En Surf, escribimos nuestro propio intérprete y lo usamos en el cliente de la aplicación móvil, aunque inicialmente, al parecer, esto generalmente tiene poco que ver con el desarrollo móvil. De hecho, los intérpretes y compiladores son herramientas para resolver problemas que se pueden encontrar en cualquier lugar. Por lo tanto, es útil comprender cómo funciona y poder escribir el tuyo propio.
Hoy, utilizando el ejemplo de traducir máscaras de un formato a otro, nos familiarizaremos con los conceptos básicos de la construcción de intérpretes y veremos cómo usar gramáticas formales, un árbol de sintaxis abstracta, reglas de traducción, incluso para resolver problemas comerciales.

Un poco sobre las máscaras: qué son y por qué las necesitas
. , , - — , . -: , , .
, . , . , API - , : 9161234567 — 8, .
, , :
, , . , , , — . ? — .
— , . , .
, :

, , : . .
, . , . , API - , : 9161234567 — 8, .
, , :
- , , .
- : , , , .
- , .
, , . , , , — . ? — .
— , . , .
, :
- . , , .
- « »: -, .
- .
, , : . .
— UX-
¿Por qué no puedes simplemente levantar y describir la máscara?
Las máscaras son frescas y cómodas. Pero hay un problema que es inevitable en determinadas condiciones: cuando el cliente tiene un formato de máscara y el servidor tiene muchos proveedores de datos diferentes y cada uno tiene su propio formato. No podemos contar con el hecho de que tendremos el mismo formato. Preguntar al servidor: "Ponnos máscaras como queramos" - también. Necesitas poder vivir con eso.
Surge el problema: hay una especificación de backend, necesitas escribir un frontend, una aplicación móvil. Puede escribir manualmente todas las máscaras para la aplicación, y esta es una buena opción cuando solo hay un proveedor y hay pocas máscaras. El programador, por supuesto, tendrá que dedicar tiempo a comprender al menos dos especificaciones para las máscaras: backend y front. Luego, debe traducir máscaras de backend específicas en las máscaras de frontend correspondientes. Esto también lleva tiempo, hay un factor humano: puedes equivocarte. No es un trabajo fácil, la traducción es difícil: algunos lenguajes de máscaras están escritos principalmente para computadoras, no para humanos.
Si de repente la máscara en el servidor ha cambiado o ha aparecido una nueva, entonces la aplicación, en primer lugar, puede dejar de funcionar. En segundo lugar, es necesario volver a realizar el arduo trabajo de traducción, se debe lanzar una nueva aplicación, esto requiere tiempo, esfuerzo y dinero. Surge la pregunta: ¿cómo minimizar el trabajo del programador? Parece que todo esto debería hacerlo una máquina, pero por alguna razón lo está haciendo una persona.
La respuesta es sí, tenemos una solución. Las máscaras están escritas en el lenguaje de las computadoras, y esta es una de las razones por las que a una persona le resulta difícil trabajar con él y traducir de un idioma a otro. Necesitamos transferir este trabajo a la computadora. Dado que la máscara parece ser una gramática formal , la forma más segura de traducir una gramática a otra es:
- comprender las reglas para construir la gramática original,
- comprender las reglas para construir la gramática de destino,
- escribir reglas de traducción desde la gramática de origen hasta el destino,
- implementar todo esto en el código.
Para eso están escritos los compiladores y traductores.
Ahora echemos un vistazo más de cerca a nuestra solución basada en gramáticas formales.
Antecedentes
En nuestra aplicación, hay bastantes pantallas diferentes que se forman de acuerdo con el principio de backend: una descripción completa de la pantalla, junto con los datos, proviene del servidor.

La mayoría de las pantallas contienen una variedad de formas de entrada. El servidor determina qué campos hay en el formulario y cómo deben formatearse. Las máscaras también se utilizan para describir estos requisitos.
Veamos cómo funcionan las máscaras.
Ejemplos de máscaras en diferentes formatos.
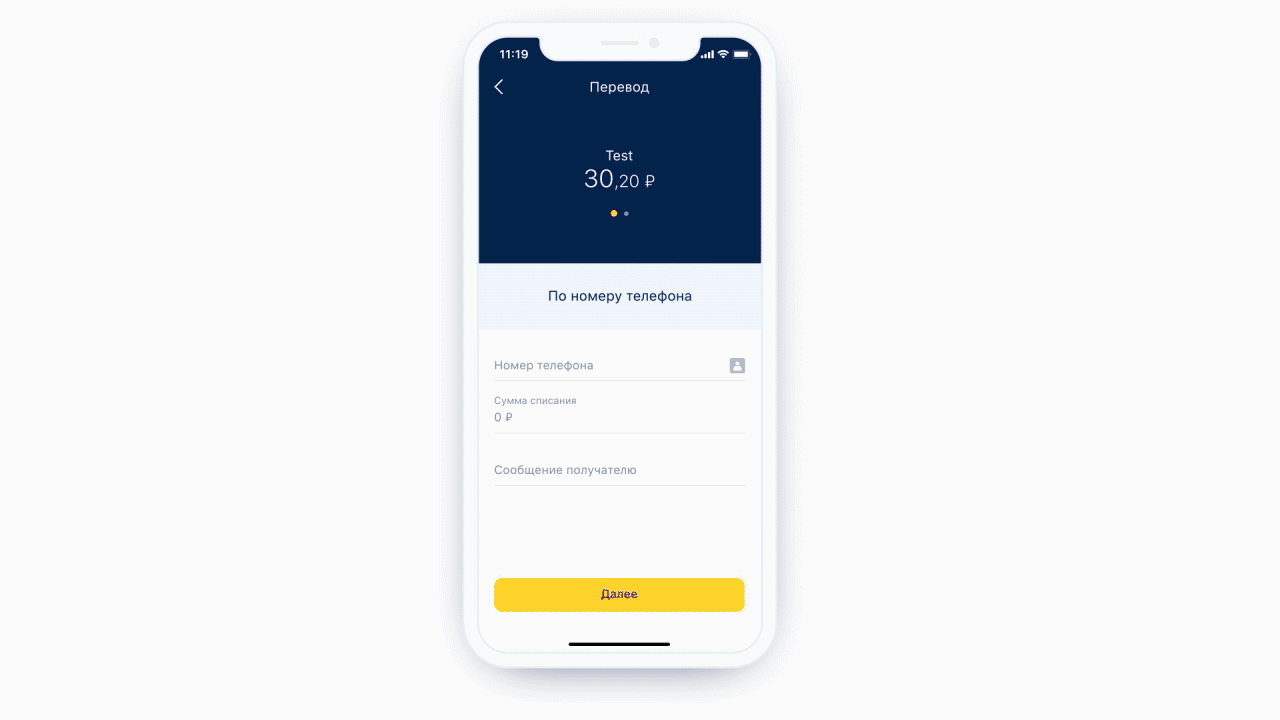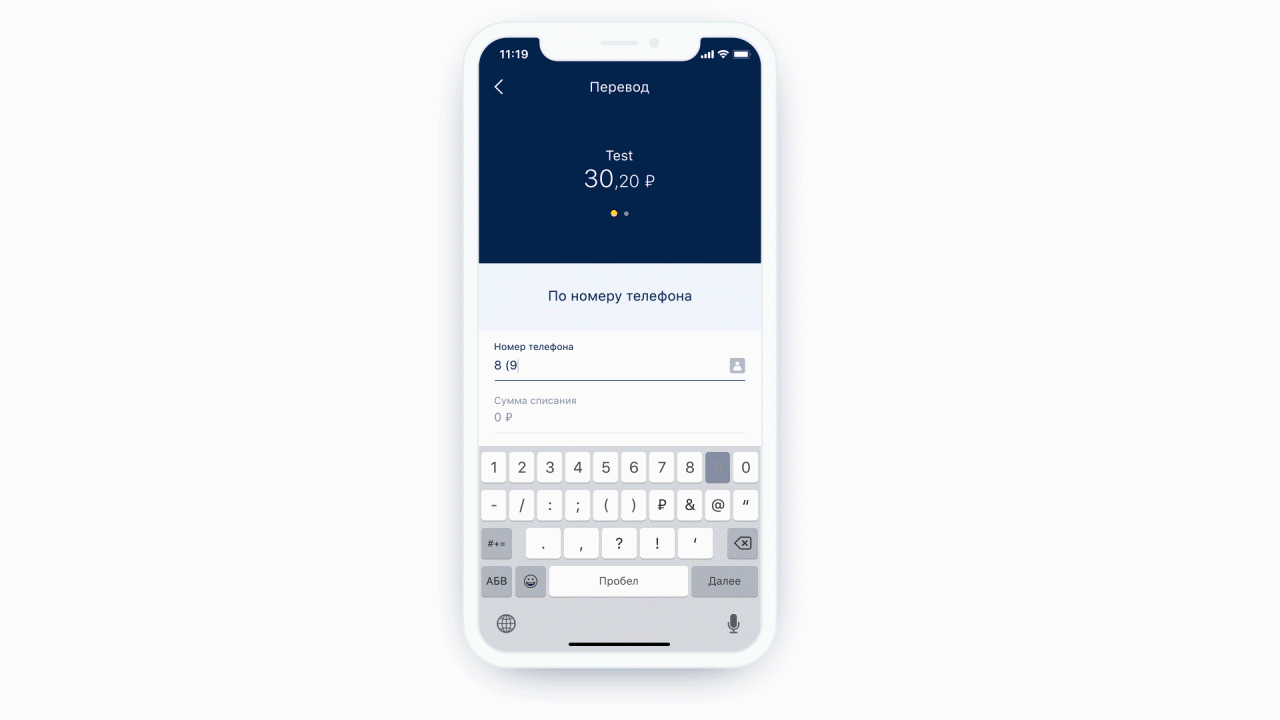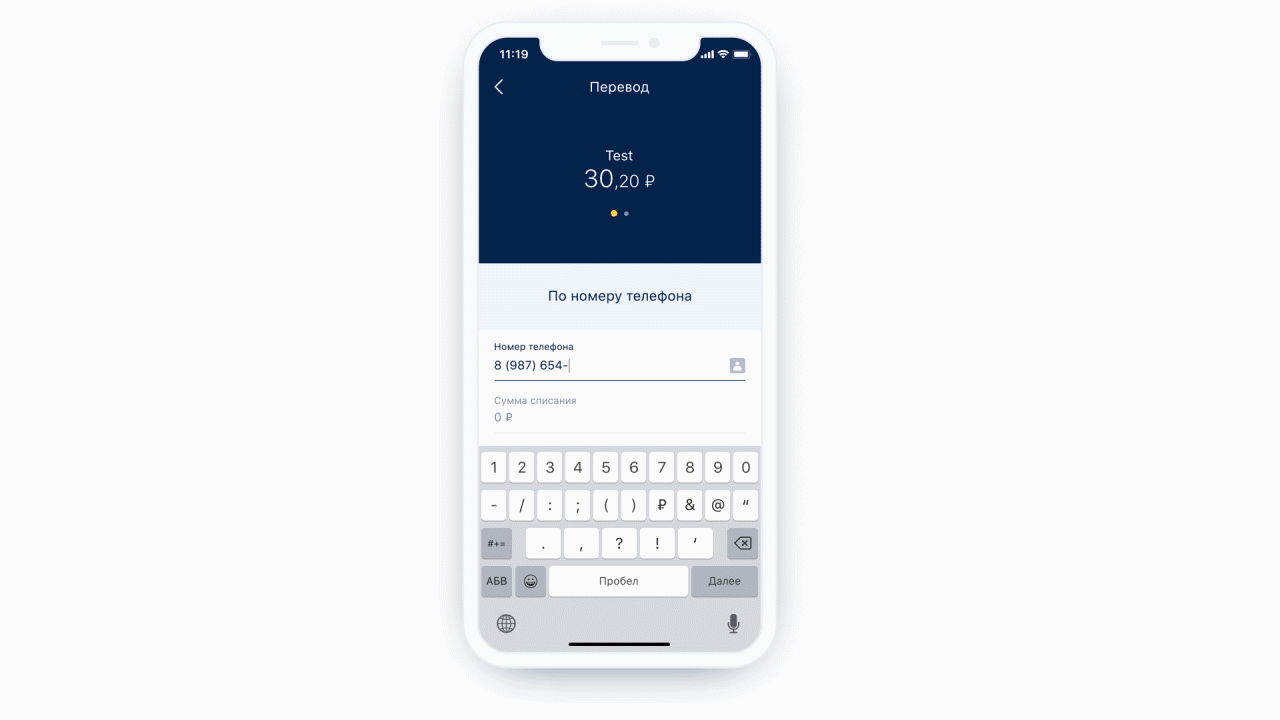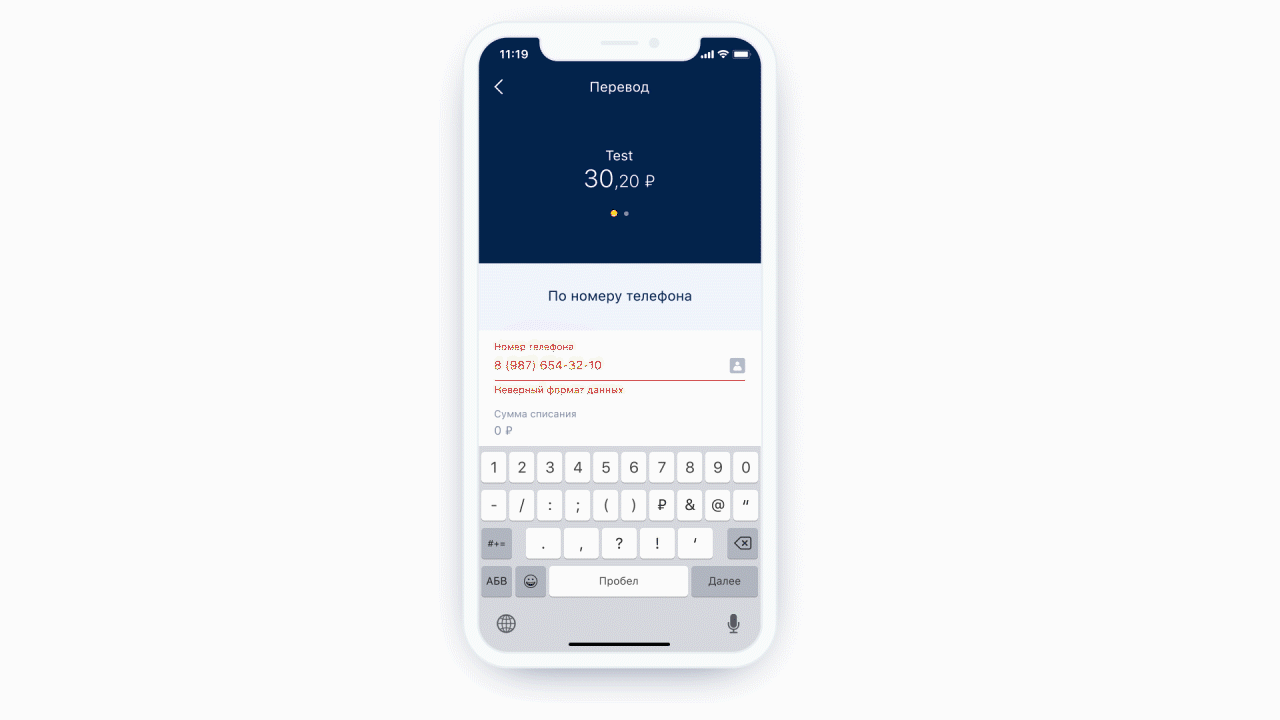
Como primer ejemplo, tomemos la misma forma de ingresar un número de teléfono. La máscara para tal forma podría verse así.

Por un lado, la propia máscara agrega separadores, paréntesis y prohíbe ingresar caracteres incorrectos. Por otro lado, la misma máscara extrae información útil de la entrada formateada para enviarla al servidor.
La parte llamada constante está resaltada en rojo. Estos son símbolos que aparecerán automáticamente - el usuario no debe ingresarlos:

Luego viene la parte dinámica - siempre está entre corchetes angulares:

Más adelante en el texto llamaré a esta expresión "expresión dinámica" - o DW para abreviar
Aquí hay una expresión mediante la cual formatearemos nuestra entrada: Las

piezas que son responsables del contenido de la parte dinámica están resaltadas en rojo.
\\ d - cualquier dígito.
+ - repetidor regular: repetir al menos una vez.
$ {3} es un símbolo de metainformación que especifica el número de repeticiones. En este caso, debería haber tres caracteres.
Entonces la expresión \\ d + $ {3} significa que debe haber tres dígitos.
En este formato de máscaras, solo puede haber un repetidor dentro de la parte dinámica:

esta limitación apareció por una razón, ahora explicaré por qué.
Digamos que tenemos un DV, en el que el tamaño está codificado: 4 elementos. Y le damos 2 elementos con un repetidor: `<! ^ \\ d + \\ v + $ {4}>`. Las siguientes combinaciones caen bajo tal DV:
- 1abc
- 12ab
- 123a
Resulta que tal DV no nos da una respuesta inequívoca, qué esperar en el lugar del segundo carácter: un número o una letra.
Tome la máscara, agréguela con la entrada del usuario. Obtenemos el número de teléfono formateado:

en el cliente, el formato de las máscaras puede verse diferente. Por ejemplo, en la biblioteca Input Mask de Redmadrobot, la máscara del número de teléfono se

ve así: Parece más agradable y más fácil de entender.
Resulta que la máscara para el servidor y la máscara para el cliente están escritas de manera diferente, pero hacen lo mismo.

Reformulemos el problema: cómo combinar máscaras de diferentes formatos
Necesitamos combinar estas máscaras entre sí, o de alguna manera obtener la segunda de una.
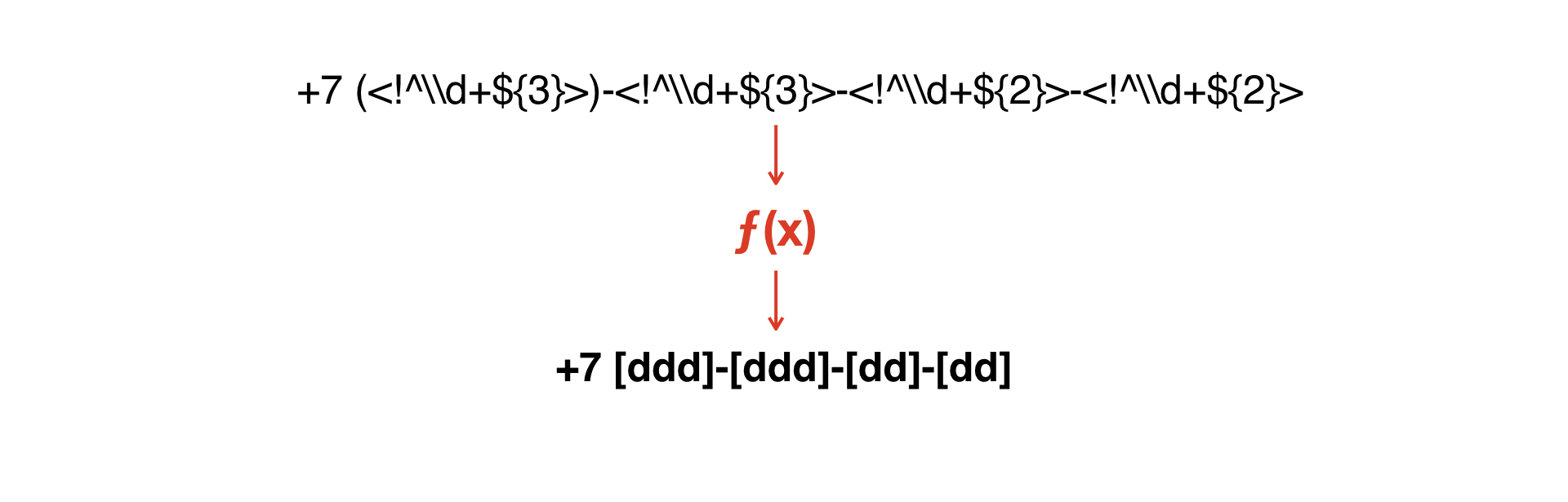
Necesitamos construir una función que convierta una máscara en la segunda.
Y aquí surgió la idea de escribir un intérprete muy simple que permitiera obtener una segunda gramática de una gramática.
Desde que llegamos al intérprete, hablemos de gramáticas.
Cómo se realiza el análisis
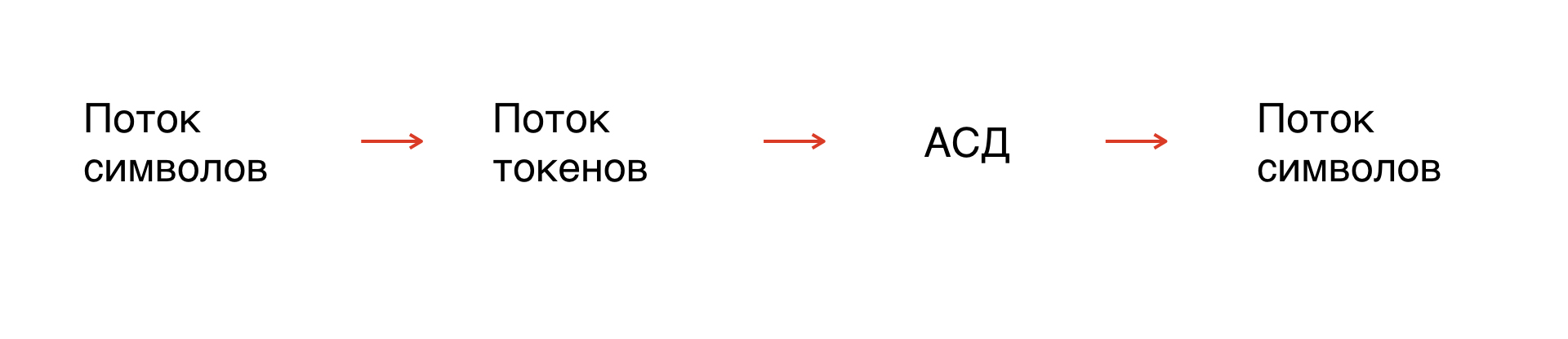
Primero, tenemos una serie de personajes: nuestra máscara. De hecho, esta es la cadena sobre la que operamos. Pero como los símbolos no están formalizados, debe formalizar la cadena: divídala en elementos que sean comprensibles para el intérprete.
Este proceso se llama tokenización: un flujo de símbolos se convierte en un flujo de tokens. El número de tokens es limitado, están formalizados, por lo tanto, se pueden analizar.
Además, basándonos en las reglas gramaticales, construimos un árbol de sintaxis abstracta a lo largo del flujo del token. Del árbol obtenemos un flujo de símbolos en la gramática que necesitamos.
Hay una expresión. Lo miramos y vemos que tenemos una constante, de la que hablé anteriormente:

representamos todas las constantes como un token CS, cuyo argumento es la constante misma:

el siguiente tipo de tokens es el comienzo del DW:

Además, todos esos tokens se interpretarán como caracteres especiales. En nuestro ejemplo, no hay muchos, en las máscaras reales puede haber muchos más.

Luego tenemos un repetidor.
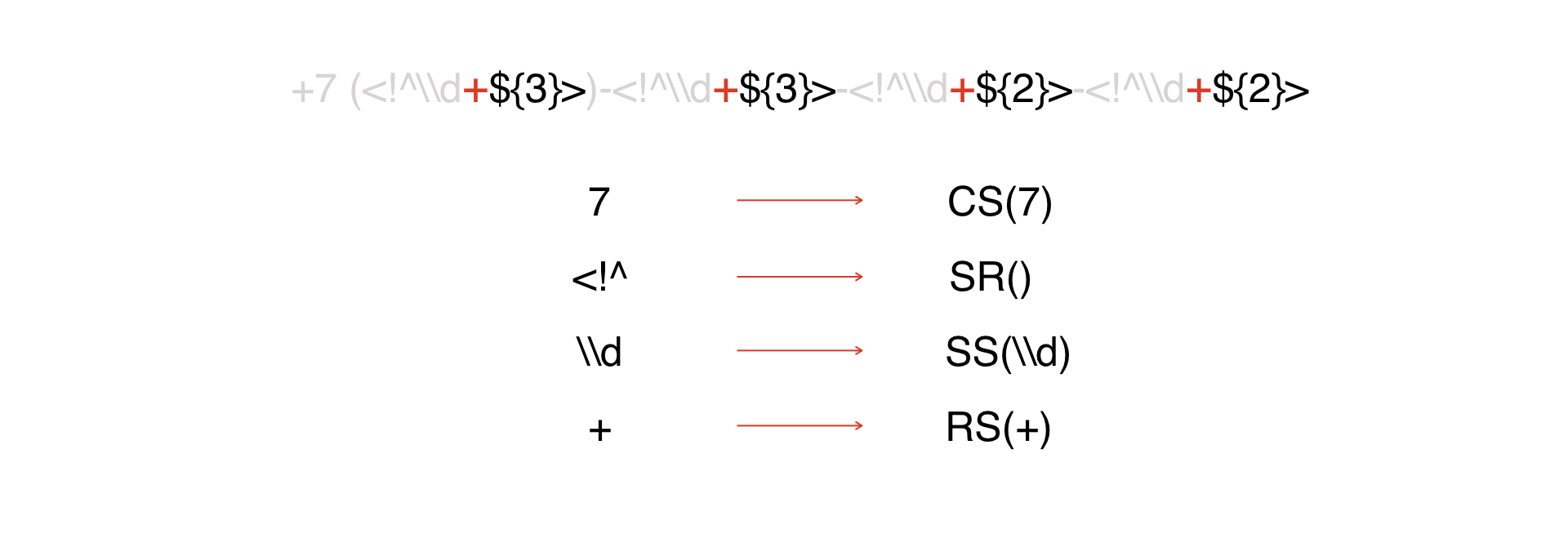
Luego, algunos caracteres que se consideran metadatos. Haremos trampa y les presentaremos una ficha, porque así es más fácil.

Fin del Lejano Oriente. Por lo tanto, hemos descompuesto todo en tokens.

Un ejemplo de tokenizar una máscara para un número de teléfono
Para ver cómo, en principio, se lleva a cabo el proceso de tokenización y cómo funcionará el intérprete, tomamos una máscara por un número de teléfono y lo transformamos en un flujo de tokens.

Primero, el símbolo +. Convierta a constante +. Luego hacemos lo mismo con el 7 y con todos los demás símbolos. Obtenemos una serie de tokens. Esta no es una estructura todavía; analizaremos esta matriz más a fondo.
Lexer y edificio ASD
Ahora la parte complicada es el lexer.

A la izquierda, se describe una leyenda: caracteres especiales que se utilizan para describir reglas léxicas. A la derecha están las propias reglas.
SymbolRule describe un símbolo. Si se aplica esta regla, si es verdadera, significa que hemos encontrado un carácter especial o un carácter constante. Podemos decir que esta es una función.
El siguiente es repeaterRule. Esta regla describe una situación en la que se encuentra un personaje, seguido de un token repetidor.
Entonces todo parece similar. Si es LW, entonces es símbolo o repetidor. En nuestro caso, esta regla es más amplia. Y al final debe haber un token con metadatos.
La última regla es maskRule. Esta es una secuencia de símbolos y DV.
Ahora construyamosun árbol de sintaxis abstracta (AST) de una matriz de tokens.
Aquí hay una lista de tokens. El primer nodo del árbol es el raíz, desde el cual comenzaremos a construir. No tiene ningún sentido, solo necesita una raíz.

Tenemos el primer token +, lo que significa que solo agregamos un nodo hijo y eso es todo.

Hacemos lo mismo con todos los demás símbolos constantes, pero luego es más complicado. Nos encontramos con un token DV.

Este no es solo un sitio normal, sabemos que debe tener algún tipo de contenido.

El nodo de contenido es solo un nodo técnico al que podemos navegar en el futuro. Tiene sus propios nodos secundarios y ¿qué nodo tendrá a continuación? El siguiente token de nuestra secuencia es un personaje especial. ¿Será un nodo hijo?

De hecho, en este caso, no. Tendremos un repetidor como nodo hijo.

¿Por qué? Porque es más conveniente trabajar con madera en el futuro. Digamos que queremos analizar este árbol y construir algún tipo de gramática a partir de él. Al analizar un árbol, observamos los tipos de nodos. Si tenemos un nodo CS, lo analizamos en el mismo nodo CS, pero para una gramática diferente. Por convención, iteramos sobre las copas del árbol y ejecutamos algún tipo de lógica.
La lógica depende del tipo de nodo o del tipo de token que se encuentra en el nodo. Para el análisis, es mucho más conveniente comprender de inmediato qué token está frente a usted: compuesto, como un repetidor, o simple, como CS. Esto es necesario para que no haya dobles interpretaciones o búsquedas constantes de nodos secundarios.
Esto sería especialmente notable en grupos de caracteres: por ejemplo, [abcde]. En ese caso, obviamente, debe haber algún tipo de nodo GRUPO padre que tendrá una lista de nodos secundarios CS (a) CS (b), etc.
Volver al token con metadatos. No está incluido en el contenido, está en el lateral.

Esto es necesario para facilitar el trabajo con el árbol, de modo que no consideremos este nodo como contenido, porque de hecho no pertenece a él.
El DV terminó, y no lo consideramos una especie de nodo: era un token que ahora se puede tirar. No lo convertiremos en un nodo de árbol.
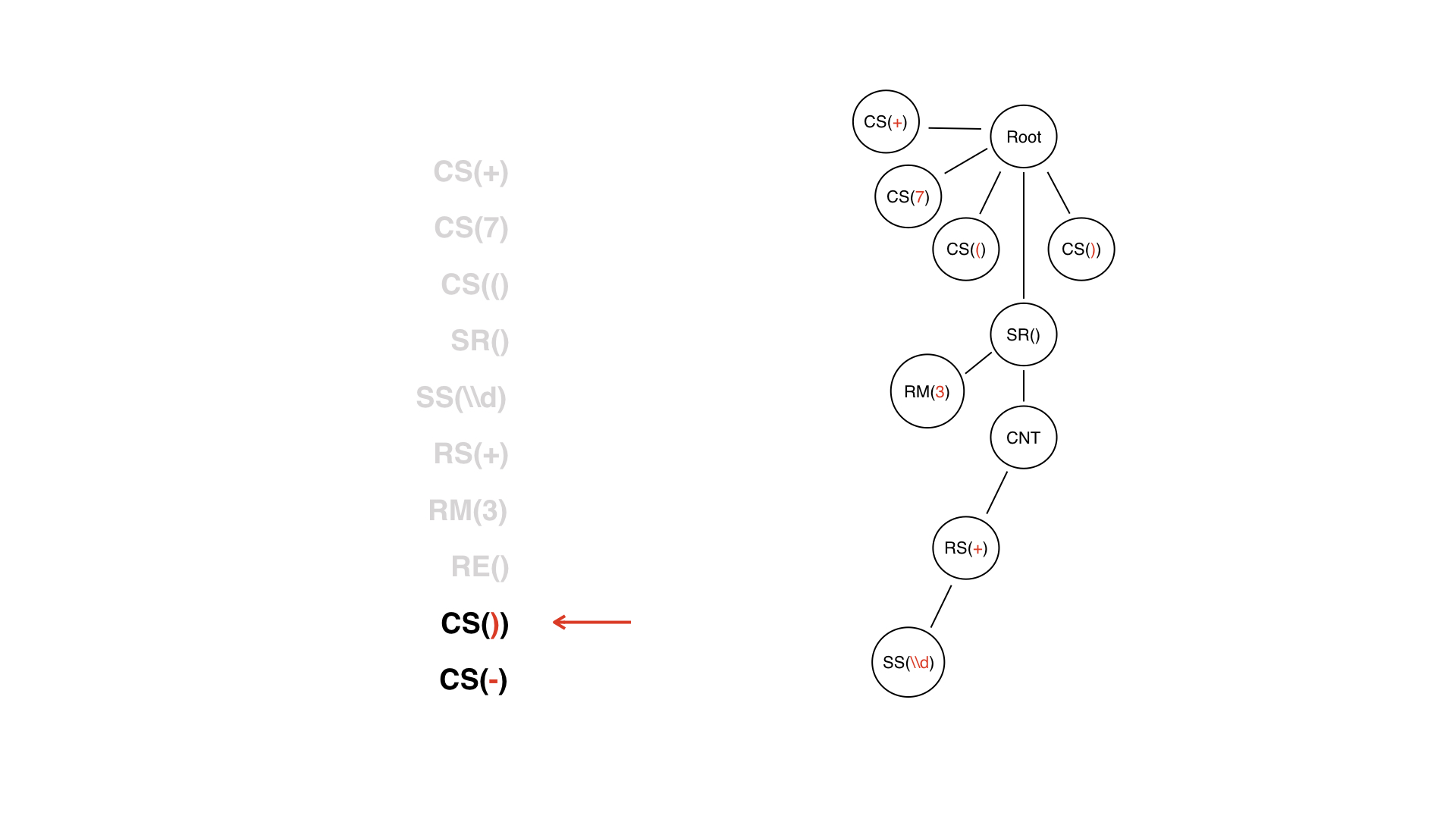
Ya tenemos un subárbol, cuya raíz es el nodo SR, es decir, la parte muy dinámica. El token final de LW nos ayuda mucho en el proceso de construcción del árbol: podemos entender cuándo se termina el subárbol de LW. Pero este token no tiene valor para la lógica: mirando un árbol fila por fila, ya entendemos cuándo terminará el DW, porque está, por así decirlo, cerrado por el nodo SR.
Además, solo símbolos constantes ordinarios.

Tenemos un arbol. Ahora repasemos este árbol en profundidad y construyamos sobre esta base alguna otra gramática: necesitas ir a un nodo, ver qué tipo de nodo es y generar un elemento de otra gramática a partir de este nodo.
Sintaxis de la biblioteca InputMask de Redmadrobot
Veamos la sintaxis de la biblioteca Redmadrobot.

Aquí está la misma expresión. +7 es una constante que se agregará automáticamente. Dentro de las llaves, se describe el DV: la parte dinámica. Dentro del DV hay un carácter especial d. Redmadrobot tiene esta notación predeterminada que denota un dígito.
Así es como se ve la notación:

La notación consta de tres partes:
- carácter es el carácter que usaremos para escribir la máscara. En qué consiste el alfabeto de la máscara. Por ejemplo, d.
- characterSet: qué caracteres ingresados por el usuario coinciden con esta notación. Por ejemplo, 0, 1, 2, 3, 4, etc.
- isOptional: si el usuario debe ingresar uno de los caracteres characterSet o no ingresar nada.
Mira, ahora tendremos esa máscara.

- El carácter "b" tiene una notación de dígitos especial y no es opcional.
- El carácter "c" tiene una notación diferente: CharacterSet es diferente. Tampoco es opcional.
- Y el carácter "C" es lo mismo que "c", solo que es opcional. Esto es necesario para que en la máscara miremos los metadatos y veamos que no hay un límite estricto, sino uno débil.
Si necesita escribir una regla cuando puede haber de uno a diez caracteres, entonces un carácter no será opcional. Y nueve caracteres serán opcionales. Es decir, en la notación del ejemplo, se escribirán en mayúsculas. Como resultado, esta regla se verá así: [cCCCCCCCCC]
Ejemplo: traducir la máscara de número de teléfono del formato de backend al formato InputMask
Aquí está el árbol que obtuvimos en el último paso. Tenemos que caminar sobre él. Lo primero que llegamos es la raíz.

Más allá de la raíz, nos encontramos en el símbolo constante + - inmediatamente generamos +. A la derecha, se escribe una máscara en formato InputMask.

El siguiente carácter es comprensible: solo 7, seguido de un paréntesis abierto.
Luego, se genera una parte de la parte dinámica, pero aún no se llena.

Entramos, tenemos contenido, este es un nodo técnico. No escribimos nada en ningún lado.

Aquí tenemos un repetidor, tampoco escribimos nada en ninguna parte, porque no hay tal símbolo en la máscara. Esa regla no se puede escribir.

Finalmente, llegamos a una especie de símbolo de contenido.
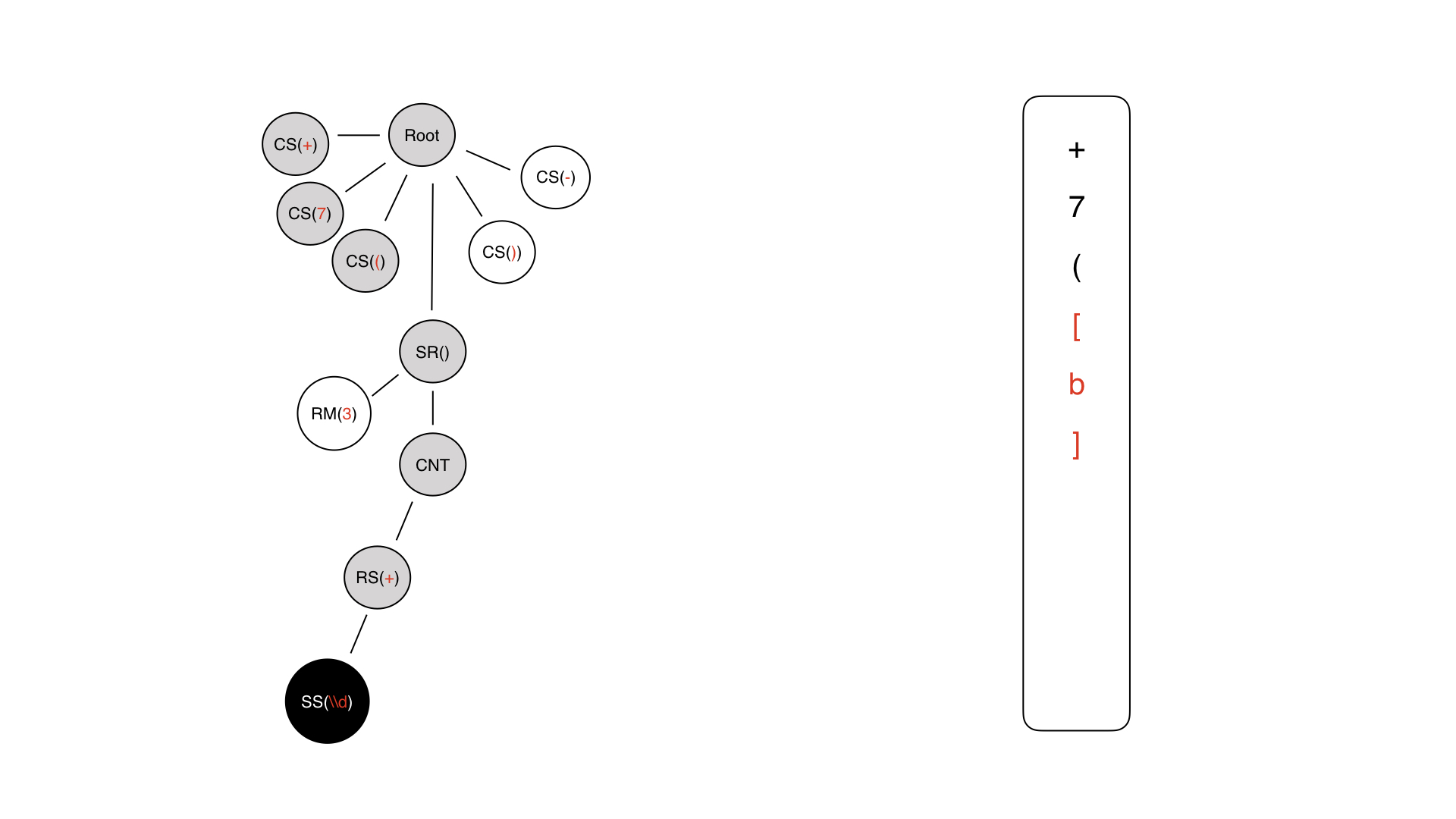
El símbolo de contenido puede ser un símbolo constante o un símbolo especial. En este caso, se usa uno especial, porque solo lleva algún tipo de carga semántica para la entrada.
Así que lo escribimos, volvemos y buscamos solo la metainformación.

Veamos que teníamos un repetidor allí y aquí tenemos 3, un límite estricto. Por tanto, lo repetimos tres veces y obtenemos una pieza tan dinámica. Luego sumamos nuestros símbolos constantes.

Como resultado, obtenemos una máscara que parece una máscara en formato de robot.
En la práctica, tomamos una gramática y generamos otra gramática a partir de ella.
Reglas para generar gramática del lado del cliente desde el lado del servidor
Ahora un poco sobre las reglas de generación. Es importante.
Puede haber casos tan difíciles: dentro de la parte dinámica hay varias piezas diferentes de DW. Dentro de llaves: esto es lo mismo que en DV, uno de muchos. Veamos cómo manejará el intérprete esta situación.

Primero viene el conjunto de caracteres, y tenemos que convertirlo a algún tipo de notación en términos de InputMask. ¿Por qué? Porque se trata de una especie de conjunto limitado de caracteres que necesitamos hacer coincidir. Necesitamos combinar la entrada del usuario y el carácter, y por lo tanto tendremos alguna notación específica escrita aquí.
A continuación tenemos el carácter \\ d.
Siguiente - DV con un tamaño opcional.

El primero, resulta, es algún personaje b. Tendrá un conjunto de caracteres que contiene abcd.
Además, está claro que ya habrá un símbolo diferente, porque no lo parcheará de manera diferente o lo parcheará incorrectamente. Y luego tenemos esta expresión que se convierte en algo como esto.
La última parte debe contener al menos un símbolo. Designemos este requisito como d. Pero también el usuario puede ingresar dos caracteres adicionales, y luego se designan como DD.
Poniendolo todo junto.

A continuación, se muestra un ejemplo de los conjuntos de caracteres que se generan. Se puede ver que b corresponde al conjunto de caracteres abcd, para números, el conjunto de caracteres preestablecido correspondiente. Para d y D, el conjunto de caracteres correspondiente contiene 12vf.
Salir
Hemos aprendido a convertir automáticamente una gramática en otra: ahora las máscaras según la especificación del servidor funcionan en nuestra aplicación.
Otra característica que obtuvimos de forma gratuita es la capacidad de realizar análisis estáticos de la máscara que nos llegó. Es decir, podemos entender qué tipo de teclado se necesita para esta máscara y cuál puede ser el número máximo de caracteres en esta máscara. Y es aún mejor, porque ahora no mostramos el mismo teclado todo el tiempo para cada elemento de formulario; mostramos el teclado requerido debajo del elemento de formulario requerido. Y también podemos definir condicionalmente exactamente que algún campo es un campo de entrada de teléfono.
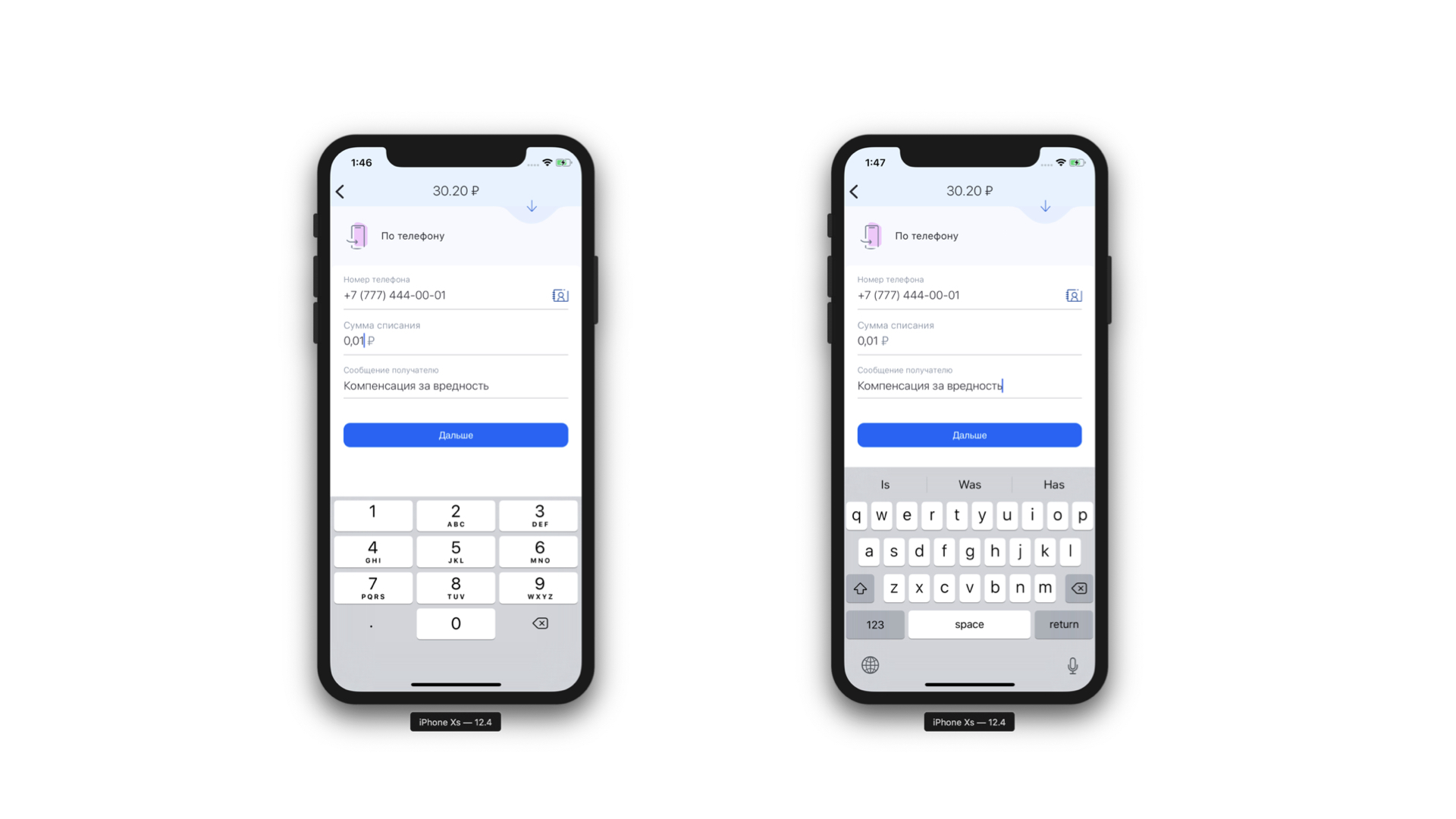
Izquierda: en la parte superior del campo de entrada del teléfono hay un icono (en realidad, un botón) que enviará al usuario a la lista de contactos. Derecha: ejemplo de un teclado para un mensaje de texto normal.
Biblioteca de trabajo para traducir máscaras
Puede ver cómo implementamos el enfoque anterior. La biblioteca se encuentra en Github .
Ejemplos de traducción de diferentes máscaras
Esta es la primera máscara que miramos al principio. Se interpreta en esta representación de RedMadRobot.

Y esta es la segunda máscara, solo una máscara de entrada para algo. Se convierte en tal representación.
