
Mucha gente piensa que es suficiente con portar la aplicación a Kubernetes (ya sea usando Helm o manualmente) y habrá felicidad. Pero no es tan simple.
El equipo de Mail.ru Cloud Solutions hatraducido un artículo del ingeniero de DevOps Julian Guindi. Habla de los escollos que enfrentó su empresa en el proceso de migración para que no pises el mismo rastrillo.
Paso uno: configure las solicitudes y los límites de los pods
Comencemos por configurar un entorno limpio en el que se ejecutarán nuestros pods. Kubernetes es excelente para programar pods y manejar estados de falla. Pero resultó que el planificador a veces no puede colocar un módulo si es difícil estimar cuántos recursos necesita para funcionar correctamente. Aquí es donde entran las solicitudes de recursos y los límites. Ha habido mucho debate sobre el mejor enfoque para establecer solicitudes y límites. A veces parece que realmente es más arte que ciencia. Este es nuestro enfoque.
Las solicitudes de pod son el valor principal que utiliza el programador para una ubicación óptima del pod.
Kubernetes: , . , PodFitsResources , .
Usamos solicitudes de aplicaciones para poder usarlas para estimar cuántos recursos realmente necesita la aplicación para funcionar correctamente. Esto permitirá al planificador colocar los nodos de manera realista. Inicialmente, queríamos configurar solicitudes con un margen para asegurarnos de que hubiera suficientes recursos para cada pod, pero notamos que el tiempo de programación aumentó significativamente y algunos pods nunca se programaron por completo, como si no hubiera solicitudes de recursos para ellos.
En este caso, el programador a menudo "exprime" los pods y no podría reprogramarlos porque el plano de control no tenía idea de cuántos recursos necesitaría la aplicación, que es un componente clave del algoritmo de programación.
Límites de podEs una limitación más clara para la vaina. Representa la cantidad máxima de recursos que el clúster asignará al contenedor.
Nuevamente, de la documentación oficial : si se establece un límite de memoria de 4 GiB para un contenedor, entonces kubelet (y el tiempo de ejecución del contenedor) lo forzará. El tiempo de ejecución evita que el contenedor utilice más del límite de recursos especificado. Por ejemplo, cuando un proceso en un contenedor intenta usar más de la cantidad de memoria permitida, el kernel sale del proceso con un error de "memoria insuficiente" (OOM).
Un contenedor siempre puede usar más recursos de los especificados en una solicitud de recursos, pero nunca puede usar más de los especificados en un límite. Este valor es difícil de establecer correctamente, pero es muy importante.
Idealmente, queremos que los requisitos de recursos del módulo cambien a lo largo del ciclo de vida del proceso sin interferir con otros procesos en el sistema; este es el objetivo de establecer límites.
Desafortunadamente, no puedo dar instrucciones específicas sobre qué valores establecer, pero nosotros mismos nos adherimos a las siguientes reglas:
- Utilizando una herramienta de prueba de carga, simulamos el tráfico de línea de base y monitoreamos el uso de recursos del pod (memoria y procesador).
- ( 5 ) . , , Go.
Tenga en cuenta que las mayores restricciones de recursos dificultan la programación porque el pod necesita un nodo de destino con suficientes recursos disponibles.
Imagine una situación en la que tiene un servidor web ligero con una limitación de recursos muy alta, como 4 GB de memoria. Es probable que este proceso deba escalarse horizontalmente y cada módulo nuevo deberá programarse en un nodo con al menos 4 GB de memoria disponible. Si no existe tal nodo, el clúster debe introducir un nuevo nodo para procesar este pod, lo que puede llevar algún tiempo. Es importante mantener el margen entre las solicitudes de recursos y los límites lo más pequeño posible para garantizar un escalado rápido y fluido.
Paso dos: configure las pruebas de vivacidad y preparación
Este es otro tema sutil que se discute con frecuencia en la comunidad de Kubernetes. Es importante tener un buen conocimiento de las pruebas de disponibilidad y disponibilidad, ya que proporcionan un mecanismo para que el software se ejecute sin problemas y minimice el tiempo de inactividad. Sin embargo, pueden afectar seriamente el rendimiento de su aplicación si no se configuran correctamente. A continuación se muestra un resumen de lo que son ambas muestras.
Liveness muestra si el contenedor está funcionando. Si falla, el kubelet mata el contenedor y se habilita una política de reinicio para él. Si el contenedor no está equipado con una sonda de Liveness, el estado predeterminado será correcto, como se indica en la documentación de Kubernetes .
Las sondas de actividad deben ser económicas, es decir, no consumir muchos recursos, porque se ejecutan con frecuencia y deben informar a Kubernetes que la aplicación se está ejecutando.
Configurarlo para que se ejecute cada segundo agregará 1 solicitud por segundo, así que tenga en cuenta que se necesitarán recursos adicionales para manejar este tráfico.
En nuestra empresa, las pruebas Liveness validan los componentes principales de una aplicación, incluso si los datos (por ejemplo, de una base de datos remota o caché) no están completamente disponibles.
Hemos configurado un punto final de "salud" en aplicaciones que simplemente devuelve un código de respuesta de 200. Esto es una indicación de que un proceso está en funcionamiento y es capaz de manejar solicitudes (pero aún no tráfico).
Prueba de preparaciónindica si el contenedor está listo para atender solicitudes. Si la sonda de preparación falla, el controlador de punto final elimina la dirección IP del módulo de los puntos finales de todos los servicios que coinciden con el módulo. Esto también se indica en la documentación de Kubernetes.
Las sondas de preparación consumen más recursos, ya que deben ir al backend de tal manera que indiquen que la aplicación está lista para aceptar solicitudes.
Hay mucho debate en la comunidad sobre si ir directamente a la base de datos. Dada la sobrecarga (las verificaciones se realizan con frecuencia, pero se pueden ajustar), decidimos que para algunas aplicaciones, la disponibilidad para atender el tráfico se cuenta solo después de verificar que los registros se devuelvan desde la base de datos. Las sondas de disponibilidad bien diseñadas garantizaron una mayor disponibilidad y eliminaron el tiempo de inactividad durante la implementación.
Si decide consultar la base de datos para comprobar que su aplicación está lista, asegúrese de que sea lo más barata posible. Tomemos una consulta como esta:
SELECT small_item FROM table LIMIT 1A continuación, se muestra un ejemplo de cómo configuramos estos dos valores en Kubernetes:
livenessProbe:
httpGet:
path: /api/liveness
port: http
readinessProbe:
httpGet:
path: /api/readiness
port: http periodSeconds: 2
Se pueden agregar algunas opciones de configuración adicionales:
initialDelaySeconds- cuántos segundos transcurrirán entre el inicio del contenedor y el inicio de las muestras.periodSeconds— .timeoutSeconds— , . -.failureThreshold— , .successThreshold— , ( , ).
:
Kubernetes tiene una topografía de red "plana"; de forma predeterminada, todos los pods interactúan directamente entre sí. En algunos casos, esto no es deseable.
Un problema de seguridad potencial es que un atacante podría usar una única aplicación vulnerable para enviar tráfico a todos los pods de la red. Como ocurre con muchas áreas de seguridad, se aplica el principio de privilegio mínimo. Idealmente, las políticas de red deberían indicar explícitamente qué conexiones entre pods están permitidas y cuáles no.
Por ejemplo, la siguiente es una política simple que deniega todo el tráfico entrante para un espacio de nombres específico:
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress
Visualización de esta configuración:
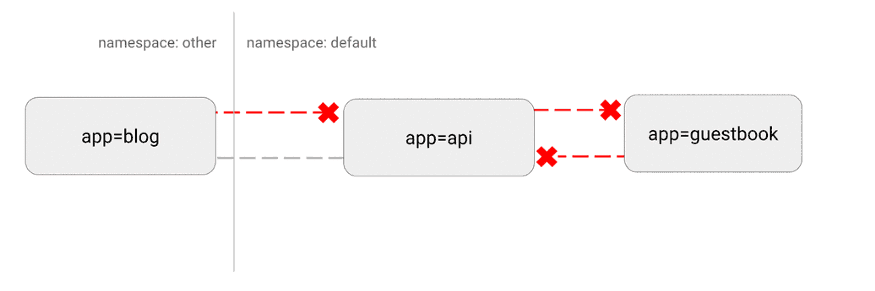
(https://miro.medium.com/max/875/1*-eiVw43azgzYzyN1th7cZg.gif)
Más detalles aquí .
Paso cuatro: comportamiento personalizado con hooks y contenedores init
Uno de nuestros principales objetivos era proporcionar implementaciones en Kubernetes sin tiempo de inactividad para los desarrolladores. Esto es difícil porque hay muchas opciones para cerrar aplicaciones y liberar recursos usados.
Surgieron dificultades particulares con Nginx . Notamos que cuando estos pods se implementaron secuencialmente, las conexiones activas se descartaron antes de que se completaran correctamente.
Después de una extensa investigación en Internet, resultó que Kubernetes no espera a que las conexiones de Nginx se agoten antes de apagar el módulo. Con la ayuda de un gancho pre-stop, implementamos la siguiente funcionalidad y eliminamos por completo el tiempo de inactividad:
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
Y aqui
nginx-killer.sh:
#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
done
Otro paradigma extremadamente útil es el uso de contenedores init para manejar el lanzamiento de aplicaciones específicas. Esto es especialmente útil si tiene un proceso de migración de base de datos que requiere muchos recursos y que debe iniciarse antes de ejecutar la aplicación. También puede especificar un límite de recursos más alto para este proceso sin establecer dicho límite para la aplicación principal.
Otro esquema común es acceder a secretos en el contenedor init, que proporciona estas credenciales al módulo principal, lo que evita el acceso no autorizado a secretos desde el módulo principal de la aplicación.
, : init- , . , .
:
Finalmente, hablemos de una técnica más avanzada.
Kubernetes es una plataforma extremadamente flexible que le permite ejecutar cargas de trabajo como mejor le parezca. Tenemos una serie de aplicaciones de alta eficiencia que consumen muchos recursos. A través de pruebas de carga exhaustivas, descubrimos que una de las aplicaciones tiene dificultades para manejar la carga de tráfico esperada cuando los valores predeterminados de Kubernetes están en vigor.
Sin embargo, Kubernetes le permite ejecutar un contenedor privilegiado que cambia los parámetros del kernel solo para un pod específico. Esto es lo que usamos para cambiar el número máximo de conexiones abiertas:
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "sysctl -w net.core.somaxconn=32768"]
Esta es una técnica más avanzada y, a menudo, innecesaria. Pero si su aplicación tiene problemas para hacer frente a una carga pesada, puede intentar ajustar algunos de estos parámetros. Más detalles sobre este proceso y configuración de varios valores, como siempre en la documentación oficial .
Finalmente
Si bien Kubernetes puede parecer una solución lista para usar, hay varios pasos clave que debe seguir para mantener sus aplicaciones funcionando sin problemas.
A lo largo de su migración a Kubernetes, es importante seguir un "ciclo de prueba de carga": ejecute la aplicación, pruebe la carga, observe las métricas y el comportamiento de escala, ajuste la configuración en función de esos datos y luego repita el ciclo nuevamente.
Estime de manera realista el tráfico esperado e intente ir más allá para ver qué componentes se rompen primero. Con este enfoque iterativo, solo algunas de estas recomendaciones pueden ser suficientes para lograr el éxito. O puede ser necesaria una personalización más profunda.
Hágase siempre estas preguntas:
- ?
- ? ? ?
- ? , ?
- ? ? ?
- ? - , ?
Kubernetes proporciona una plataforma increíble que permite las mejores prácticas para implementar miles de servicios en un clúster. Sin embargo, todas las aplicaciones son diferentes. A veces, la implementación requiere un poco más de trabajo.
Afortunadamente, Kubernetes proporciona la configuración necesaria para cumplir con todos los objetivos técnicos. Con una combinación de solicitudes y límites de recursos, sondeos de disponibilidad y disponibilidad, contenedores de inicio, políticas de red y ajustes personalizados del kernel, puede lograr un alto rendimiento junto con tolerancia a fallas y una rápida escalabilidad.
Qué más leer: