En Lyft decidimos trasladar nuestra infraestructura de servidores a Kubernetes, un sistema de orquestación de contenedores distribuidos, para aprovechar los beneficios que ofrece la automatización. Querían una plataforma sólida y confiable que pudiera convertirse en la base para un mayor desarrollo, así como reducir los costos generales y aumentar la eficiencia.
Los sistemas distribuidos pueden ser difíciles de comprender y analizar, y Kubernetes no es una excepción. A pesar de sus muchos beneficios, identificamos varios cuellos de botella al migrar a CronJob , un sistema integrado en Kubernetes para realizar tareas repetitivas en un horario. En esta serie de dos partes, analizaremos los inconvenientes técnicos y operativos de Kubernetes CronJob cuando se utiliza en un proyecto grande y compartiremos con usted nuestra experiencia para superarlos.
Primero, describiremos las deficiencias de Kubernetes CronJobs que encontramos al usarlos en Lyft. Luego (en la segunda parte), le diremos cómo eliminamos estas deficiencias en la pila de Kubernetes, aumentamos la usabilidad y mejoramos la confiabilidad.
Parte 1. Introducción
¿Quién se beneficiará de estos artículos?
- Usuarios de Kubernetes CronJob.
- , Kubernetes.
- , Kubernetes .
- , Kubernetes , .
- Contributor' Kubernetes.
?
- , Kubernetes ( , CronJob) .
- , Kubernetes Lyft , .
:
- cron'.
- , CronJob, — , CronJob, Job' Pod', . CronJob Unix cron' .
- sidecar- , . Lyft sidecar- , runtime- Envoy, statsd .., sidecar-, , .
- ronjobcontroller — Kubernetes, CronJob'.
- , cron , ( ).
- Lyft Engineering , ( «», « », « ») — Lyft ( «», « », «» «»). , , «-» .
CronJob' Lyft
Hoy en día, nuestro entorno de producción multiinquilino tiene casi 500 trabajos cron que se llaman más de 1500 veces por hora.
Lyft utiliza ampliamente las tareas periódicas programadas para una variedad de propósitos. Antes de trasladarse a Kubernetes, se ejecutaban directamente en máquinas Linux utilizando cron Unix normal. Los equipos de desarrollo fueron responsables de redactar las
crontabdefiniciones y aprovisionar las instancias, que las ejecutaron utilizando las canalizaciones de Infraestructura como Código (IaC), y el equipo de infraestructura fue responsable de mantenerlas.
Como parte de un esfuerzo mayor para contener y migrar cargas de trabajo a nuestra propia plataforma Kubernetes, decidimos pasar a CronJob *, reemplazando el cron clásico de Unix con su contraparte de Kubernetes. Como muchos otros, se eligió Kubernetes por sus grandes ventajas (al menos en teoría), incluido el uso eficiente de los recursos.
Imagine una tarea cron que se ejecuta una vez a la semana durante 15 minutos. En nuestro antiguo entorno, la máquina dedicada a esta tarea estaría inactiva el 99,85% del tiempo. En el caso de Kubernetes, los recursos computacionales (CPU, memoria) se usan solo durante la llamada. El resto del tiempo, las capacidades no utilizadas se pueden utilizar para iniciar otros CronJob's, o simplemente reducirracimo. Dada la forma anterior de ejecutar trabajos cron, nos beneficiaríamos mucho si cambiamos a un modelo en el que los trabajos son efímeros.

Límites de responsabilidad para desarrolladores e ingenieros de plataforma en Lyft Stack
Después de migrar a la plataforma Kubernetes, los equipos de desarrollo dejaron de asignar y operar sus propias instancias informáticas. El equipo de la plataforma ahora es responsable de mantener y operar los recursos computacionales y las dependencias de tiempo de ejecución en la pila de Kubernetes. Además, es la responsable de crear los propios objetos CronJob. Los desarrolladores solo necesitan configurar el programa de tareas y el código de la aplicación.
