
¡Hola!
Mi nombre es Nikita y superviso el desarrollo de varios proyectos en DomClick. Hoy quiero continuar con el tema de las "imágenes divertidas" en el mundo de RabbitMQ. En su artículo, Alexey Kazakov consideró una herramienta tan poderosa como las colas diferidas y las diferentes implementaciones de la estrategia Retry. Hoy hablaremos sobre cómo usar RabbitMQ para programar tareas periódicas.
¿Por qué necesitamos crear nuestra propia bicicleta y por qué abandonamos el apio y otras herramientas de gestión de tareas? El caso es que no se ajustaban a nuestras tareas y requisitos de tolerancia a fallos, que son bastante estrictos en nuestra empresa.
Al cambiar a Docker y Kubernetes, muchos desarrolladores se enfrentan a los problemas de organizar tareas periódicas, las coronas se lanzan con una pandereta y el control del proceso deja mucho que desear. Y luego están los problemas con las cargas máximas durante el día.
Mi tarea consistía en implementar en el proyecto un sistema confiable para procesar tareas periódicas, fácilmente escalable y tolerante a fallas. Nuestro proyecto está en Python, por lo que era lógico ver cómo nos conviene Celery. Esta es una buena herramienta, pero con ella a menudo nos hemos encontrado con problemas de confiabilidad, escalabilidad y lanzamiento sin interrupciones. Una vaina, un grupo de procesos. Al escalar Apio, debe aumentar los recursos de un pod, porque no hay sincronización entre los pods, lo que significa detener el procesamiento de tareas, aunque sea temporalmente. Y si las tareas también son a largo plazo, entonces ya adivinó lo difícil que es gestionarlas. El segundo inconveniente obvio: de fábrica no hay soporte para la asincronía, y para nosotros esto es importante, porque las tareas contienen principalmente operaciones de E / S, y Celery se ejecuta en subprocesos.
En ese momento (2018), no encontramos una herramienta preparada adecuada y comenzamos a desarrollar la nuestra. Tomando como base la funcionalidad de ejecución diferida de tareas y el Intercambio de Letra Muerta, decidimos crear un sistema para el procesamiento de tareas periódicas. El concepto se veía así:
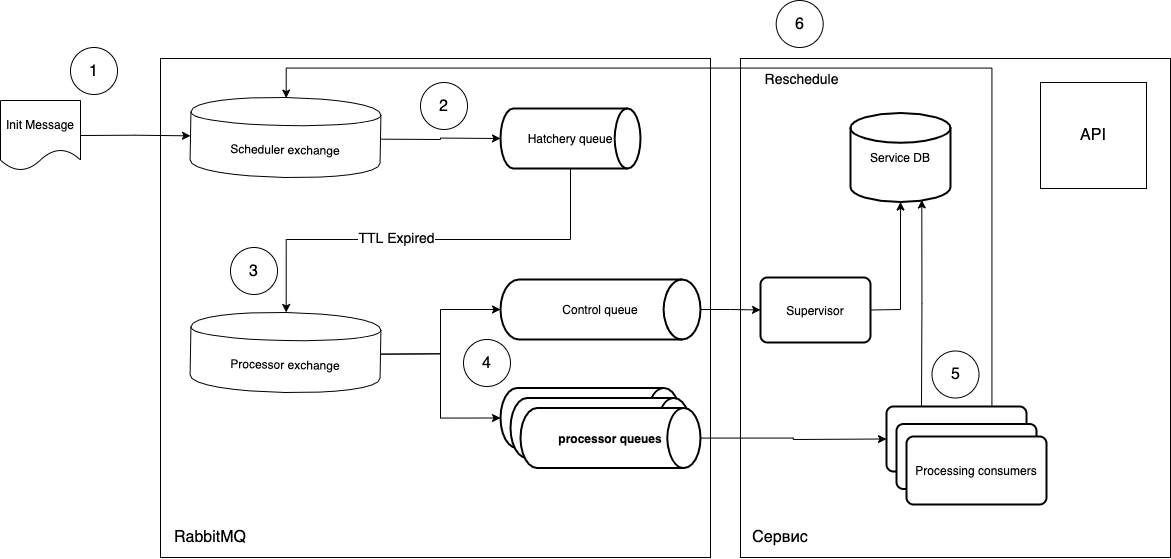
intentaré explicar qué es qué.
- Las tareas se envían en forma de mensaje al intercambio del Programador.
