
En este artículo te explicaré:
- qué tipo de bestia es este Airflow, de qué componentes se compone y cómo interactúan entre sí
- sobre las principales entidades de Airflow: pipelines llamados DAG, Operator y algunas cosas más
- cómo tener éxito en el desarrollo de Airflow
- cómo implementamos la generación de pipelines y la llamada "escritura declarativa de pipelines"
- sobre los pros y los contras de usar Airflow
¿Qué es Airflow?
Airflow es una plataforma para crear, monitorear y orquestar tuberías. Este proyecto de código abierto, escrito en Python, fue creado en 2014 en Airbnb. En 2016, Airflow pasó a estar bajo el ala de Apache Software Foundation, pasó por una incubadora y, a principios de 2019, se convirtió en un proyecto Apache de primer nivel.
En el mundo del procesamiento de datos, algunos lo llaman herramienta ETL, pero esto no es exactamente ETL en el sentido clásico, como Pentaho, Informatica PowerCenter, Talend y otros similares. Airflow es un orquestador, "cron con pilas": no hace el trabajo pesado de la transferencia y el procesamiento de datos por sí mismo, pero les dice a otros sistemas y marcos qué hacer y monitorea el estado de ejecución. Lo usamos principalmente para ejecutar consultas en trabajos de Hive o Spark.
Revelación
Airflow, worker ( ), . , , .
La gama de tareas resueltas con Airflow no se limita a ejecutar algo en un clúster de Hadoop. Puede ejecutar código Python, ejecutar comandos Bash, alojar contenedores y pods de Docker en Kubernetes, ejecutar consultas en su base de datos favorita y más.
Arquitectura de flujo de aire
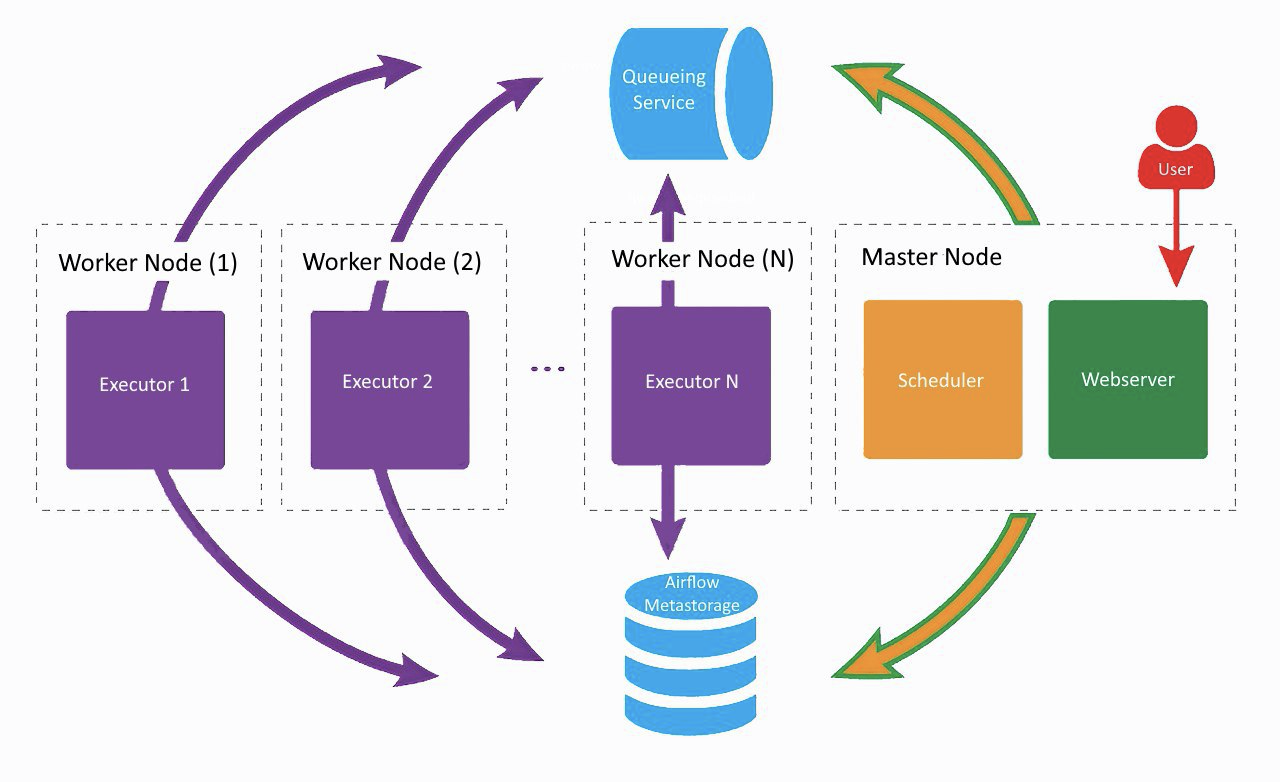
Así es aproximadamente como se ve nuestra configuración actual de Airflow, solo Lamoda usa dos trabajadores. En una máquina separada, el servidor web y el programador están girando, los trabajadores están fumando en los vecinos. Uno fue creado para tareas regulares, el segundo fue adaptado para ejecutar entrenamiento de modelos ML usando Vowpal Wabbit. Todos los componentes se comunican entre sí a través de una cola de tareas y una base de metadatos.
En los albores del desarrollo de Airflow en la empresa, todos los componentes (excepto la base de datos) funcionaban en la misma máquina, pero en algún momento esto provocó una falta de recursos en el servidor y retrasos en el funcionamiento del planificador. Por lo tanto, decidimos distribuir los servicios a diferentes servidores y llegamos a la arquitectura que se muestra en la imagen de arriba.
Componentes de flujo de aire
Webserver
Webserver es una interfaz web que muestra lo que está sucediendo con la canalización. Esta página es
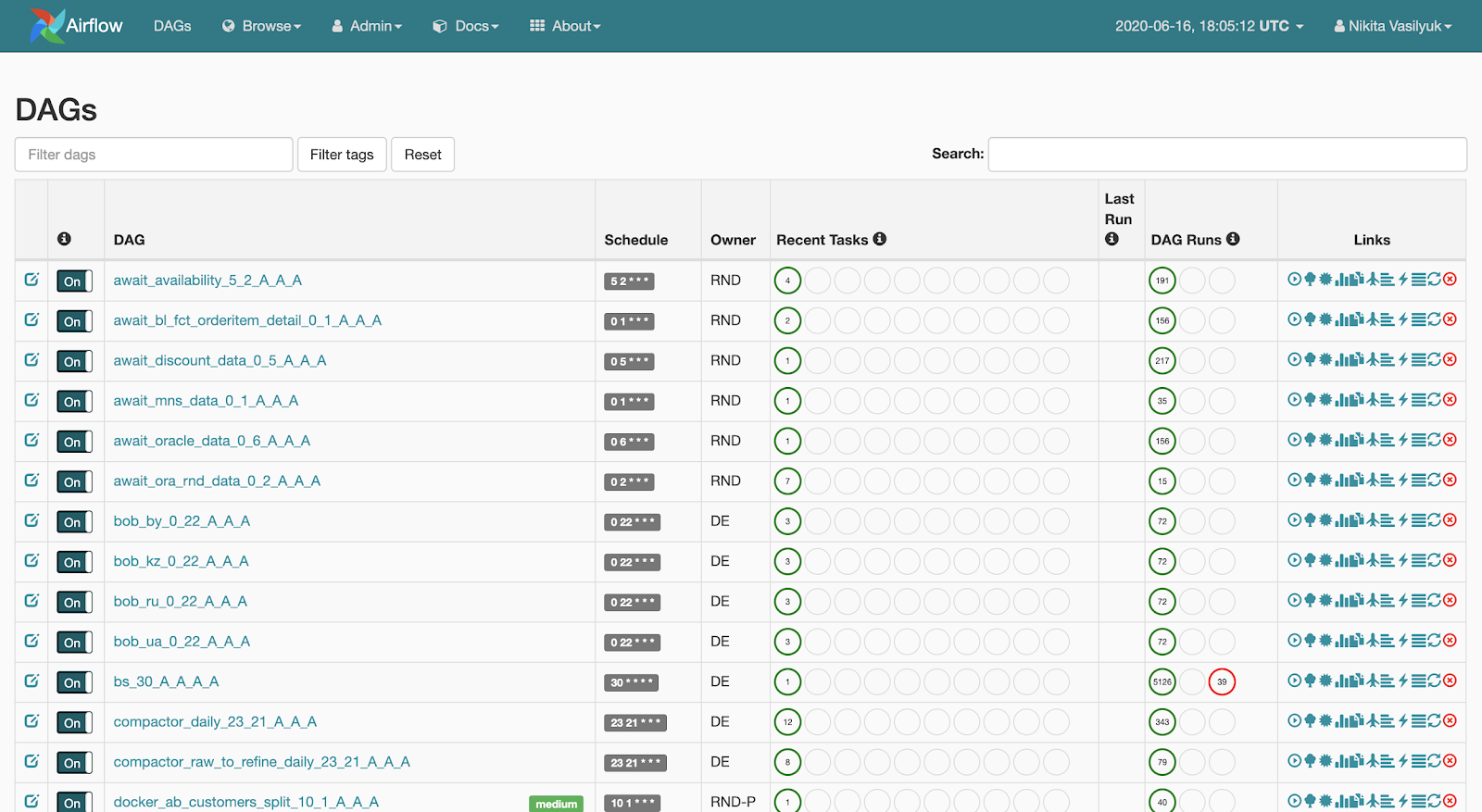
visible para el usuario: el servidor web permite ver la lista de canalizaciones disponibles. Se muestran breves estadísticas de lanzamientos junto a cada canalización. También hay varios botones que lanzan con fuerza el pipeline o muestran información detallada: estadísticas de lanzamiento, el código fuente del pipeline, su visualización en forma de gráfico o tabla, una lista de tareas y el historial de sus lanzamientos.
Si hacemos clic en la tubería, pasaremos por el menú Vista de gráfico. Aquí se muestran las tareas y los vínculos entre ellos.
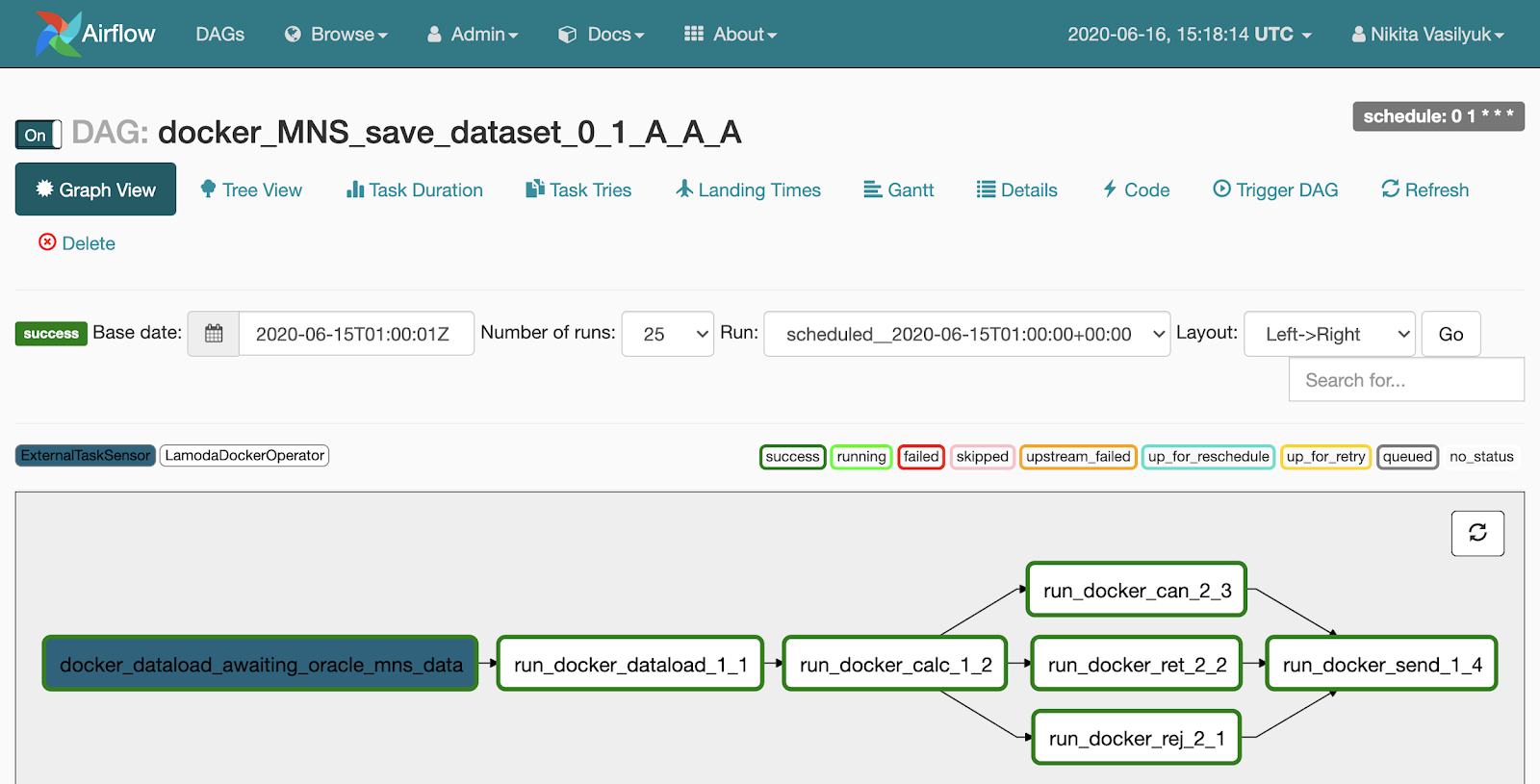
Hay un menú de vista de árbol junto a la vista de gráfico. Fue creado para reiniciar tareas, ver estadísticas y registros. En el lado izquierdo, se muestra una vista de árbol del gráfico, enfrente hay una tabla con el historial de inicio de la tarea.
Cada línea de esta tabla aterradora es una tarea, cada columna es un comienzo de la tubería. En su intersección hay una plaza con el lanzamiento de una tarea específica para una fecha determinada. Si hace clic en él, aparece un menú donde puede ver información detallada y registros de esta tarea, iniciarla o reiniciarla, y también marcarla como exitosa o no exitosa.

Programador: como su nombre lo indica, lanza canalizaciones cuando llega su momento. Es un proceso de Python que periódicamente va al directorio con canalizaciones, extrae su estado actual desde allí, verifica el estado y lo inicia. En general, Scheduler es el más interesante y al mismo tiempo el cuello de botella en la arquitectura Airflow.
- La primera advertencia es que solo se puede ejecutar una instancia de Scheduler a la vez. Esto significa que el modo de alta disponibilidad no es posible actualmente (los desarrolladores planean agregar Scheduler HA a Airflow versión 2.0).
- : , - . , - , .
Hasta algún tiempo, el retraso se ajusta mediante los parámetros del archivo de configuración de Airflow, pero el retraso de inicio aún permanece. De esto se deduce que Airflow no se trata de procesamiento de datos en tiempo real. Si actúa sin darse cuenta y especifica un intervalo de lanzamiento demasiado frecuente (una vez cada dos minutos), puede lograr un retraso en su canalización. La experiencia muestra que una vez cada 5 minutos ya es bastante frecuente, y algunos no recomiendan ejecutar la canalización cada 10 minutos. Tenemos un par de pipelines que arrancan cada 10 minutos, son bastante simples y no han tenido ningún problema con ellos hasta ahora.
Worker
Worker es donde se ejecuta nuestro código y se realizan las tareas. Airflow admite varios ejecutores:
- El primero, el más simple, es el SequentialExecutor. Lanza de forma secuencial las tareas entrantes y pausa el programador mientras dure su ejecución.
- LocalExecutor , , LocalExecutor . : - SQLite, LocalExecutor SequentialExecutor.
- CeleryExecutor , . Celery – , RabbitMQ Redis. , .
- DaskExecutor Dask – .
- KubernetesExecutor pod Kubernetes.
- DebugExecutor IDE.
Entidades de Apache Airflow
Pipeline, o DAG
La esencia más importante de Airflow es el DAG, también conocido como pipeline, también conocido como gráfico acíclico dirigido. Para que quede más claro cómo cocinarlo y por qué lo necesitas, analizaré un pequeño ejemplo.
Digamos que un analista vino a nosotros y nos pidió que completáramos datos en una tabla determinada una vez al día. Él preparó toda la información: qué obtener de dónde, cuándo comenzar, con qué SLA. A continuación, se muestra un ejemplo de cómo podríamos describir nuestra canalización.
dag = DAG(
dag_id="load_some_data",
schedule_interval="0 1 * * *",
default_args={
"start_date": datetime(2020, 4, 20),
"owner": "DE",
"depends_on_past": False,
"sla": timedelta(minutes=45),
"email": "<your_email_here>",
"email_on_failure": True,
"retries": 2,
"retry_delay": timedelta(minutes=5)
}
)
Dag_id contiene el nombre exclusivo de la canalización. A continuación, usamos schedule_interval para especificar la frecuencia con la que debe ejecutarse.
Punto muy importante: dado que Airflow fue desarrollado por una empresa internacional, solo funciona en UTC. Por el momento, no hay una forma sensata de hacer que Airflow funcione en una zona horaria diferente, por lo que debe recordar constantemente la diferencia entre nuestra zona horaria y UTC. En la versión 1.10.10, fue posible cambiar la zona horaria en la interfaz de usuario, pero esto solo se aplica a la interfaz web, las canalizaciones aún se ejecutarán en UTC.
El parámetro default_args es un diccionario que describe los argumentos predeterminados para todas las tareas dentro de esta canalización. Los nombres de la mayoría de los parámetros se describen a sí mismos bien, no me detendré en ellos.
Operador
Un operador es una clase de Python que describe qué acciones deben realizarse dentro de nuestra tarea diaria para deleitar al analista.
Podemos usar HiveOperator, que, curiosamente, está diseñado para enviar solicitudes de ejecución a Hive. Para iniciar el operador, debe especificar el nombre de la tarea, la canalización, el ID de la conexión a Hive y la solicitud que se está ejecutando.
run_sql = HiveOperator(
dag=dag,
task_id="run_sql",
hive_cli_conn_id="hive",
hql="""
INSERT OVERWRITE TABLE some_table
SELECT * FROM other_table t1
JOIN another_table t2 on ...
WHERE other_table.dt = '{{ ds }}'
"""
)
notify = SlackAPIPostOperator(
dag=dag,
task_id="notify_slack",
slack_conn_id="slack",
token=token,
channel="airflow_alerts",
text="Guys, I'm done for {{ ds }}"
)
run_sql >> notify
Hay una parte de la plantilla Jinja en la solicitud que pasamos al constructor del operador. Jinja es una biblioteca de plantillas de Python.
Cada lanzamiento de canalización almacena información sobre la fecha de lanzamiento. Se encuentra en una variable llamada fecha_ejecución. {{ds}} es una macro que solo tomará la fecha en el formato% Y-% m-% d en ejecución_fecha. En un momento determinado antes de iniciar el operador, Airflow generará una cadena de consulta, sustituirá la fecha requerida allí y enviará una solicitud de ejecución.
ds no es la única macro, hay unas 20 de ellas (una lista de todas las macros disponibles) . Incluyen diferentes formatos de fecha y un par de funciones para trabajar con fechas: sumar o restar días.
Cuando me familiaricé con Airflow, no entendí por qué se necesitan todo tipo de macros, cuando puedes simplemente insertar una llamada datetime.now () allí y disfrutar de la vida. Pero en algunos casos, esto puede arruinarnos la vida tanto a nosotros como al analista. Por ejemplo, si queremos recalcular algo para alguna fecha en el pasado, Airflow reemplazará allí no la fecha en que se lanzó la tubería, sino el tiempo de ejecución real. Y en algunos casos, es posible que no obtengamos lo que esperamos.
Por ejemplo, si queremos reiniciar la canalización para el martes pasado, cuando use datetime.now (), en realidad recalcularemos la canalización para hoy, y no para la fecha requerida. Además, es posible que los datos de hoy ni siquiera estén listos en este momento.
Después de completar con éxito la solicitud, podemos enviar una notificación a Slack sobre la carga de datos. A continuación, ordenamos Airflow, en qué orden comenzar las tareas. Gracias a la sobrecarga del operador en Airflow, utilizo fácilmente el operador >> para especificar el orden de los pasos en la tubería. En mi ejemplo, decimos que primero comenzaremos a ejecutar la solicitud y luego enviaremos una notificación a Slack.
Idempotencia
Es imposible hablar de Airflow sin mencionar la idempotencia. Por si acaso, déjame recordarte: la idempotencia es una propiedad de un objeto, cuando vuelves a aplicar una operación a un objeto, siempre devuelve el mismo resultado.
En el contexto de Airflow, esto significa que si hoy es viernes y reiniciamos la tarea el martes pasado, la tarea comenzará como si fuera el martes pasado, y nada más. Es decir, el lanzamiento o reinicio de una tarea para alguna fecha en el pasado no debería depender de ninguna manera de cuándo se lanzó realmente esta tarea. La idempotencia se implementa utilizando la variable execution_date mencionada anteriormente.
Airflow fue desarrollado como una herramienta para resolver tareas de procesamiento de datos. En este mundo, generalmente procesamos una gran cantidad de datos solo cuando están listos, es decir, al día siguiente. Y los creadores de Airflow originalmente establecieron ese concepto en sus productos.
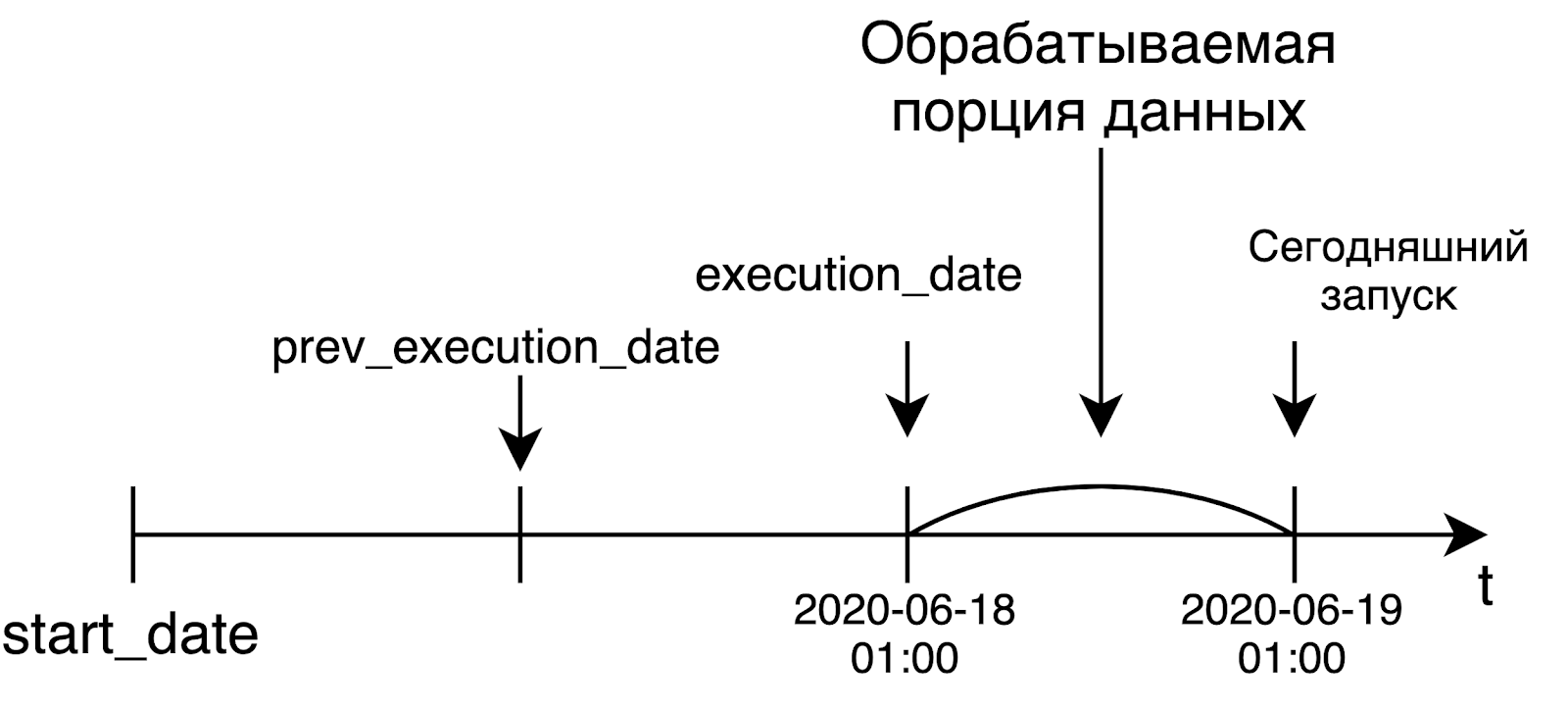
Cuando lancemos una canalización diaria, lo más probable es que queramos procesar datos de ayer. Es por eso que la fecha de ejecución será igual al borde izquierdo del intervalo para el que procesamos los datos. Por ejemplo, el lanzamiento de hoy, que comenzó a la 1 am UTC, recibirá la fecha de ayer como ejecución_fecha. En el caso de una canalización por horas, la situación es la misma: para iniciar la canalización a las 6 a. M., El tiempo en la fecha de ejecución será igual a las 5 a. M. Esta idea no es muy obvia al principio, pero sin embargo, es muy significativa e importante.
Operadores de flujo de aire más comunes
En Airflow, no solo hay operadores que van a Hive y envían algo a holgura. De hecho, hay toneladas de operadores por ahí. En el artículo, destaqué los más populares y útiles.
- BashOpetator y PythonOperator. Todo está claro con ellos: envían un comando bash y una función de python para su ejecución, respectivamente.
- Existe una gran variedad de operadores para enviar consultas a varias bases de datos. Se admiten Postgres estándar, MySQL, Oracle, Hive, Presto. Si por alguna razón no hay un operador para su base de datos favorita, puede usar un JdbcOperator más general o escribir el suyo propio, Airflow lo permite.
- Sensor – , . , - . , , . , : 3 , . . , , .
- BranchPythonOperator – , , python , , .
- DockerOpetator Docker- . , Docker- , . , .
- KubernetesPodOperator pod Kubernetes.
- DummyOperator , .
Lamoda
- – LamodaDockerOperator. , : - Hadoop, . LamodaDockerOperator Spark- , python.
- LamodaHiveperator – , . Hive. , - , , . , , HiveCliHook HiveServer2Hook, .
- – ExternalTaskSensor. . , Hadoop . , , , - , , . , - HDFS, Airflow.
- BashOperator, PythonOperator – , bash- python .
- , . - , .
Airflow
- Variables – , , , . , . , Hive, HDFS, . dev- prod-, .
- Connections – , . Airflow : http ftp, .
- Hooks – , .
- SLA -. , . SLA , , - - . - : - , Airflow .
- – XCom, cross-communication. : , json-. – 48 .
- – , . , . , 5, , , , .

Además, puede ver cómo cambió la duración de las tareas durante el día. En nuestro caso, este es el proceso de transferencia de datos de Kafka a Hive con verificación de la calidad de los datos. Además, puede rastrear cuándo la tarea, por alguna razón, tomó más tiempo de lo habitual.

Cómo tener éxito en el desarrollo del flujo de aire
A continuación se ofrecen algunos consejos que le ayudarán a evitar recibir un disparo en el pie cuando utilice Airflow:
- Es útil mantener cada canalización (o generador de canalizaciones, más sobre eso a continuación) en un archivo separado. Inmediatamente sé a qué archivo debo ir para ver la canalización o el generador requeridos.
- , , . , -, . , - , . : , , .
- – schedule_interval start_date dag_id. , Airflow , - -. DAGS , Scheduler, . , , dag_id. , .
- catchup. True, Airflow , start_date . , . False Airflow . , Airflow True ( -).
- – . , python , airflow DAG, , DAG. . , , . REST API, requests.get() .
:
Desde el comienzo de usar Airflow, hemos mantenido las configuraciones de canalización separadas del código. Inicialmente, esto se debió a las peculiaridades del esquema de implementación, pero gradualmente este enfoque se arraigó. Y ahora usamos configs siempre que haya un indicio de repetición. Esto se refiere especialmente a los trabajos de Spark que ejecutamos desde Docker. De ahí surgió la historia con la escritura declarativa de pipelines.
El enfoque es que tenemos un directorio con configs. Cada archivo de configuración contiene una o varias canalizaciones con su descripción: cómo deben funcionar, cuándo comenzar, qué tareas hay en él y en qué orden deben realizarse.
Mostraré cómo se ve el código para llamar a nuestro generador de canalizaciones. En la entrada recibe un directorio con configs, un prefijo y una clase que se encargará de llenar el pipeline de tareas. Bajo el capó, el generador va al directorio especificado, encuentra los archivos de configuración allí, crea tareas en estos archivos para cada canalización y los conecta.
from libs.dag_from_config.dag_generator import DagGenerator
from libs.runners.docker_runner import DockerRunner
generator = DagGenerator(config_dir='dag_configs/docker_runner', prefix='docker')
dags = generator.generate(task_runner=DockerRunner)
for dag in dags:
globals()[dag.dag_id] = dag #
Así es como se ve un archivo de configuración típico. Para describir las configuraciones, usamos el formato HOCON , que es un superconjunto de JSON. Admite importaciones de otros archivos HOCON y puede hacer referencia a los valores de otras variables.
En la configuración a nivel de canalización (bloque de atribución), puede especificar muchos parámetros, pero los más importantes son el nombre, la fecha de inicio y el intervalo de programación.
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
Aquí puede especificar la simultaneidad: cuántas tareas se ejecutarán simultáneamente en una ejecución. Recientemente, hemos agregado un bloque con una breve descripción de descuento de la canalización aquí. Luego, junto con el resto de la información sobre el pipeline, irá a Confluence (implementamos el envío usando Foliant ). Resultó muy conveniente: de esta manera ahorramos tiempo a los desarrolladores entusiastas para crear páginas en Confluence.
Luego viene la parte que se encarga de la formación de tareas. Primero, en el bloque de conexiones, indicamos de qué conexión en Airflow necesitamos tomar parámetros para conectarnos a una fuente externa; en el ejemplo, este es nuestro DWH.
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
Toda la información necesaria, como usuario, contraseña, URL, etc., se enviará al contenedor de la ventana acoplable como variables de entorno. En el bloque Contenedores indicamos qué tareas lanzaremos. En su interior se encuentra el nombre de la imagen, una lista de conexiones utilizadas y una lista de variables de entorno.
Puede notar que las plantillas de Jinja aparecen en los valores de algunas variables de entorno. Para especificar una cola en YARN, usamos la sintaxis estándar de Airflow para recuperar valores de variables. Para indicar la fecha de lanzamiento, usamos la macro {{ds_nodash}}, que representa la fecha de su ejecución_date sin guiones. La configuración contiene 3 tareas más similares, están ocultas para mayor claridad.
A continuación, utilizando tareas, indicamos cómo se lanzarán estas tareas. Notará que se enumeran como una lista en una lista. Esto significa que las 4 tareas se ejecutarán en paralelo entre sí.
Y una última cosa: especificamos de qué canalizaciones base depende nuestro DAG actual. Los números y letras extraños al final de los nombres de los dags básicos son el programa que incorporamos en el nombre de la tubería. Por lo tanto, nuestra tubería comenzará a llenarse solo después de que se completen los dags básicos y las tareas especificadas en ellos.
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
Texto completo del archivo de configuración
docker_image = "docker_registry/attribution/calculation:1.1.0"
dags {
attribution {
owner = "RND"
name = "attribution"
start_date = "20190601"
emails = [...]
schedule_interval = "0 1 * * *"
depends_on_past = true
concurrency = 4
description = """
- z_log
-
- ,
-
"""
tags = ["critical"]
docker {
connections {
LMD_DWH = "dwh"
}
containers {
desktop {
image = ${docker_image}
connections = [LMD_DWH]
environment {
LMD_YARN_QUEUE = "{{ var.value.YARN_QUEUE }}"
LMD_INSTANCES = 60
LMD_MEMORY_PER_INSTANCE = "4g"
LMD_ZLOG_SOURCE = "z_log_db.z_log"
LMD_ATTRIBUTION_TABLE = "{{ var.value.HIVE_DB_DERIVATIVES }}.z_log_attribution"
LMD_ORDERS_TABLE = "rocket_dwh_bl.fct_orderitem_detail"
LMD_PLATFORMS = "desktop"
LMD_RUN_DATE = "{{ ds_nodash }}"
}
}
mobile {...}
iOS {...}
Android {...}
}
tasks = [[desktop, mobile, iOS, Android]]
}
awaits {
z_log_compaction {
dag = "compactor_daily_23_21_A_A_A"
task = "compact_z_log_db_z_log"
timedelta = 3hr37m
}
oracle_bl_fct_orderitem_detail {
dag = "await_bl_fct_orderitem_detail_0_1_A_A_A"
}
}
}
}
Esto es lo que obtenemos tras generación:
- 2 puntos en el bloque de espera convertidos en dos sensores que esperan la ejecución del pipeline básico,
- Las 4 tareas que especificamos en el bloque docker se convirtieron en 4 tareas en ejecución en paralelo,
- Agregamos un DummyOperator entre los dos bloques de operadores para que no haya una red de conexiones entre tareas.
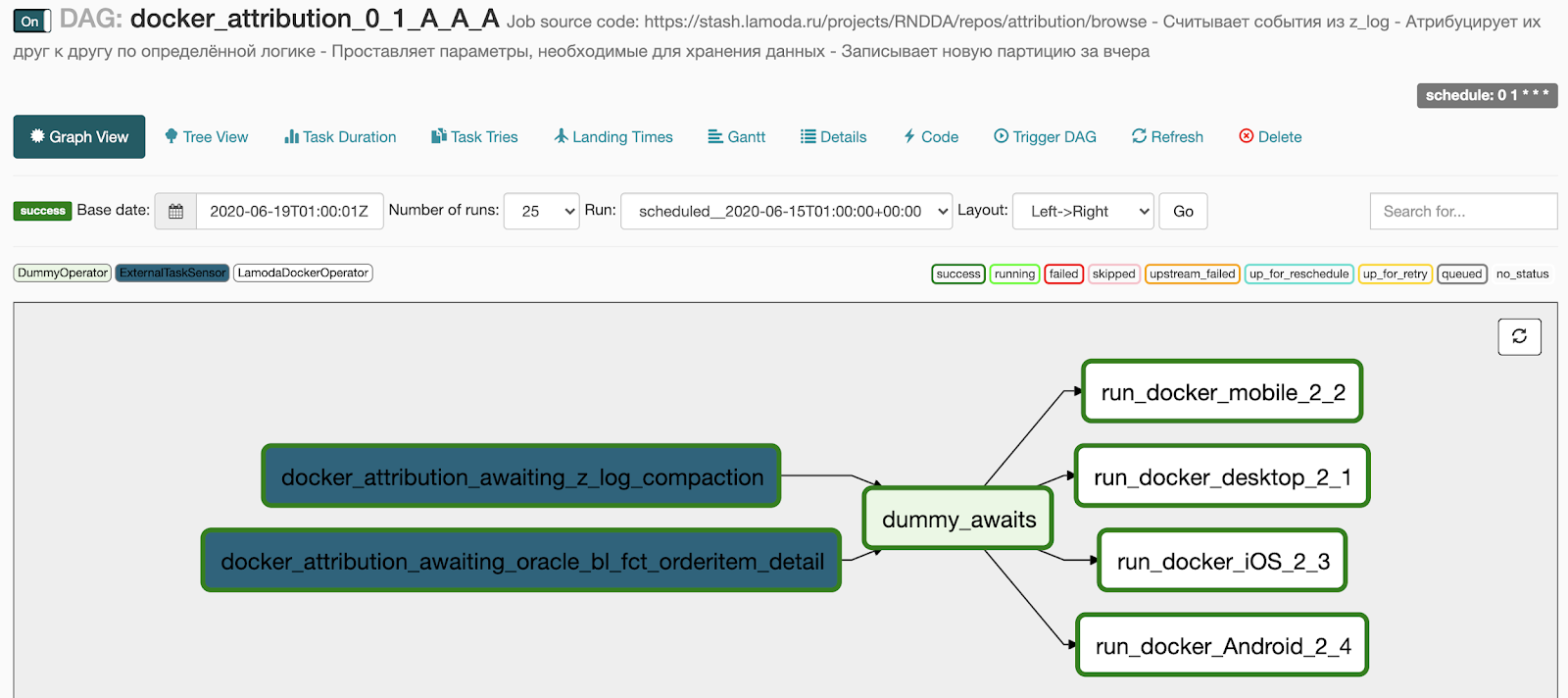
Que queremos hacer a continuación
Primero, cree un entorno de funciones completo. Ahora tenemos un puesto de desarrollo para probar todas nuestras tuberías. Y antes de realizar la prueba, debe asegurarse de que el entorno de desarrollo sea gratuito ahora.
Recientemente, nuestro equipo se ha expandido y ha aumentado el número de solicitantes. Hemos encontrado una solución temporal al problema y ahora avísanos en Slack cuando tomemos dev. Funciona, pero sigue siendo un cuello de botella en el desarrollo y las pruebas.
Una opción es trasladarse a Kubernetes. Por ejemplo, al crear una solicitud de extracción en el maestro, puede generar un espacio de nombres separado en Kubernetes, donde implementar Airflow, implementar el código, luego dispersar variables, conexiones. Después de la implementación, el desarrollador vendrá a la instancia de Airflow recién creada y probará sus canalizaciones. Tenemos algo de trabajo preliminar sobre este tema, pero nuestras manos no llegaron al clúster de combate de Kubernetes, donde pudimos ejecutarlo todo.
La segunda opción para implementar el entorno de funciones es organizar un repositorio con una rama de desarrollo común, donde el código de los desarrolladores se fusiona y se implementa automáticamente en el entorno de desarrollo. Ahora estamos mirando activamente hacia este esquema.
También queremos intentar implementar complementos, cosas para expandir la funcionalidad de la interfaz web. El objetivo principal de la implementación de complementos es crear un diagrama de Gantt a nivel de todo el flujo de aire, es decir, a nivel de todas las tuberías, así como crear un gráfico de dependencia entre diferentes tuberías.
Por qué elegimos Airflow
- En primer lugar, esto es Python, donde con la ayuda de dos bucles y un par de condiciones, puede crear una canalización elegante y que funcione correctamente. Y no será necesario describirlo en una gran parte de XML. Además, casi todo el ecosistema de Python y todo su zoológico de bibliotecas están disponibles de fábrica, que se pueden usar como desee.
- La ausencia de XML simplifica enormemente la revisión del código. Escribimos el código de la canalización y las configuraciones para ello, y todo es genial, todo funciona. De hecho, puede arrastrar en XML o cualquier otro formato de configuración, pero esto ya es cuestión de gustos.
- unit-, , .
- , «», . Airflow . , , .
- Airflow ( ).
- Active Directory RBAC (role-based access control, )
- Worker Celery Kubernetes.
- open source-, , .
- Airflow , . .
- : statsd , Sentry – , Airflow , . Airflow-exporter Prometheus.
Airflow,
- – : , , execution_date – , .
- - -, , , Apache NiFi. – code-review diff- , .
- Scheduler - .
- – , . – .
- Airflow : . , , . RBAC ( ) , UI (, , ). RBAC – security Flask, .
- : , , -, , . , .
Airflow
- crontab’a cron .
- Python.
- - Docker, , .
- , , real time.
- Airflow , “, , , Z – ”.