El aprendizaje por refuerzo es malo, o mejor dicho, no funciona en absoluto con dimensiones elevadas. Y también se enfrenta al problema de que los simuladores de física son bastante lentos. Por lo tanto, recientemente, una forma de eludir estas limitaciones se ha vuelto popular entrenando una red neuronal separada que simula un motor de física. Resulta algo así como un análogo de la imaginación, en el que tiene lugar un aprendizaje básico adicional.
Veamos cuánto se ha avanzado en esta área y observemos las principales arquitecturas.
La idea de utilizar una red neuronal en lugar de un simulador físico no es nueva, ya que simuladores simples como MuJoCo o Bullet en CPU modernas son capaces de entregar al menos 100-200 FPS (y más a menudo a 60), y ejecutar un simulador de red neuronal en lotes paralelos produce fácilmente 2000-10000 FPS en calidad comparable. Es cierto que en horizontes pequeños de 10 a 100 pasos, pero para el aprendizaje por refuerzo esto suele ser suficiente.
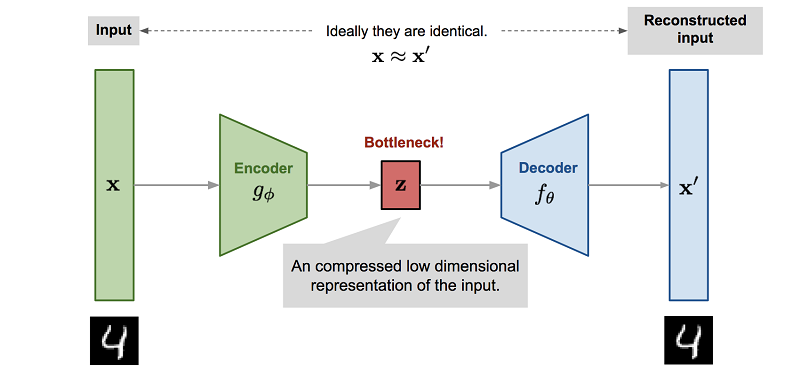
Pero lo que es más importante, el proceso de entrenamiento de una red neuronal para imitar un motor de física generalmente implica una reducción de dimensionalidad. Dado que la forma más fácil de entrenar una red neuronal de este tipo es usar un codificador automático, donde ocurre automáticamente.
, , . , . - , , , , Z.
Z Reinforcement Learning. , , ( , , ). , .
, — , , . . , Z , model-based , , .
, Reinforcement Learning. "" : , , , .
World Models
( ), 2018 World Models.
: - "" , Z. ( ).
VAE:
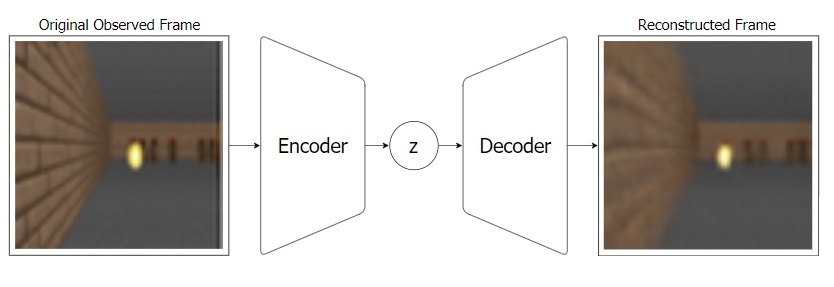
, VAE ( MDN-RNN), . VAE , . , RNN Z . .
:

, : VAE(V) Z MDN-RNN(M) . Z, . MDN-RNN , Z , .
, "" ( - MDN-RNN), . ( ), .
, "" (. ) MDN-RNN (Controller — "", ). , , environment. , C , . VAE(V).
Controller ©, ? ! , -"", Controller. , . , CMA-ES. , Z , . . , , , .
, , .
PlaNet
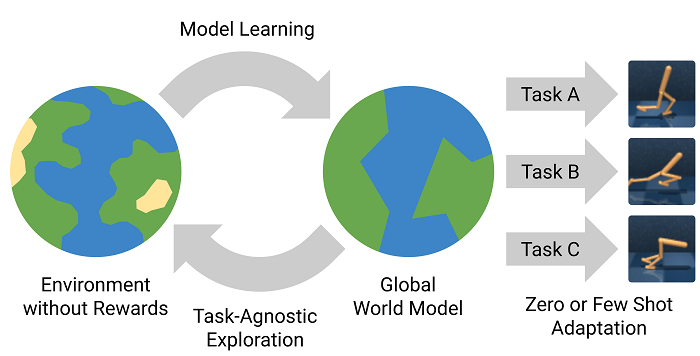
PlaNet. (, , Controller reinforcement learning), PlaNet Model-Based .
, Model-Based RL — . . , . , , RL , .
Model-Based , , , . (CEM PDDM).
- , ! , .
, . , . .
, . . . (.. state, Reinforcement Learning) , , . Model-Based .
PlaNet, World Models , , Z ( S — state).

Z (, S) , , . , - .
S (, Z) . , , . , .
S , . Model-Based ( ""). .
, , .. -"", A. Model-Based — . , state S . R , state S , ( ). , , ! ( ). Model-Based , .. , , , S R. , World Models, .
Model-Based , PlaNet . 50 . , , , , Model-Free .

Model-Based , (-), . , . . , Model-Based, PlaNet . ( ), .
Dreamer
PlaNet Dreamer. .
PlaNet, Dreamer S, , . Dreamer Value , . Reinforcement Learning. . , . Model-Based ( PlaNet) .

, , Dreamer Actor , . Model-Free , actor-critic.
actor-critic Model-Free , actor , critic ( value, advantage), Dreamer actor . Model-Free .
Dreamer' , . Actor , (. ). Value , , value reward .

, Dreamer Model-Based . Model-Free. model-based ( , ) Actor . Dreamer . , PlaNet Model-Based .
, Dreamer 20 , , Model-Free . , Dreamer 20 , ( ) .

Dreamer Reinforcement Learning . MuJoCo, , .
Plan2Explore
. Reinforcement Learning , .
, - , . , - , , . , , ! Plan2Explore .
Reinforcement Learning , , . , .
, . . , -, . -, , - , .
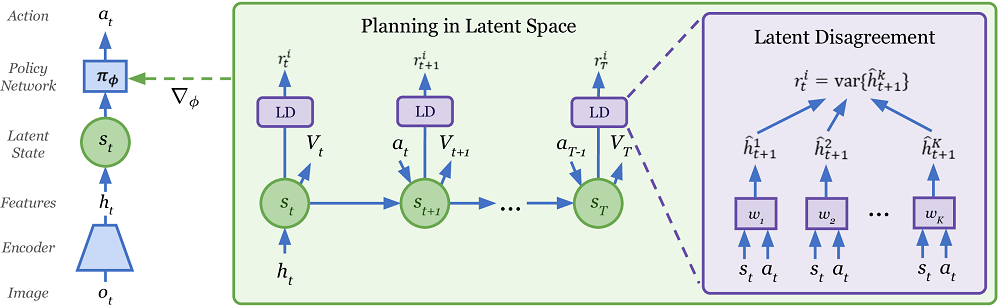
, . , , Plan2Explore , . , .
Plan2Explore : , . , - , . . . zero-shot . ( , . World Models ), few-shot .
Plan2Explore , Dreamer Model-Free , , . , .
Curiosamente, Plan2Explore utiliza una forma inusual de evaluar la novedad de nuevos lugares mientras explora el mundo. Para ello, se entrena un conjunto de modelos entrenados solo sobre un modelo del mundo y prediciendo solo un paso adelante. Se argumenta que sus predicciones difieren para estados de alta novedad, pero como conjuntos de datos (visitas frecuentes al sitio), sus predicciones comienzan a coincidir incluso en entornos estocásticos aleatorios. Dado que las predicciones de un paso eventualmente convergen a algunos valores medios en este entorno estocástico. Si no ha entendido nada, entonces no está solo. Allí en el artículo no está muy claro cómo se describe. Pero de alguna manera parece funcionar.