
Hoy le contaremos cómo desarrollamos un sistema de búsqueda de pozos candidatos para fracturamiento hidráulico (HF) utilizando aprendizaje automático (en adelante, ML) y qué resultó de él. Averigüemos por qué se necesita la fracturación hidráulica, qué tiene que ver el ML y por qué nuestra experiencia puede ser útil no solo para los petroleros.
Debajo del corte, una declaración detallada del problema, una descripción de nuestras soluciones de TI, la elección de métricas, la creación de un pipeline ML, el desarrollo de una arquitectura para el lanzamiento de un modelo en prod.
Escribimos sobre por qué se realiza la fractura en nuestros artículos anteriores aquí y aquí .
¿Por qué está aquí el aprendizaje automático? Por un lado, la fracturación hidráulica es más barata que la perforación, pero sigue siendo costosa y, por otro lado, no será posible realizarla en todos los pozos, no tendrá ningún efecto. Un geólogo experto busca lugares adecuados. Dado que el número de empresas operativas es grande (decenas de miles), las opciones a menudo se pasan por alto y la empresa pierde su beneficio potencial. El uso del aprendizaje automático puede acelerar significativamente el análisis de la información. Sin embargo, crear un modelo ML es solo la mitad de la batalla. Es necesario hacerlo funcionar en modo constante, conectarlo al servicio de datos, dibujar una hermosa interfaz y hacerlo para que el usuario pueda ingresar fácilmente a la aplicación y resolver su problema en dos clics.
Al abstraerse de la industria petrolera, se puede observar que en todas las empresas se están resolviendo tareas similares. Todos quieren:
A. Automatizar el procesamiento y análisis de grandes flujos de datos.
B. Reduzca costos y no se pierda los beneficios.
C. Haga que dicho sistema sea rápido y eficiente.
A partir del artículo, aprenderá cómo implementamos dicho sistema, qué herramientas usamos y también qué obstáculos tuvimos en el espinoso camino de introducir ML en producción. Estamos seguros de que nuestra experiencia puede ser de interés para todo aquel que quiera automatizar una rutina, independientemente del campo de actividad.
Cómo se seleccionan los pozos para la fracturación hidráulica de la forma "tradicional"
Al seleccionar los pozos candidatos para la fracturación hidráulica, el petrolero confía en su amplia experiencia y observa diferentes gráficos y tablas, luego de lo cual predice dónde realizar la fracturación hidráulica. Sin embargo, nadie sabe de manera confiable lo que está sucediendo a una profundidad de varios miles de metros, porque no es tan fácil mirar bajo tierra (puede leer más en el artículo anterior ). El análisis de datos por métodos "tradicionales" requiere costos laborales significativos, pero, desafortunadamente, no garantiza un pronóstico preciso de los resultados de la fracturación hidráulica (spoiler - también con ML).
Si describimos el proceso actual de identificación de pozos candidatos para fracturamiento hidráulico, entonces constará de las siguientes etapas: descarga de datos de pozos de los sistemas de información corporativos, procesamiento de los datos obtenidos, realización de análisis de expertos, acuerdo sobre una solución, realización de fracturamiento hidráulico y análisis de resultados. Parece simple, pero no del todo.
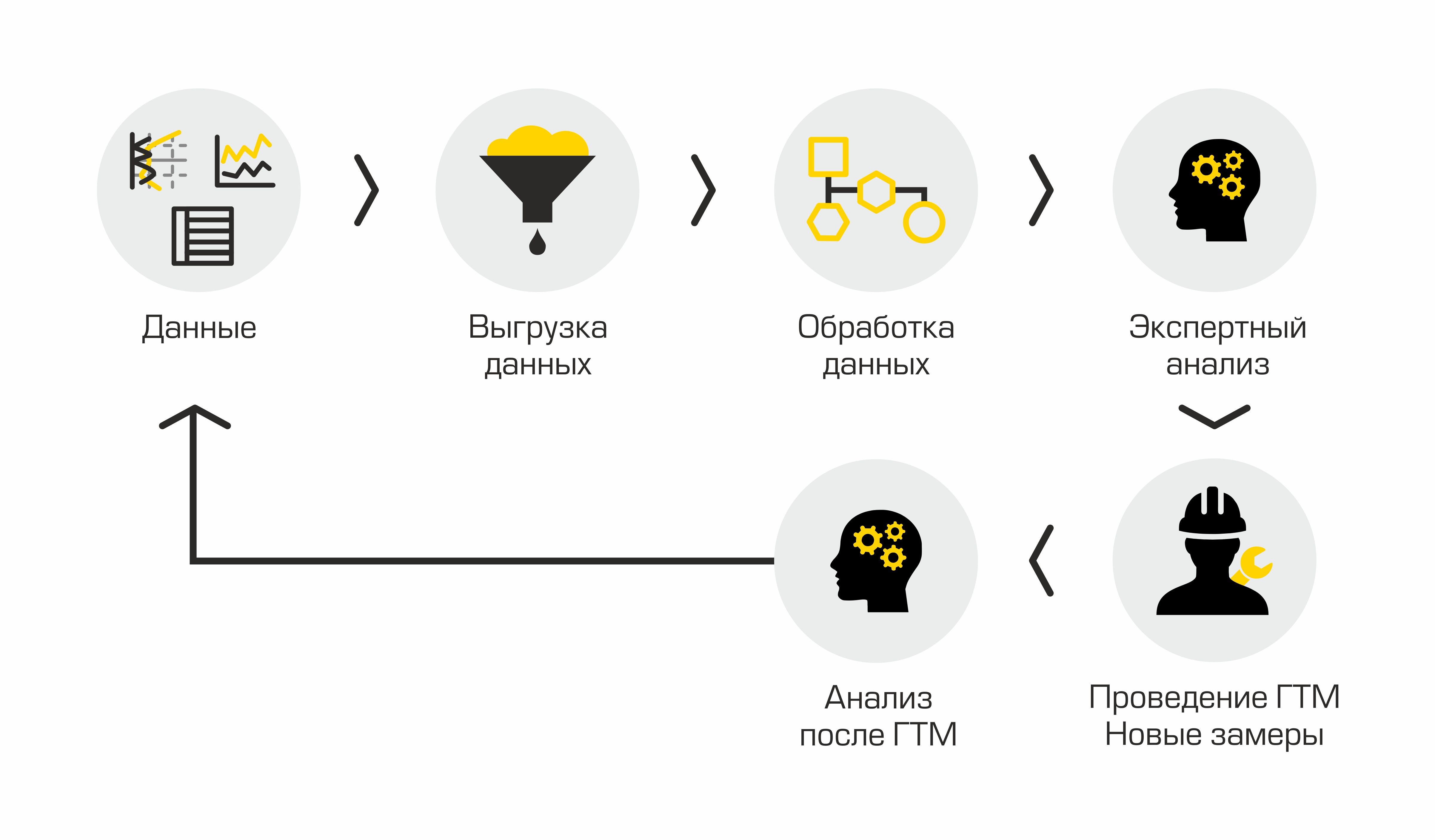
Proceso actual de selección de pozos candidatos
La principal desventaja de este enfoque “manual” es mucha rutina, los volúmenes crecen, la gente comienza a ahogarse en el trabajo, no hay transparencia en el proceso y los métodos.
Formulación del problema
En 2019, nuestro equipo de análisis de datos enfrentó la tarea de crear un sistema automatizado para seleccionar pozos candidatos para fracturamiento hidráulico. Para nosotros, sonó así: simular el estado de todos los pozos, asumiendo que en este momento es necesario realizar operaciones de fracturamiento hidráulico en ellos, y luego clasificar los pozos por el mayor aumento en la producción de petróleo y seleccionar los pozos Top-N a los que irá la flota y tomar medidas para aumentar la recuperación de petróleo.
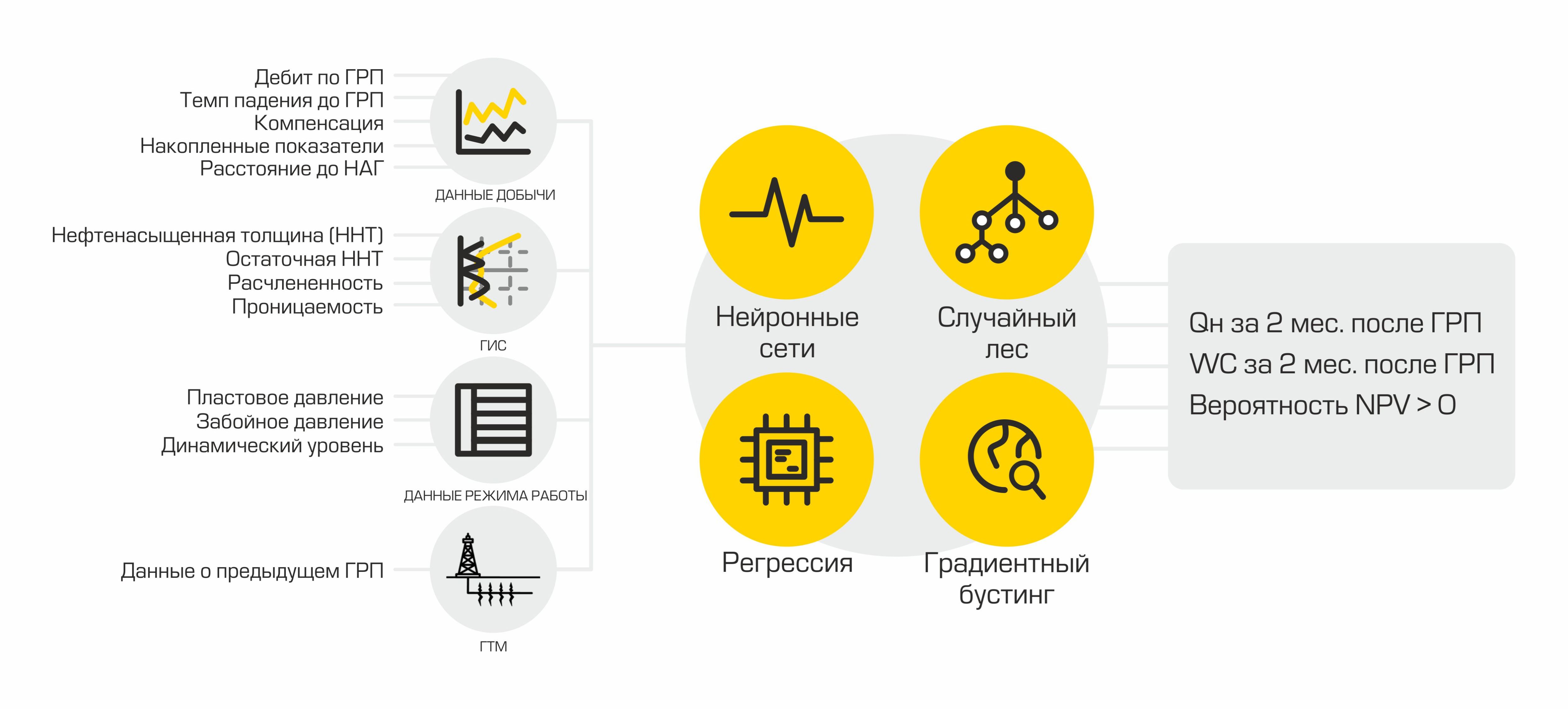
Utilizando modelos ML, se forman indicadores que indican la viabilidad de la fracturación hidráulica en un pozo específico: producción de petróleo después de la fracturación hidráulica planificada y el éxito de este evento.
En nuestro caso, la tasa de producción de petróleo es la cantidad de petróleo producida en metros cúbicos por mes. Este indicador se calcula en base a dos valores: caudal de líquido y corte de agua. Los petroleros llaman a un líquido una mezcla de aceite y agua: esta mezcla es el producto de los pozos. Y el corte de agua es la proporción de contenido de agua en una mezcla dada. Para calcular la tasa de producción de petróleo esperada después de la fracturación, se utilizan dos modelos de regresión: uno predice la tasa de flujo de fluido después de la fractura y el otro predice el corte de agua. Utilizando los valores devueltos por los datos del modelo, los pronósticos de producción de petróleo se calculan mediante la fórmula:

El éxito de la fractura es una variable objetivo binaria. Se determina utilizando el valor real del aumento en la tasa de producción de petróleo, que se obtuvo después de la fracturación hidráulica. Si la ganancia es mayor que un cierto umbral determinado por un experto en el área de dominio, entonces el valor del atributo de éxito es igual a uno, de lo contrario es igual a cero. Por lo tanto, formamos el marcado para resolver el problema de clasificación.
En cuanto a la métrica ... La métrica debe provenir del negocio y reflejar los intereses del cliente, nos dicen los cursos de aprendizaje automático. En nuestra opinión, aquí es donde radica el principal éxito o fracaso de un proyecto de aprendizaje automático. Un grupo de científicos de datos puede mejorar la calidad del modelo durante el tiempo que quieran, pero si no aumenta el valor comercial para el cliente de ninguna manera, este modelo está condenado al fracaso. Después de todo, era importante para el cliente obtener un candidato exacto con predicciones "físicas" de los parámetros de rendimiento del pozo después de la fracturación hidráulica.
Para el problema de la regresión, se eligieron las siguientes métricas:

¿Por qué no hay una métrica? Usted se pregunta: cada una refleja su propia verdad. Para los campos donde las tasas de producción promedio son altas, MAE será grande y MAPE será pequeño. Si tomamos un campo con tasas de producción promedio bajas, el panorama será el contrario.
Se eligieron las siguientes métricas para el problema de clasificación:

( wiki ),
Área bajo la curva ROC - AUC ( wiki ).
Errores que encontramos
Error n. ° 1: construir un modelo universal para todos los campos.
Después de analizar los conjuntos de datos, quedó claro que los datos cambian de un campo a otro. Esto no es sorprendente, ya que los depósitos, por regla general, tienen una estructura geológica diferente.
Nuestra suposición de que si tomamos y manejamos todos los datos disponibles para el entrenamiento en un modelo, entonces él mismo revelará las regularidades de la estructura geológica, ha fallado. El modelo entrenado con los datos de un campo específico mostró una mayor calidad de predicciones que el modelo, que se creó utilizando información sobre todos los campos disponibles.
Para cada campo, se probaron diferentes algoritmos de aprendizaje automático y, según los resultados de la validación cruzada, se seleccionó uno con el MAPE más bajo.
Error n. ° 2: falta de comprensión profunda de los datos.
Si desea crear un buen modelo de aprendizaje automático para un proceso físico real, comprenda cómo ocurre este proceso.
Inicialmente, nuestro equipo no tenía un experto en dominios y nos movíamos caóticamente. Por desgracia, no notamos los errores del modelo al analizar los pronósticos, extrajeron conclusiones incorrectas en función de los resultados.
Error n. ° 3: falta de infraestructura.
Al principio, descargamos muchos archivos csv diferentes para diferentes campos y diferentes parámetros. En algún momento, se acumuló una cantidad insoportable de archivos y modelos. Se hizo imposible reproducir los experimentos ya realizados, se perdieron archivos y surgió confusión.
1. PARTE TÉCNICA
Hoy nuestro sistema de autoselección de candidatos se ve así:
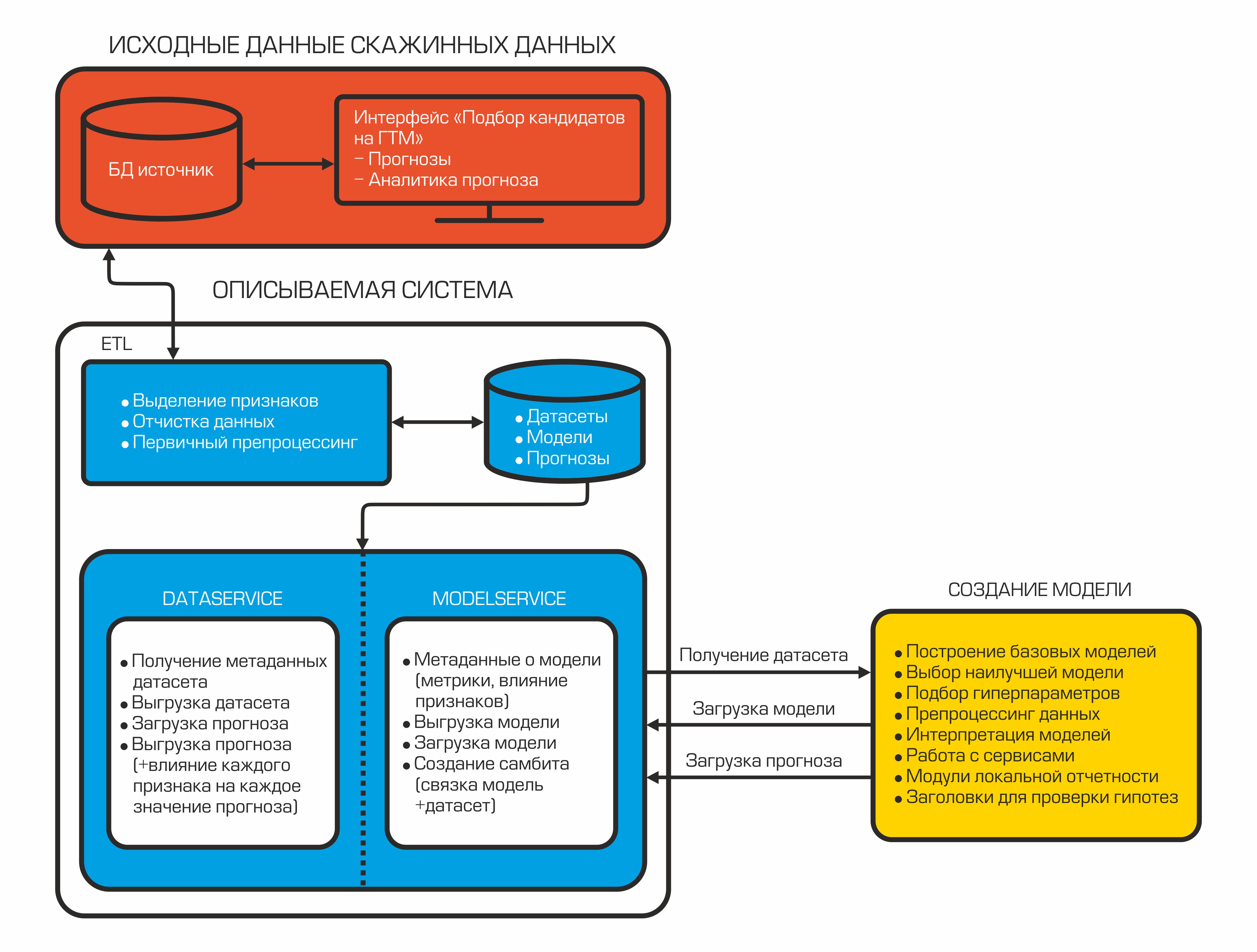
Cada componente es un contenedor aislado que realiza una función específica.
2.1 ETL = Carga de datos
Todo comienza con los datos. Especialmente si queremos construir un modelo de aprendizaje automático. Elegimos Pentaho Data Integration como sistema de integración.

Captura de pantalla de una de las transformaciones
Principales ventajas:
- sistema libre;
- una gran selección de componentes para conectarse a varias fuentes de datos y transformar el flujo de datos;
- disponibilidad de una interfaz web;
- la capacidad de administrar a través de REST API;
- Inicio sesión.
Además de todo lo anterior, teníamos una amplia experiencia en el desarrollo de integraciones para este producto. ¿Por qué se necesita la integración de datos en los proyectos de ML? En la preparación de bases de datos están en constante requerido para implementar cálculos complejos para proporcionar datos a una mente común "en el camino" para calcular los nuevos signos - .. Media, el parámetro cambia con el tiempo, etc.
Para cada fracturación hecho descargan más de 400 parámetros que describen el trabajo bien en el momento de actividades, operación de pozos adyacentes, así como información sobre fracturación hidráulica realizada previamente. Además, tiene lugar la transformación y el preprocesamiento de datos.
Elegimos PostgreSQL como repositorio de los datos procesados. Tiene un gran conjunto de métodos para trabajar con json. Dado que almacenamos los conjuntos de datos finales en este formato, esto se convirtió en un factor decisivo.
Un proyecto de aprendizaje automático está asociado con un cambio constante en los datos de entrada debido a la adición de nuevas funciones, por lo tanto, Data Vault se utiliza como el esquema de la base de datos (enlace a wiki). Este esquema de diseño de almacenamiento le permite agregar rápidamente nuevos datos sobre un objeto y no violar la integridad de las tablas y consultas.
2.2 Servicios de datos y modelos
Después de combinar y calcular los indicadores necesarios, los datos se cargan en la base de datos. Se almacenan aquí y están esperando que el datasinter los tome para crear el modelo ML. Para esto, existe DataService, un servicio escrito en Python y que usa el protocolo gRPC. Le permite obtener conjuntos de datos y sus metadatos (tipos de características, su descripción, tamaño del conjunto de datos, etc.), cargar y descargar pronósticos, administrar parámetros de filtrado y división por tren / prueba. Los pronósticos en la base de datos se almacenan en formato json, lo que le permite recibir datos rápidamente y almacenar no solo el valor del pronóstico, sino también la influencia de cada característica en este pronóstico en particular.
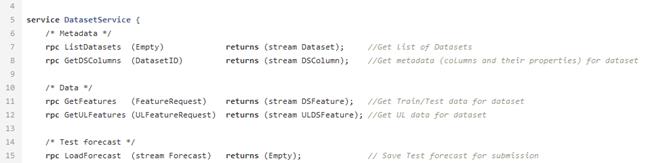
Ejemplo de archivo proto para el servicio de datos.
Cuando se crea el modelo, debe guardarse; para este propósito, se utiliza ModelService, también escrito en Python con gRPC. Las capacidades de este servicio no se limitan a guardar y cargar un modelo. Además, permite monitorear métricas, la importancia de las características, y también implementa una conexión modelo + conjunto de datos para la posterior creación automática de un pronóstico cuando aparecen nuevos datos.

La estructura de nuestro servicio de modelos se ve así.
2.3 Modelo de AA
En cierto punto, nuestro equipo se dio cuenta de que la automatización también debería afectar la creación de modelos de AA. Esta necesidad fue impulsada por la necesidad de acelerar el proceso de hacer pronósticos y probar hipótesis. Y tomamos la decisión de desarrollar e implementar nuestra propia biblioteca AutoML en nuestra canalización.
Inicialmente, se consideró la posibilidad de usar bibliotecas AutoML listas para usar, pero las soluciones existentes resultaron no ser lo suficientemente flexibles para nuestra tarea y no tenían todas las funciones necesarias a la vez (a pedido de los trabajadores, podemos escribir un artículo separado sobre nuestro AutoML). Solo notamos que el marco que hemos desarrollado contiene clases utilizadas para preprocesar un conjunto de datos, generar y seleccionar características. Como modelos de aprendizaje automático, usamos un conjunto familiar de algoritmos que hemos usado con mayor éxito antes: implementaciones de aumento de gradiente de las bibliotecas xgboost, catboost, un bosque aleatorio de Sklearn, una red neuronal completamente conectada en Pytorch, etc. Después del entrenamiento, AutoML devuelve un canal de sklearn que incluye las clases mencionadas, así como el modelo ML,que mostró el mejor resultado en la validación cruzada para la métrica seleccionada.
Además del modelo, se crea un informe sobre la influencia de cualquier signo en un pronóstico específico. Tal informe permite a los geólogos mirar bajo el capó de una misteriosa caja negra. Por lo tanto, AutoML recibe el conjunto de datos etiquetado utilizando DataService y, después del entrenamiento, forma el modelo final. A continuación, podemos obtener la estimación final de la calidad del modelo cargando el conjunto de datos de prueba, generando pronósticos y calculando métricas de calidad. La etapa final es cargar un archivo binario del modelo generado, su descripción, métricas al ModelService, mientras que los pronósticos y la información sobre la influencia de las características se devuelven al DataService.
Entonces, nuestro modelo se coloca en un tubo de ensayo y está listo para ser lanzado en prod. En cualquier momento, podemos usarlo para generar pronósticos basados en datos nuevos y relevantes.
2.4 Interfaz
El usuario final de nuestro producto es un geólogo y necesita interactuar de alguna manera con el modelo ML. La forma más conveniente para él es un módulo en software especializado. Lo hemos implementado.
La interfaz, disponible para nuestro usuario, parece una tienda en línea: puede seleccionar el campo deseado y obtener una lista de los pozos exitosos más probables. En la tarjeta del pozo, el usuario ve el crecimiento previsto después de la fracturación hidráulica y decide por sí mismo si quiere agregarlo a la "canasta" y considerarlo con más detalle.

Interfaz del módulo en la aplicación.

Así es como se ve la tarjeta de pozo en el apéndice.
