
Los últimos años de aprendizaje profundo han sido una serie continua de logros: desde derrotar a la gente en el juego de Go hasta el liderazgo mundial en reconocimiento de imágenes, reconocimiento de voz, traducción de texto y otras tareas. Pero este progreso ha ido acompañado de un aumento insaciable del apetito por la potencia informática. Un grupo de científicos del MIT, la Universidad de Yongse (Corea) y la Universidad de Brasilia publicó un metaanálisis de 1.058 artículos científicos sobre aprendizaje automático . Muestra claramente que el progreso en el aprendizaje automático (ML) es un derivado de la potencia de cálculo del sistema . El rendimiento de la computadora siempre ha limitado la funcionalidad de ML, pero ahora las necesidades de los nuevos modelos de ML están creciendo mucho más rápido que el rendimiento de la computadora.
El estudio demuestra que los avances en el aprendizaje automático son, de hecho, poco más que una consecuencia de la Ley de Moore. Y por esta razón, muchos problemas de ML nunca se resolverán debido a las limitaciones físicas de la computadora.
Los investigadores analizaron artículos científicos sobre clasificación de imágenes (ImageNet), reconocimiento de objetos (MS COCO), respuesta a preguntas (SQuAD 1.1), reconocimiento de entidades nombradas (COLLN 2003) y traducción automática (WMT 2014 En-to-Fr).

Consultas informáticas ML, escala logarítmica
Se ha demostrado que el progreso en las cinco áreas depende en gran medida del aumento de la potencia informática. La extrapolación de esta relación deja en claro que el progreso en estas áreas se está volviendo rápidamente insostenible económica, técnica y ambientalmente. Por tanto, un mayor progreso en estas aplicaciones requerirá métodos significativamente más eficientes desde el punto de vista informático.
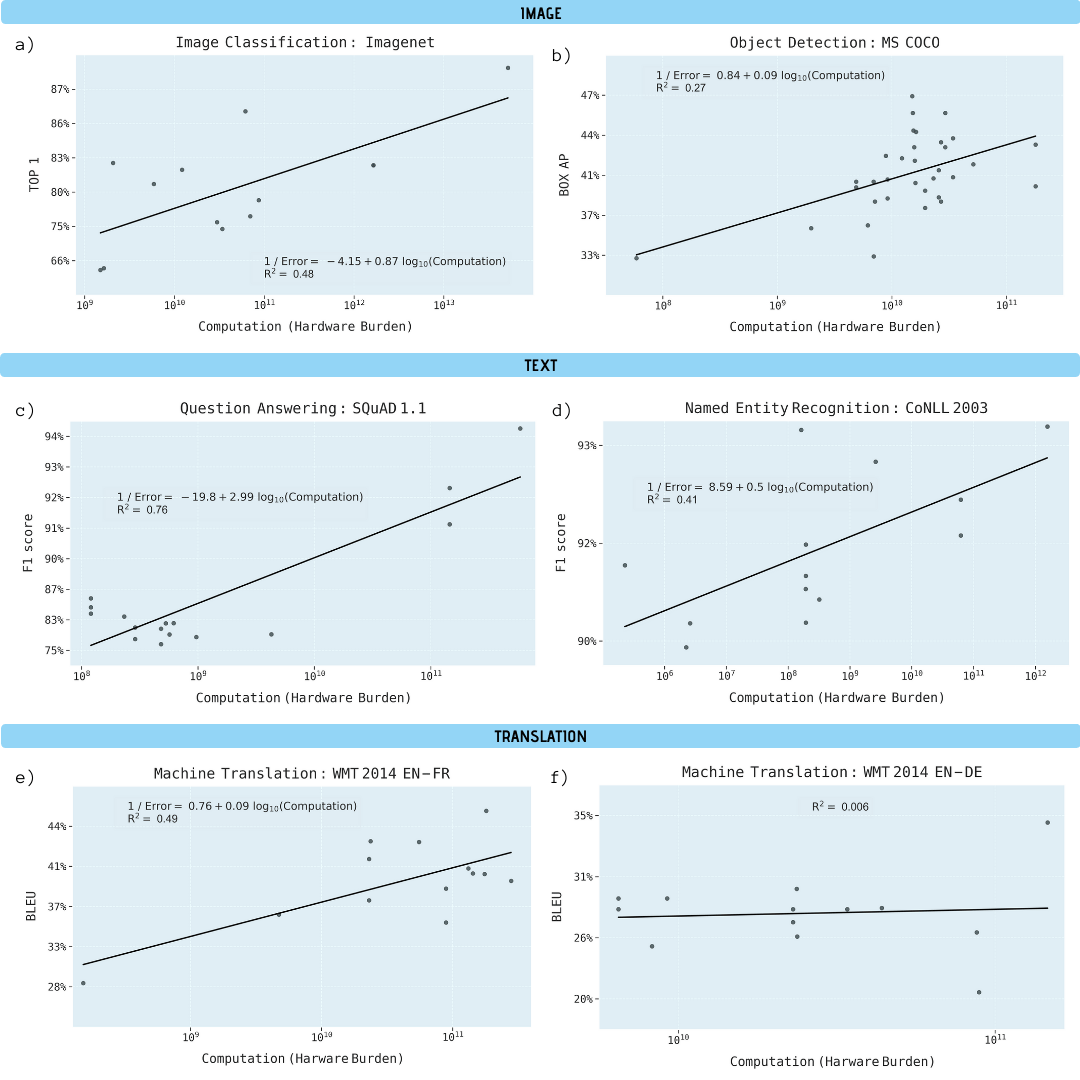
Mejora del rendimiento en diversas tareas de aprendizaje automático en función del poder computacional del modelo de aprendizaje (en gigaflops)
¿Por qué el aprendizaje automático depende tanto del poder computacional?
Hay razones importantes para creer que el aprendizaje profundo es intrínsecamente más dependiente de la computación que otros métodos. En particular, debido al papel de la hiperparametrización y la forma en que se escala el sistema, cuando se utilizan datos de entrenamiento adicionales para mejorar la calidad del resultado (por ejemplo, para reducir la tasa de errores de clasificación, el error cuadrático medio de regresión, etc.).
Se ha comprobado que la hiperparametrización aporta importantes ventajas, es decir, la implementación de redes neuronales con más parámetros que la cantidad de puntos de datos disponibles para entrenarla. Clásicamente, esto conduciría a un sobreajuste. Pero las técnicas de optimización de gradiente estocástico proporcionan un efecto de regularización a expensas de la detención temprana, poniendo las redes neuronales en modo de interpolación donde los datos de entrenamiento se ajustan casi exactamente, mientras se mantienen predicciones razonables en puntos intermedios. Un ejemplo de redes a gran escala con hiperparametrización es uno de los mejores sistemas de reconocimiento de patrones NoisyStudent , que tiene 480 millones de parámetros para 1,2 millones de puntos de datos de ImageNet.
El problema con la hiperparametrización es que la cantidad de parámetros de aprendizaje profundo debe crecer a medida que aumenta la cantidad de puntos de datos. Dado que el costo de entrenar un modelo de aprendizaje profundo se escala con el producto de la cantidad de parámetros y la cantidad de puntos de datos, esto significa que el requisito computacional crece al menos al cuadrado de la cantidad de puntos de datos en un sistema hiperparametrizado. El escalado cuadrático aún no estima suficientemente qué tan rápido deben crecer las redes de aprendizaje profundo, ya que la cantidad de datos de entrenamiento debe escalar mucho más rápido que linealmente para obtener mejoras de rendimiento lineales.
Considere un modelo generativo que tiene 10 valores distintos de cero de entre 1000 posibles, y considere cuatro modelos para intentar descubrir estos parámetros:
- : 10
- : 9 1
- : 1000 ,
- : , 1000 , ()
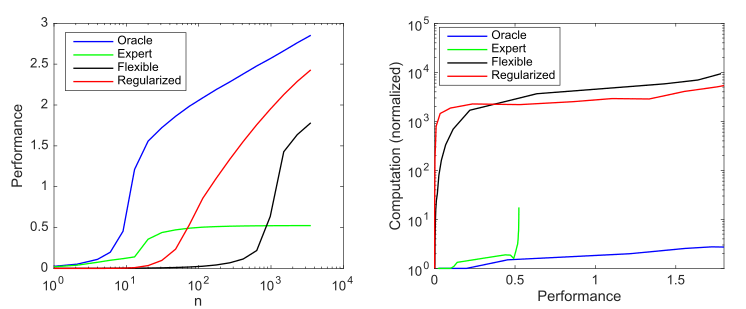
El impacto de la complejidad y la regularización del modelo en el rendimiento del modelo (medido como un error cuadrático medio normalizado de log 10 negativo frente al predictor óptimo) y en los requisitos computacionales promedió más de 1000 simulaciones por caso; a) productividad promedio a medida que aumenta el tamaño de la muestra; b) Cálculo promedio necesario para mejorar el rendimiento
Este gráfico resume el principio descrito por Andrew Ng: los métodos tradicionales de aprendizaje automático funcionan mejor con datos pequeños, pero los modelos de aprendizaje automático flexibles funcionan mejor con datos grandes. Un fenómeno común de los modelos ágiles es que tienen un mayor potencial, pero también una cantidad significativamente mayor de datos y necesidades computacionales.
Podemos ver que el aprendizaje profundo funciona bien porque usa hiperparametrización para crear un modelo muy flexible y regularización (implícita) para reducir la complejidad de la muestra a niveles aceptables. Sin embargo, al mismo tiempo, el aprendizaje profundo es mucho más intensivo en computación que los modelos más eficientes. Por lo tanto, aumentar la flexibilidad del ML implica la dependencia de grandes cantidades de datos y cálculos.
Límites computacionales
El rendimiento de la computadora siempre ha limitado el poder de los sistemas ML.
Por ejemplo, Frank Rosenblatt describió la primera red neuronal de tres capas en 1960. Se esperaba que ella "demostrara las posibilidades de utilizar el perceptrón como un dispositivo de reconocimiento de patrones". Pero Rosenblatt descubrió que "a medida que aumenta el número de conexiones en la red, la carga en una computadora digital típica pronto se vuelve excesiva". Más tarde, en 1969, Minsky y Papert explicaron las limitaciones de las redes de 3 capas, incluida la incapacidad de aprender una función XOR simple. Pero notaron una solución potencial: “Los experimentadores han encontrado una forma interesante de sortear esta dificultad introduciendo cadenas más largas de unidades intermedias” (es decir, construyendo redes neuronales más profundas). A pesar de esta posible solución, gran parte del trabajo académico en esta área se ha abandonado.porque en ese momento simplemente no había suficiente potencia informática.
Durante las décadas siguientes, las mejoras en el hardware proporcionaron aproximadamente 50.000 veces la mejora del rendimiento y las redes neuronales aumentaron proporcionalmente sus necesidades computacionales, como se muestra en KDPV. Dado que el aumento de la potencia de cálculo en un dólar se equiparó aproximadamente a la potencia de cálculo por chip, los costos económicos de ejecutar tales modelos se han mantenido en gran medida estables a lo largo del tiempo.
A pesar de una aceleración tan significativa de la CPU, los modelos de aprendizaje profundo todavía eran demasiado lentos para aplicaciones a gran escala en 2009. Esto obligó a los investigadores a centrarse en modelos a menor escala o utilizar menos ejemplos de formación.
El punto de inflexión fue la transferencia del aprendizaje profundo a la GPU, que inmediatamente dio una aceleración en5-15 veces , que en 2012 había aumentado a 35 veces y que llevó a una importante victoria de AlexNet en la competencia Imagenet de 2012 . Pero el reconocimiento de imágenes fue solo el primer punto de referencia en el que ganaron los sistemas de aprendizaje profundo. Pronto ganaron en detección de objetos, reconocimiento de entidades nombradas, traducción automática, respuesta a preguntas y reconocimiento de voz.
La adopción del aprendizaje profundo en las GPU (y luego en los ASIC) llevó a la adopción generalizada de estos sistemas. Pero la cantidad de potencia informática en los sistemas de aprendizaje automático modernos creció aún más rápido, aproximadamente 10 veces al año entre 2012 y 2019. Esta velocidad es mucho más rápida que la mejora general del cambio a las GPU, la modesta ganancia del último suspiro de la Ley de Moore o la mayor eficiencia del entrenamiento de redes neuronales.
En cambio, la principal ganancia en la eficiencia del aprendizaje automático provino de la ejecución de modelos durante períodos más largos en más máquinas. Por ejemplo, en 2012 AlexNet entrenó en dos GPU durante 5-6 días, en 2017 ResNeXt-101 entrenó en ocho GPU durante más de 10 días, y en 2019 NoisyStudent entrenó en alrededor de mil TPU durante 6 días. Otro ejemplo extremo es el sistema de traducción automática Evolved Transformer , que utilizó más de 2 millones de horas de GPU en capacitación, lo que costó millones de dólares.
Escalar los cálculos de aprendizaje profundo aumentando los relojes de hardware o más chips es problemático a largo plazo. Porque implica que los costos escalan aproximadamente al mismo ritmo que los aumentos en la potencia informática, y eso rápidamente hace imposible un mayor crecimiento.
Futuro
Triste conclusión de lo anterior.
La siguiente tabla muestra cuánto poder computacional y cuánto costo del sistema logrará ciertos objetivos en problemas de ML, si extrapolamos de los modelos actuales. Las tareas de aprendizaje automático se ejecutarán en las supercomputadoras más potentes. Los autores del trabajo científico creen que no se cumplirán los requisitos para las metas establecidas . Aunque están considerando opciones teóricamente posibles para lograrlas: mejorar la eficiencia sin aumentar el rendimiento, aceleradores de hardware como TPU y FPGA, computación neuromórfica, computación cuántica y otras, ninguna de estas tecnologías (todavía) le permite superar los límites computacionales del ML.

. .