Sin embargo, todo se ve bien en papel. En la práctica, hemos identificado varios cuellos de botella al migrar de un entorno cron de Unix tradicional bien estudiado a un entorno CronJob efímero y distribuido en Kubernetes.
* Aunque CronJob tenía y todavía tiene (a partir de Kubernetes v1.18) estado beta, nos pareció bastante satisfactorio para nuestras necesidades en ese momento y también encajaba perfectamente con el resto del kit de herramientas de infraestructura de Kubernetes que teníamos. ...
¿Cuál es la diferencia entre Kubernetes CronJob y Unix cron?
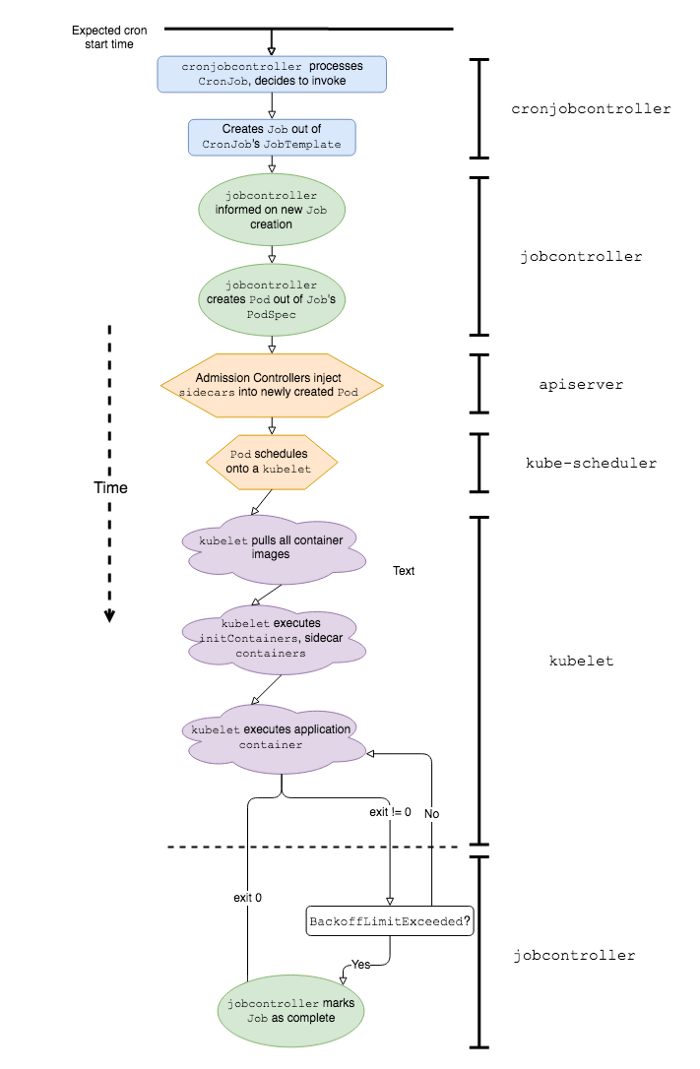
Una secuencia simplificada de eventos y componentes de software de K8 involucrados en el trabajo de Kubernetes CronJob
Para explicar mejor por qué trabajar con Kubernetes CronJob en un entorno de producción está asociado con ciertas dificultades, primero definamos en qué se diferencian del clásico. Se supone que CronJob funciona de la misma manera que los trabajos cron de Linux o Unix; sin embargo, en realidad existen al menos un par de diferencias importantes en su comportamiento: velocidad de inicio y manejo de fallas .
Velocidad de lanzamiento
El inicio diferido (inicio diferido) se define como el tiempo transcurrido desde el cron de inicio programado hasta el inicio real del código de la aplicación. En otras palabras, si el cron está programado para comenzar a las 00:00:00 y la aplicación comienza a ejecutarse a las 00:00:22, entonces el retraso en el inicio de ese cron en particular será de 22 segundos.