- El
routing_keysoftware entra en la cola de incubación requerida, que tiene un parámetromessage_ttl, y también la conexión con el intercambio del procesador como un intercambio de cartas de trato. La cola de "maduración" no está asociada con el tipo de tareas, solo desempeña el papel de un "temporizador", es decir, puede crear tantas colas como períodos necesite y gestionarlasrouting_key. - Dado que la cola no tiene oyentes, los mensajes después de "madurar" en la cola van al intercambio de Procesador.
- Luego, el consumidor libre (consumidor de procesamiento) toma el mensaje y lo ejecuta. Después de la ejecución, el ciclo se repite si es necesario.
¿Cuál es la ventaja de tal esquema?
- Ejecución por fases, es decir, no se procesará una nueva tarea si no se ha completado la anterior.
- Un solo oyente (consumidor), es decir, puede hacer tanto trabajadores universales como especializados. Escalado simplemente aumentando la cantidad de vainas necesarias.
- Implemente nuevas tareas sin interrumpir el trabajo de las actuales. Es suficiente actualizar suavemente los pods de escucha y enviar el mensaje apropiado a la cola. Es decir, puede generar pods con un nuevo código, que se ocupará de los mensajes nuevos, y los procesos actuales permanecerán en los pods antiguos. Esto nos da una actualización perfecta.
- Puede utilizar código asincrónico y cualquier infraestructura, sin dejar de ser independiente de la pila.
- Se puede controlar la ejecución de las tareas en el nativo
ack/ nivelreject, y también obtener una cola adicional opcional (cola de control) que puede realizar un seguimiento del ciclo de vida de las tareas.
El circuito resultó ser bastante simple, creamos rápidamente un prototipo funcional. Y el código es hermoso. Es suficiente marcar la función de devolución de llamada con un decorador simple que controla el ciclo de vida del mensaje.
def rmq_scheduler(routing_key_for_delay_queue, routing_key_for_processing_queue):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
log_error(e)
redelivered_count = get_count_of_redelivery_attempts(properties)
if redelivered_count <= 3:
await resend_msg(
channel=channel,
body=body,
properties=properties,
routing_key=routing_key_for_processing_queue)
else:
async with app.natalya_db_engine.acquire() as conn:
async with conn.begin():
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return wrapper
return decorator
Ahora usamos este esquema para realizar solo tareas secuenciales periódicas, pero también se puede usar cuando es importante comenzar a ejecutar una tarea en un momento específico, sin desplazar el tiempo a la ejecución en sí. Para hacer esto, simplemente vuelva a programar la tarea después de que el mensaje llegue al supervisor.
Es cierto que este enfoque tiene costos generales adicionales. Debe comprender que en caso de error, el mensaje volverá a la cola, otro trabajador lo recogerá y comenzará a ejecutarlo inmediatamente. Por lo tanto, debe separar el manejo de errores según el grado de criticidad y pensar de antemano qué hacer con el mensaje en caso de que se produzca tal o cual error.
Posibles opciones:
- El error se solucionará solo (por ejemplo, es un error del sistema): envíe
noacky repita el manejo de errores. - Error de lógica empresarial: debe interrumpir el ciclo - enviar
ack. - El error del punto 1 se repite con demasiada frecuencia: envenenamos
rejecty avisamos a los desarrolladores. Aquí hay opciones. Puede crear una cola de cartas de trato para que los mensajes se depositen a fin de devolver el mensaje después del análisis, o puede utilizar la técnica de reintento (especificarmessage_ttl).
Ejemplo de decorador:
def auto_ack_or_nack(log_message):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
await channel.basic_client_nack(envelope.delivery_tag, requeue=False)
log_error(log_message, exception=e)
return wrapper
return decorator
Este esquema ha estado trabajando con nosotros durante medio año, es bastante confiable y prácticamente no requiere atención. El bloqueo de la aplicación no interrumpe el programador y solo retrasa ligeramente la ejecución de las tareas.
No hay ventajas sin desventajas. Este esquema también tiene una vulnerabilidad crítica. Si algo le sucedió a RabbitMQ y los mensajes desaparecieron, entonces debe mirar manualmente lo que se perdió y comenzar el ciclo nuevamente. Pero esta es una situación extremadamente improbable en la que tendrá que pensar en este servicio al final :)
PD Si el tema de la programación de tareas periódicas le parece interesante, en el próximo artículo, le contaré con más detalle cómo automatizamos la creación de colas, así como sobre Supervisor.
Enlaces: