
Con la transición al autoaislamiento en marzo de este año, nosotros, como muchas empresas, hemos movido todos nuestros eventos de comestibles en línea. Bueno, recuerdas esta maravillosa imagen sobre seminarios web con monos. Durante los últimos seis meses, solo en el tema de los centros de datos, del cual mi equipo es responsable, hemos acumulado alrededor de 25 seminarios web grabados de 2 horas, 50 horas de video en total. El problema que ha surgido en pleno crecimiento es cómo entender en qué vídeo buscar respuestas a determinadas preguntas. El catálogo, las etiquetas, una breve descripción están bien, bueno, finalmente encontramos que hay 4 videos de dos horas sobre el tema, ¿y luego qué? ¿Mirar en rebobinar? ¿Es posible de alguna manera diferente? ¿Y si actúas a la moda y tratas de arruinar la IA?
Spoiler para los impacientes : no pude encontrar un sistema milagroso completo o montarlo en mi rodilla, y entonces no tendría sentido en este artículo. Pero como resultado de varios días (o más bien noches) de investigación, obtuve un MVP en funcionamiento, del cual quiero hablarles. El propósito del artículo es observar el nivel de interés en el tema, obtener consejos de personas conocedoras y quizás encontrar a alguien más que tenga el mismo problema.
Lo que quiero hacer
A primera vista, todo parecía simple: toma un video, lo ejecuta a través de la red neuronal, obtiene un texto y luego busca un fragmento en el texto que describe el tema de interés. Sería aún más conveniente buscar todos los videos del catálogo a la vez. De hecho, se ha inventado para subir transcripciones del texto junto con los videos durante mucho tiempo, Youtube y la mayoría de plataformas educativas saben cómo hacerlo, aunque está claro que la gente allí edita estos textos. Puede escanear rápidamente el texto con los ojos y comprender si hay una respuesta a la pregunta deseada. Probablemente, desde una funcionalidad conveniente, no estaría de más poder pinchar en el lugar de interés en el texto y escuchar lo que el disertante dice y muestra allí, esto tampoco es difícil si hay un marcado de palabras en el tiempo, donde están en el texto. Bueno, estaba soñando con posibles direcciones de desarrollo, hablemos al final,y ahora intentemos simplemente implementar la cadena de la manera más eficiente posible
archivo de video -> fragmento de texto -> búsqueda de texto difuso .
Al principio pensé, dado que todo es tan simple, y este caso se ha discutido en todas las conferencias de IA durante 4 años, tales sistemas deberían existir listos para usar. Un par de horas de búsqueda y lectura de artículos demostraron que este no era el caso. El video se utiliza principalmente para buscar rostros, automóviles y otros objetos visuales (máscaras / cascos), y audio: canciones, pistas, así como el tono / entonación del hablante, como parte de las soluciones para centros de llamadas. Logramos encontrar solo esta mención del sistema Deepgram . Pero ella, lamentablemente, no tiene soporte para el idioma ruso. Además, Microsoft tiene una funcionalidad muy similar en Streams , pero en ninguna parte encontré una mención de soporte para el idioma ruso, aparentemente, tampoco está allí.
Ok, reinventemos. No soy un programador profesional (y, por cierto, aceptaré con gusto críticas constructivas sobre el código), pero de vez en cuando escribo algo “para mí”. Las redes neuronales que pueden convertir la voz en texto se denominan (sorpresa sorpresa), voz a texto . Si puede encontrar un servicio público de conversión de voz a texto, puede utilizarlo para "digitalizar" la voz en todos los seminarios web y luego realizar una búsqueda difusa en el texto, una tarea más sencilla. Confieso que al principio no pensé en "subirme a la nube", quería recopilar todo localmente, pero después de leer este artículo sobre Habré, decidí que el reconocimiento de voz se hace realmente mejor en la nube.
Buscando servicios en la nube para conversión de voz a texto
La búsqueda de servicios capaces de realizar conversión de voz a texto mostró que existen muchos de estos sistemas, incluidos los desarrollados en Rusia, también hay proveedores globales de nube como Google , Amazon , MS Azure entre ellos . Aquí encontrará descripciones de varios servicios, incluidos los de idioma ruso . En general, las primeras 20 líneas de los resultados del motor de búsqueda serán únicas. Pero hay otro inconveniente: me gustaría lanzar este sistema a producción en el futuro, esto es un costo y trabajo para Cisco, que a nivel mundial tiene contratos con nubes líderes. Entonces, de toda la lista, decidí considerar solo a ellos por ahora.
Entonces mi lista se ha reducido a Google , Amazon , Azure ,IBM Watson (los enlaces a los títulos son los mismos que en la tabla siguiente). Todos los servicios tienen API a través de las cuales se pueden utilizar. Después de analizar el resto de posibilidades, compilé una pequeña tabla:

IBM Watson dejó la carrera en esta etapa, ya que todas las grabaciones que tengo en ruso, se decidió probar al resto de proveedores en un breve extracto del webinar. Configuré cuentas en AWS y Azure. De cara al futuro, diré que Microsoft resultó ser un hueso duro de roer en términos de configuración de una cuenta. Trabajé desde una red corporativa que "aterriza" en Internet en algún lugar de Ámsterdam, durante el proceso de registro me preguntaron dos veces si estaba seguro de que mi dirección era Rusia, después de lo cual el sistema mostró un mensaje de que la cuenta estaba bloqueada administrativamente "pendiente de aclaración". ... Después de 5 días, mientras escribía este artículo, la situación no ha cambiado, por lo que aún no he podido probar Azure, ¡lo cual es una pena! Entiendo: seguridad, pero esto aún no me ha permitido probar el servicio. Intentaré hacer esto más tarde, cuando se resuelva la situación.
Por separado, me gustaría probar dicha función en Yandex.Cloud, su reconocimiento del habla rusa, en teoría, debería ser el mejor. Pero, desafortunadamente, en la página de acceso de prueba del servicio solo existe la posibilidad de "decir" el texto, no se proporciona la descarga del archivo. Entonces, pospondremos junto con Azure en segundo lugar.
Entonces, hay Google y Amazon, ¡probémoslo pronto! Antes de escribir cualquier código, puede verificar y comparar todo a mano, ambos proveedores, además de la API, tienen una interfaz administrativa. Para la prueba, primero preparé un fragmento de 10 minutos de carácter general, si es posible, con un mínimo de terminología especializada. Pero luego resultó que Google admite un fragmento de hasta 1 minuto en modo de prueba, así que utilicé este fragmento de 57 segundos para comparar servicios .
En base a los resultados del trabajo, ambos servicios emiten el texto reconocido, puede comparar los resultados de su trabajo en un intervalo de un minuto.
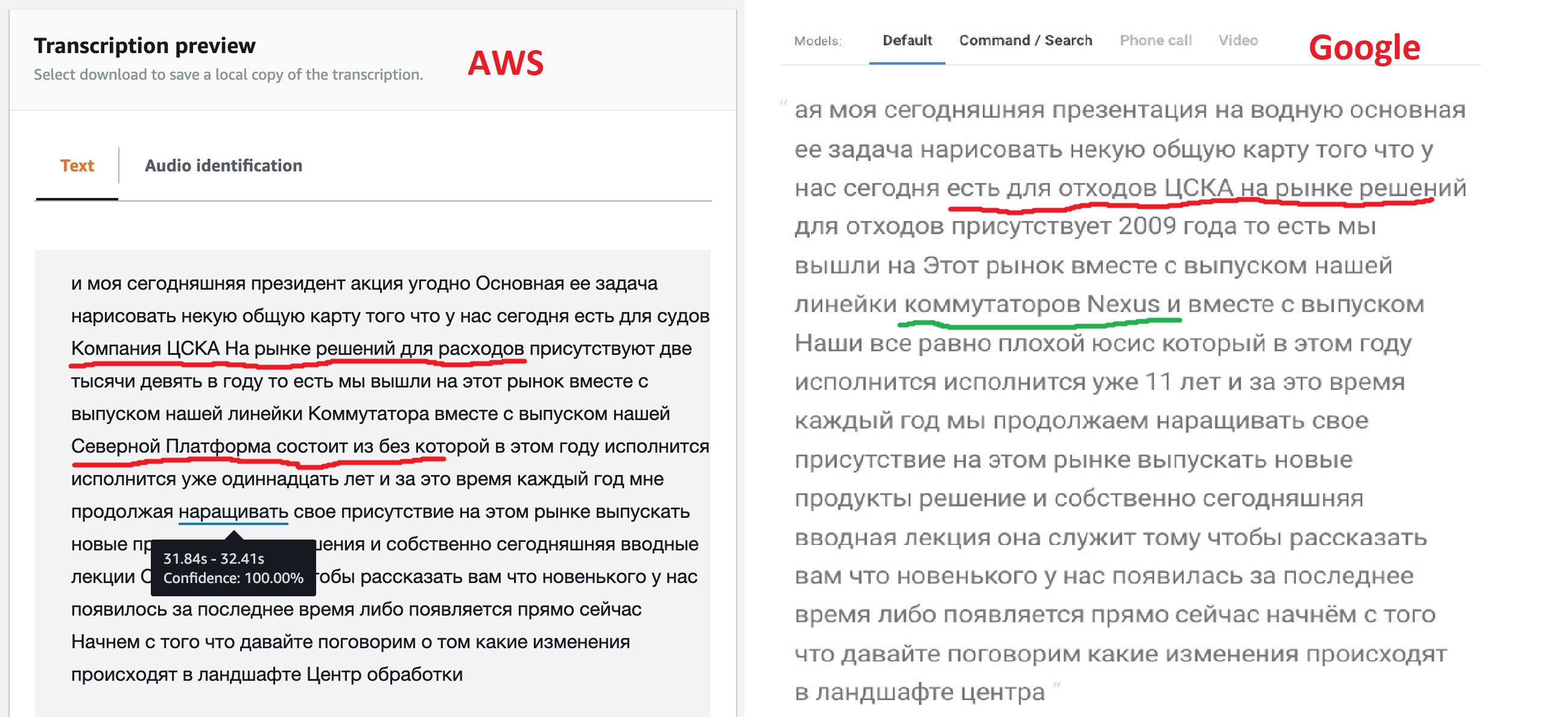
El resultado, francamente hablando, no es el esperado, pero no en vano los modelos brindan diferentes opciones para su personalización. Como podemos ver, el motor de Google "out of the box" reconoció la mayor parte del texto con mayor claridad, también logró ver los nombres de algunos productos, aunque no todos. Esto sugiere que su modelo permite texto multilingüe. Amazon (más tarde esto se confirmó) no tiene esa oportunidad - dijeron ruso, lo que significa que cantaremos: "Kin babe lom" y punto!
Pero la capacidad de etiquetar JSON que ofrece Amazon me pareció muy interesante. Después de todo, esto permitirá en el futuro implementar una transición directa a la parte del archivo donde se encontró el fragmento deseado. Quizás Google también tenga esa función, porque todas las redes neuronales de reconocimiento de voz funcionan de esta manera, pero una búsqueda superficial en la documentación no logró encontrar esta característica.

