
¿Qué son las métricas cortas y largas?
Los modelos de ranking intentan estimar la probabilidad de que el usuario interactúe con la noticia (publicación): le prestará atención, marcará “Me gusta”, escribirá un comentario. El modelo luego distribuye los registros en orden descendente de esta probabilidad. Por tanto, al mejorar el ranking, podemos conseguir un incremento en el CTR (click-through rate) de las acciones del usuario: me gusta, comentarios y otros. Estas métricas son muy sensibles a los cambios en el modelo de clasificación. Los llamaré cortos .
Pero hay otro tipo de métricas. Se cree, por ejemplo, que el tiempo que pasa en la aplicación, o el número de sesiones del usuario, reflejan mucho mejor su actitud hacia el servicio. Llamaremos largas a esas métricas .
Optimizar métricas largas directamente a través de algoritmos de clasificación no es una tarea trivial. Con métricas cortas, esto es mucho más fácil: el CTR de Me gusta, por ejemplo, está directamente relacionado con qué tan bien estimamos su probabilidad. Pero si conocemos las relaciones causales (o causales) entre métricas cortas y largas, entonces podemos enfocarnos en optimizar solo aquellas métricas cortas que de manera predecible deberían afectar a las largas. Traté de extraer tales conexiones causales, y escribí sobre ello en mi trabajo, que completé como un diploma en la Licenciatura en Ciencias (CT) de ITMO. Realizamos la investigación en el laboratorio de Machine Learning de ITMO junto con VKontakte.
Enlaces a código, conjunto de datos y sandbox
Puedes encontrar todo el código aquí: AnverK .
Para analizar las relaciones entre las métricas, usamos un conjunto de datos que incluye los resultados de más de 6,000 pruebas A / B reales que fueron realizadas por el equipo de VK en varios momentos. El conjunto de datos también está disponible en el repositorio .
En la caja de arena, puede ver cómo usar el contenedor propuesto: en datos sintéticos .
Y aquí, cómo aplicar algoritmos a un conjunto de datos: en el conjunto de datos propuesto .
Tratar con correlaciones falsas
Puede parecer que para solucionar nuestro problema basta con calcular las correlaciones entre las métricas. Pero esto no es del todo cierto: la correlación no siempre es causalidad. Digamos que medimos solo cuatro métricas y sus relaciones causales se ven así:

Sin pérdida de generalidad, supongamos que hay una influencia positiva en la dirección de la flecha: cuantos más me gusta, más SPU. En este caso, será posible establecer que los comentarios en la foto tienen un efecto positivo en la SPU. Y decida que si "aumenta" esta métrica, el SPU aumentará. Este fenómeno se llama falsa correlación.: El coeficiente de correlación es bastante alto, pero no existe una relación causal. Las correlaciones falsas no se limitan a dos efectos de la misma causa. De la misma columna, se podría llegar a la conclusión errónea de que los Me gusta tienen un efecto positivo en la cantidad de aperturas de fotos.
Incluso con un ejemplo tan simple, resulta obvio que un simple análisis de correlaciones conducirá a muchas conclusiones erróneas. La inferencia causal (métodos de inferencia de relaciones) permite restaurar las relaciones causales a partir de los datos. Para aplicarlos en la tarea, hemos elegido los algoritmos de inferencia causal más adecuados, implementamos interfaces de Python para ellos y también agregamos modificaciones de algoritmos conocidos que funcionan mejor en nuestras condiciones.
Algoritmos clásicos para enlaces de inferencia
Hemos considerado varios métodos de inferencia causal: PC (Peter y Clark), FCI (Fast Causal Inference) y FCI + (similar a FCI desde un punto de vista teórico, pero mucho más rápido). Puede leer sobre ellos en detalle en estas fuentes:
- Causalidad (J. Pearl, 2009),
- Causalidad, predicción y búsqueda (P. Spirtes et al., 2000),
- Aprender modelos causales dispersos no es NP-difícil (T. Claassen et al., 2013).
Pero es importante comprender que el primer método (PC) supone que observamos todas las cantidades que afectan a dos o más métricas; esta hipótesis se llama Suficiencia Causal. Los otros dos algoritmos toman en cuenta que puede haber factores no observables que afecten las métricas monitoreadas. Es decir, en el segundo caso, la representación causal se considera más natural y permite la presencia de factores inobservables.:

Todas las implementaciones de estos algoritmos se proporcionan en la biblioteca pcalg . Es hermoso y flexible, pero con un "inconveniente": está escrito en R (cuando se desarrollan las funciones más pesadas desde el punto de vista informático, se utiliza el paquete RCPP). Por lo tanto, para los métodos anteriores, escribí contenedores en la clase CausalGraphBuilder, agregando ejemplos de su uso.
Describiré los contratos de la función de inferencia de enlaces, es decir, la interfaz y el resultado que se puede obtener en la salida. Puede aprobar una función de prueba de independencia condicional. Esta es una prueba como esta que vuelve bajo la hipótesis nula de que las cantidades y condicionalmente independiente para un conjunto conocido de cantidades ... El valor predeterminado es una prueba de correlación parcial . Elegí la función con esta prueba porque es la predeterminada en pcalg y está implementada en RCPP, lo que la hace rápida en la práctica. También puedes transferir, a partir del cual los vértices se considerarán dependientes. Para los algoritmos de PC y FCI, también puede establecer el número de núcleos de CPU, si no necesita escribir un registro de la operación de la biblioteca. No existe tal opción para FCI +, pero recomiendo usar este algoritmo en particular: gana en velocidad. Otra advertencia: FCI + actualmente no es compatible con el algoritmo de orientación de bordes propuesto; el punto está en las limitaciones de la biblioteca pcalg.
Con base en los resultados del trabajo de todos los algoritmos, se construye un PAG (gráfico ancestral parcial) en forma de lista de aristas. Con el algoritmo de PC, debe interpretarse como un gráfico causal en el sentido clásico (o red bayesiana): un borde orientado desde a , significa influencia en ... Si el borde no es direccional o bidireccional, entonces no podemos orientarlo de forma única, lo que significa:
- o los datos disponibles son insuficientes para establecer una dirección,
- o es imposible, porque el verdadero gráfico causal, utilizando solo datos observables, solo puede establecerse hasta una clase de equivalencia.
Los algoritmos FCI también darán como resultado PAG, pero aparecerá un nuevo tipo de bordes en él, con una "o" al final. Esto significa que la flecha puede estar ahí o no. En este caso, la diferencia más importante entre los algoritmos FCI y la PC es que un borde bidireccional (con dos flechas) deja en claro que los vértices que conecta son consecuencia de algún vértice no observable. En consecuencia, un borde doble en el algoritmo de PC ahora parece un borde con dos extremos "o". Hay una ilustración para tal caso en la caja de arena con ejemplos sintéticos.
Modificar el algoritmo de orientación del borde
Los métodos clásicos tienen un inconveniente importante. Admiten que puede haber factores desconocidos, pero al mismo tiempo se basan en otra suposición demasiado seria. Su esencia es que la función de probar la independencia condicional debe ser perfecta. De lo contrario, el algoritmo no es responsable de sí mismo y no garantiza ni la corrección ni la integridad del gráfico (el hecho de que no se pueden orientar más bordes sin violar la corrección). ¿Conoce muchas pruebas de independencia condicional de muestras finitas ideales? Yo no.
A pesar de este inconveniente, los esqueletos de gráficos se construyen de manera bastante convincente, pero están orientados de manera demasiado agresiva. Entonces sugerí una modificación al algoritmo de orientación de bordes. Bono: le permite ajustar implícitamente el número de bordes orientados. Para explicar claramente su esencia, sería necesario hablar aquí en detalle sobre los algoritmos para la derivación de vínculos causales. Por lo tanto, adjuntaré la teoría de este algoritmo y la modificación propuesta por separado; un enlace al material estará al final de la publicación.
Comparar modelos - 1: Estimación de probabilidad de gráficos
Curiosamente, una de las serias dificultades para derivar vínculos causales es la comparación y evaluación de modelos. ¿Como paso? El caso es que, por lo general, se desconoce la verdadera representación causal de los datos reales. Además, no podemos conocerlo en términos de distribución con tanta precisión como para generar datos reales a partir de él. Es decir, se desconoce la verdad básica para la mayoría de los conjuntos de datos. Por lo tanto, surge un dilema: utilice datos (semi) sintéticos con una verdad fundamental conocida, o intente prescindir de la verdad fundamental, pero pruebe con datos reales. En mi trabajo, intenté implementar dos enfoques para realizar pruebas.
El primero es la estimación de probabilidad del gráfico:

Aquí - muchos padres de vértice , - información conjunta de cantidades y y Es la entropía de la cantidad ... De hecho, el segundo término no depende de la estructura del gráfico, por lo tanto, como regla, solo se considera el primero. Pero puede ver que la probabilidad no disminuye con la adición de nuevos bordes; esto debe tenerse en cuenta al comparar.
Es importante comprender que dicha evaluación solo funciona para comparar redes bayesianas (salida del algoritmo de PC), porque en los PAG reales (salida de los algoritmos FCI, FCI +), los bordes dobles tienen semánticas completamente diferentes.
Por lo tanto, comparé la orientación de los bordes con mi algoritmo y la PC clásica: la
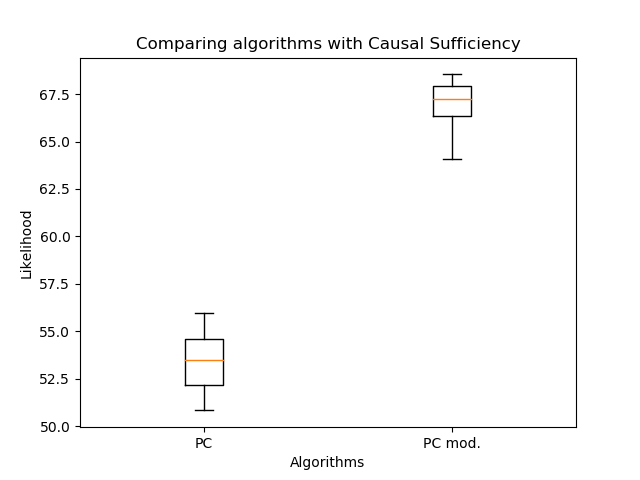
orientación modificada de los bordes permitió un aumento significativo en la probabilidad en comparación con el algoritmo clásico. Pero ahora es importante comparar el número de aristas:
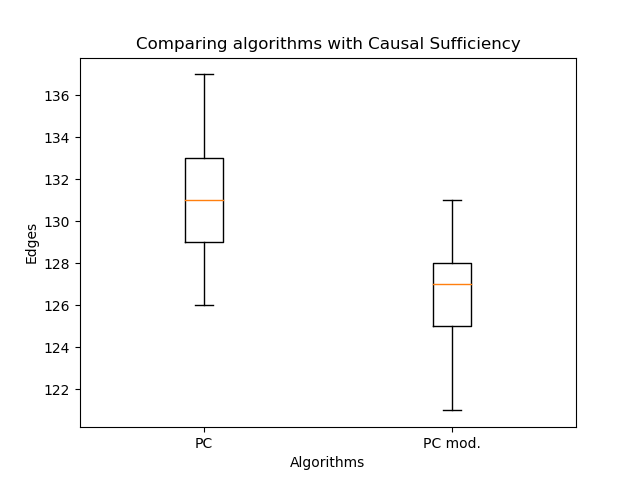
Hay incluso menos de ellos, esto es lo esperado. Por lo tanto, incluso con menos bordes, es posible restaurar una estructura de gráfico más plausible. Aquí podría argumentar que la probabilidad no disminuye con el número de aristas. El punto es que el gráfico resultante en el caso general no es un subgráfico del gráfico obtenido por el algoritmo de PC clásico. Pueden aparecer aristas dobles en lugar de aristas simples, y las aristas simples pueden cambiar de dirección. ¡Así que no hay impedimentos!
Comparación de modelos - 2: uso de un enfoque de clasificación
Pasemos a la segunda forma de comparación. Usaremos el algoritmo de PC para construir un gráfico causal y seleccionar un gráfico acíclico aleatorio de él. Después de eso, generaremos los datos en cada vértice como una combinación lineal de los valores en los vértices principales con los coeficientescon la adición de ruido gaussiano. Tomé la idea para esa generación del artículo "Hacia un descubrimiento causal robusto y versátil para aplicaciones comerciales" (Borboudakis et al., 2016). Los vértices que no tienen padres se generaron a partir de una distribución normal, con parámetros como en el conjunto de datos para el vértice correspondiente.
Cuando se reciben los datos, les aplicamos los algoritmos que queremos evaluar. Además, ya tenemos un verdadero gráfico causal. Solo queda por entender cómo comparar los gráficos resultantes con el verdadero. En "Reconstrucción robusta de modelos gráficos causales basada en información condicional de 2 y 3 puntos" (Affeldt et al., 2015), se sugirió utilizar terminología de clasificación. Asumiremos que la arista dibujada es una clase Positiva y la que no está dibujada es Negativa. Entonces verdadero positivo () Es cuando hemos dibujado el mismo borde que en el gráfico causal verdadero, y falso positivo () - si se dibuja un borde que no está en el gráfico causal verdadero. Evaluaremos estos valores desde el punto de vista del esqueleto.
Para tener en cuenta las direcciones, presentamospara bordes que se muestran correctamente, pero con la dirección incorrecta. Después de eso, lo consideraremos así:
Entonces puedes leer -tamaño tanto para el esqueleto como teniendo en cuenta la orientación (obviamente, en este caso no será mayor que el del esqueleto). Sin embargo, en el caso del algoritmo de PC, un borde doble se suma a solamente , pero no , porque todavía se deduce una de las aristas reales (sin la Suficiencia Causal, esto sería incorrecto).
Finalmente, comparemos los algoritmos:

Los dos primeros gráficos son una comparación de los esqueletos del algoritmo de PC: el clásico y con la nueva orientación de borde. Son necesarios para mostrar el borde superior-medidas. Los dos segundos comparan estos algoritmos con respecto a la orientación. Como puede ver, no hay victoria.
Comparar modelos - 3: desactivar la suficiencia causal
Ahora "cerremos" algunas variables en el gráfico verdadero y en los datos sintéticos después de la generación. Esto desactivará la suficiencia causal. Pero será necesario comparar los resultados no con la gráfica verdadera, sino con la obtenida de la siguiente manera:
- los bordes de los padres del vértice oculto se dibujarán a sus hijos,
- conecta a todos los hijos del vértice oculto con un doble borde.
Ya compararemos los algoritmos FCI + (con orientación de borde modificada y con la clásica):

Y ahora, cuando no se cumple la Suficiencia Causal, el resultado de la nueva orientación se vuelve mucho mejor.
Ha aparecido otra observación importante: los algoritmos de PC y FCI construyen esqueletos casi idénticos en la práctica. Por tanto, comparé su salida con la orientación de los bordes, que propuse en mi trabajo.
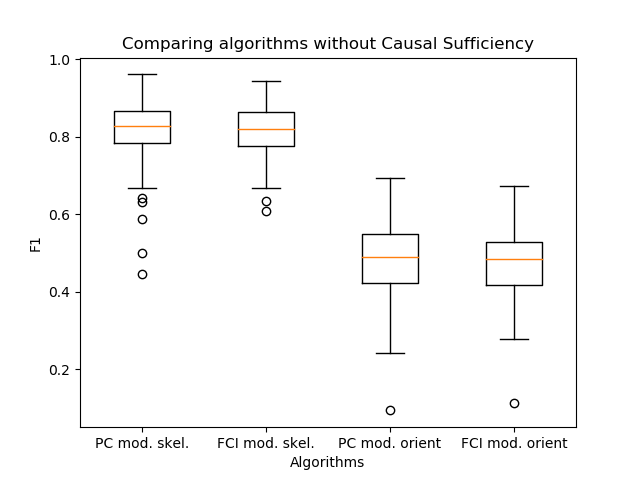
Resultó que los algoritmos prácticamente no difieren en calidad. En este caso, la PC es un paso del algoritmo de construcción del esqueleto dentro de la FCI. Por lo tanto, usar el algoritmo de orientación de PC, como en el algoritmo FCI, es una buena solución para aumentar la velocidad de inferencia de enlaces.
Salida
Resumiré brevemente de lo que hablamos en este artículo:
- Cómo puede surgir la tarea de derivar vínculos causales en una gran empresa de TI.
- ¿Qué son las correlaciones falsas y cómo pueden interferir con la selección de características?
- Qué algoritmos para enlaces de inferencia existen y se utilizan con más frecuencia.
- ¿Qué dificultades pueden surgir al derivar gráficos causales?
- ¿Qué es la comparación de gráficos causales y cómo lidiar con ella?
Si está interesado en el tema de la inferencia causal, eche un vistazo a mi otro artículo , hay más teoría en él. Allí escribo en detalle sobre los términos básicos que se utilizan en la inferencia de enlaces, así como sobre cómo funcionan los algoritmos clásicos y la orientación de los bordes propuestos por mí.