Supongamos que tenemos un registro de documentos con los que trabajan los operadores o contadores en VLSI , como este: Tradicionalmente, dicha pantalla usa la clasificación directa (nueva desde abajo) o inversa (nueva desde arriba) por fecha y el identificador ordinal asignado cuando se crea el documento, o ... Ya he comentado los problemas típicos que surgen en este caso en el artículo Antipatrones de PostgreSQL: Navegando por el Registro . Pero lo que si el usuario por alguna razón quería "atípicos" - por ejemplo, ordenar un campo "como esto", y otro "así" -

ORDER BY dt, idORDER BY dt DESC, id DESC
ORDER BY dt, id DESC? Pero no queremos crear el segundo índice, porque ralentiza la inserción y el volumen extra en la base de datos.
¿Es posible resolver este problema de manera efectiva usando solo el índice
(dt, id)?
Primero esbocemos cómo está ordenado nuestro índice: tenga en
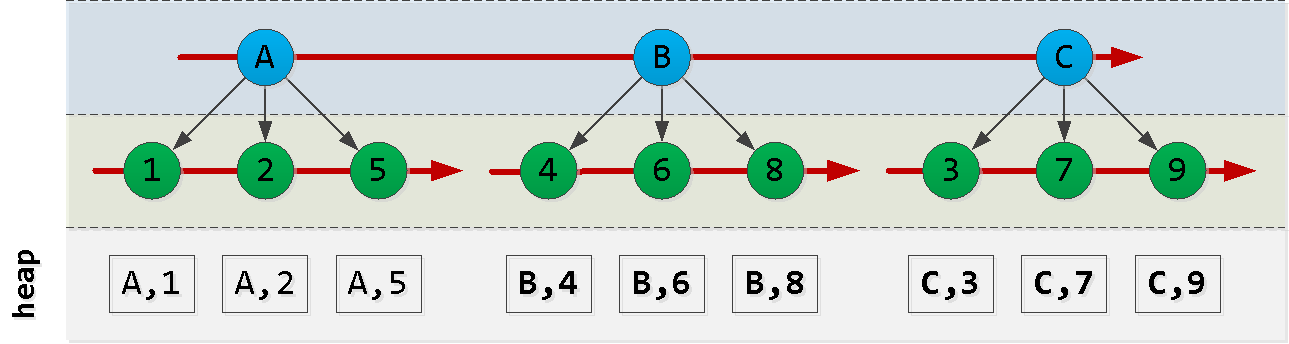
cuenta que el orden en el que se crean las entradas de id no coincide necesariamente con el orden de dt, por lo que no podemos confiar en él y tendremos que inventar algo.
Ahora suponga que estamos en el punto (A, 2) y queremos leer las 6 entradas "siguientes" en el orden : ¡Ajá! Hemos seleccionado alguna "pieza" del primer nodo , otra "pieza" del último nodo y todos los registros de los nodos entre ellos ( ). Cada uno de estos bloques se lee con bastante éxito por índice , a pesar del orden no muy adecuado. Intentemos construir una consulta como esta:
ORDER BY dt, id DESC
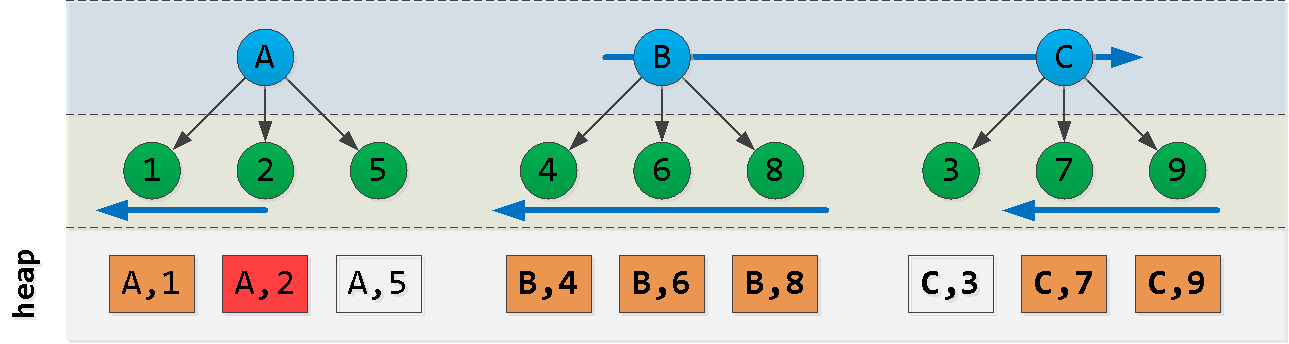
ACB(dt, id)
- primero leemos desde el bloque A "a la izquierda" del registro inicial - obtenemos
Nregistros - además leemos
L - N"a la derecha" del valor A - encontramos en el último bloque la clave máxima C
- filtrar todos los registros de la selección anterior con esta clave y restarlo "a la derecha"
Ahora intentemos representar en el código y verificar el modelo:
CREATE TABLE doc(
id
serial
, dt
date
);
CREATE INDEX ON doc(dt, id); --
-- ""
INSERT INTO doc(dt)
SELECT
now()::date - (random() * 365)::integer
FROM
generate_series(1, 10000);Para no calcular el número de registros ya leídos y la diferencia entre este y el número objetivo, obliguemos a PostgreSQL a hacer esto usando un "truco"
UNION ALLy LIMIT:
(
... LIMIT 100
)
UNION ALL
(
... LIMIT 100
)
LIMIT 100Ahora recopilemos los siguientes 100 registros con la clasificación de destino del último valor conocido:
(dt, id DESC)
WITH src AS (
SELECT
'{"dt" : "2019-09-07", "id" : 2331}'::json -- ""
)
, pre AS (
(
( -- 100 "" "" A
SELECT
*
FROM
doc
WHERE
dt = ((TABLE src) ->> 'dt')::date AND
id < ((TABLE src) ->> 'id')::integer
ORDER BY
dt DESC, id DESC
LIMIT 100
)
UNION ALL
( -- 100 "" "" A -> B, C
SELECT
*
FROM
doc
WHERE
dt > ((TABLE src) ->> 'dt')::date
ORDER BY
dt, id
LIMIT 100
)
)
LIMIT 100
)
-- C ,
, maxdt AS (
SELECT
max(dt)
FROM
pre
WHERE
dt > ((TABLE src) ->> 'dt')::date
)
( -- "" C
SELECT
*
FROM
pre
WHERE
dt <> (TABLE maxdt)
ORDER BY
dt, id DESC -- , B
LIMIT 100
)
UNION ALL
( -- "" C 100
SELECT
*
FROM
doc
WHERE
dt = (TABLE maxdt)
ORDER BY
dt, id DESC
LIMIT 100
)
LIMIT 100;Veamos lo que sucedió en términos de:

[mira explica.tensor.ru]
- Entonces,
A = '2019-09-07'leemos 3 registros usando la primera clave . - Terminaron de leer otros 97 por
ByCdebido al golpe exactoIndex Scan. - Entre todos los registros, 18 fueron filtrados por la clave máxima
C. - Leemos 23 registros (en lugar de los 18 buscados
Bitmap Scan) usando la clave máxima. - Todos reordenaron y recortaron los 100 registros de destino.
- ... ¡y todo tomó menos de un milisegundo!
El método, por supuesto, no es universal y con índices en una mayor cantidad de campos se convertirá en algo muy terrible, pero si realmente desea darle al usuario una clasificación "no estándar" sin "colapsar" la base en
Seq Scanuna tabla grande, puede usarlo con cuidado.