Al observar este JSON, puede ver que consta de tres secciones: el texto traducido (transcripción), una matriz de palabras (elementos) y un conjunto de segmentos (segmentos). Para una matriz de palabras y segmentos, para cada elemento, se indican sus horas de inicio y finalización, así como la confianza de la red neuronal de que lo reconoció correctamente.
Enseñar a una red neuronal a comprender los centros de datos
Entonces, al final de esta etapa, decidí elegir Amazon Transcribe para experimentos adicionales e intentar configurar un modelo de aprendizaje. Y si no puede lograr un reconocimiento estable, póngase en contacto con Google. Se llevaron a cabo más pruebas en un fragmento de 10 minutos.
AWS Transcribe tiene dos opciones para ajustar lo que reconoce la red neuronal y un par de funciones más para el posprocesamiento de texto:
- Custom Vocabularies – «» , , «» , . : «, , » Word 97- . , , .. .
- Custom Language Models – «» 10 . , . , , , .
- , , -. , – , .. -, .
Entonces, decidí hacer mi propia palabra para el texto. Obviamente, incluirá palabras como "red, servidores, perfiles, centro de datos, dispositivo, controlador, infraestructura". Después de 2-3 pruebas, mi vocabulario aumentó a 60 palabras. Este diccionario debe crearse en un archivo de texto normal, una palabra por línea, todo en mayúsculas. También hay una opción más compleja ( descrita aquí ) con la capacidad de especificar cómo se pronuncia la palabra, pero en la etapa inicial decidí hacerlo con una lista simple.
Antes de usar un diccionario, debe crearlo. En la pestaña Vocabulario personalizado en Amazon Transcribe, haga clic en Crear vocabulario , cargue el texto de nuestro archivo, especifique el idioma ruso, responda el resto de las preguntas y comienza el proceso de creación de un diccionario. Una vez que está fueraEl procesamiento pasa a estar listo : se puede usar el diccionario.
La pregunta sigue siendo: ¿cómo reconocer los términos "en inglés"? Permítame recordarle que el diccionario solo admite un idioma. Al principio pensé en crear un diccionario separado con términos en inglés y ejecutar el mismo texto en él. Cuando se detectan términos como Cisco , VLAN , UCSetc. c tasa de probabilidad 100% - tómelos para el fragmento de tiempo dado. Pero diré de inmediato: no funcionó, el analizador de idioma inglés no reconoció más de la mitad de los términos en el texto. Después de pensarlo, decidí que esto es lógico, ya que todos estos términos pronunciamos con "acento ruso", ni siquiera los angloamericanos nos entienden la primera vez. Esto llevó a la idea de simplemente agregar estos términos al diccionario ruso de acuerdo con el principio "como se escucha, así está escrito". Cisco , usies , eisiai , vilan , viikslan : después de todo, nosotros, con toda honestidad, lo decimos cuando nos comunicamos entre nosotros. Esto aumentó el diccionario en un par de docenas de palabras, pero mirando hacia el futuro, ¡mejoró la calidad del reconocimiento en un orden de magnitud!
Como dice el refrán, "un buen pensamiento viene después" , el primer diccionario ya está creado, así que decidí crear otro, agregando todas las abreviaturas y comparando lo que pasa.
Iniciar el reconocimiento con un diccionario es igual de sencillo, en el servicio Transcribir , en la pestaña Trabajo de transcripción , seleccione Crear trabajo , especifique el idioma ruso y no olvide especificar el diccionario que necesitamos. Otra acción útil: puede pedirle a la red neuronal que nos brinde varios resultados de búsqueda alternativos, el elemento Resultados alternativos : Sí , configuré 3 opciones alternativas. Más tarde, cuando haga búsquedas de texto difuso, esto será útil.
La transmisión de un fragmento de texto de 10 minutos toma de 4 a 5 minutos, para no perder el tiempo, decidí escribir una pequeña herramienta que facilitará el proceso de comparar los resultados. Mostraré el texto final del archivo JSON en el navegador, resaltando simultáneamente la “confiabilidad” de la detección de palabras individuales por la red neuronal (el mismo parámetro de confianza ). Tengo tres opciones para el texto resultante: la traducción predeterminada, un diccionario sin términos y un diccionario con términos. Deje que los tres textos se muestren simultáneamente en tres columnas. Destaco las palabras con confiabilidad superior al 95% en verde, del 95% al 70% en amarillo, por debajo del 70% en rojo. El código compilado apresuradamente de la página HTML resultante se encuentra a continuación, los archivos JSON deben estar en el mismo directorio que el archivo. Los nombres de archivo se especifican en las variables FILENAME1, etc.
Código de página HTML para ver resultados
<!DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8"> <title>Title</title> </head>
<body onload="initText()">
<hr> <table> <tr valign="top">
<td width="400"> <h2 >- </h2><div id="text-area-1"></div></td>
<td width="400"> <h2 > 1: / </h2><div id="text-area-2"></div></td>
<td width="400"> <h2 > 2: / </h2><div id="text-area-3"></div></td>
</tr> </table> <hr>
<style>
.known { background-image: linear-gradient(90deg, #f1fff4, #c4ffdb, #f1fff4); }
.unknown { background-image: linear-gradient(90deg, #ffffff, #ffe5f1, #ffffff); }
.badknown { background-image: linear-gradient(90deg, #feffeb, #ffffc2, #feffeb); }
</style>
<script>
// File names
const FILENAME1 = "1-My_CiscoClub_transcription_10min-1-default.json";
const FILENAME2 = '2-My_CiscoClub_transcription_10min-2-Russian_only.json';
const FILENAME3 = '3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json';
// Read file from disk and call callback if success
function readTextFile(file, textBlockName, callback) {
let rawFile = new XMLHttpRequest();
rawFile.overrideMimeType("application/json");
rawFile.open("GET", file, true);
rawFile.onreadystatechange = function() {
if (rawFile.readyState === 4 && rawFile.status == "200") {
callback(textBlockName, rawFile.responseText);
}
};
rawFile.send(null);
}
// Insert text to text block and color words confidence level
function updateTextBlock(textBlockName, text) {
var data = JSON.parse(text);
let translatedTextList = data['results']['items'];
const listLen = translatedTextList.length;
const textBlock = document.getElementById(textBlockName);
for (let i=0; i<listLen; i++) {
let addWord = translatedTextList[i]['alternatives'][0];
// load word probability and setup color depends on it
let wordProbability = parseFloat(addWord['confidence']);
let wordClass = 'unknown';
// setup the color
if (wordProbability > 0.95) {
wordClass = 'known';
} else if (wordProbability > 0.7) {
wordClass = 'badknown';
}
// insert colored word to the end of block
let insText = '<span class="' + wordClass+ '">' + addWord['content'] + ' </span>';
textBlock.insertAdjacentHTML('beforeEnd', insText)
}
}
function initText() {
// read three files each to it's area
readTextFile(FILENAME1, "text-area-1", function(textBlockName, text){
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME2, "text-area-2", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME3, "text-area-3", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
}
</script>
</body></html>
Descargo los archivos asrOutput.json para las tres tareas, les cambio el nombre como están escritos en el script HTML, y esto es lo que sucede.

Se ve claramente que la adición de términos en ruso permitió a la red neuronal reconocer con mayor precisión términos específicos: " perfil de servicio ", etc. Y la incorporación de la transcripción rusa en el segundo paso convirtió CSKA en cisco . El texto todavía está bastante "sucio", pero para mi tarea de búsqueda de contexto ya debería ser adecuado. A medida que se agregan y leen nuevos seminarios web, el vocabulario se expandirá gradualmente, este es un proceso de mantenimiento de un sistema que no debe olvidarse.
Búsqueda difusa en texto reconocido
Probablemente hay una docena de enfoques para resolver el problema de la búsqueda difusa, en su mayor parte se basan en un pequeño conjunto de algoritmos matemáticos, como, por ejemplo, la distancia de Levenshtein. buen artículo sobre esto , uno más y uno más . Pero quería encontrar algo listo, como lanzado y funciona.
A partir de soluciones listas para usar para la búsqueda de documentos locales, después de una pequeña investigación, encontré un proyecto SPHINX relativamente antiguo , y la posibilidad de búsqueda de texto completo, al parecer, está en PostgreSQL, está escrito sobre ello AQUÍ . Pero la mayoría de los materiales, incluso en ruso, se encontraron sobre Elasticsearch . Después de leer buenas guías de puesta en marcha y configuración comoEsta publicación o esta lección , aquí hay otra , así como la documentación y la guía de API para Python , decidí usarla.
Para todos los experimentos locales, he estado usando Docker durante mucho tiempo , y recomiendo encarecidamente a todos los que, por alguna razón, aún no lo hayan descubierto, que lo hagan. De hecho, trato de no ejecutar nada más que entornos de desarrollo, navegadores y "visores" en el sistema operativo local. Aparte de la ausencia de problemas de compatibilidad, etc. esto le permite probar rápidamente un nuevo producto y ver si funciona bien.
Descargamos el contenedor con Elasticsearch y lo ejecutamos con dos comandos:
$ docker pull elasticsearch:7.9.1
$ docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.1
Después de iniciar el contenedor,
http://localhost:9200la interfaz elástica aparece en la dirección , se puede acceder a ella usando un navegador o la API REST de una herramienta POSTMAN. Pero encontré un complemento de Chrome útil .
Así es como se ve la ventana del complemento con el ejemplo sobre gatitos divertidos descrito en una de las guías anteriores .
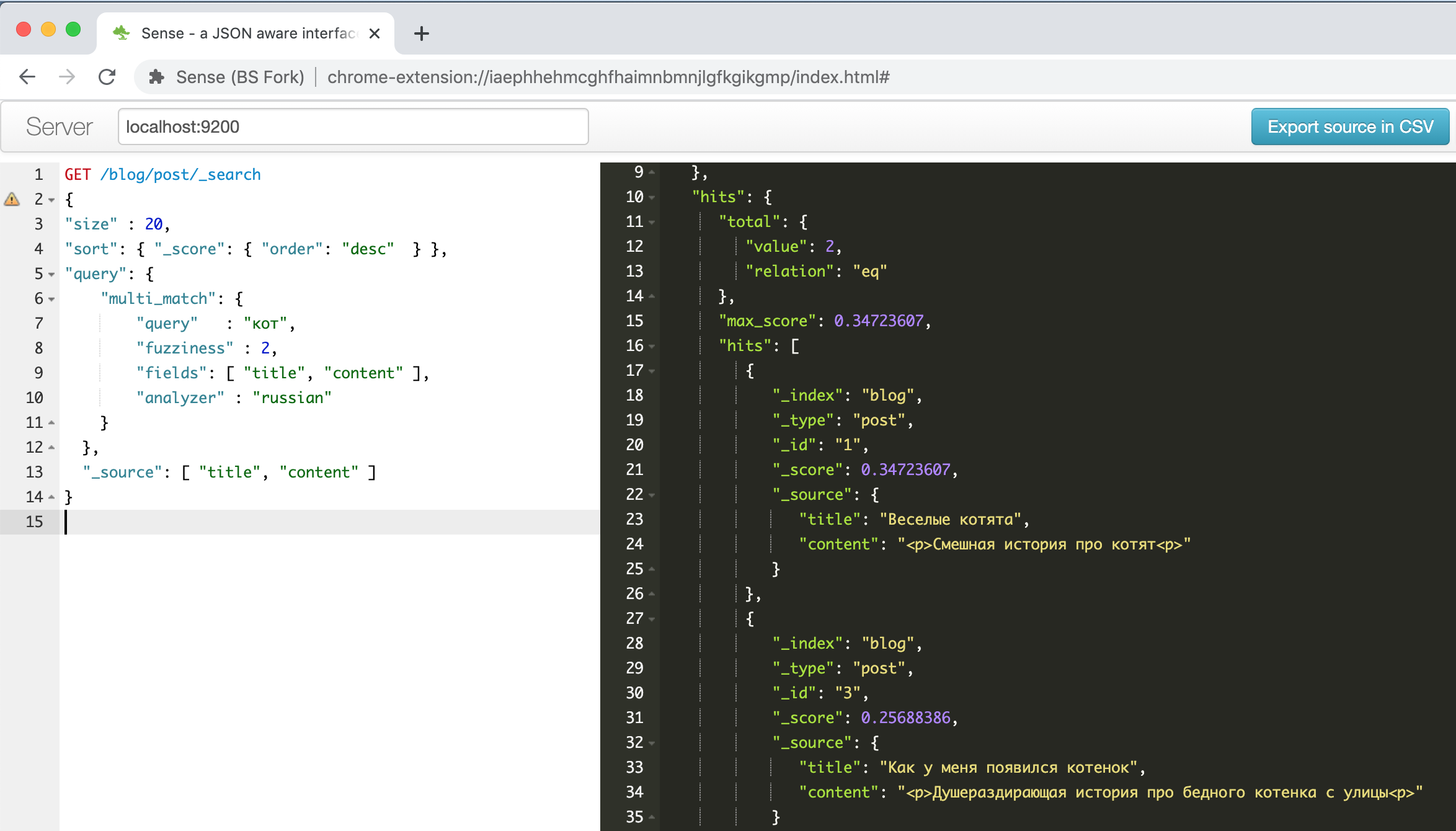
A la izquierda hay una consulta; a la derecha hay una respuesta, autocompletar, resaltado de sintaxis, autoformato, ¡qué más se necesita para ser productivo! Además, este complemento puede reconocer el formato de línea de comando CURL en el texto pegado desde el portapapeles y formatearlo correctamente, por ejemplo, intente pegar la línea
" curl -X GET $ ES_URL " y vea qué sucede. Algo útil, en general.
¿Qué y cómo almacenaré y buscaré?Elasticsearch toma todos los documentos JSON y los almacena en estructuras llamadas índices. Puede haber tantos índices diferentes como desee, pero un índice puede contener datos y documentos homogéneos con una estructura de campos similar y el mismo enfoque de búsqueda.
Para investigar las posibilidades de la búsqueda difusa, decidí descargar y buscar la sección de frases (segmentos) del archivo de transcripción obtenido en el paso anterior. En la sección de segmentos del archivo JSON, los datos se almacenan en el siguiente formato:
- 1 (segment)
-> /
->
--> 1
---->
----> , (confidence)
--> 2
---->
----> , (confidence)
Quiero aumentar la probabilidad de una búsqueda exitosa, por lo que cargaré todas las opciones alternativas a la base de datos para la búsqueda y luego seleccionaré la que tenga mayor confianza total de los fragmentos encontrados.
Para reformatear y cargar un documento JSON en Elasticsearch, utilizo un pequeño script de Python, la lógica del script es la siguiente:
- Primero, revisamos todos los elementos de la sección de segmentos y todas las opciones de transcripción alternativas
- Para cada opción de transcripción, consideramos su total confianza en el reconocimiento, solo tomo la media aritmética para palabras individuales, aunque, probablemente, en el futuro esto deba abordarse con más cuidado.
- Para cada opción de transcripción alternativa, cargue un registro del formulario en Elasticsearch
{ "recording_id" : < >, "seg_id" : <id >, "alt_id" : <id >, "start_time" : < >, "end_time" : < >, "transcribe_score" : < (confidence) >, "transcript" : < > }
Script de Python que carga registros de un archivo JSON en Elasticsearch
from elasticsearch import Elasticsearch
import json
from statistics import mean
#
TRANCRIBE_FILE_NAME = "3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json"
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
es.indices.create(index=INDEX_NAME) # Create index for our recordings
# Open and load file
res = None
with open(TRANCRIBE_FILE_NAME) as json_file:
data = json.load(json_file)
res = data['results']
#
index = 1
for idx, seq in enumerate(res['segments']):
# enumerate fragments
for jdx, alt in enumerate(seq['alternatives']):
# enumerate alternatives for each segments
score_list = []
for item in alt['items']:
score_list.append( float(item['confidence']))
score = mean(score_list)
obj = {
"recording_id" : "rec_1",
"seg_id" : idx,
"alt_id" : jdx,
"start_time" : seq["start_time"],
"end_time" : seq ["end_time"],
"transcribe_score" : score,
"transcript" : alt["transcript"]
}
es.index( index=INDEX_NAME, id = index, body = obj )
index += 1
Si no tiene Python, no se desanime, Docker nos ayudará nuevamente. Por lo general, uso un contenedor con un cuaderno Jupyter: puede conectarse a él con un navegador normal y hacer lo que tenga que hacer, lo único que debe pensar en guardar los resultados, ya que toda la información se pierde cuando se destruye el contenedor. Si no ha trabajado con esta herramienta antes, entonces aquí hay un buen artículo para principiantes , por cierto, puede omitir con seguridad la sección sobre instalación.Comenzamos
un contenedor con un cuaderno de Python con el comando:
$ docker run -p 8888:8888 jupyter/base-notebook sh -c 'jupyter notebook --allow-root --no-browser --ip=0.0.0.0 --port=8888'
Y nos conectamos a él con cualquier navegador en la dirección que vemos en la pantalla después del lanzamiento exitoso del script, esto es
http://127.0.0.1:8888con la clave de seguridad especificada.
Creamos un nuevo cuaderno, en la primera celda escribimos:
!pip install elasticsearch
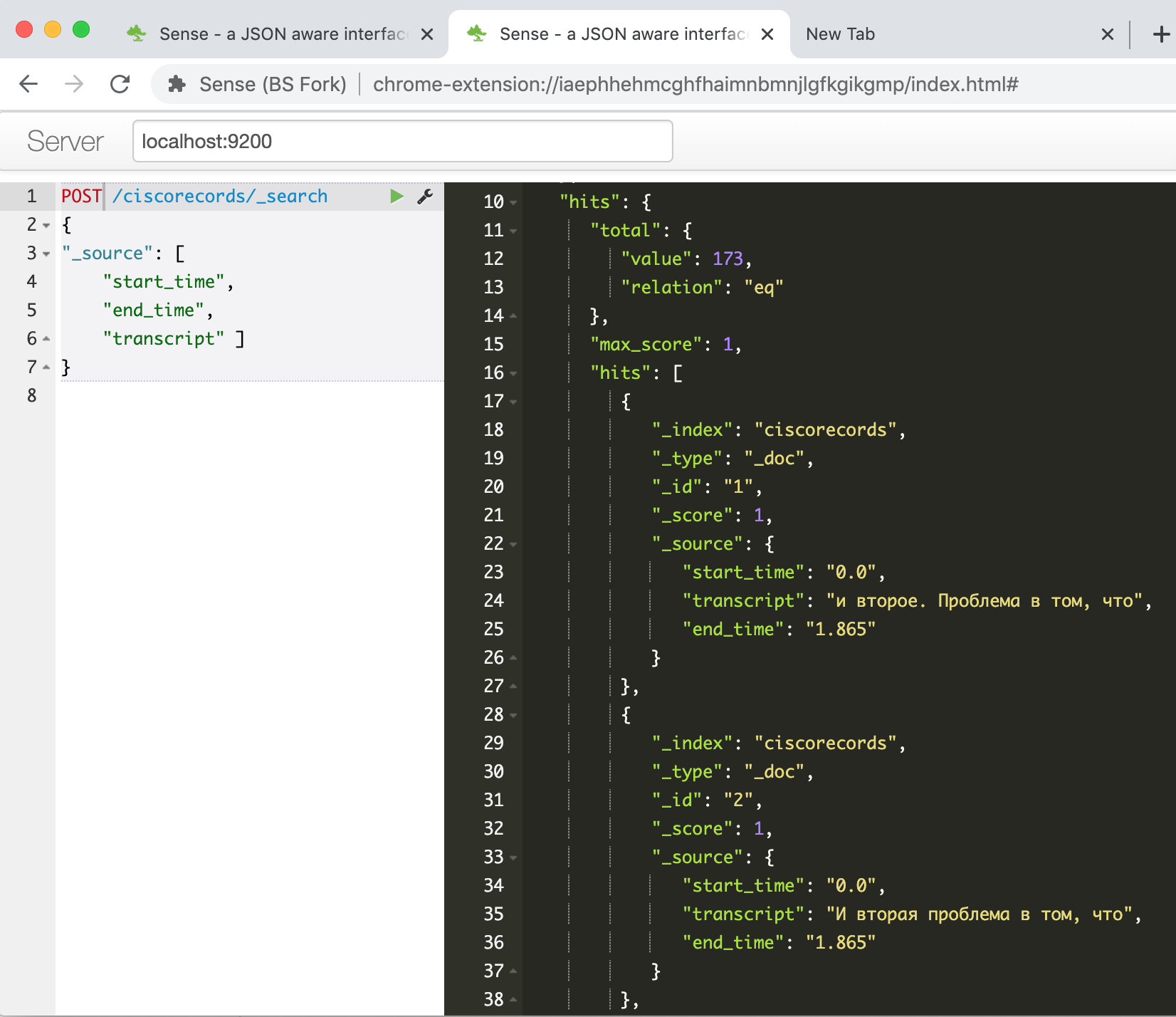
Ejecutar, esperar hasta que se instale el paquete para trabajar con ES a través de la API, copiar nuestro script en la segunda celda y ejecutarlo. Después de su trabajo, si todo sale bien, podemos comprobar en la consola de Elasticsearch que nuestros datos se han cargado correctamente. Ingresamos el comando
GET /ciscorecords/_searchy vemos nuestros registros cargados en la ventana de respuesta, un total de 173 piezas, como nos dice el campo hits.total.value .
Ahora es el momento de probar la búsqueda difusa, de eso se trata. Por ejemplo, para buscar la frase "núcleo de la red del centro de datos", debe dar el siguiente comando:
POST /ciscorecords/_search
{
"size" : 20,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : " ",
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
"_source": [ "transcript", "transcribe_score" ]
}
¡Obtenemos hasta 47 resultados!

No es de extrañar, ya que la mayoría de ellos son variaciones diferentes del mismo fragmento. Escribamos otro script para seleccionar de cada segmento un registro con el valor de confianza más alto.
Script de Python para consultar la base de datos Elasticsearch
#####
#
# PHRASE = " "
# PHRASE = " "
PHRASE = " "
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
#
elastic_queary = {
"size" : 40,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : PHRASE,
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
}
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
#
res = es.search(index=INDEX_NAME, body = elastic_queary)
print ("Got %d Hits:" % res['hits']['total']['value'])
#
search_results = {}
for hit in res['hits']['hits']:
seg_id = hit["_source"]['seg_id']
if seg_id not in search_results or search_results[seg_id]['score'] < hit["_score"]:
_res = hit["_source"]
_res["score"] = hit["_score"]
search_results[seg_id] = _res
print ("%s unique results \n-----" % len(search_results))
for rec in search_results:
print ("seg %(seg_id)s: %(score).4f : start(%(start_time)s)-end(%(end_time)s) -- %(transcript)s" % \
(search_results[rec]))
Ejemplo de salida:
Got 47 Hits:
16 unique results
-----
seg 39: 7.2885 : start(374.24)-end(377.165) -- , ..
seg 49: 7.0923 : start(464.44)-end(468.065) -- , ...
seg 41: 4.5401 : start(385.14)-end(405.065) -- . , , , , , ...
seg 30: 4.3556 : start(292.74)-end(298.265) -- , , ,
seg 44: 2.1968 : start(415.34)-end(426.765) -- , , , . -
seg 48: 2.0587 : start(449.64)-end(464.065) -- , , , , , .
seg 26: 1.8621 : start(243.24)-end(259.065) -- . . , . ...
Vemos que los resultados se han vuelto mucho más pequeños, y ahora podemos visualizarlos y seleccionar el que más nos interese.
Además, dado que tenemos la hora de inicio y finalización del fragmento de video, podemos crear una página con un reproductor de video y "rebobinarla" programáticamente hasta el fragmento de interés.
Pero pondré esta tarea en un artículo separado si hay interés en más publicaciones sobre este tema.
En lugar de una conclusión
Entonces, en el marco de este artículo, mostré cómo resolví el problema de construir un sistema de búsqueda de texto usando una herramienta de video con grabaciones de webinars sobre temas técnicos. El resultado es lo que se suele llamar MVP, es decir el algoritmo de trabajo mínimo que le permite obtener un resultado y demuestra que el resultado es, en principio, alcanzable con las tecnologías existentes.
Todavía queda un largo camino por recorrer hasta el producto final, a partir de ideas que se pueden implementar en un futuro próximo:
- Atornille el reproductor de video para que pueda escuchar, ver el fragmento encontrado
- Piense en la posibilidad de edición de texto, mientras puede dejar un ancla al texto de palabras reconocidas al 100%, editar solo fragmentos donde la calidad del reconocimiento "se hunde"
- elasticsearch, -
- speech-to-text, Google, Yandex, Azure. –
- , «»
- BERT (Bi-directional Encoder Representation from Transformer), . – « xx yy».
- , - - . Youtube , 15-20 , ,
- – , , ,
Si tiene alguna pregunta o comentario, estaré encantado de responderlos y también estaré encantado de escuchar cualquier sugerencia para mejorar o simplificar el proceso en su conjunto. Este es mi primer artículo técnico para Habr, realmente espero que haya resultado útil e interesante.
¡Buena suerte a todos en su búsqueda creativa y que la Fuerza esté con ustedes!