Introducción
Este artículo es una recopilación de otro artículo . En él, pretendo concentrarme en herramientas para trabajar con Big data, enfocadas al análisis de datos.
Entonces, digamos que aceptó los datos sin procesar, los procesó y ahora está listo para su uso posterior.
Existen muchas herramientas que se utilizan para manipular datos, cada una con sus propias ventajas y desventajas. La mayoría de ellos están orientados a OLAP, pero algunos también están optimizados para OLTP. Algunos de ellos usan formatos estándar y se enfocan solo en la ejecución de consultas, otros usan su propio formato o almacenamiento para transferir los datos procesados a la fuente con el fin de mejorar el rendimiento. Algunos están optimizados para almacenar datos utilizando esquemas específicos, como estrella o copo de nieve, pero otros son más flexibles. Resumiendo, tenemos las siguientes oposiciones:
- Almacén de datos frente a lago
- Hadoop frente al almacenamiento sin conexión
- OLAP frente a OLTP
- Motor de consultas versus mecanismos OLAP
También veremos herramientas para procesar datos con la capacidad de ejecutar consultas.
Herramientas de procesamiento de datos
La mayoría de las herramientas mencionadas pueden conectarse a un servidor de metadatos como Hive y ejecutar consultas, crear vistas, etc. Esto se usa a menudo para crear niveles de informes adicionales (mejorados).
Spark SQL proporciona una forma de combinar sin problemas consultas SQL con programas Spark, para que pueda mezclar la API de DataFrame con SQL. Tiene integración con Hive y una conexión JDBC u ODBC estándar, por lo que puede conectar Tableau, Looker o cualquier herramienta de BI a sus datos a través de Spark.

Apache Flinktambién proporciona API SQL. El soporte SQL de Flink se basa en Apache Calcite, que implementa el estándar SQL. También se integra con Hive a través de HiveCatalog. Por ejemplo, los usuarios pueden almacenar sus tablas Kafka o ElasticSearch en Hive Metastore utilizando HiveCatalog y reutilizarlas más tarde en consultas SQL.
Kafka también proporciona capacidades SQL. En general, la mayoría de las herramientas de procesamiento de datos proporcionan interfaces SQL.
Herramientas de consulta
Este tipo de herramienta está enfocada a una consulta unificada a diferentes fuentes de datos en diferentes formatos. La idea es enrutar consultas a su lago de datos utilizando SQL como si fuera una base de datos relacional normal, aunque tiene algunas limitaciones. Algunas de estas herramientas también pueden consultar bases de datos NoSQL y mucho más. Estas herramientas proporcionan una interfaz JDBC a herramientas externas como Tableau o Looker para conectarse de forma segura a su lago de datos. Las herramientas de consulta son la opción más lenta, pero proporcionan la mayor flexibilidad.
Cerdo apache: una de las primeras herramientas junto con Hive. Tiene su propio idioma además de SQL. Una característica distintiva de los programas creados por Pig es que su estructura se presta a una paralelización significativa, lo que, a su vez, les permite procesar conjuntos de datos muy grandes. Debido a esto, todavía no está desactualizado en comparación con los sistemas modernos basados en SQL.
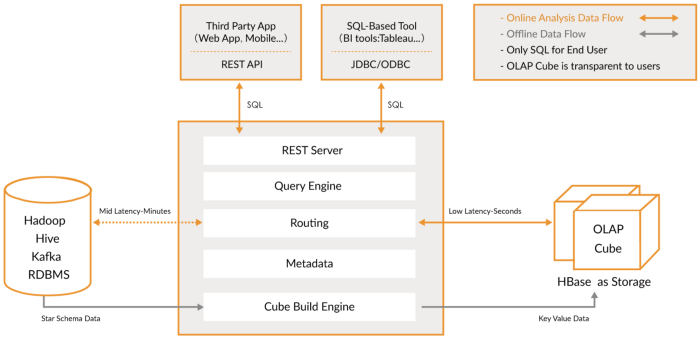
Presto: Una plataforma de código abierto de Facebook. Es un motor de consultas SQL distribuido para realizar consultas analíticas interactivas contra fuentes de datos de cualquier tamaño. Presto le permite consultar datos donde sea que estén, incluidos Hive, Cassandra, bases de datos relacionales y sistemas de archivos. Puede consultar grandes conjuntos de datos en segundos. Presto es independiente de Hadoop, pero se integra con la mayoría de sus herramientas, especialmente Hive, para ejecutar consultas SQL.
Taladro Apache: Proporciona un motor de consultas SQL sin esquema para Hadoop, NoSQL e incluso almacenamiento en la nube. No depende de Hadoop, pero tiene muchas integraciones con herramientas del ecosistema como Hive. Una sola consulta puede combinar datos de varias tiendas, realizando optimizaciones específicas para cada una de ellas. Esto es muy bueno porque permite a los analistas tratar cualquier dato como una tabla, incluso si realmente están leyendo el archivo. Drill es totalmente compatible con SQL estándar. Los usuarios empresariales, analistas y científicos de datos pueden utilizar herramientas de inteligencia empresarial estándar como Tableau, Qlik y Excel para interactuar con almacenes de datos no relacionales mediante los controladores Drill JDBC y ODBC. Además,Los desarrolladores pueden utilizar la sencilla API REST Drill en sus aplicaciones personalizadas para crear hermosas visualizaciones.
Bases de datos OLTP
Aunque Hadoop está optimizado para OLAP, todavía hay situaciones en las que desea ejecutar consultas OLTP en una aplicación interactiva.
HBase tiene propiedades ACID muy limitadas por diseño, ya que se creó a escala y no proporciona capacidades ACID listas para usar, pero puede usarse para algunos escenarios OLTP.
Apache Phoenix se basa en HBase y proporciona una forma de realizar consultas OTLP en todo el ecosistema de Hadoop. Apache Phoenix está completamente integrado con otros productos de Hadoop como Spark, Hive, Pig, Flume y Map Reduce. También puede almacenar metadatos, admitir la creación de tablas y cambios de versiones incrementales mediante comandos DDL. Funciona bastante rápido, más rápido que usar Drill u otro
mecanismo de solicitudes.
Puede utilizar cualquier base de datos a gran escala fuera del ecosistema de Hadoop como Cassandra, YugaByteDB, ScyllaDB para OTLP.
Finalmente, es muy común que las bases de datos rápidas de cualquier tipo, como MongoDB o MySQL, tengan un subconjunto de datos más lento, generalmente el más reciente. Los motores de consulta mencionados anteriormente pueden combinar datos entre el almacenamiento lento y rápido en una sola consulta.
Indexación distribuida
Estas herramientas proporcionan formas de almacenar y recuperar datos de texto no estructurados, y viven fuera del ecosistema de Hadoop, ya que requieren estructuras especializadas para almacenar los datos. La idea es utilizar un índice invertido para realizar búsquedas rápidas. Además de la búsqueda de texto, esta tecnología se puede utilizar para una variedad de propósitos, como almacenar registros, eventos, etc. Hay dos opciones principales:
Solr: Esta es una plataforma de búsqueda empresarial de código abierto muy rápida y popular construida sobre Apache Lucene. Solr es una herramienta robusta, escalable y resistente que proporciona indexación distribuida, replicación y consultas de equilibrio de carga, recuperación y conmutación por error automáticas, configuración centralizada y más. Es excelente para la búsqueda de texto, pero sus casos de uso son limitados en comparación con ElasticSearch.
ElasticSearch: También es un índice distribuido muy popular, pero se ha convertido en un ecosistema propio que abarca muchos casos de uso, como APM, búsqueda, almacenamiento de texto, análisis, paneles, aprendizaje automático y más. Definitivamente es una herramienta para tener en su caja de herramientas para DevOps o para la canalización de datos, ya que es muy versátil. También puede almacenar y buscar videos e imágenes.
ElasticSearchse puede utilizar como una capa de almacenamiento rápido para su lago de datos para la funcionalidad de búsqueda avanzada. Si está almacenando sus datos en una gran base de datos de valores clave como HBase o Cassandra, que brindan capacidades de búsqueda muy limitadas debido a la falta de conexiones, puede poner ElasticSearch delante de ellos para ejecutar consultas, devolver ID y luego realice una búsqueda rápida en su base de datos.
También se puede utilizar para análisis. Puede exportar sus datos, indexarlos y luego consultarlos usando KibanaAl crear paneles, informes y más, puede agregar histogramas, agregaciones complejas e incluso ejecutar algoritmos de aprendizaje automático sobre sus datos. El ecosistema ElasticSearch es enorme y vale la pena explorarlo.
Bases de datos OLAP
Aquí buscamos bases de datos que también pueden proporcionar un almacén de metadatos para esquemas de consulta. En comparación con los sistemas de ejecución de consultas, estas herramientas también proporcionan almacenamiento de datos y se pueden aplicar a esquemas de almacenamiento específicos (esquema en estrella). Estas herramientas utilizan sintaxis SQL. Spark u otras plataformas pueden interactuar con ellos.
Colmena Apache: ya hablamos de Hive como un repositorio de esquemas central para Spark y otras herramientas para que puedan usar SQL, pero Hive también puede almacenar datos, por lo que puede usarlo como un repositorio. Puede acceder a HDFS o HBase. Cuando lo solicita Hive, utiliza Apache Tez, Apache Spark o MapReduce, siendo mucho más rápido que Tez o Spark. También tiene un lenguaje de procedimiento llamado HPL-SQL. Hive es un almacén de metadatos extremadamente popular para Spark SQL.
Apache Impala: Es una base de datos analítica nativa para Hadoop que puede usar para almacenar datos y consultarlos de manera eficiente. Puede conectarse a Hive para obtener metadatos usando Hcatalog. Impala proporciona baja latencia y alta simultaneidad para consultas de inteligencia empresarial y análisis en Hadoop (que no se proporciona en plataformas empaquetadas como Apache Hive). Impala también escala linealmente, incluso en entornos multiusuario, que es una mejor alternativa de consulta que Hive. Impala está integrado con la seguridad patentada de Hadoop y Kerberos para la autenticación, por lo que puede administrar de forma segura el acceso a los datos. Utiliza HBase y HDFS para el almacenamiento de datos.

Apache Tajo: Este es otro almacén de datos para Hadoop. Tajo está diseñado para ejecutar consultas ad-hoc con baja latencia y escalabilidad, agregación en línea y ETL para grandes conjuntos de datos almacenados en HDFS y otras fuentes de datos. Admite la integración con Hive Metastore para acceder a esquemas comunes. También tiene muchas optimizaciones de consultas, es escalable, tolerante a fallas y proporciona una interfaz JDBC.
Apache Kylin: Este es un nuevo almacén de datos analíticos distribuidos. Kylin es extremadamente rápido, por lo que se puede utilizar para complementar algunas otras bases de datos como Hive para casos de uso donde el rendimiento es crítico, como paneles de control o informes interactivos. Este es probablemente el mejor almacén de datos OLAP, pero es difícil de usar. Otro problema es que se requiere más espacio de almacenamiento debido al gran estiramiento. La idea es que si los motores de consulta o Hive no son lo suficientemente rápidos, puede crear un "Cube" en Kylin, que es una tabla multidimensional optimizada para OLAP con
valores que puede consultar desde paneles o informes interactivos. Puede crear cubos directamente desde Spark e incluso casi en tiempo real desde Kafka.
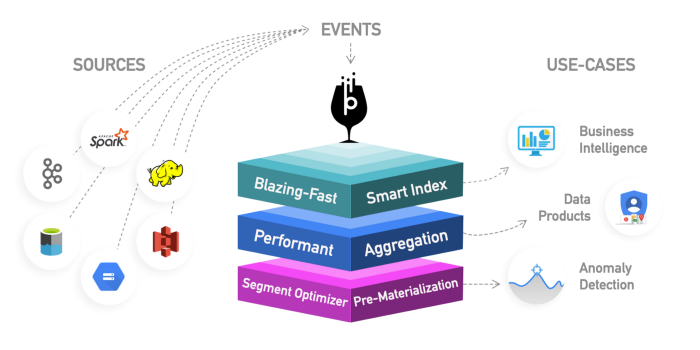
Herramientas OLAP
En esta categoría, incluyo motores más nuevos, que son evoluciones de bases de datos OLAP anteriores, que brindan más funcionalidad, creando una plataforma analítica integral. De hecho, son un híbrido de las dos categorías anteriores que agregan indexación a sus bases de datos OLAP. Viven fuera de la plataforma Hadoop pero están estrechamente integrados. En este caso, normalmente omite el paso de procesamiento y utiliza estas herramientas directamente.
Intentan resolver el problema de consultar datos en tiempo real y datos históricos de manera uniforme, para que pueda consultar datos en tiempo real inmediatamente tan pronto como estén disponibles, junto con datos históricos de baja latencia para que pueda crear aplicaciones y paneles interactivos. Estas herramientas permiten, en muchos casos, consultar datos sin procesar con poca o ninguna transformación estilo ELT, pero con alto rendimiento, mejor que las bases de datos OLAP convencionales.
Lo que tienen en común es que brindan una vista unificada de datos, ingesta de datos en vivo y por lotes, indexación distribuida, formato de datos nativo, compatibilidad con SQL, interfaz JDBC, compatibilidad con datos en caliente y en frío, múltiples integraciones y almacenamiento de metadatos.
Apache Druid: Este es el motor OLAP en tiempo real más famoso. Se centra en datos de series de tiempo, pero se puede utilizar para cualquier dato. Utiliza su propio formato de columnas que puede comprimir mucho los datos y tiene muchas optimizaciones integradas, como índices invertidos, codificación de texto, datos que se contraen automáticamente y más. Los datos se cargan en tiempo real utilizando Tranquility o Kafka, que tienen una latencia muy baja, se almacenan en la memoria en un formato de cadena optimizado para escritura, pero tan pronto como llegan, están disponibles para consultas, al igual que los datos descargados anteriormente. El proceso en segundo plano es responsable de mover datos de forma asincrónica a un sistema de almacenamiento profundo como HDFS. Cuando los datos se mueven a un almacenamiento profundo, se dividen en fragmentos más pequeños,segregados en el tiempo, llamados segmentos, que están bien optimizados para consultas de baja latencia. Este segmento tiene una marca de tiempo para varias dimensiones que puede usar para filtrar y agregar, y métricas, que son estados precalculados. En la recepción de ráfagas, los datos se guardan directamente en segmentos. Apache Druid admite la deglución de empujar y tirar, la integración con Hive, Spark e incluso NiFi. Puede usar el almacén de metadatos de Hive y admite consultas SQL de Hive, que luego se convierten en consultas JSON utilizadas por Druid. La integración de Hive admite JDBC, por lo que puede conectar cualquier herramienta de BI. También tiene su propio repositorio de metadatos, generalmente se usa MySQL para esto.Puede aceptar grandes cantidades de datos y se escala muy bien. El principal problema es que tiene muchos componentes y es difícil de administrar e implementar.
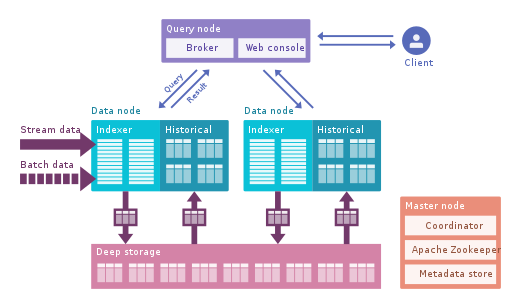
Apache Pinot : esta es una nueva alternativa Druid de código abierto de LinkedIn. En comparación con Druid, ofrece una latencia más baja gracias al índice Startree, que realiza un cálculo previo parcial, por lo que puede usarse para aplicaciones centradas en el usuario (se usó para obtener feeds de LinkedIn). Utiliza un índice ordenado en lugar de uno invertido, que es más rápido. Tiene una arquitectura de complementos extensible y también tiene muchas integraciones, pero no es compatible con Hive. También integra procesamiento por lotes y en tiempo real, proporciona carga rápida, índice inteligente y almacena datos en segmentos. Es más fácil y rápido de implementar en comparación con Druid, pero parece un poco inmaduro en este momento.
ClickHouse: Escrito en C ++, este motor proporciona un rendimiento increíble para consultas OLAP, especialmente para agregados. Es como una base de datos relacional, por lo que puede modelar los datos fácilmente. Es muy fácil de configurar y tiene muchas integraciones.
Lea este artículo que compara los 3 motores en detalle.
Empiece poco a poco examinando sus datos antes de tomar una decisión. Estos nuevos mecanismos son muy poderosos, pero difíciles de usar. Si puede esperar horas, utilice el procesamiento por lotes y una base de datos como Hive o Tajo; luego use Kylin para acelerar las consultas OLAP y hacerlas más interactivas. Si eso no es suficiente y necesita incluso menos latencia y datos en tiempo real, considere los motores OLAP. Druid es más adecuado para análisis en tiempo real. Kaileen se centra más en los casos OLAP. Druid tiene una buena integración con Kafka como transmisión en vivo. Kylin está recibiendo datos de Hive o Kafka en lotes, aunque está prevista una recepción en directo.
Finalmente, Greenplum Es otro motor OLAP, más enfocado a la inteligencia artificial.
Visualización de datos
Existen varias herramientas comerciales para la visualización, como Qlik, Looker o Tableau.
Si prefiere Open Source, busque SuperSet. Es una gran herramienta que soporta todas las herramientas que mencionamos, tiene un gran editor y es realmente rápida, usa SQLAlchemy para brindar soporte a muchas bases de datos.
Otras herramientas interesantes son Metabase o Falcon .
Conclusión
Existe una amplia variedad de herramientas que se pueden utilizar para manipular datos, desde motores de consulta flexibles como Presto hasta almacenamiento de alto rendimiento como Kylin. No existe una solución única para todos, le aconsejo que investigue los datos y comience con algo pequeño. Los motores de consulta son un buen punto de partida debido a su flexibilidad. Luego, para diferentes casos de uso, es posible que deba agregar herramientas adicionales para lograr el nivel de servicio que desea.
Preste especial atención a las nuevas herramientas como Druid o Pinot, que proporcionan una forma sencilla de analizar grandes cantidades de datos con una latencia muy baja, reduciendo la brecha entre OLTP y OLAP en términos de rendimiento. Es posible que tenga la tentación de pensar en el procesamiento, el cálculo previo de agregados y cosas por el estilo, pero considere estas herramientas si desea simplificar su trabajo.