
Las bases de datos gráficas son una tecnología importante para los profesionales de bases de datos. Intento mantenerme al día con las innovaciones y las nuevas tecnologías en esta área y después de trabajar con bases de datos relacionales y NoSQL, veo que el papel de las bases de datos de grafos está creciendo. Cuando se trabaja con datos jerárquicos complejos, no solo las bases de datos tradicionales, sino también NoSQL son ineficaces. A menudo, con un aumento en el número de niveles de enlaces y el tamaño de la base, hay una disminución en el rendimiento. Y a medida que las relaciones se vuelven más complejas, también aumenta el número de JOIN.
Por supuesto, existen soluciones en el modelo relacional para trabajar con jerarquías (por ejemplo, usando CTE recursivas), pero estas siguen siendo soluciones. Al mismo tiempo, la funcionalidad de las bases de datos de gráficos de SQL Server le permite procesar fácilmente varios niveles de la jerarquía. Tanto el modelo de datos como las consultas se simplifican y, por tanto, son más eficientes. La cantidad de código se reduce significativamente.
Las bases de datos de gráficos son un lenguaje expresivo para representar sistemas complejos. Esta tecnología ya se utiliza bastante en la industria de TI en áreas como redes sociales, sistemas antifraude, análisis de redes de TI, recomendaciones sociales, recomendaciones de productos y contenido.
La funcionalidad de la base de datos de gráficos en SQL Server es adecuada para escenarios en los que los datos están estrechamente acoplados y tienen relaciones bien definidas.
Modelo de datos gráficos
Un gráfico es un conjunto de vértices (nodos) y aristas (relaciones). Los vértices representan entidades y los bordes representan enlaces cuyos atributos pueden contener información.
Una base de datos de grafos modela entidades en forma de grafo, como se define en la teoría de grafos. Las estructuras de datos son vértices y aristas. Los atributos son propiedades de vértices y aristas. Un enlace es una conexión de vértices.
A diferencia de otros modelos de datos, en las bases de datos de gráficos, las relaciones entre entidades tienen prioridad. Por lo tanto, no es necesario calcular las relaciones utilizando claves externas o de alguna otra forma. Puede crear modelos de datos complejos utilizando solo abstracciones de vértices y bordes.
En el mundo moderno, modelar relaciones requiere técnicas cada vez más sofisticadas. Para modelar relaciones, SQL Server 2017 ofrece capacidades de base de datos de gráficos. Los vértices y los bordes del gráfico se representan como nuevos tipos de tablas: NODE y EDGE. Se utiliza una nueva función T-SQL llamada MATCH () para consultar el gráfico. Dado que esta funcionalidad está integrada en SQL Server 2017, se puede utilizar en sus bases de datos existentes sin necesidad de conversión.
Beneficios del modelo gráfico
Hoy en día, tanto las empresas como los usuarios demandan aplicaciones que manejen más y más datos mientras esperan un alto rendimiento y confiabilidad. La presentación de datos en forma de gráfico ofrece un medio conveniente para manejar relaciones complejas. Este enfoque resuelve muchos problemas y le ayuda a obtener resultados dentro de un contexto determinado.
Parece que en el futuro, muchas aplicaciones se beneficiarán del uso de bases de datos gráficas.
Modelado de datos: del modelo relacional al gráfico
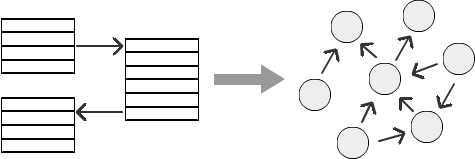
Ejemplo
Tomemos un ejemplo de una estructura organizacional con una jerarquía de empleados: un empleado reporta a un gerente, un gerente reporta a un gerente senior, y así sucesivamente. Esta jerarquía puede tener cualquier número de niveles, dependiendo de una empresa en particular. Pero a medida que aumenta el número de niveles, calcular las relaciones en una base de datos relacional se vuelve cada vez más difícil. Es bastante difícil representar la jerarquía de empleados, la jerarquía en las comunicaciones de marketing o redes sociales. Veamos cómo SQL Graph puede resolver el problema de manejar diferentes niveles de la jerarquía.
Para este ejemplo, hagamos un modelo de datos simple. Creemos una tabla de empleados EMP con un identificador EMPNO y una columna MGR, indicando el identificador del gerente (gerente) del empleado. Toda la información sobre la jerarquía se almacena en esta tabla y se puede consultar utilizando las columnas EMPNO y MGR .
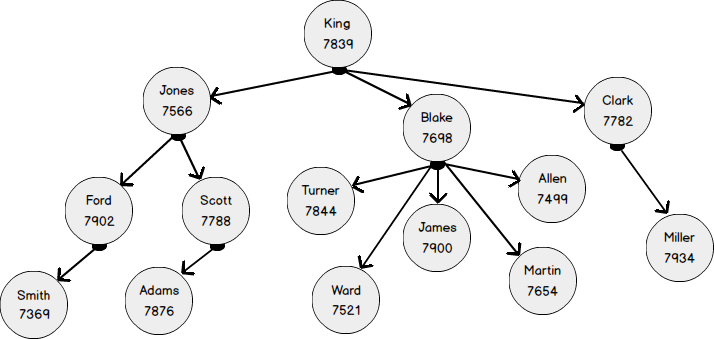
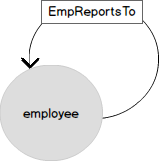
El siguiente diagrama muestra el mismo modelo de organigrama con cuatro niveles de anidamiento en una forma más familiar. Los empleados son los vértices del gráfico de la tabla EMP . La entidad "empleado" está vinculada a sí misma mediante el enlace "envía" (ReportsTo). En términos de gráficos, un enlace es un borde (EDGE) que conecta los nodos (NODE) de los empleados.
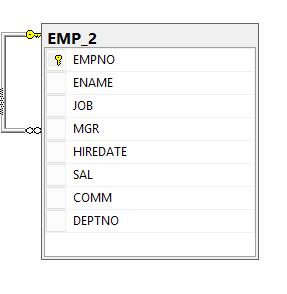
Creemos una tabla EMP regular y agreguemos los valores allí de acuerdo con el diagrama anterior.
CREATE TABLE EMP
(EMPNO INT NOT NULL,
ENAME VARCHAR(20),
JOB VARCHAR(10),
MGR INT,
JOINDATE DATETIME,
SALARY DECIMAL(7, 2),
COMMISIION DECIMAL(7, 2),
DNO INT)
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, '02-MAR-1970', 8000, NULL, 2),
(7499, 'ALLEN', 'SALESMAN', 7698, '20-MAR-1971', 1600, 3000, 3),
(7521, 'WARD', 'SALESMAN', 7698, '07-FEB-1983', 1250, 5000, 3),
(7566, 'JONES', 'MANAGER', 7839, '02-JUN-1961', 2975, 50000, 2),
(7654, 'MARTIN', 'SALESMAN', 7698, '28-FEB-1971', 1250, 14000, 3),
(7698, 'BLAKE', 'MANAGER', 7839, '01-JAN-1988', 2850, 12000, 3),
(7782, 'CLARK', 'MANAGER', 7839, '09-APR-1971', 2450, 13000, 1),
(7788, 'SCOTT', 'ANALYST', 7566, '09-DEC-1982', 3000, 1200, 2),
(7839, 'KING', 'PRESIDENT', NULL, '17-JUL-1971', 5000, 1456, 1),
(7844, 'TURNER', 'SALESMAN', 7698, '08-AUG-1971', 1500, 0, 3),
(7876, 'ADAMS', 'CLERK', 7788, '12-MAR-1973', 1100, 0, 2),
(7900, 'JAMES', 'CLERK', 7698, '03-NOV-1971', 950, 0, 3),
(7902, 'FORD', 'ANALYST', 7566, '04-MAR-1961', 3000, 0, 2),
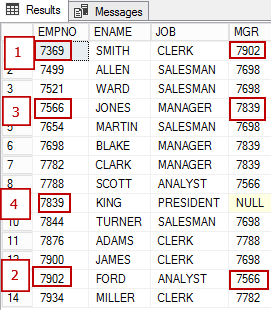
(7934, 'MILLER', 'CLERK', 7782, '21-JAN-1972', 1300, 0, 1)La siguiente figura muestra los empleados:
- empleado con EMPNO 7369 reporta al 7902;
- empleado con EMPNO 7902 obedece 7566
- empleado con EMPNO 7566 obedece 7839
Ahora veamos una representación gráfica de los mismos datos. El nodo EMPLEADO tiene varios atributos y está asociado a sí mismo por la relación "obedecer" (EmplReportsTo). EmplReportsTo es el nombre de la relación.
La tabla de borde (EDGE) también puede contener atributos.
Crear la tabla de nodos EmpNode
La sintaxis para crear un nodo es bastante simple: la instrucción CREATE TABLE se agrega con "AS NODE" al final .
CREATE TABLE dbo.EmpNode(
ID Int Identity(1,1),
EMPNO NUMERIC(4) NOT NULL,
ENAME VARCHAR(10),
MGR NUMERIC(4),
DNO INT
) AS NODE;Ahora transformemos los datos de una tabla normal en una gráfica. El siguiente INSERT inserta datos de la tabla relacional EMP .
INSERT INTO EmpNode(EMPNO,ENAME,MGR,DNO) select empno,ename,MGR,dno from emp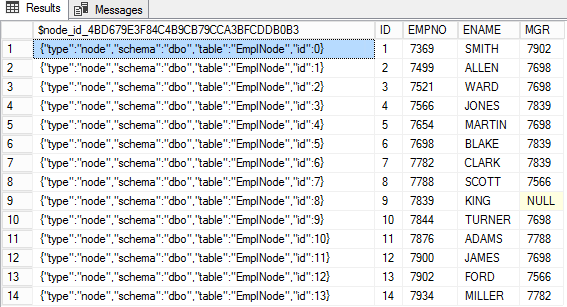
El
$node_id_*ID de nodo se almacena en una columna especial en la tabla de nodos en forma de JSON. Las columnas restantes de esta tabla contienen los atributos del nodo.
Crear aristas (EDGE)
Crear una tabla de aristas es muy similar a crear una tabla de nodos, excepto que se utiliza la palabra clave "AS EDGE" .
CREATE TABLE empReportsTo(Deptno int) AS EDGE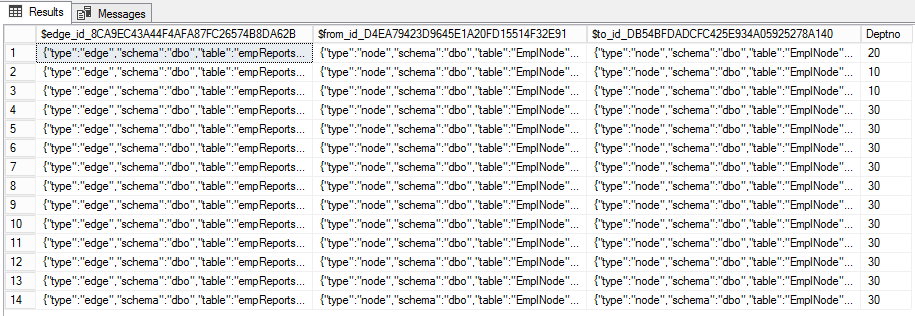
Ahora definamos las relaciones entre los empleados usando las columnas EMPNO y MGR . El organigrama muestra cómo escribir INSERT .
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 1),
(SELECT $node_id FROM EmpNode WHERE id = 13),20);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 2),
(SELECT $node_id FROM EmpNode WHERE id = 6),10);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 3),
(SELECT $node_id FROM EmpNode WHERE id = 6),10)
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 4),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 5),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 6),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 7),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 8),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 9),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 10),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 11),
(SELECT $node_id FROM EmpNode WHERE id = 8),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 12),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 13),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 14),
(SELECT $node_id FROM EmpNode WHERE id = 7),30);La tabla de borde predeterminada tiene tres columnas. El primero
$edge_ides el identificador JSON del borde. Los otros dos ( $from_idy $to_id) representan comunicaciones entre los nodos. Además, las nervaduras pueden tener propiedades adicionales. En nuestro caso, este es Deptno .
Vistas del sistema
Hay
sys.tablesdos columnas nuevas en la vista del sistema :
- is_edge
- is_node
SELECT t.is_edge,t.is_node,*
FROM sys.tables t
WHERE name like 'emp%'
SSMS
Los objetos relacionados con gráficos se encuentran en la carpeta Graph Tables. El icono de la tabla de nodos está marcado con un punto y el icono de la tabla del borde está marcado con dos círculos vinculados (que se parecen un poco a los anteojos).

Expresión MATCH
La expresión MATCH se toma de CQL (Cypher Query Language). Esta es una forma eficaz de consultar las propiedades de los gráficos. CQL comienza con una expresión MATCH .
Sintaxis
MATCH (<graph_search_pattern>)
<graph_search_pattern>::=
{<node_alias> {
{ <-( <edge_alias> )- }
| { -( <edge_alias> )-> }
<node_alias>
}
}
[ { AND } { ( <graph_search_pattern> ) } ]
[ ,...n ]
<node_alias> ::=
node_table_name | node_alias
<edge_alias> ::=
edge_table_name | edge_aliasEjemplos
Echemos un vistazo a algunos ejemplos.
La consulta a continuación muestra los empleados a quienes Smith y su gerente reportan.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR
FROM
empnode e, empnode e1, empReportsTo m
WHERE
MATCH(e-(m)->e1)
and e.ENAME='SMITH'
La siguiente consulta es para encontrar empleados y gerentes de segundo nivel para Smith. Si elimina la cláusula WHERE , el resultado mostrará todos los empleados.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2
WHERE
MATCH(e-(m)->e1-(m1)->e2)
and e.ENAME='SMITH'
Y finalmente, una solicitud para empleados y gerentes de tercer nivel.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e-(m)->e1-(m1)->e2-(m2)->e3)
and e.ENAME='SMITH'
Ahora cambiemos de dirección para atrapar a los jefes de Smith.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e<-(m)-e1<-(m1)-e2<-(m2)-e3)
Conclusión
SQL Server 2017 se ha establecido como una solución empresarial completa para varios desafíos comerciales de TI. La primera versión de SQL Graph es muy prometedora. Incluso a pesar de algunas limitaciones, ya existe suficiente funcionalidad para explorar las capacidades de los gráficos.
La funcionalidad de SQL Graph está completamente integrada en SQL Engine. Sin embargo, como se mencionó, SQL Server 2017 tiene las siguientes limitaciones:
No admite polimorfismo.
- .
- $from_id $to_id UPDATE.
- (transitive closure), CTE.
- In-Memory OLTP.
- (System-Versioned Temporal Table), .
- NODE EDGE.
- (cross-database queries).
- - (wizard) .
- GUI, Power BI.

: