- Empezaré por la procedencia de los cines online.

En el transcurso del desarrollo de Internet, aparecieron los servicios de medios OTT, que comenzaron a utilizarse para transferir contenido de medios a través de Internet, a diferencia de los servicios de medios tradicionales, donde se utilizaba el cable, satélite y otros canales de comunicación.
Dichos servicios de medios se basan en OVP, una plataforma de video en línea, que incluye un sistema de administración de contenido, un reproductor web y un CDN. Una clase separada de dichos sistemas es OTT-TV, un cine en línea que, además de OVP, implementa sistemas de control y gestión para el acceso al contenido, un sistema de protección de derechos de contenido digital, gestión de suscripciones, compras y diversas métricas técnicas y de productos. E impone a estos sistemas mayores requisitos de tiempo de actividad y latencia.
Hablaré del backend, que se encarga del sistema de gestión de contenidos, de la funcionalidad de usuario del cine online y de la parte del sistema de gestión y control de contenidos.
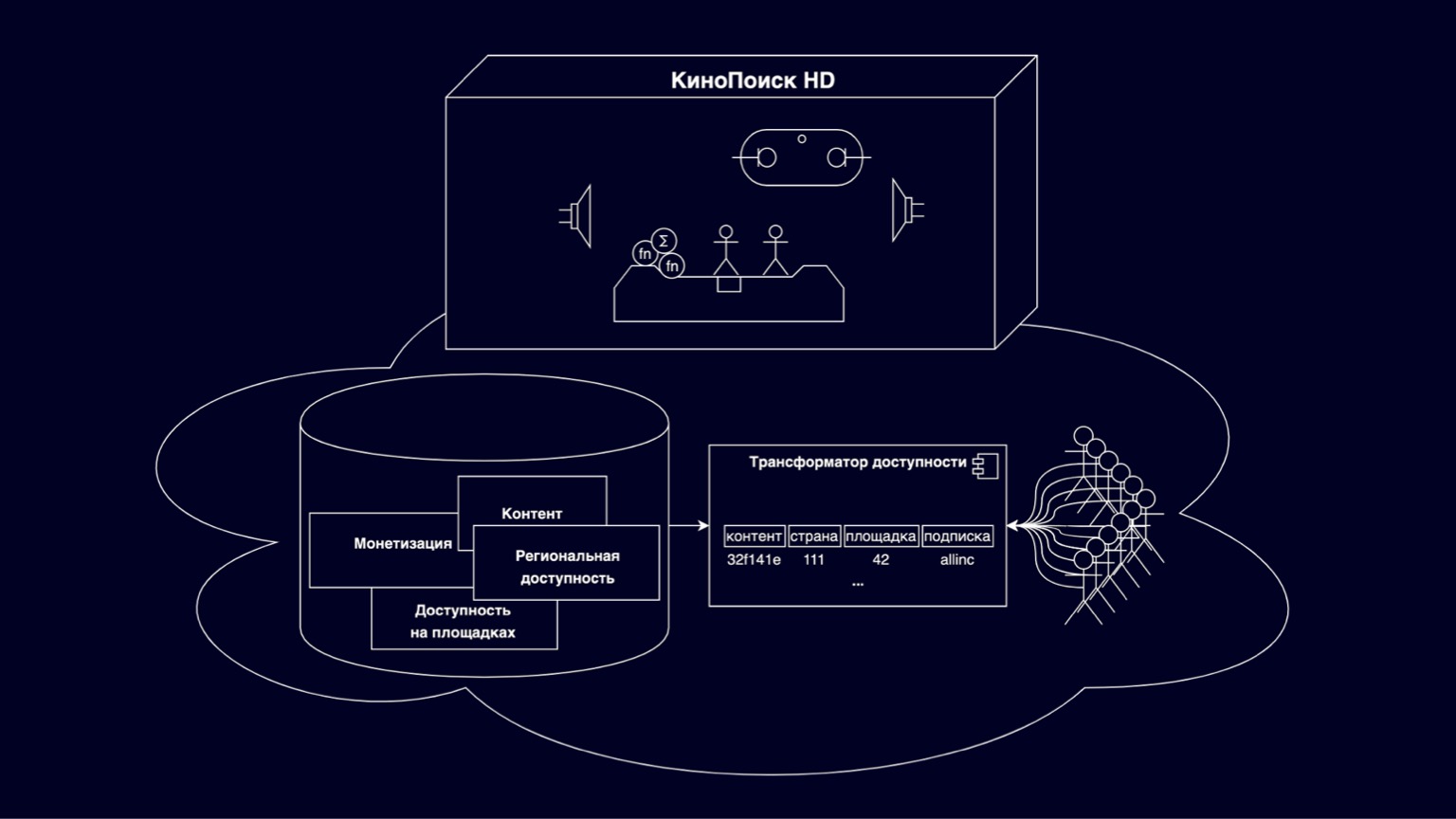
Veamos de qué están hechos los cines online. En el paralelepípedo KinoPoisk HD, se implementan todo tipo de cosas interesantes y modos de visualización. Miles de usuarios de RPS seleccionan el contenido disponible en las tiendas, se suscriben y compran. Guarde el progreso de la navegación, la configuración del usuario. Miles de RPS generan varias métricas. Este es un conjunto de componentes bastante grande e interesante, cuyos detalles no entraremos hoy. Pero vale la pena mencionar que, en general, estos son servicios buenos y comprensiblemente escalables, debido al hecho de que los usuarios los fragmentan.
Hoy nos centraremos en la nube debajo de la caja. Esta es una plataforma responsable de almacenar películas, series, diversas restricciones de los titulares de derechos de autor. Apoyado por los esfuerzos de varios departamentos. Parte de esta plataforma es un transformador de accesibilidad que responde preguntas que puedo ver ahora mismo en esta ubicación. Sin un transformador de accesibilidad, ningún contenido aparecerá literalmente en KinoPoisk HD.
El desafío para el transformador es traducir un modelo de accesibilidad flexible y en capas en un modelo eficiente que se adapte bien a tantos consumidores de contenido como sea posible.
¿Por qué es flexible y escalable?? Principalmente porque incluye varias entidades que describen contenido, monetización, disponibilidad relacional y disponibilidad en sitios. Todo esto está en relaciones revolucionarias, tiene una jerarquía compleja. Y esta flexibilidad es necesaria para cumplir con los requisitos de decenas de titulares de derechos de autor y varias opciones de precios flexibles.
Por sitios, nos referimos, por ejemplo, a un cine en línea en la web, un cine en línea en dispositivos y otros servicios OTT asociados que también reproducen nuestro contenido.
Está claro que para calcular de forma eficaz la disponibilidad de un modelo de varios niveles de este tipo, es necesario crear uniones complejas, y tales consultas no se escalan para ninguna carga, son lo suficientemente difíciles de interpretar para construir alguna funcionalidad en ellas de forma rápida y clara. Para resolver estos problemas, surgió un transformador de accesibilidad, desnormalizando el modelo presentado en la diapositiva como una clave compuesta, que incluye ID de contenido, países, sitios, suscripciones y algún residuo invisible no clave que constituye la mayor parte de la memoria. Hoy hablaremos de las dificultades de escalar el transformador de accesibilidad.
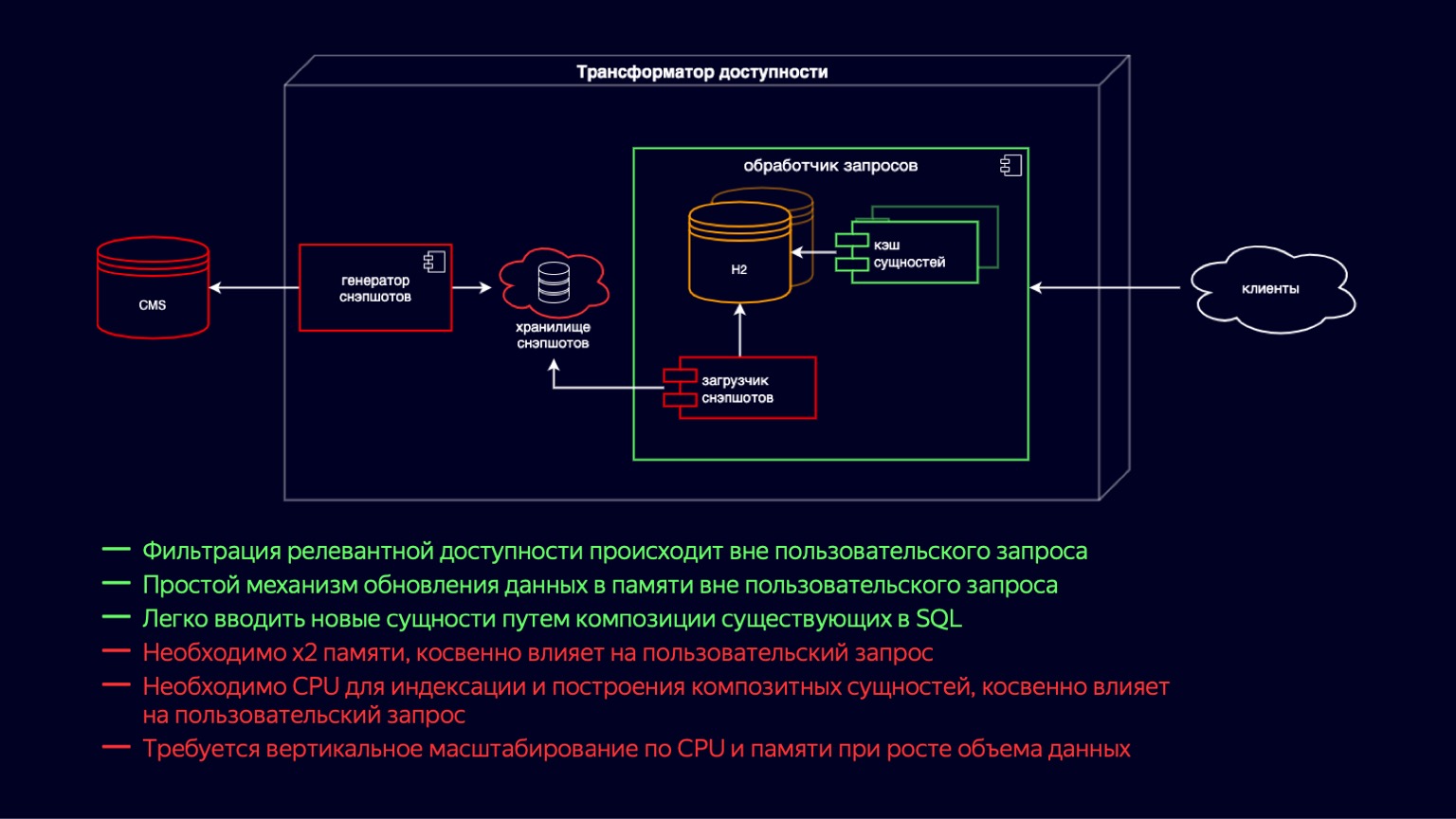
Profundicemos en este componente y veamos en qué consiste. Aquí vemos el estado del sistema justo antes del inicio del problema. Durante todo este tiempo, el transformador de accesibilidad se ha movido por el camino del desarrollo ultrarrápido del cine en línea. Era importante lanzar rápidamente nuevas funciones, en primer lugar, para garantizar la disponibilidad de decenas de miles de películas y series de televisión.
Si va de izquierda a derecha, entonces hay un CMS, una base de datos relacional en la que en tercera forma normal y en EAVnuestras principales entidades se almacenan. El siguiente es el cargador de instantáneas. Además, el generador de instantáneas, que recibe regularmente datos relevantes, los filtra y los agrega al almacenamiento de instantáneas. En realidad, se trata de un volcado de SQL. Más adentro de la instancia del procesador de solicitudes, Snapshot Loader recibe regularmente nuevos datos y los importa a H2. H2 es una base de datos en memoria escrita en Java que implementa las capacidades básicas de un DBMS, es decir, hay un intérprete de consultas, un optimizador de consultas e índices.
De hecho, este es exactamente el componente que brinda la flexibilidad para crear nuevas funciones para un cine en línea debido al hecho de que simplemente puede escribir consultas SQL y unir entidades desnormalizadas de manera rápida y sencilla.
H2 se actualiza en un modelo de copia en escritura. El cargador de instantáneas toma una nueva instancia de base de datos y la llena. Y luego, después de llenar, desecha el viejo usando el recolector de basura.
Simultáneamente con H2, se eleva la caché de entidades, que incluye entidades compuestas y un índice por encima de ellas. Las entidades compuestas son esencialmente una continuación de la desnormalización de lo que se encuentra en H2 para adaptarse a las solicitudes de latencia más exigentes de los clientes. Las entidades de caché se actualizan de la misma manera según el modelo de copia en escritura, simultáneamente con la generación de nuevas instancias H2.
Las principales ventajas del sistema: puede agregar nuevas funciones de manera fácil y flexible mediante combinaciones. Un esquema relativamente simple para actualizar datos mediante copia en escritura. La desventaja es, por supuesto, que se necesitan x2 de memoria para almacenar y actualizar estas entidades. Esto afecta indirectamente a la solicitud del usuario, ya que el recolector de basura la elimina.
Además, al crear la caché de la entidad, se requiere un recurso de CPU para la indexación. Y esto también afecta indirectamente la solicitud del usuario, pero a expensas de la competencia por los recursos de la CPU. Ambos puntos juntos conducen al hecho de que con el crecimiento del volumen de datos de nuestras entidades principales, el procesador de consultas necesita escalar verticalmente, tanto en términos de CPU como de memoria.
Pero el sistema se basó en decenas de miles de películas y series de televisión disponibles en línea. Por lo tanto, durante mucho tiempo, estas desventajas fueron aceptables, permitieron explotar la principal ventaja en términos de flexibilidad y facilidad para introducir nuevas funciones de un cine en línea.
Está claro que todo esto funcionó hasta cierto punto. Imagina que este autobús amarillo es nuestro transformador de accesibilidad.

Alberga películas y seriales reproducidos por desnormalización, es decir, hay decenas de miles de ellos. Y en una de las paradas, es necesario subir a bordo cientos de miles de videos musicales y tráileres y colocarlos de alguna manera. Una vez a bordo, también se multiplicarán debido a la desnormalización. Los que están adentro necesitan encogerse, y los que están afuera necesitan saltar adentro, pasar. Puedes imaginar cómo sucede esto. Técnicamente, en este momento, nuestra capacidad de memoria en la instancia creció a decenas de gigabytes. La creación de la caché y la eliminación de instancias antiguas mediante el recolector de basura requirió varios núcleos virtuales. Y dado que la cantidad de datos ha aumentado drásticamente, todo este procedimiento ha llevado al hecho de que la publicación de contenido nuevo lleva decenas de minutos.
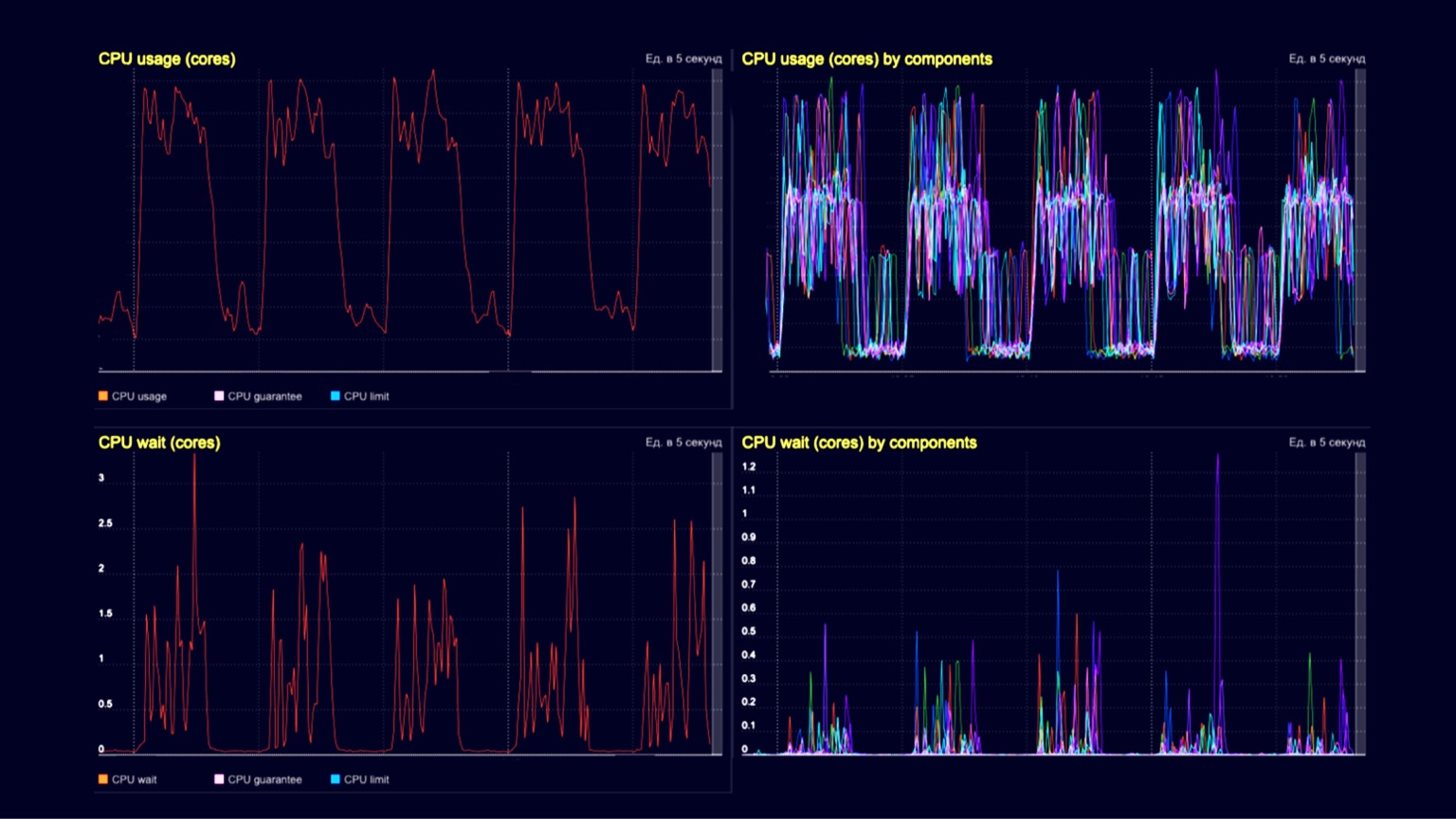
Técnicamente, estamos viendo la utilización de la CPU aquí en un clúster de procesadores de consultas. En las depresiones - procesamiento de solicitudes de clientes del orden de varios miles de RPS, y en las colinas - los mismos varios miles de RPS, más la misma carga de instantáneas y su eliminación mediante un recolector de basura. Los dos gráficos inferiores son la espera de la CPU en el contenedor. Vemos que también comienzan a manifestarse en el momento de descargar las instantáneas y su disposición.