Además de las ganancias de aceite y líquido previstas, el usuario también puede averiguar qué características influyeron en el resultado propuesto. La importancia de las características se calcula en la etapa de creación de un modelo usando el método shap y luego se carga en la interfaz del software con DataService.

La aplicación muestra claramente qué características fueron más importantes para las predicciones del modelo.
El usuario también puede mirar análogos del pozo de interés. La búsqueda de análogos se implementa en el lado del cliente utilizando el algoritmo de árbol Kd .
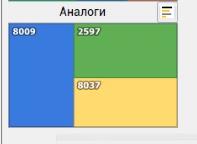
El módulo muestra pozos con parámetros geológicos similares.
2. CÓMO MEJORAMOS EL MODELO ML

Parece que vale la pena ejecutar AutoML con los datos disponibles, y estaremos encantados. Pero sucede que la calidad de las previsiones obtenidas automáticamente no se puede comparar con los resultados de los indicadores de datos. El punto es que para mejorar los modelos, los analistas a menudo proponen y prueban varias hipótesis. Si la idea mejora la precisión de la previsión en datos reales, se implementa en AutoML. Por lo tanto, al agregar nuevas funciones, hemos mejorado la previsión automática lo suficiente como para pasar a la creación de modelos y previsiones con una participación mínima de los analistas. A continuación, se muestran algunas hipótesis que se han probado e implementado en nuestro AutoML:
1. Cambiar el método de llenado
En los primeros modelos, llenamos casi todos los huecos en las características con la media, excepto los categóricos, para ellos se utilizó el significado más común. Posteriormente, con el trabajo conjunto de analistas y un experto, en el área de dominio, fue posible seleccionar los valores más adecuados para llenar los vacíos en el 80% de las características. También probamos algunos métodos de relleno más usando las bibliotecas sklearn y missingpy. Los mejores resultados se obtuvieron con llenado constante y KNNImputer, hasta un 5% de MAPE.

Resultados de un experimento para llenar los vacíos con diferentes métodos.
2. Generación de funciones
Agregar nuevas funciones es un proceso iterativo para nosotros. Para mejorar los modelos, intentamos agregar nuevas características basadas en las recomendaciones de un experto en el dominio, basadas en la experiencia de artículos científicos y nuestras propias conclusiones de los datos.

Probar las hipótesis propuestas por el equipo ayuda a introducir nuevas funciones.
