cherburgo ( Embarked=C) puede aumentar sus posibilidades de supervivencia. ¿O qué pasa si eres un hombre PClass 3menor de 33 años, tus posibilidades también aumentan? Recuerde: las mujeres y los niños primero. Es un buen ejercicio sacar estas conclusiones usted mismo interpretando la visualización. Estas conclusiones solo fueron posibles debido a la limitación del árbol. ¿Quién sabe qué más se puede revelar aplicando otras restricciones? ¡Intentalo!
Como ejemplo final de este tipo, quiero mostrarle cómo restringir la partición a atributos específicos. Esto es aplicable no solo para evitar el aprendizaje de árboles sobre correlaciones no deseadas o alternativas forzadas , sino que también reduce el espacio de búsqueda. El enfoque puede reducir drásticamente el tiempo de ejecución, especialmente cuando se utilizan particiones multivariadas. Si vuelve al ejemplo anterior, es posible que encuentre un nodo que busca un atributo
PassengerId. Quizás no queremos modelarlo, ya que al menos no debería contribuir a la información sobre la supervivencia. Verificar la identificación del pasajero puede ser una señal de reentrenamiento. Cambiemos la situación con un parámetro blacklist_attribute_indices.
- SNIP -
...allowed_splits=[TwentyQuantileRangeSplit.build_with_restrictions(blacklist_attribute_indices=['PassengerId']),
FixedValueSplit.build_with_restrictions(blacklist_attribute_indices=['Name Length']),
...],
- SNIP -
Puede preguntar por qué
name lengthaparece. Tenga en cuenta que los nombres largos (nombres dobles o títulos [nobles]) pueden indicar un pasado rico, aumentando sus posibilidades de supervivencia.
Consejo adicional: siempre puedes agregar lo mismoSplitRuledos veces. Si solo desea incluir en la lista negra un atributo para ciertos niveles de HDTree, simplementeSplitRuleno agregue ningún límite de nivel.
Predicción de puntos de datos
Como ya habrá notado, la interfaz genérica de scikit-learn se puede utilizar para la predicción. Esto
predict(), predict_proba()además score(). Pero puedes ir más lejos. Hay explain_decision()uno que mostrará una representación textual de la solución.
print(hdtree_titanic_3.explain_decision(X_titanic_train[42]))
Se supone que este es el último cambio en el árbol. El código generará esto:
Query:
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': 'female', 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Survived" because of:
Explanation 1:
Step 1: Sex doesn't match value male
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
Esto funciona incluso para datos faltantes. Establezcamos el índice de atributo 2 (
Sex) como faltante (None):
passenger_42 = X_titanic_train[42].copy()
passenger_42[2] = None
print(hdtree_titanic_3.explain_decision(passenger_42))
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': None, 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Death" because of:
Explanation 1:
Step 1: Sex has no value available
Step 2: Age is OUTSIDE range [28.00, ..., 31.00[(41.00 is above range)
Step 3: Age is OUTSIDE range [18.00, ..., 25.00[(41.00 is above range)
Step 4: Leaf. Vote for {'Death'}
---------------------------------
Explanation 2:
Step 1: Sex has no value available
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
---------------------------------
Esto imprimirá todas las rutas de decisión (hay más de una, ¡porque en algunos nodos no se puede tomar la decisión!). El resultado final será la clase más común de todas las hojas.
... otras cosas útiles
Puede continuar y obtener la vista de árbol como texto:
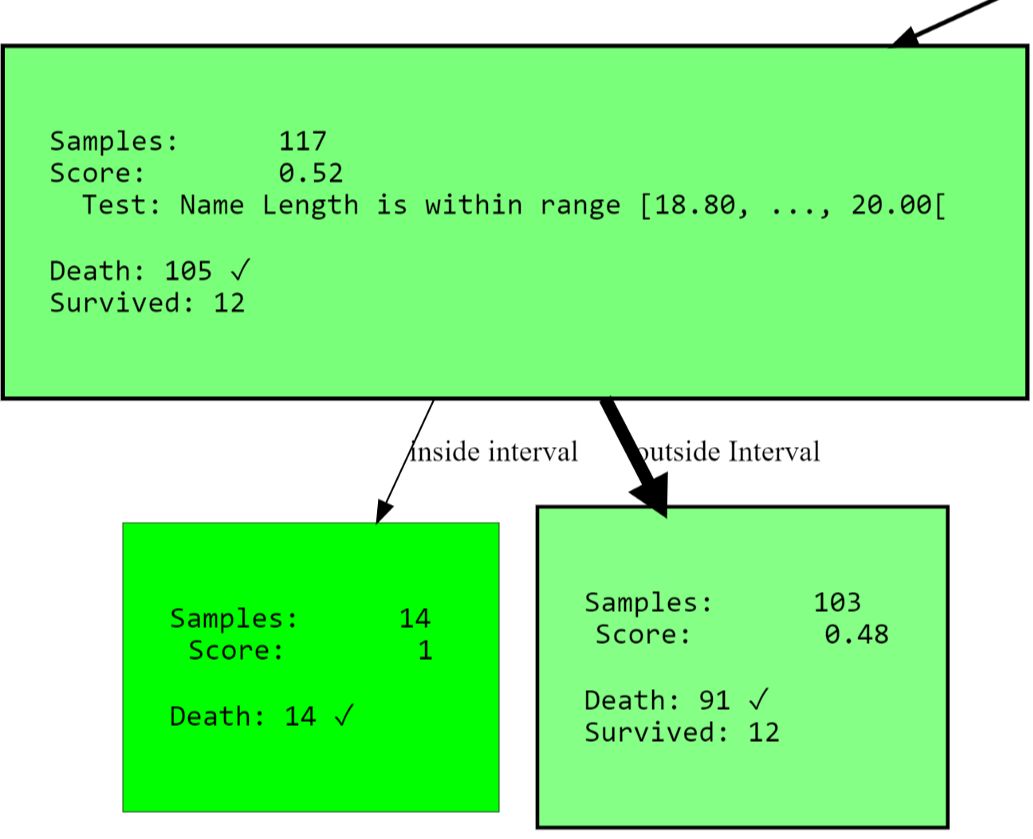
Level 0, ROOT: Node having 596 samples and 2 children with split rule "Split on Sex equals male" (Split Score:
0.251)
-Level 1, Child #1: Node having 390 samples and 2 children with split rule "Age is within range [28.00, ..., 31.00["
(Split Score: 0.342)
--Level 2, Child #1: Node having 117 samples and 2 children with split rule "Name Length is within range [18.80,
..., 20.00[" (Split Score: 0.543)
---Level 3, Child #1: Node having 14 samples and no children with
- SNIP -
O acceda a todos los nodos limpios (con una puntuación alta):
[str(node) for node in hdtree_titanic_3.get_clean_nodes(min_score=0.5)]
['Node having 117 samples and 2 children with split rule "Name Length is within range [18.80, ..., 20.00[" (Split
Score: 0.543)',
'Node having 14 samples and no children with split rule "no split rule" (Node Score: 1)',
'Node having 15 samples and no children with split rule "no split rule" (Node Score: 0.647)',
'Node having 107 samples and 2 children with split rule "Fare is within range [134.61, ..., 152.31[" (Split Score:
0.822)',
'Node having 102 samples and no children with split rule "no split rule" (Node Score: 0.861)']
Extensión HDTree
Lo más importante que puede querer agregar al sistema es el suyo
SplitRule. La regla de separación realmente puede hacer lo que quiera para separar ... Implementar SplitRulemediante implementación AbstractSplitRule. Esto es un poco complicado ya que debe manejar la ingesta de datos, la estimación del rendimiento y todo eso usted mismo. Por estas razones, hay mixins en el paquete que puede agregar a la implementación según el tipo de división. Los mixins hacen la mayor parte de la parte difícil por ti.
Bibliografía
- [1] Wikipedia article on Decision Trees
- [2] Medium 101 article on Decision Trees
- [3] Breiman, Leo, Joseph H Friedman, R. A. Olshen and C. J. Stone. “Classification and Regression Trees.” (1983).
- [4] scikit-learn documentation: Decision Tree Classifier
- [5] Cython project page
- [6] Wikipedia article on pruning
- [7] sklearn documentation: plot a Decision Tree
- [8] Wikipedia article Support Vector Machine
- [9] MLExtend Python library
- [10] Wikipedia Article Entropy in context of Decision Trees
- [12] Wikipedia Article on imputing
- [13] Hackernoon article about one-hot-encoding
- [14] Wikipedia Article about Quantiles
- [15] Hyafil, Laurent; Rivest, Ronald L. “Constructing optimal binary decision trees is NP-complete” (1976)
- [16] Hackernoon Article on Decision Trees
Descubra los detalles de cómo obtener una profesión de alto perfil desde cero o subir de nivel en habilidades y salario tomando cursos en línea de SkillFactory:
- Curso de aprendizaje automático (12 semanas)
- Curso avanzado "Machine Learning Pro + Deep Learning" (20 semanas)
- « Machine Learning Data Science» (20 )
- «Python -» (9 )
E
