
PostgreSQL ya ha demostrado su valía: funciona muy bien, es utilizado por empresas digitales de moda como Alibaba y TripAdvisor, y la falta de regalías lo convierte en una alternativa tentadora a monstruos como MS SQL u Oracle DB. Pero tan pronto como empezamos a pensar en PostgreSQL en el panorama empresarial, inmediatamente nos encontramos con requisitos estrictos: “¿Pero qué pasa con la tolerancia a fallas de configuración? resistencia al desastre? ¿Dónde está el seguimiento integral? ¿Qué pasa con las copias de seguridad automatizadas? ¿qué pasa con el uso de bibliotecas de cintas, tanto de almacenamiento directo como secundario? "
Por un lado, PostgreSQL no tiene funciones de respaldo integradas, como el DBMS para "adultos" como RMAN, Oracle DB o SAP Database Backup. Por otro lado, los proveedores de sistemas de copia de seguridad corporativos (Veeam, Veritas, Commvault), si bien admiten PostgreSQL, de hecho solo trabajan con una determinada configuración (normalmente autónoma) y con un conjunto de restricciones diversas.
Los sistemas de respaldo especialmente diseñados para PostgreSQL, como Barman, Wal-g, pg_probackup, son extremadamente populares en instalaciones pequeñas de PostgreSQL o donde no se necesitan respaldos pesados de otros elementos del panorama de TI. Por ejemplo, además de PostgreSQL, la infraestructura puede tener servidores físicos y virtuales, OpenShift, Oracle, MariaDB, Cassandra, etc. Todo esto debe respaldarse con una herramienta común. Poner una solución separada exclusivamente para PostgreSQL es una mala idea: los datos se copiarán en algún lugar del disco y luego deberán eliminarse en cinta. Esta duplicación de la copia de seguridad aumenta el tiempo de la copia de seguridad y, lo que es más importante, la recuperación.
En una solución empresarial, una instalación se respalda con una cierta cantidad de nodos en un clúster dedicado. Al mismo tiempo, por ejemplo, Commvault solo puede funcionar con un clúster de dos nodos, en el que Primario y Secundario se asignan rígidamente a ciertos nodos. Y tiene sentido hacer una copia de seguridad solo con Primary, porque hacer una copia de seguridad con Secondary tiene sus limitaciones. Debido a las peculiaridades del DBMS, no se crea un volcado en Secundario, por lo que solo queda la posibilidad de una copia de seguridad del archivo.
Para mitigar los riesgos del tiempo de inactividad, la creación de un sistema tolerante a fallas crea una configuración de clúster en vivo, y el primario puede migrar gradualmente entre diferentes servidores. Por ejemplo, el propio software Patroni inicia Primary en un nodo de clúster seleccionado al azar. SRK no tiene forma de rastrear esto de inmediato, y si la configuración cambia, los procesos se interrumpen. Es decir, la introducción del control externo evita que el SRK funcione de manera eficaz, porque el servidor de control simplemente no comprende dónde y qué datos se deben copiar.
Otro problema es la implementación de la copia de seguridad en Postgres. Es posible mediante volcado y funciona en bases pequeñas. Pero en las bases de datos grandes, el volcado lleva mucho tiempo, requiere muchos recursos y puede provocar una falla en la instancia de la base de datos.
La copia de seguridad de archivos corrige la situación, pero en bases de datos grandes es lenta porque funciona en modo de un solo subproceso. Además, los proveedores tienen una serie de restricciones adicionales. No puede utilizar copias de seguridad de archivo y volcado al mismo tiempo o no se admite la deduplicación. Hay muchos problemas, y la mayoría de las veces es más fácil elegir un DBMS costoso pero probado en lugar de Postgres.
¡Ningún lugar para retirarse! ¡Detrás de los desarrolladores de Moscú !
Sin embargo, recientemente nuestro equipo enfrentó un desafío difícil: en el proyecto de creación de AIS OSAGO 2.0, donde hicimos la infraestructura de TI, los desarrolladores del nuevo sistema eligieron PostgreSQL.
Es mucho más fácil para los grandes desarrolladores de software utilizar soluciones de código abierto "de moda". Facebook tiene suficientes especialistas para apoyar el trabajo de este DBMS. Y en el caso de PCA, todas las tareas del "segundo día" recayeron sobre nuestros hombros. Se nos pidió que proporcionáramos tolerancia a fallas, ensamblar un clúster y, por supuesto, establecer una copia de seguridad. La lógica de las acciones fue la siguiente:
- Enseñe al SRK a realizar una copia de seguridad desde el nodo principal del clúster. Para hacer esto, el SRK debe encontrarlo, lo que significa que necesita integración con una u otra solución para administrar el clúster de PostgreSQL. En el caso de PCA, se utilizó el software Patroni para ello.
- Decida el tipo de copia de seguridad según la cantidad de datos y los requisitos de recuperación. Por ejemplo, cuando sea necesario restaurar páginas de forma granular, utilice un volcado, y si las bases de datos son grandes y no se requiere una restauración granular, trabaje a nivel de archivo.
- Adjunte la función de copia de seguridad en bloque a la solución para crear una copia de seguridad de varios subprocesos.
Al mismo tiempo, inicialmente nos propusimos crear un sistema eficaz y simple sin ataduras monstruosas de componentes adicionales. Cuantas menos muletas, menor será la carga de trabajo del personal y menor será el riesgo de falla del SII. Inmediatamente descartamos los enfoques que usaban Veeam y RMAN, porque un conjunto de dos soluciones ya apunta a la falta de confiabilidad del sistema.
Un poco de magia para una empresa
Por lo tanto, necesitábamos garantizar un respaldo confiable para 10 clústeres de 3 nodos cada uno, mientras que la misma infraestructura se refleja en el centro de datos de respaldo. Los centros de datos en el plan PostgreSQL funcionan según el principio activo-pasivo. La cantidad total de bases de datos fue de 50 TB. Cualquier SRC de nivel corporativo puede manejar esto fácilmente. Pero el matiz es que inicialmente Postgres no tiene un gancho para una compatibilidad completa y profunda con los sistemas de respaldo. Por lo tanto, tuvimos que buscar una solución que inicialmente tenga la máxima funcionalidad en conjunto con PostgreSQL y modificar el sistema.
Realizamos 3 "hackatones" internos: analizamos más de cincuenta desarrollos, los probamos, realizamos cambios en relación con nuestras hipótesis y los probamos nuevamente. Después de analizar las opciones disponibles, elegimos Commvault. Fuera de la caja, este producto podría funcionar con la instalación de PostgreSQL en clúster más simple, y su arquitectura abierta dio lugar a la esperanza (que se hizo realidad) de un refinamiento e integración exitosos. Además, Commvault puede realizar copias de seguridad de los registros de PostgreSQL. Por ejemplo, Veritas NetBackup en la parte de PostgreSQL solo puede realizar copias de seguridad completas.
Aprenda más sobre arquitectura. Los servidores de administración de Commvault se instalaron en cada uno de los dos centros de datos en una configuración de CommServ HA. El sistema se duplica, se administra a través de una única consola y, desde el punto de vista de HA, cumple con todos los requisitos empresariales.
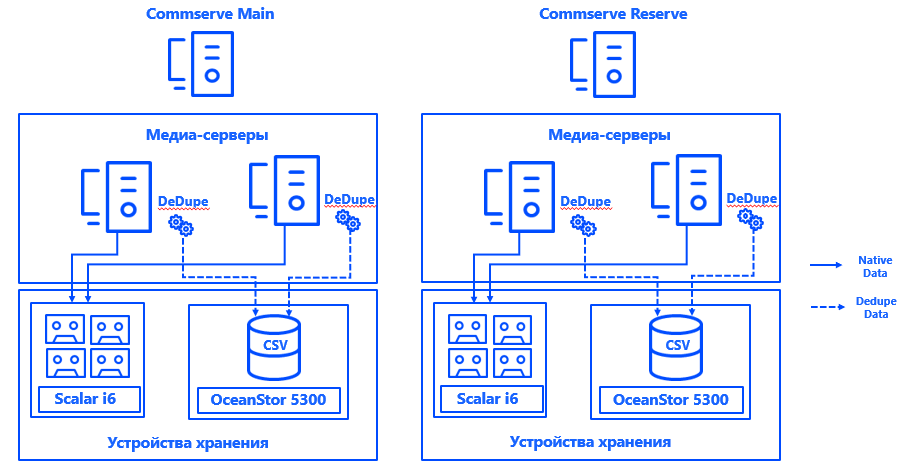
También lanzamos dos servidores de medios físicos en cada centro de datos, a los cuales conectamos matrices de discos y bibliotecas de cintas dedicadas específicamente para respaldos a través de una SAN a través de Fibre Channel. Las bases de deduplicación ampliadas aseguraron la resistencia de los servidores de medios y la conexión de cada servidor a cada CSV, la posibilidad de un funcionamiento continuo en caso de falla de cualquier componente. La arquitectura del sistema permite que la copia de seguridad continúe incluso si uno de los centros de datos se cae.
Patroni define un nodo primario para cada clúster. Puede ser cualquier nodo libre en el centro de datos, pero solo en el principal. En la copia de seguridad, todos los nodos son secundarios.
Para que Commvault entienda qué nodo del clúster es el principal, integramos el sistema (gracias a la arquitectura abierta de la solución) con Postgres. Para hacer esto, se creó un script que informa la ubicación actual del nodo principal al servidor de administración de Commvault.
En general, el proceso se ve así:
Patroni selecciona Primario → Keepalived abre el clúster IP y ejecuta el script → El agente de Commvault en el nodo del clúster seleccionado recibe una notificación de que es Primario → Commvault reconfigura automáticamente la copia de seguridad dentro del pseudocliente.
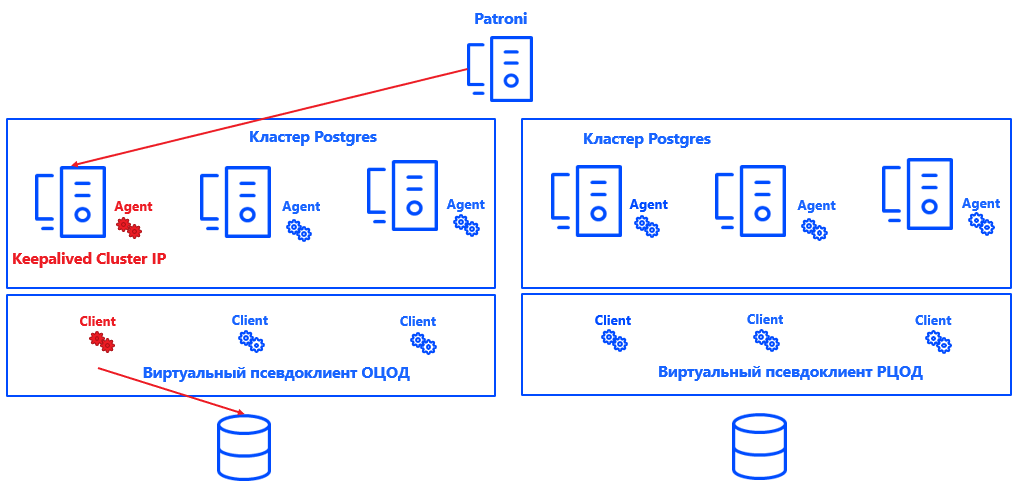
La ventaja de este enfoque es que la solución no afecta ni a la consistencia ni a la corrección de los registros ni a la recuperación de la instancia de Postgres. También es fácilmente escalable, porque ahora no es necesario arreglar los nodos primario y secundario de Commvault. Es suficiente con que el sistema comprenda dónde está Primario y la cantidad de nodos se puede aumentar a casi cualquier valor.
La solución no pretende ser ideal y tiene sus propios matices. Commvault solo puede respaldar una instancia completa, no bases de datos individuales. Por lo tanto, se ha creado una instancia separada para cada base de datos. Los clientes reales se combinan en pseudoclientes virtuales. Cada pseudocliente de Commvault es un clúster de UNIX. Agrega los nodos de clúster en los que está instalado el agente de Commvault para Postgres. Como resultado, todos los nodos virtuales del pseudocliente se respaldan como una sola instancia.
Dentro de cada pseudocliente, se indica el nodo activo del clúster. Esto es lo que define nuestra solución de integración para Commvault. El principio de su funcionamiento es bastante simple: si la IP de un clúster se eleva en un nodo, el script establece el parámetro "nodo activo" en el binario del agente de Commvault; de hecho, el script establece "1" en la parte requerida de la memoria. El agente envía estos datos a CommServe y Commvault realiza una copia de seguridad desde el nodo deseado. Además, la corrección de la configuración se comprueba a nivel de script, lo que ayuda a evitar errores al iniciar la copia de seguridad.
Al mismo tiempo, las bases de datos grandes se respaldan en bloque en varios subprocesos, cumpliendo con los requisitos de RPO y ventanas de respaldo. La carga en el sistema es insignificante: las copias completas no ocurren con tanta frecuencia, otros días solo se recopilan los registros, además, durante los períodos de baja carga.
Por cierto, aplicamos políticas independientes para realizar copias de seguridad de los registros archivados de PostgreSQL: se almacenan de acuerdo con diferentes reglas, se copian según un programa diferente y la deduplicación no está habilitada para ellos, ya que estos registros contienen datos únicos.
Para garantizar la coherencia de toda la infraestructura de TI, se instalan clientes de archivos Commvault separados en cada uno de los nodos del clúster. Excluyen los archivos de Postgres de las copias de seguridad y están destinados solo para las copias de seguridad del sistema operativo y las aplicaciones. Esta parte de los datos también tiene su propia política y su propio período de almacenamiento.

Ahora el SRK no afecta los servicios productivos, pero si la situación cambia, será posible habilitar el sistema de limitación de carga en Commvault.
¿Esta bien? ¡Bueno!
Por lo tanto, no solo obtuvimos una copia de seguridad viable, sino también completamente automatizada para una instalación de PostgreSQL en clúster, que cumple con todos los requisitos de las llamadas empresariales.
Los parámetros RPO y RTO a 1 hora y 2 horas se superponen con un margen, lo que significa que el sistema los cumplirá incluso con un aumento significativo en el volumen de datos almacenados. A pesar de muchas dudas, PostgreSQL y el entorno empresarial resultaron ser bastante compatibles. Y ahora sabemos por nuestra propia experiencia que es posible realizar una copia de seguridad de dicho DBMS en una amplia variedad de configuraciones.
Por supuesto, en el camino, tuvimos que desgastar siete pares de botas de hierro, superar una serie de dificultades, pisar algunos rastrillos y corregir varios errores. Pero ahora el enfoque ya se ha probado y se puede utilizar para implementar código abierto en lugar de DBMS propietario en el duro entorno empresarial.
¿Ha probado PostgreSQL en un entorno corporativo?
Autores:
Oleg Lavrenov, ingeniero de diseño de los sistemas de almacenamiento de datos Jet Infosystems
Dmitry Erykin, ingeniero de diseño de Jet Infosystems Computing Systems