Una de las primeras fueron las características identificadas sobre la base de la agrupación. De hecho, simplemente seleccionamos grupos en el conjunto de datos basados en parámetros geológicos y generamos estadísticas básicas para otras características basadas en grupos; esto dio un pequeño aumento en la calidad.
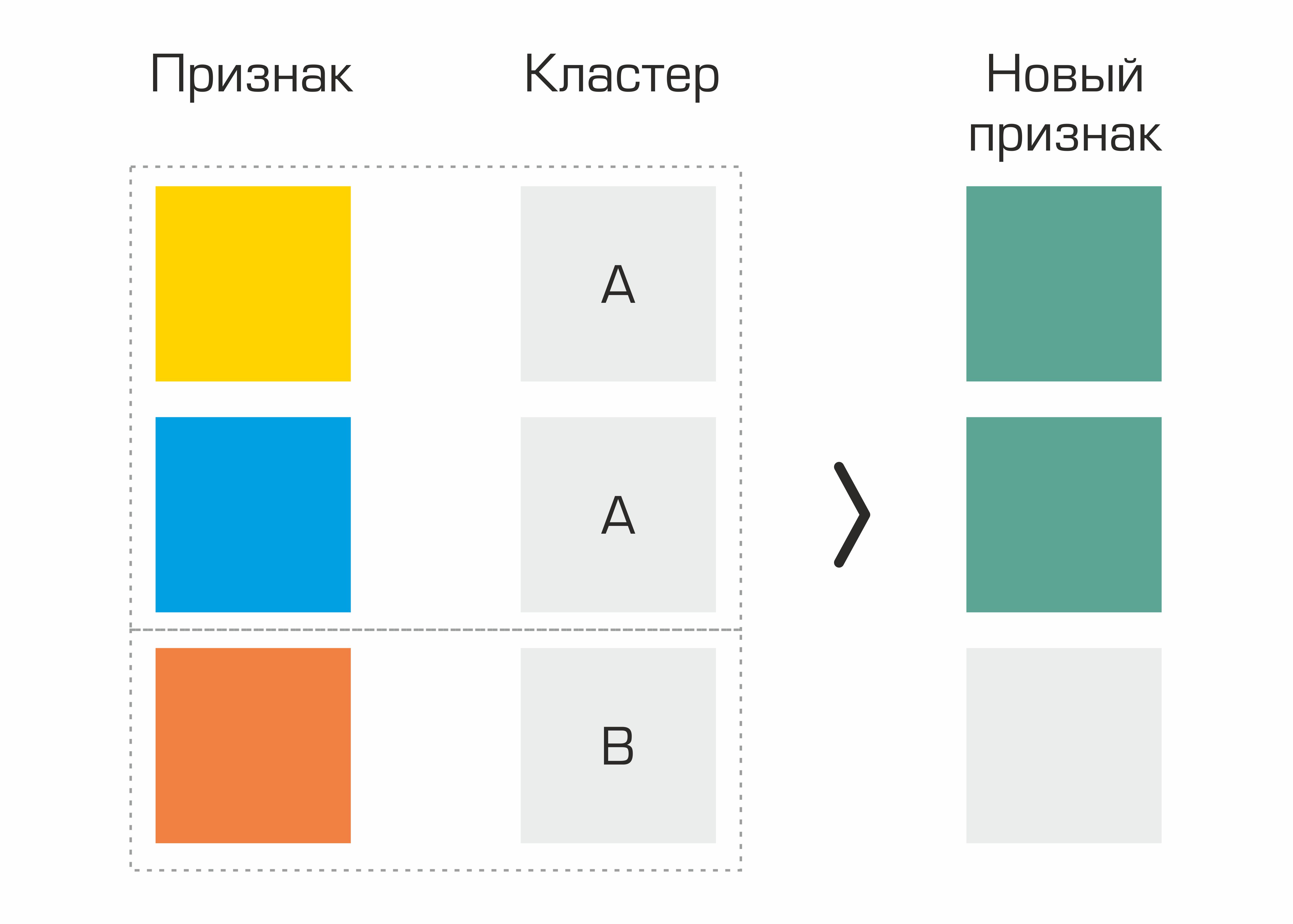
El proceso de creación de una característica basada en la selección de clústeres.
También agregamos los signos que inventamos al sumergirnos en la región del dominio: producción acumulada de petróleo normalizada a la edad del pozo en meses, la inyección acumulada normalizada a la edad del pozo en meses, los parámetros incluidos en la fórmula de Dupuis. Pero la generación del conjunto estándar de PolynomialFeatures de sklearn no nos dio un aumento en la calidad.
3.
Selección de características Realizamos la selección de características varias veces: tanto manualmente junto con un experto en el dominio como utilizando métodos estándar de selección de características. Después de varias iteraciones, decidimos eliminar de los datos algunas características que no afectan al objetivo. Así, logramos reducir el tamaño del conjunto de datos, manteniendo la misma calidad, lo que permitió acelerar significativamente la creación de modelos.
Y ahora sobre las métricas recibidas ...
En uno de los campos, obtuvimos los siguientes indicadores de calidad del modelo:

Cabe señalar que el resultado de la fracturación hidráulica también depende de una serie de factores externos que no están previstos. Por lo tanto, no podemos hablar de reducir MAPE a 0.
Conclusión La
selección de pozos candidatos para la fracturación hidráulica utilizando ML es un proyecto ambicioso que reunió a 7 personas: ingenieros de datos, analizadores de datos, expertos en dominio y gerentes. Hoy, el proyecto está realmente listo para su lanzamiento y ya se está probando en varias subsidiarias de la Compañía.
La empresa está abierta a la experimentación, por lo que se seleccionaron unos 20 pozos de la lista y se fracturaron. La desviación del pronóstico con el valor real de la tasa de producción de petróleo inicial (MAPE) fue de aproximadamente el 10%. ¡Y este es un muy buen resultado!
No seamos astutos: especialmente en la etapa inicial, varios de nuestros pozos propuestos resultaron ser opciones inadecuadas.
Escriba preguntas y comentarios, intentaremos responderlos.
Suscríbete a nuestro blog, tenemos muchas más ideas y proyectos interesantes, ¡sobre los que definitivamente escribiremos!