En el caso de los crons clásicos de Unix, el retraso de inicio es mínimo. Cuando sea el momento adecuado, estos comandos simplemente se ejecutan. Confirmemos esto con el siguiente ejemplo:
# date
0 0 * * * date >> date-cron.log
Con una configuración cron como esta, lo más probable es que obtengamos el siguiente resultado en
date-cron.log:
Mon Jun 22 00:00:00 PDT 2020
Tue Jun 23 00:00:00 PDT 2020
…
Por otro lado, Kubernetes CronJob puede experimentar retrasos significativos en el inicio porque la aplicación está precedida por una serie de eventos. Éstos son algunos de ellos:
-
cronjobcontrollerprocesa y decide llamar al CronJob; -
cronjobcontrollercrea un trabajo basado en la especificación del trabajo de CronJob; -
jobcontrolleradvierte un nuevo trabajo y crea un pod; - El controlador de admisión inserta los datos del contenedor del sidecar en la especificación del Pod *;
-
kube-schedulerplanificar un Pod en kubelet; -
kubeletlanza Pod (obteniendo todas las imágenes del contenedor); -
kubeletinicia todos los contenedores sidecar *; -
kubeletlanza el contenedor de aplicaciones *.
* Estas etapas son exclusivas de la pila de Lyft Kubernetes.
Hemos descubierto que los elementos 1, 5 y 7 hacen la contribución más significativa a la latencia una vez que alcanzamos una cierta escala de CronJob en Kubernetes.
Retraso causado por el trabajo cronjobcontroller'
Para comprender mejor de dónde proviene la latencia, examinemos el código fuente en línea
cronjobcontroller'. En Kubernetes 1.18, cronjobcontrollersolo verifica todos los CronJob cada 10 segundos y ejecuta algo de lógica en cada uno.
La implementación
cronjobcontroller'hace esto sincrónicamente al realizar al menos una llamada API adicional para cada CronJob. Cuando el número de CronJob excede un cierto número, estas llamadas a la API comienzan a sufrir restricciones del lado del cliente .
El ciclo de sondeo de 10 segundos y las llamadas a la API del lado del cliente conducen a un aumento significativo en el retraso del lanzamiento de CronJob.
Programación de grupos con crons
Debido a la naturaleza del programa cron, la mayoría de ellos se ejecutan al comienzo del minuto (XX: YY: 00). Por ejemplo, el
@hourlycron (por hora) se ejecuta a las 01:00:00, 02:00:00, etc. En el caso de una plataforma cron de múltiples inquilinos con muchos crons ejecutándose cada hora, cada cuarto de hora, cada 5 minutos, etc., esto conduce a cuellos de botella (hotspots) cuando se inician varios crons al mismo tiempo. En Lyft notamos que uno de esos lugares es el comienzo de la hora (XX: 00: 00). Estos hotspots crean una carga y conducen a una limitación adicional de la frecuencia de las solicitudes en los componentes de la capa de control involucrados en la ejecución del CronJob, como kube-schedulery kube-apiserver, lo que conduce a un aumento notable en el retraso de inicio.
Además, si no aprovisiona energía de cómputo para cargas máximas (y / o usa instancias de cómputo del servicio en la nube) y, en su lugar, usa el mecanismo de ajuste de escala automático del clúster para escalar dinámicamente los nodos, entonces el tiempo necesario para iniciar los nodos agrega una contribución adicional a la latencia de inicio. vainas CronJob.
Lanzamiento de pod: contenedores de ayuda
Una vez que el pod de CronJob se haya programado con éxito
kubelet, este último debería buscar y ejecutar las imágenes del contenedor de todos los sidecars y la aplicación en sí. Debido a las características específicas del lanzamiento de contenedores en Lyft (los contenedores con sidecar comienzan antes que los contenedores de aplicación), el retraso en el inicio de cualquier sidecar afectará inevitablemente el resultado, lo que provocará un retraso adicional en el inicio de la tarea.
Por lo tanto, las demoras en el inicio, antes de la ejecución del código de aplicación requerido, junto con una gran cantidad de CronJob en un entorno de múltiples inquilinos, conducen a demoras de inicio notables e impredecibles. Como veremos un poco más adelante, en la vida real, tal retraso puede afectar negativamente el comportamiento del CronJob, amenazando con perder lanzamientos.
Manejo de colisiones de contenedores
En general, se recomienda vigilar el trabajo de los crones. Para los sistemas Unix, esto es bastante fácil de hacer. Los viejos de Unix interpretan el comando dado usando el shell especificado
$SHELL, y después de que el comando sale (exitoso o no) esa llamada en particular se considera completa. Puede rastrear la ejecución de un cron en Unix usando un script simple como este:
#!/bin/sh
my-cron-command
exitcode=$?
if [[ $exitcode -ne 0 ]]; then
# stat-and-log is pseudocode for emitting metrics and logs
stat-and-log "failure"
else
stat-and-log "success"
fi
exit $exitcode
En el caso de Unix, cron
stat-and-logse ejecutará exactamente una vez por cada llamada cron, independientemente de $exitcode. Por lo tanto, estas métricas se pueden utilizar para organizar las notificaciones más simples sobre llamadas fallidas.
En el caso de Kubernetes CronJob, donde los reintentos en fallas se definen de forma predeterminada, y la falla en sí puede ser causada por varias razones (falla del trabajo o falla del contenedor), la supervisión no es tan simple y directa.
Usando un script similar en el contenedor de la aplicación y con los trabajos configurados para reiniciarse en caso de falla, CronJob intentará ejecutar la tarea en caso de falla, generando métricas y registros en el proceso, hasta que alcance BackoffLimit(número máximo de reintentos). Por lo tanto, un desarrollador que intente determinar la causa de un problema tendrá que ordenar una gran cantidad de "basura" innecesaria. Además, la alerta del script de shell en respuesta a la primera falla también puede resultar ser un ruido ordinario en el que es imposible basar acciones adicionales, ya que el contenedor de la aplicación puede recuperar y completar exitosamente la tarea por sí solo.
Puede implementar alertas a nivel de trabajo, en lugar de a nivel de contenedor de aplicación. Para ello, se encuentran disponibles métricas de nivel de API para errores de trabajos, como
kube_job_status_faileddesde kube-state-metrics. La desventaja de este enfoque es que el ingeniero de turno solo se da cuenta del problema después de que el trabajo alcanza la “etapa de falla final” y alcanza el límite BackoffLimit, lo que puede ocurrir mucho más tarde que la primera falla del contenedor de la aplicación.
CronJob'
Los ciclos de reinicio y retraso de inicio sustanciales introducen una latencia adicional que puede evitar que Kubernetes CronJob se vuelva a ejecutar. En el caso de CronJob que se llaman con frecuencia, o aquellos con tiempos de ejecución significativamente más largos que el tiempo de inactividad, este retraso adicional puede causar problemas con la próxima llamada programada. Si CronJob tiene una política
ConcurrencyPolicy: Forbidque prohíbe la simultaneidad , el retraso da como resultado que las llamadas futuras no se completen a tiempo y se retrasen.

Un ejemplo de una línea de tiempo (desde el punto de vista de un controlador cronjob) en la que se excede el valor de startDeadlineSeconds para un CronJob por hora específico: omite su inicio programado y no se llamará hasta la próxima hora programada
También hay un escenario más desagradable (lo encontramos en Lyft), debido a que CronJob puede omitir llamadas por completo; aquí es cuando CronJob está instalado
startingDeadlineSeconds. En este escenario, si se excede el retraso de inicio startingDeadlineSeconds, CronJob omitirá el inicio por completo.
Además, si
ConcurrencyPolicyCronJob está configurado en Forbid, el ciclo de reinicio en caso de falla de la llamada anterior también puede interferir con la siguiente llamada de CronJob.
Problemas con el funcionamiento de Kubernetes CronJob en condiciones del mundo real
Desde que comenzamos a migrar tareas de calendario repetitivas a Kubernetes, se ha descubierto que usar el mecanismo CronJob sin cambios conduce a momentos desagradables, tanto desde el punto de vista de los desarrolladores como desde el punto de vista del equipo de la plataforma. Desafortunadamente, comenzaron a negar los beneficios y beneficios por los que originalmente elegimos Kubernetes CronJob. Pronto nos dimos cuenta de que ni los desarrolladores ni el equipo de la plataforma tenían las herramientas necesarias a su disposición para explotar CronJob y comprender sus intrincados ciclos de vida.
Los desarrolladores intentaron explotar su CronJob y configurarlos, pero como resultado vinieron a nosotros con muchas quejas y preguntas como estas:
- ¿Por qué no funciona mi cron?
- Parece que mi cron ha dejado de funcionar. ¿Cómo puede confirmar que realmente se está ejecutando?
- No sabía que cron no estaba funcionando y pensé que todo estaba bien.
- ¿Cómo "arreglo" un cron que falta? No puedo simplemente iniciar sesión SSH y ejecutar el comando yo mismo.
- ¿Puede decir por qué este cron parece haberse perdido varias ejecuciones entre X y Y?
- Tenemos X (gran número) de crones, cada uno con sus propias notificaciones, y resulta bastante tedioso / difícil mantenerlos todos.
- Pod, Job, sidecar: ¿qué tontería es esta?
Como equipo de la plataforma , no pudimos responder preguntas como:
- ¿Cómo cuantificar el rendimiento de la plataforma cron de Kubernetes?
- ¿Cómo afectará la habilitación de CronJob adicionales a nuestro entorno de Kubernetes?
- Kubernetes CronJob' ( multi-tenant) single-tenant cron' Unix?
- Service-Level-Objectives (SLOs — ) ?
- , , , ?
La depuración de fallos de CronJob no es una tarea fácil. A menudo se necesita intuición para comprender dónde ocurren las fallas y dónde buscar pruebas. A veces, estas pistas son bastante difíciles de obtener, como, por ejemplo, los registros
cronjobcontroller', que se registran solo si se habilita el alto nivel de detalle. Además, los rastros pueden simplemente desaparecer después de un cierto período de tiempo, lo que hace que la depuración sea similar al juego "Kick a mole" (sobre esto , aproximadamente Transl.), Por ejemplo, Eventos de Kubernetes para CronJob, Jobs y Pods que por defecto solo se guardan durante una hora. Ninguno de estos métodos es fácil de usar y ninguno escala bien en términos de soporte a medida que crece el número de CronJob en la plataforma.
Además, a veces Kubernetes simplementedeja de intentar ejecutar el CronJob si se perdió demasiadas ejecuciones. En este caso, debe reiniciarse manualmente. En la vida real, esto sucede con mucha más frecuencia de lo que imagina, y la necesidad de solucionar el problema manualmente cada vez se vuelve bastante dolorosa.
Con esto concluye mi inmersión en los problemas técnicos y operativos que encontramos al usar Kubernetes CronJob en un proyecto ajetreado. En la segunda parte, hablaremos sobre cómo eliminamos Kubernetes en nuestra pila, mejoramos la usabilidad y mejoramos la confiabilidad de CronJob.
Parte 2. Introducción
Quedó claro que Kubernetes CronJob, sin cambios, no puede convertirse en un reemplazo simple y conveniente para sus contrapartes de Unix. Para transferir con confianza todas nuestras viejas a Kubernetes, necesitábamos no solo eliminar las deficiencias técnicas de CronJob, sino también mejorar su usabilidad . A saber:
1. Escuche a los desarrolladores para comprender las respuestas a las preguntas sobre las brujas que más les preocupan. Por ejemplo: ¿Ha comenzado mi cron? ¿Se ejecutó el código de la aplicación? ¿Fue exitoso el lanzamiento? ¿Cuánto tiempo se ejecutó el cron? (¿Cuánto tiempo tomó el código de la aplicación?)
2. Simplifique el mantenimiento de la plataforma haciendo que CronJob sea más comprensible, su ciclo de vida más transparente y los límites de la plataforma / aplicación más claros.
3. Complemente nuestra plataforma con métricas y alertas estándar para reducir la cantidad de configuración de alertas personalizadas y reducir la cantidad de enlaces cron duplicados que los desarrolladores tienen que escribir y mantener.
4. Desarrollar herramientas para una fácil recuperación de fallos y probar nuevas configuraciones de CronJob.
5. Solucione problemas técnicos de larga data en Kubernetes , como un error de TooManyMissedStarts que requiere intervención manual para solucionarlo y causa un bloqueo en un escenario de falla crítica ( cuando no se establece StartDeadlineSeconds ) que pasa desapercibido.
Decisión
Resolvimos todos estos problemas de la siguiente manera:
- (observability). CronJob', (Service Level Objectives, SLOs) .
- CronJob' « » Kubernetes.
- Kubernetes.
CronJob'

Un ejemplo de un panel generado por la plataforma para monitorear un CronJob específico
Hemos agregado las siguientes métricas a la pila de Kubernetes (están definidas para todos los CronJob en Lyft):
1.
started.count- este contador se incrementa cuando el contenedor de la aplicación se inicia por primera vez cuando se llama al CronJob. Ayuda a responder la pregunta: “ ¿Se ejecutó el código de la aplicación? ".
2.
{success, failure}.count- Estos contadores se incrementan cuando una llamada CronJob en particular alcanza el estado de terminal (es decir, el Trabajo ha terminado su trabajo y jobcontrollerya no intenta ejecutarlo). Responden a la pregunta: “ ¿Fue exitoso el lanzamiento? ".
3.
scheduling-decision.{invoke, skip}.count- estos contadoresle permiten conocer las decisiones que se toman cronjobcontrolleral llamar al CronJob. En particular, skip.countayuda a responder la pregunta: “ ¿Por qué no funciona mi cron? ". Las siguientes etiquetas actúan como sus parámetros reason:
-
reason = concurrencyPolicy-cronjobcontrollerperdió la llamada a CronJob, porque de lo contrario la romperíaConcurrencyPolicy; -
reason = missedDeadline- secronjobcontrollernegó a llamar a CronJob porque perdió la ventana de llamada especificada.spec.startingDeadlineSeconds; -
reason = errorEs un parámetro común para todos los demás errores que ocurren al intentar llamar a un CronJob.
4.
app-container-duration.seconds- Este temporizador mide la vida útil del contenedor de la aplicación. Ayuda a responder la pregunta: “ ¿Cuánto tiempo se ejecutó el código de la aplicación? ". En este temporizador, deliberadamente no incluimos el tiempo requerido para la programación de pods, lanzamiento de contenedores sidecar, etc., ya que son responsabilidad del equipo de la plataforma y están incluidos en el retraso de lanzamiento.
5.
start-delay.seconds- Este temporizador mide el retraso de inicio. Esta métrica, cuando se agrega a través de la plataforma, permite a los ingenieros que la mantienen no solo evaluar, monitorear y ajustar el rendimiento de la plataforma, sino que también sirve como base para determinar los SLO para parámetros como el retraso de inicio y la frecuencia máxima de programación cron.
Basándonos en estas métricas, hemos creado alertas predeterminadas. Notifican a los desarrolladores cuando:
- Su CronJob no comenzó según lo programado (
rate(scheduling-decision.skip.count) > 0); - Su CronJob falló (
rate(failure.count) > 0).
Los desarrolladores ya no necesitan definir sus propias alertas y métricas para crons en Kubernetes; la plataforma proporciona sus contrapartes listas para usar.
Ejecutando crons cuando sea necesario
Lo adaptamos
kubectl create job test-job --from=cronjob/<your-cronjob>a nuestra herramienta CLI interna. Los ingenieros de Lyft lo usan para interactuar con sus servicios en Kubernetes para llamar a CronJob cuando sea necesario para:
- recuperación de bloqueos intermitentes de CronJob;
- runtime- , 3:00 ( , CronJob', Job' Pod' ), — , ;
- runtime- CronJob' Unix cron', , .
TooManyMissedStarts
Hemos corregido un error con TooManyMissedStarts para que ahora los CronJob no se "cuelguen" después de 100 inicios consecutivos perdidos. Este parche no solo elimina la necesidad de intervención manual, sino que le permite realizar un seguimiento de cuándo se
startingDeadlineSeconds excede el tiempo . Gracias a Vallery Lancey por diseñar y construir este parche, a Tom Wanielista por ayudar a diseñar el algoritmo. Abrimos un PR para llevar este parche a la rama principal de Kubernetes (sin embargo, nunca se adoptó y se cerró debido a la inactividad, aproximadamente Transl.) .
Implementando monitoreo cron

¿En qué etapas del ciclo de vida de Kubernetes CronJob hemos agregado mecanismos para exportar métricas?
Alertas que no dependen de los horarios cron
La parte más complicada de implementar las notificaciones de llamadas cron perdidas es manejar sus horarios ( crontab.guru fue útil para descifrarlas ). Por ejemplo, considere el siguiente programa:
# 5
*/5 * * * *
Puede hacer que el contador para este incremento cron cada vez que salga (o usar un enlace cron ). Luego, en el sistema de notificación, puede escribir una expresión condicional del formulario: "Mira los 60 minutos anteriores y avísame si el contador aumenta en menos de 12". Problema resuelto, ¿verdad?
Pero, ¿qué pasa si su horario se ve así?
# 9 17
# .
# , (9-17, -)
0 9–17 * * 1–5
En este caso, tendrá que modificar la condición (aunque, tal vez, ¿su sistema tiene una función de notificación solo para el horario comercial?). Sea como fuere, estos ejemplos ilustran que las notificaciones vinculantes a las programaciones cron tienen varias desventajas:
- Cuando cambia el horario, debe realizar cambios en la lógica de notificación.
- Algunas programaciones cron requieren consultas bastante complejas para replicar utilizando series de tiempo.
- Es necesario que haya algún tipo de "período de espera" para los crones que no comienzan su trabajo exactamente a tiempo para minimizar los falsos positivos.
El paso 2 por sí solo hace que la generación de notificaciones por defecto para todas las viejas en la plataforma sea una tarea muy difícil, y el paso 3 es especialmente relevante para plataformas distribuidas como Kubernetes CronJob, en las que el retraso en el lanzamiento es un factor significativo. Además, existen soluciones que utilizan " interruptores de hombre muerto ", lo que nos vuelve a traer de nuevo a la necesidad de vincular la notificación al horario del cron, y / o algoritmos de detección de anomalías que requieren algo de entrenamiento y no funcionan inmediatamente para nuevos CronJob o cambios en su calendario.
Otra forma de ver el problema es preguntarse: ¿qué significa que cron debería haberse iniciado pero no lo hizo?
En Kubernetes, si te olvidas de los errores en
cronjobcontroller'o la posibilidad de una caída en el plano de control en sí (aunque debería ver esto inmediatamente si rastrea el estado del clúster correctamente) - esto significa que cronjobcontrollerel CronJob evaluó y decidió (de acuerdo con el horario del cron) que debería ser llamado, pero por alguna razón por la razón que decidí deliberadamente no hacerlo .
¿Suena familiar? ¡Esto es exactamente lo que hace nuestra métrica
scheduling-decision.skip.count! Ahora solo necesitamos hacer un seguimiento del cambio rate(scheduling-decision.skip.count)para notificar al usuario que su CronJob debería haberse activado, pero no fue así.
Esta solución desacopla el programa cron de la notificación en sí, lo que proporciona varios beneficios:
- Ahora no es necesario volver a configurar las alertas al cambiar los horarios.
- No hay necesidad de condiciones y solicitudes de tiempo complejas.
- Puede generar fácilmente alertas predeterminadas para todos los CronJob en la plataforma.
Esto, combinado con las otras series de tiempo y alertas mencionadas anteriormente, ayuda a crear una imagen más completa y comprensible del estado del CronJob.
Implementación de un temporizador de retardo de inicio
Debido a la naturaleza compleja del ciclo de vida de CronJob, necesitábamos pensar detenidamente sobre los puntos específicos del kit de herramientas en la pila para medir esta métrica de manera confiable y precisa. Como resultado, todo se redujo a fijar dos puntos en el tiempo:
- T1: cuándo debe iniciarse cron (según su programación).
- T2: cuando el código de la aplicación comienza a ejecutarse.
En este caso
start delay(retraso de inicio) = 2 — 1. Para arreglar el momento T1, incluimos el código en la lógica de llamada cron en el cronjobcontroller'. Registra la hora de inicio esperada como .metadata.Annotationlos objetos de trabajo que cronjobcontrollercrea cuando se llama al CronJob. Ahora se puede recuperar mediante cualquier cliente API mediante una solicitud normal GET Job.
Con T2 todo resultó más complicado. Dado que necesitamos que el valor sea lo más cercano al real posible , T2 debe coincidir con el momento en que se lanza por primera vez el contenedor con la aplicación . Si dispara T2 en cualquiercuando se inicia el contenedor (incluidos los reinicios), retrasar el lanzamiento en este caso incluirá el tiempo de ejecución de la aplicación. Por lo tanto, decidimos asignar otro
.metadata.Annotationobjeto de trabajo cada vez que descubrimos que el contenedor de la aplicación para un trabajo determinado recibió por primera vez un estado Running. Por lo tanto, en esencia, se creó un bloqueo distribuido y se ignoraron los inicios futuros del contenedor de la aplicación para este trabajo (solo se guardó el momento del primer inicio).
resultados
Después de implementar nuevas funciones y corregir errores, recibimos muchos comentarios positivos de los desarrolladores. Ahora, los desarrolladores que utilizan nuestra plataforma Kubernetes CronJob:
- ya no tendrá que preocuparse por sus propias herramientas de supervisión y alertas;
- , CronJob' , .. alert' , ;
- CronJob' , CronJob' « »;
- (
app-container-duration.seconds).
Además, los ingenieros de mantenimiento de la plataforma ahora tienen un nuevo parámetro ( retraso de inicio ) para medir la experiencia del usuario y el rendimiento de la plataforma.
Finalmente (y quizás nuestra mayor victoria), al hacer que CronJob (y sus estados) sean más transparentes y rastreables, hemos simplificado enormemente el proceso de depuración para desarrolladores e ingenieros de plataforma. Ahora pueden depurar juntos utilizando los mismos datos, por lo que a menudo sucede que los desarrolladores encuentran el problema por sí mismos y lo resuelven utilizando las herramientas proporcionadas por la plataforma.
Conclusión
Organizar tareas distribuidas y programadas no es fácil. CronJob Kubernetes es solo una forma de organizarlo. Aunque están lejos de ser ideales, los CronJob son bastante capaces de trabajar en proyectos globales, si, por supuesto, está dispuesto a invertir tiempo y esfuerzo en mejorarlos: aumentar la observabilidad, comprender las causas y las características específicas de las fallas y complementar con herramientas que faciliten su uso.
Nota: hay una propuesta de mejora de Kubernetes (KEP) abierta para corregir las deficiencias de CronJob y traducir su versión actualizada a GA.
Gracias a Rithu John , Scott Lau, Scarlett Perry , Julien Silland y Tom Wanielista por su ayuda en la revisión de esta serie de artículos.
PD del traductor
Lea también en nuestro blog: