Inspirado en la charla, este artículo presenta un enfoque para simplificar el proceso de creación de operadores para Kubernetes y le muestra cómo puede crear los suyos propios utilizando un operador de shell con un esfuerzo mínimo.

Presentamos el video con el informe (~ 23 minutos en inglés, mucho más informativo que el artículo) y el extracto principal en forma de texto. ¡Vamos!
En Flant optimizamos y automatizamos todo constantemente. Hoy hablaremos de otro concepto apasionante. ¡Conozca las secuencias de comandos de shell nativas de la nube !
Sin embargo, comencemos con el contexto en el que todo esto está sucediendo: Kubernetes.
API y controladores de Kubernetes
La API en Kubernetes se puede representar como una especie de servidor de archivos con directorios para cada tipo de objeto. Los objetos (recursos) de este servidor están representados por archivos YAML. Además, el servidor tiene una API básica para hacer tres cosas:
- obtener un recurso por su tipo y nombre;
- cambiar el recurso (en este caso, el servidor almacena solo los objetos "correctos" - se descartan todos los formados incorrectamente o destinados a otros directorios);
- ( / ).
Así, Kubernetes actúa como una especie de servidor de archivos (para manifiestos YAML) con tres métodos básicos (sí, de hecho, hay otros, pero los omitiremos por ahora).

El problema es que el servidor solo puede almacenar información. Para que funcione, necesita un controlador , el segundo concepto más importante y fundamental en el mundo de Kubernetes.
Hay dos tipos principales de controladores. El primero toma información de Kubernetes, la procesa de acuerdo con la lógica anidada y la devuelve a K8. El segundo toma información de Kubernetes, pero, a diferencia del primer tipo, cambia el estado de algunos recursos externos.
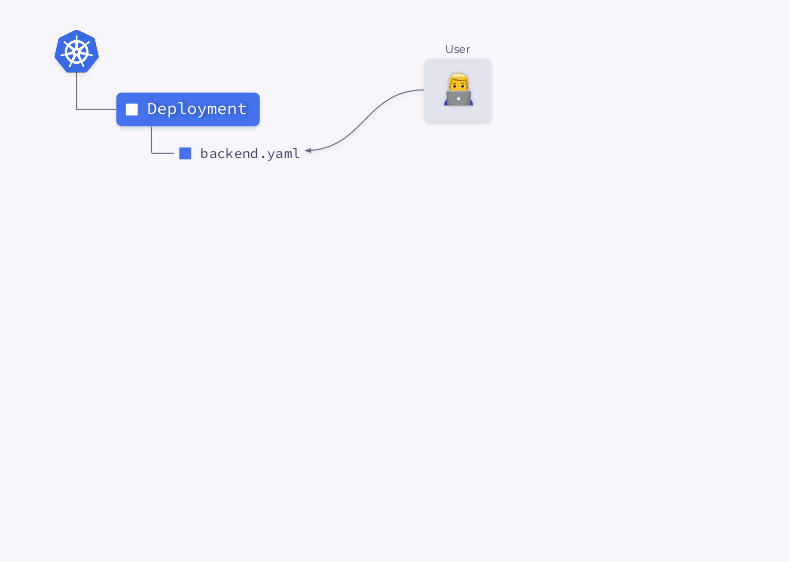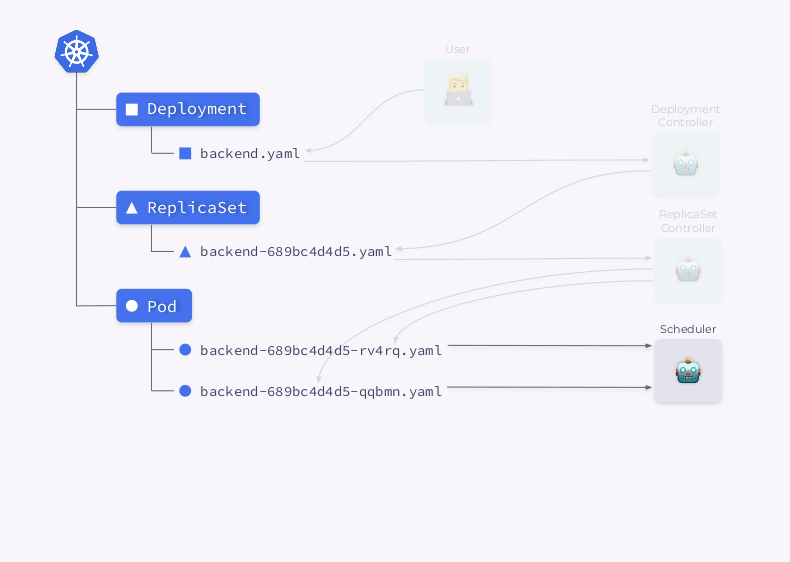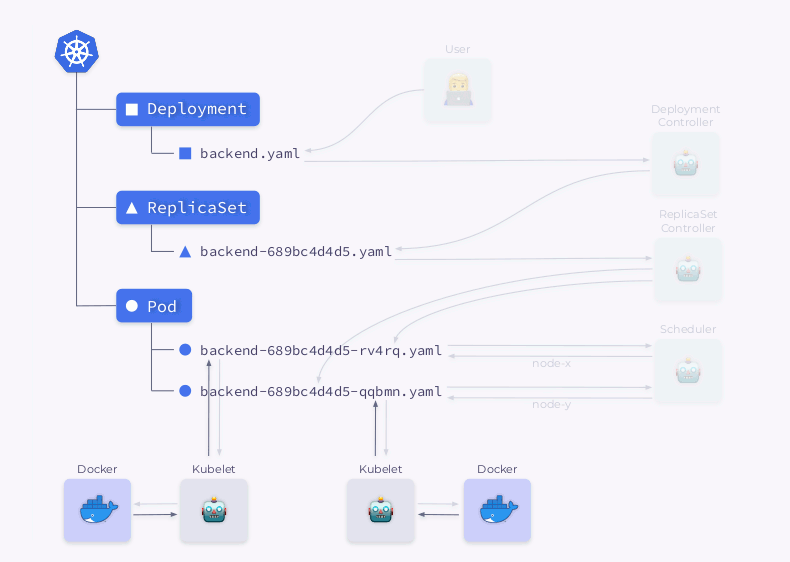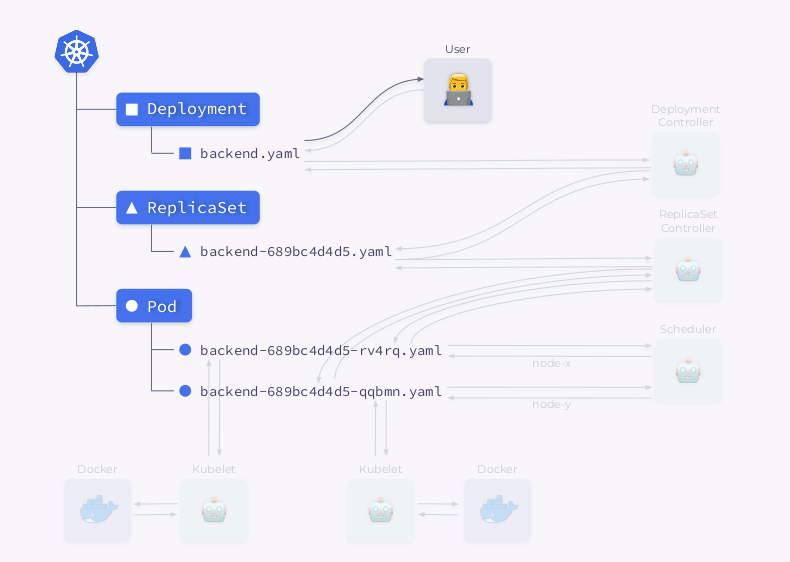
Echemos un vistazo más de cerca al proceso de creación de una implementación en Kubernetes:
- El controlador de implementación (incluido en
kube-controller-manager) recibe información sobre la implementación y crea un ReplicaSet. - ReplicaSet crea dos réplicas (dos pods) según esta información, pero estos pods aún no están programados.
- El programador programa pods y agrega información de nodo a sus YAML.
- Los Kubelets realizan cambios en un recurso externo (por ejemplo, Docker).
Luego, toda esta secuencia se repite en orden inverso: kubelet verifica los contenedores, calcula el estado del pod y lo devuelve. El controlador ReplicaSet obtiene el estado y actualiza el estado del conjunto de réplicas. Lo mismo sucede con el Deployment Controller y el usuario finalmente obtiene un estado actualizado (actual).
Operador de shell
Resulta que Kubernetes se basa en la colaboración de varios controladores (los operadores de Kubernetes también son controladores). Surge la pregunta, ¿cómo crear su propio operador con el mínimo esfuerzo? Y aquí viene al rescate el operador de caparazón desarrollado por nosotros . Permite a los administradores del sistema crear sus propias declaraciones utilizando métodos familiares.

Ejemplo simple: copiar secretos
Echemos un vistazo a un ejemplo sencillo.
Digamos que tenemos un clúster de Kubernetes. Tiene un espacio de nombres
defaultcon algún secreto mysecret. Además, hay otros espacios de nombres en el clúster. Algunos de ellos tienen una etiqueta específica adjunta. Nuestro objetivo es copiar Secret en espacios de nombres con una etiqueta.
La tarea se complica por el hecho de que pueden aparecer nuevos espacios de nombres en el clúster y algunos de ellos pueden tener esta etiqueta. Por otro lado, al eliminar una etiqueta, también debe eliminarse Secret. Además de todo, el secreto en sí también puede cambiar: en este caso, el nuevo secreto debe copiarse a todos los espacios de nombres con etiquetas. Si Secret se elimina accidentalmente en cualquier espacio de nombres, nuestro operador debe restaurarlo de inmediato.
Ahora que se ha formulado la tarea, es hora de comenzar a implementarla utilizando el operador de shell. Pero primero, vale la pena decir algunas palabras sobre el propio operador de shell.
Cómo funciona el operador de shell
Al igual que otras cargas de trabajo en Kubernetes, el operador de shell se ejecuta en su pod. Este pod
/hookscontiene archivos ejecutables en el directorio . Estos pueden ser scripts en Bash, Python, Ruby, etc. A estos ejecutables los llamamos ganchos .

Shell-operator se suscribe a los eventos de Kubernetes y activa estos ganchos en respuesta a cualquier evento que necesitemos.

¿Cómo sabe el operador de shell qué gancho ejecutar y cuándo? El caso es que cada anzuelo tiene dos etapas. Al inicio, el operador de shell ejecuta todos los ganchos con un argumento
--config; esta es la etapa de configuración. Y después de eso, los ganchos se lanzan de la manera normal, en respuesta a los eventos a los que están vinculados. En el último caso, el gancho recibe el contexto de enlace.): datos en formato JSON, que analizaremos con más detalle a continuación.
Haciendo un operador en Bash
Ahora estamos listos para la implementación. Para hacer esto, necesitamos escribir dos funciones (por cierto, recomendamos la biblioteca shell_lib , que simplifica enormemente la escritura de ganchos en Bash):
- el primero es necesario para la etapa de configuración: muestra el contexto de enlace;
- el segundo contiene la lógica principal del gancho.
#!/bin/bash
source /shell_lib.sh
function __config__() {
cat << EOF
configVersion: v1
# BINDING CONFIGURATION
EOF
}
function __main__() {
# THE LOGIC
}
hook::run "$@"
El siguiente paso es decidir qué objetos necesitamos. En nuestro caso, necesitamos rastrear:
- fuente secreta de cambios;
- todos los espacios de nombres en el clúster, para que sepa a cuál de ellos se adjunta la etiqueta;
- secretos de destino para asegurarse de que estén todos sincronizados con el secreto de origen.
Suscríbete a una fuente secreta
La configuración de encuadernación es bastante simple para él. Indicamos que estamos interesados en Secret con un nombre
mysecreten el espacio de nombres default:

function __config__() {
cat << EOF
configVersion: v1
kubernetes:
- name: src_secret
apiVersion: v1
kind: Secret
nameSelector:
matchNames:
- mysecret
namespace:
nameSelector:
matchNames: ["default"]
group: main
EOF
Como resultado, el
src_secretenlace se ejecutará cuando cambie el secreto de origen ( ) y recibirá el siguiente contexto de enlace:

Como puede ver, contiene el nombre y el objeto completo.
Hacer un seguimiento de los espacios de nombres
Ahora necesita suscribirse a los espacios de nombres. Para hacer esto, especificaremos la siguiente configuración de enlace:
- name: namespaces
group: main
apiVersion: v1
kind: Namespace
jqFilter: |
{
namespace: .metadata.name,
hasLabel: (
.metadata.labels // {} |
contains({"secret": "yes"})
)
}
group: main
keepFullObjectsInMemory: false
Como puede ver, ha aparecido un nuevo campo llamado jqFilter en la configuración . Como su nombre indica,
jqFilterfiltra toda la información innecesaria y crea un nuevo objeto JSON con los campos que nos interesan. Un gancho con esta configuración recibirá el siguiente contexto de enlace:
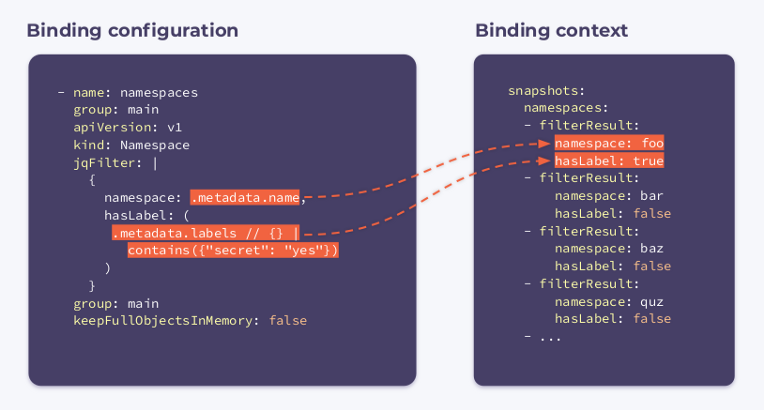
Contiene una matriz
filterResultspara cada espacio de nombres en el clúster. Una variable booleana que hasLabelindica si la etiqueta está adjunta al espacio de nombres dado. El selector keepFullObjectsInMemory: falsedice que no es necesario mantener objetos completos en la memoria.
Seguimiento de objetivos secretos
Nos suscribimos a todos los secretos que tienen una anotación
managed-secret: "yes"(estos son nuestros objetivos dst_secrets):
- name: dst_secrets
apiVersion: v1
kind: Secret
labelSelector:
matchLabels:
managed-secret: "yes"
jqFilter: |
{
"namespace":
.metadata.namespace,
"resourceVersion":
.metadata.annotations.resourceVersion
}
group: main
keepFullObjectsInMemory: false
En este caso,
jqFilterfiltra toda la información excepto el espacio de nombres y el parámetro resourceVersion. El último parámetro se pasó a la anotación al crear el secreto: te permite comparar versiones de secretos y mantenerlas actualizadas.
Un gancho configurado de esta manera recibirá los tres contextos de enlace descritos anteriormente cuando se ejecute. Piense en ellos como una especie de instantánea del clúster.

A partir de toda esta información, se puede desarrollar un algoritmo básico. Repite todos los espacios de nombres y:
- si es
hasLabelrelevantetruepara el espacio de nombres actual:- compara el secreto global con el local:
- si son iguales, no hace nada;
- si difieren, ejecutan
kubectl replaceocreate;
- compara el secreto global con el local:
- si es
hasLabelrelevantefalsepara el espacio de nombres actual:
- se asegura de que Secret no esté en el espacio de nombres dado:
- si el secreto local está presente, elimínelo usando
kubectl delete; - si no se encuentra ningún secreto local, no hace nada.
- si el secreto local está presente, elimínelo usando
- se asegura de que Secret no esté en el espacio de nombres dado:

Puede descargar la implementación del algoritmo en Bash en nuestro repositorio con ejemplos .
¡Así es como pudimos crear un controlador Kubernetes simple usando 35 líneas de configuraciones YAML y aproximadamente la misma cantidad de código Bash! El trabajo del operador de caparazón es unirlos.
Sin embargo, copiar secretos no es la única área de aplicación de la utilidad. Aquí hay algunos ejemplos más para mostrar de lo que es capaz.
Ejemplo 1: realizar cambios en ConfigMap
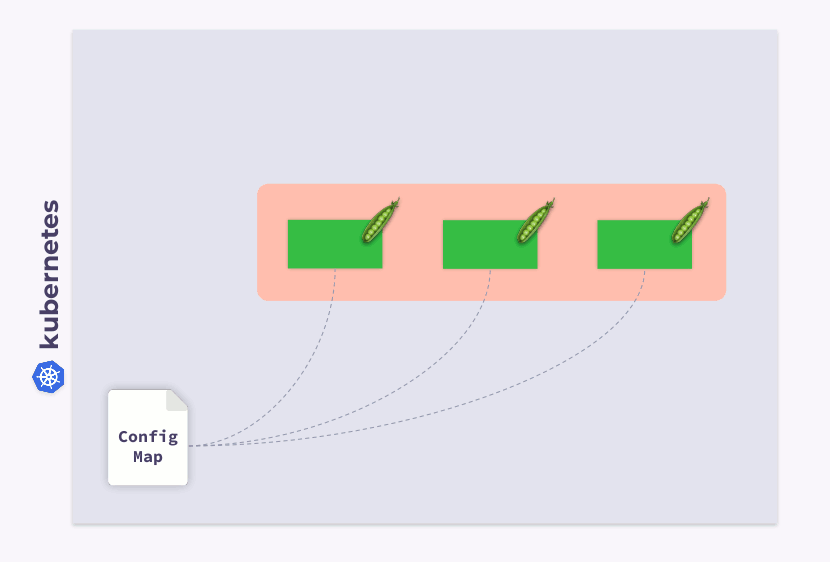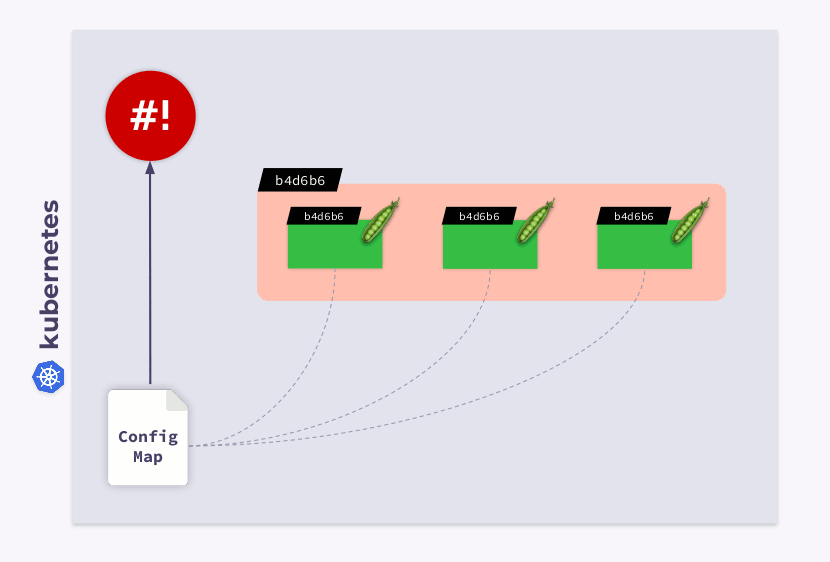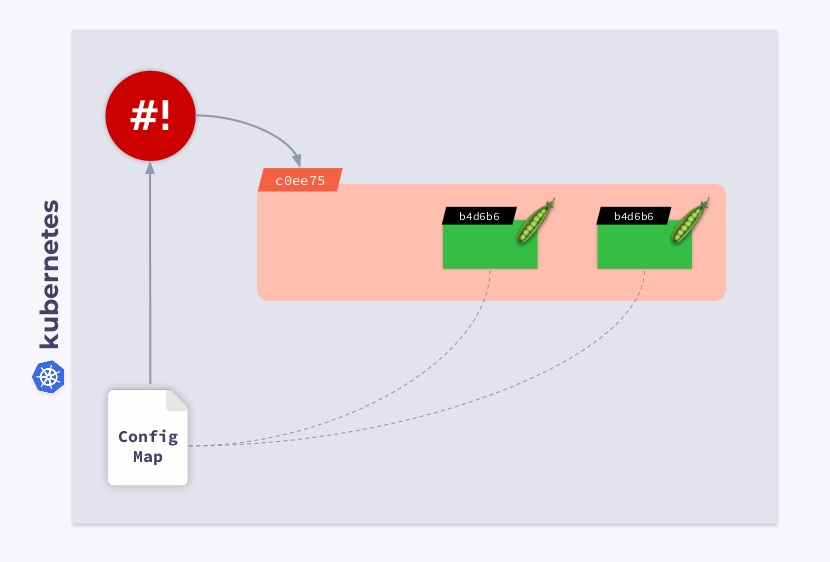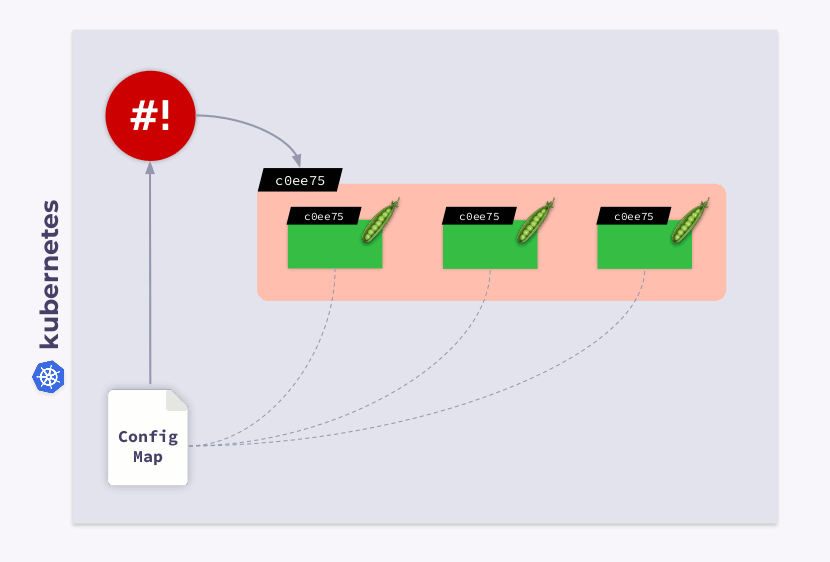
Echemos un vistazo a una implementación de tres pods. Los pods usan ConfigMap para almacenar alguna configuración. Cuando se lanzaron los pods, ConfigMap estaba en algún estado (llamémoslo v.1). En consecuencia, todos los pods usan esta versión particular de ConfigMap.
Ahora suponga que ConfigMap ha cambiado (v.2). Sin embargo, los pods usarán la versión anterior de ConfigMap (v.1):
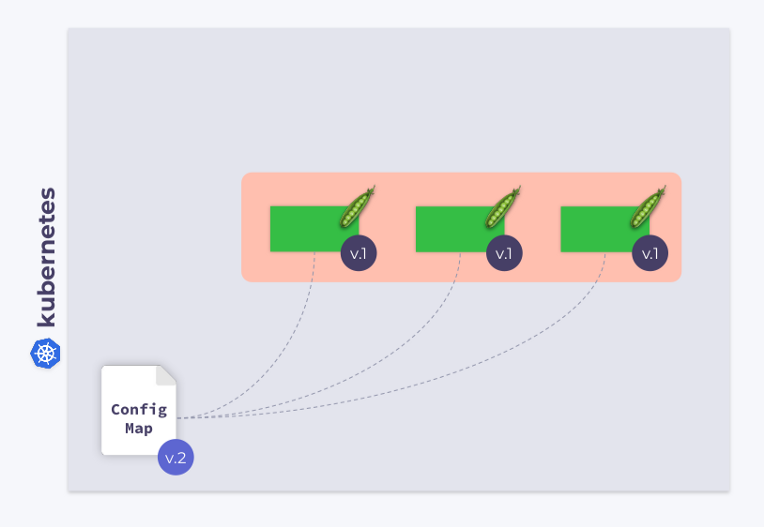
¿Cómo puedo hacer que migren al nuevo ConfigMap (v.2)? La respuesta es simple: use una plantilla. Agreguemos una anotación de suma de comprobación a la sección
templateConfiguración de implementación:

Como resultado, esta suma de comprobación se registrará en todos los pods y será la misma que en Implementación. Ahora solo necesita actualizar la anotación cuando ConfigMap cambie. Y el operador de caparazón es útil en este caso. Todo lo que necesita hacer es programar un enlace que se suscribirá a ConfigMap y actualizará la suma de comprobación .
Si el usuario realiza cambios en ConfigMap, el operador de shell los notará y volverá a calcular la suma de comprobación. Entonces entra en juego la magia de Kubernetes: el orquestador matará la cápsula, creará una nueva, esperará a que se convierta
Readyy pasará a la siguiente. Como resultado, la implementación se sincronizará y migrará a la nueva versión de ConfigMap.
Ejemplo 2: trabajar con definiciones de recursos personalizadas
Como sabe, Kubernetes le permite crear tipos (tipos) personalizados de objetos. Por ejemplo, puede crear kind
MysqlDatabase. Digamos que este tipo tiene dos parámetros de metadatos: nameynamespace.
apiVersion: example.com/v1alpha1
kind: MysqlDatabase
metadata:
name: foo
namespace: bar
Tenemos un clúster de Kubernetes con diferentes espacios de nombres en los que podemos crear bases de datos MySQL. En este caso, el operador de shell se puede utilizar para rastrear recursos
MysqlDatabase, conectarlos al servidor MySQL y sincronizar los estados deseados y observados del clúster.

Ejemplo 3: supervisión de una red de clústeres
Como sabe, usar ping es la forma más sencilla de monitorear una red. En este ejemplo, mostraremos cómo implementar dicho monitoreo usando el operador de shell.
En primer lugar, debe suscribirse a los nodos. El operador de shell necesita el nombre y la dirección IP de cada nodo. Con su ayuda, hará ping a estos nodos.
configVersion: v1
kubernetes:
- name: nodes
apiVersion: v1
kind: Node
jqFilter: |
{
name: .metadata.name,
ip: (
.status.addresses[] |
select(.type == "InternalIP") |
.address
)
}
group: main
keepFullObjectsInMemory: false
executeHookOnEvent: []
schedule:
- name: every_minute
group: main
crontab: "* * * * *"
El parámetro
executeHookOnEvent: []evita el lanzamiento del gancho en respuesta a cualquier evento (es decir, en respuesta a cambios, adiciones, eliminaciones de nodos). Sin embargo, se ejecutará (y actualizará la lista de hosts) según una programación , cada minuto, según lo indique el campo schedule.
Ahora surge la pregunta, ¿cómo sabemos exactamente sobre problemas como la pérdida de paquetes? Echemos un vistazo al código:
function __main__() {
for i in $(seq 0 "$(context::jq -r '(.snapshots.nodes | length) - 1')"); do
node_name="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.name')"
node_ip="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.ip')"
packets_lost=0
if ! ping -c 1 "$node_ip" -t 1 ; then
packets_lost=1
fi
cat >> "$METRICS_PATH" <<END
{
"name": "node_packets_lost",
"add": $packets_lost,
"labels": {
"node": "$node_name"
}
}
END
done
}
Repasamos la lista de nodos, obtenemos sus nombres y direcciones IP, hacemos ping y enviamos los resultados a Prometheus. Shell-operator puede exportar métricas a Prometheus , guardándolas en un archivo ubicado de acuerdo con la ruta especificada en la variable de entorno
$METRICS_PATH.
Así es como puede hacer un operador para un monitoreo de red simple en un clúster.
Mecanismo de cola
Este artículo estaría incompleto sin describir otro mecanismo importante integrado en el operador de shell. Imagine que ejecuta un gancho en respuesta a un evento en el clúster.
- ¿Qué sucede si ocurre otro evento en el clúster al mismo tiempo ?
- ¿El operador de shell iniciará otra instancia del gancho?
- Pero, ¿y si, digamos, cinco eventos ocurren inmediatamente en el grupo?
- ¿Los manejará el operador de caparazón en paralelo?
- ¿Qué pasa con los recursos consumidos como la memoria y la CPU?
Afortunadamente, el operador shell tiene un mecanismo de cola incorporado. Todos los eventos se ponen en cola y se procesan secuencialmente.
Ilustremos esto con ejemplos. Digamos que tenemos dos ganchos. El primer evento va al primer gancho. Una vez finalizado su procesamiento, la cola avanza. Los siguientes tres eventos se redirigen al segundo gancho: se eliminan de la cola y se introducen en un "lote". Es decir, el gancho recibe una serie de eventos , o más exactamente, una serie de contextos vinculantes.
Además, estos eventos se pueden combinar en uno grande . El parámetro
groupen la configuración de enlace es responsable de esto .

Puede crear cualquier número de colas / ganchos y sus diversas combinaciones. Por ejemplo, una cola puede funcionar con dos ganchos o viceversa.
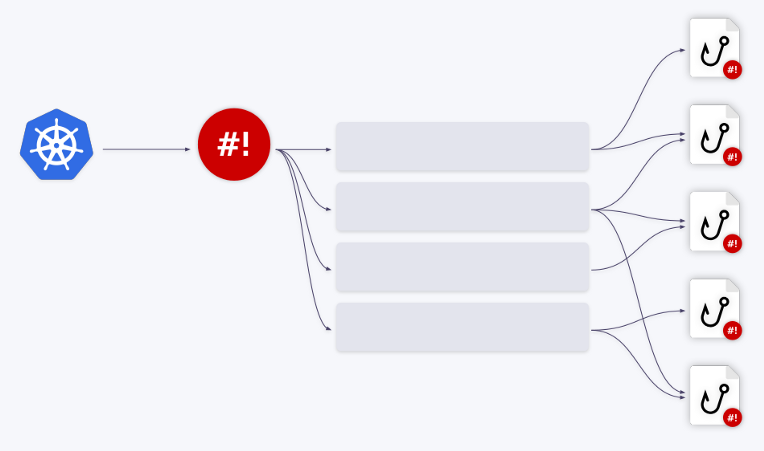
Todo lo que necesita hacer es ajustar el campo
queueen consecuencia en la configuración de enlace. Si no se especifica ningún nombre de cola, el enlace se ejecuta en la cola predeterminada ( default). Este mecanismo de cola le permite resolver completamente todos los problemas de administración de recursos cuando trabaja con ganchos.
Conclusión
Hablamos sobre qué es un operador de shell, mostramos cómo se puede utilizar para crear operadores de Kubernetes de forma rápida y sin esfuerzo, y dimos varios ejemplos de su uso.
La información detallada sobre el operador de shell, así como una guía rápida para usarlo, están disponibles en el repositorio correspondiente en GitHub . No dude en contactarnos con preguntas: puede discutirlas en un grupo especial de Telegram (en ruso) o en este foro (en inglés).
Y si te gustó, siempre estamos encantados de tener nuevos números / PR / estrellas en GitHub, donde, por cierto, puedes encontrar otros proyectos interesantes . Entre ellos, cabe destacar el addon-operator , que es el hermano mayor del shell-operator... Esta utilidad utiliza gráficos de Helm para instalar complementos, puede entregar actualizaciones y monitorear varios parámetros / valores de gráficos, controla el proceso de instalación de gráficos y también puede modificarlos en respuesta a eventos en el clúster.

Vídeos y diapositivas
Video de la actuación (~ 23 minutos):
Presentación del informe:
PD
Lea también en nuestro blog:
- " Creación simple de operadores de Kubernetes con un operador de shell: avance del proyecto en un año ";
- “ Presentamos el operador shell: crear operadores para Kubernetes ahora es más fácil ”;
- “ ¿Es fácil y conveniente preparar un clúster de Kubernetes? Anunciamos addon-operator ";
- " Ampliando y complementando Kubernetes" (reseña y vídeo del informe) .