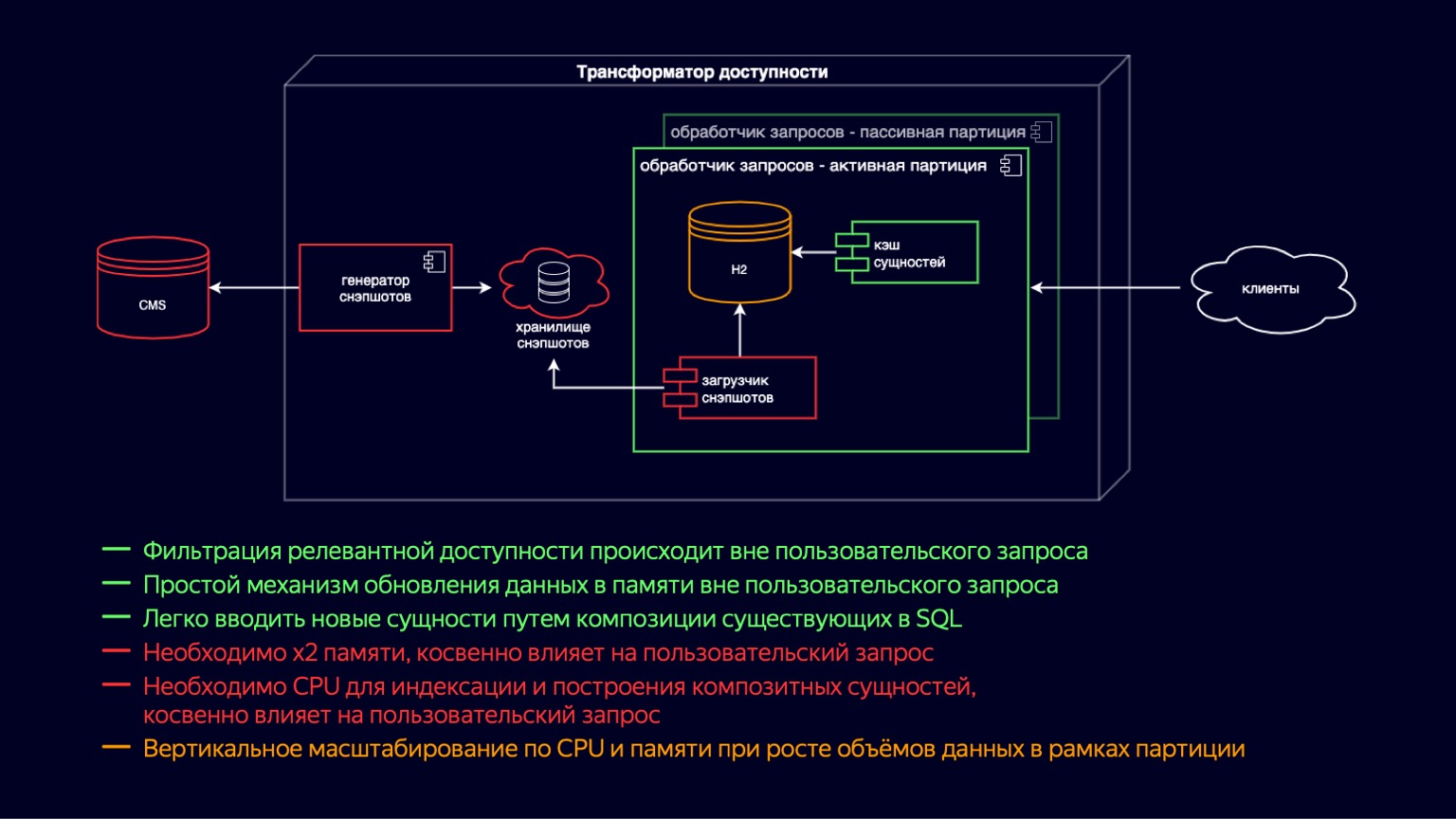
Para acomodar estos videos musicales y avances y continuar escalando, presentamos instancias de procesador de solicitudes activas y pasivas. De hecho, se trata de una transferencia de copia en escritura hasta un nivel. Ahora tenemos instancias activas y pasivas en el contenedor. El pasivo prepara el nuevo H2 y la caché de entidades, mientras que el activo simplemente procesa las solicitudes de los usuarios. Por lo tanto, hemos reducido el impacto de la recolección de basura y sus pausas en el procesamiento de las solicitudes de los usuarios. Pero al mismo tiempo, dado que todavía viven en el mismo contenedor, la carga de instantáneas y la creación de caché aún compiten por los recursos de la CPU, y el impacto en las solicitudes de los usuarios sigue ahí.
Además, hemos introducido la partición por sitio. Esto nos proporcionó una reducción de la memoria en aquellos sitios donde no se necesitan todos estos nuevos tipos de contenido. Por ejemplo, esto permitió que una sala de cine en línea no descargara videos musicales y avances, y redujera el impacto. Pero al mismo tiempo, para los sitios que necesitan proporcionar accesibilidad a todo el contenido, por supuesto, nada ha cambiado.
Por lo tanto, los pros y los contras del esquema siguieron siendo los mismos que antes. Pero debido al particionamiento, el escalado vertical en términos de CPU y memoria se movió a los sitios, y esto permitió que algunos sitios continuaran escalando. En comparación con el esquema de publicación de contenido anterior, esto no ha cambiado de ninguna manera. En general, tomó las mismas decenas de minutos, por lo que seguimos buscando formas de optimizarlo.

¿Qué entendimos en ese momento? Que las consultas de cine en línea utilizan una pequeña parte de las capacidades de DBMS. El intérprete y optimizador de consultas ha degenerado con el tiempo en una caché de entidad. Nos dimos cuenta de que la definición de accesibilidad es ampliamente universal. Las consultas se diferencian en que debe comprender la disponibilidad de una unidad de contenido o lista y agregar atributos adicionales a esta disponibilidad. En general, esto se puede hacer sin un DBMS completo.
Y en segundo lugar, una parte de la clave compuesta son los parámetros cardinales bajos. Hay docenas de países, en el límite de un par de cientos, docenas de sitios y solo unas pocas suscripciones. Lo más probable es que no se requiera una desnormalización completa. Ambos hallazgos nos han llevado a avanzar hacia una representación en memoria más compacta y menos desnormalizada, pero que aún responde rápidamente a las solicitudes de los usuarios.

En la diapositiva, vemos la transición del transformador de disponibilidad v1 a v2. Aquí hay un esquema de un nuevo esquema de accesibilidad, donde la clave compuesta en realidad se reduce a ser una clave de ID de contenido. Y la accesibilidad, física o lógicamente, se reduce a determinar la disponibilidad mediante listas de países, sitios y suscripciones.
Por lo tanto, reducimos la cantidad de resto invisible que no es clave, que constituye la mayor parte de la memoria, y al mismo tiempo reducimos la cantidad de memoria.
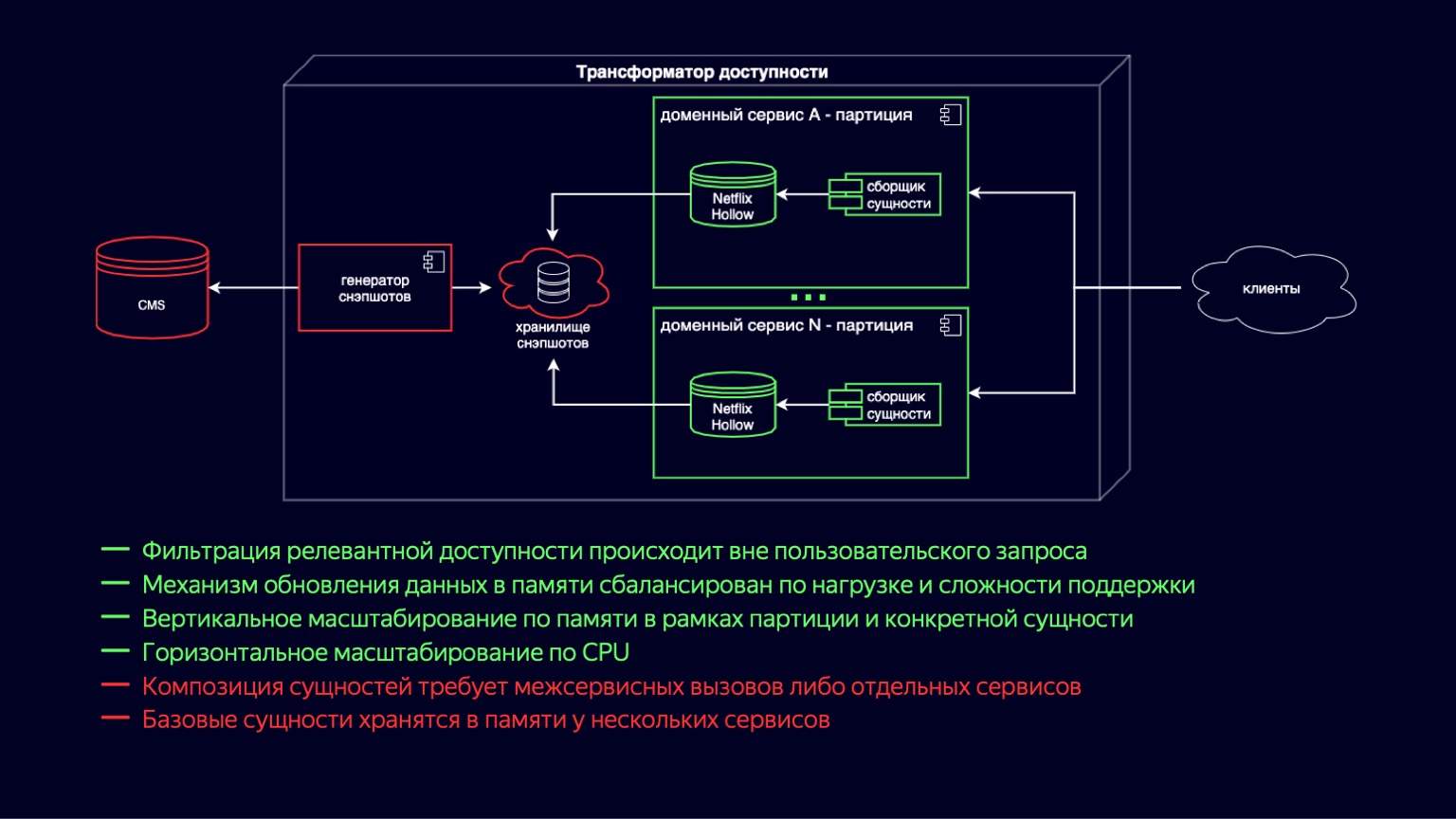
Aquí vemos el proceso de transición al nuevo circuito transformador de accesibilidad. Netflix Hollow desempeña el papel de proveedor e indexador de entidades básicas, sobre las cuales los servicios de dominio recopilan sobre la marcha un conjunto de entidades compuestas de varios tamaños. Esto funciona porque las entidades subyacentes todavía están desnormalizadas y el número de uniones es mínimo durante la construcción. Por otro lado, determinar la disponibilidad se reduce a ciclos simples y económicos y no debería ser difícil.
Al mismo tiempo, Netflix Hollow almacena y trata con bastante cuidado la carga en la CPU y la recolección de basura, tanto durante la actualización de datos como durante el acceso a ellos. Esto nos permite reducir las colinas que vimos en los gráficos de utilización de la CPU y mantenerlas en un mínimo aceptable. Además, dado que implementa un esquema de entrega híbrido en forma de instantáneas y se diferencia de ellas, puede aumentar la velocidad de publicación de contenido nuevo en unos pocos minutos.
Está claro que se han conservado la mayoría de las ventajas del esquema anterior. El mecanismo para actualizar los datos en la memoria se ha vuelto más simple y económico en términos de utilización de recursos. El escalado vertical por particiones, por sitios también se ha complementado con escalado para una entidad específica, ahora es más económico. Y dado que redujimos la sobrecarga de actualizar las copias instantáneas, hubo una escala verdaderamente horizontal en la CPU.
La desventaja de este esquema es que la composición de la entidad requiere llamadas entre servicios o servicios separados. Y todavía hay duplicación de datos a nivel de entidad base, ya que ahora se almacenan en cada servicio de dominio donde se usa. Pero Netflix Hollow almacena datos de forma más compacta que H2, y H2 los almacena de forma mucho más compacta que HashMap con objetos. Por lo tanto, este signo negativo también se considera aceptable y le permite mirar hacia el futuro con optimismo.

Esta diapositiva es capaz de cargar incluso el agua del grifo con optimismo. Porque escalar a nuevos países ya no es un factor multiplicador de la memoria, ni tampoco lo es escalar a nuevos sitios. Debido a la partición, se convierte a escala horizontal.
Bueno, el escalado de nuevos usuarios y la expansión de la funcionalidad del cine en línea se reduce a un aumento en la carga. Para proporcionarlo, estamos listos para ofrecer tantos servicios livianos vinculados a la CPU como sea necesario. Por otro lado, hemos acumulado suficientes conocimientos en el ámbito de la accesibilidad para afrontar nuevos retos con confianza. Espero haber podido compartir algunos de estos conocimientos con ustedes. Gracias por su atención.