Casi cualquier negocio se enfrenta a una carga flotante: silencio o agitación. No tienes que ir muy lejos para ver ejemplos:
- el tráfico de la tienda en línea puede fluctuar significativamente según la hora del día o la temporada;
- Los servicios internos de las empresas pueden estar "vacíos" durante semanas y, en vísperas de la presentación del informe trimestral, su asistencia aumentará drásticamente.
Debajo del corte, hablemos de cómo ayudamos a nuestros clientes a resolver este problema al introducir un nuevo nivel de almacenamiento con IOPS personalizadas.
Algunas palabras sobre los discos
Todos nuestros clientes quieren más o menos una cosa: obtener una infraestructura confiable que cumpla con los requisitos de los procesos comerciales a un buen precio. En consecuencia, nosotros, como proveedor de la nube, nos enfrentamos a la tarea de construir servicios y servicios de tal manera que podamos encontrar fácilmente la solución óptima para cada cliente.
Anteriormente, teníamos dos niveles de almacenamiento: st2 y gp2. El número "2" en nuestra terminología interna significa una versión más nueva y mejorada.
st2: Estándar (HDD) : medios de disco duro SAS de bajo costo y sin complicaciones . Excelente para servicios en los que IOPS no es fundamental, pero el ancho de banda es importante.
Sus parámetros son los siguientes: tiempo de respuesta - no más de 10 ms, rendimiento de discos hasta 2000 GB - 500 IOPS, de 2000 GB - 1000 IOPS, y el ancho de banda crece con cada gigabyte y llega a 500 MB / s para los mismos 2000 GB.
gp2: Universal (SSD) : unidades SSD SAS más caras y rápidas. Adecuado para clientes cuyas aplicaciones son más exigentes en términos de IOPS. Por ejemplo, bases de datos de tiendas en línea.
Los parámetros de Gp2 se especifican en el SLA. El rendimiento en IOPS se calcula por volumen: hay 10 IOPS por GB. La barra superior es 10,000 IOPS. Y el tiempo de respuesta de dichos discos no es más de 2 ms. Se trata de un rendimiento bastante alto, capaz de cubrir el 97% de las tareas empresariales.
A lo largo de los años de trabajo, hemos acumulado una gran cantidad de estadísticas y experiencia en relación con los clientes y notamos que algunos de ellos no se sienten del todo cómodos eligiendo entre dos opciones de conducción. Por ejemplo, alguien podría querer un mejor rendimiento que 10 IOPS por gigabyte. O una carga flotante no permite detenerse en uno de los tipos y pagar por estar listo para la hora pico, pero las capacidades inactivas periódicas tampoco es una opción.
Puede simular un caso tópico simple. Durante la pandemia, una empresa necesitaba emitir pases para los empleados. Para que puedan viajar con seguridad por Moscú. El personal es numeroso, dos mil personas. Se emitió una orden para actualizar urgentemente los datos personales en el sistema CRM corporativo. Dicho y hecho. Más de mil personas se apresuraron simultáneamente a actualizar la información. Pero las personas ahorrativas estaban comprometidas con CRM. Se ha asignado poca capacidad. ¡Nadie esperaba que más de diez personas se subieran a él al mismo tiempo! Todo cayó y no pudo levantarse hasta un día más. Los procesos comerciales se han interrumpido, la gente está sentada en casa y tiene miedo de las multas. Y si existiera la oportunidad de "modificar" de manera flexible el rendimiento de los discos en la nube, aumentarían las IOPS durante un breve período de tiempo y luego lo devolverían como estaba, eliminando o reduciendo significativamente el tiempo de inactividad de CRM.
Por un lado, la situación es grotesca, el porcentaje de clientes con tales necesidades no es muy grande. Un pequeño proveedor incluso tomaría su existencia como una anomalía estadística y no tomaría ninguna medida. Por otro lado, organizar un nuevo nivel de almacenamiento nos permitirá aumentar la flexibilidad de los servicios para todos los clientes. Eso significa que tenemos que hacerlo.
Si ha estado siguiendo nuestro blog durante mucho tiempo, probablemente recuerde el artículo en el que hablamos sobre una serie de experimentos con Dell EMC ScaleIO (ahora PowerFlex OS) y su implementación en la nube CROC. Sea como fuere, le recomendamos que se familiarice con él para una comprensión general.
En términos generales, digamos: ScaleIO (DellEMC pasó a llamarse ScaleIO primero a VxFlex OS, y desde el 25 de junio de 2020 a PowerFlex OS) es un almacenamiento definido por software, SDS, súper versátil y confiable. La confiabilidad es nuestro requisito # 0. Por tanto, cada nodo que forma parte del Storage Pool se instala en un rack separado, lo que excluye la posibilidad de pérdida de datos en caso de una pérdida parcial de energía en el centro de datos o localmente en el rack.
Si falla un disco, servidor o rack completo, tendremos tiempo suficiente para replicar los datos a otros hosts y luego reemplazar el elemento fallado. Si dos rejillas mueren a la vez, no se perderá nada de todos modos. En esta situación, el clúster entrará en modo de emergencia, la escritura y lectura de datos de los discos será limitada, pero después de restaurar la conectividad con el bastidor "bloqueado", PowerFlex OS asumirá el proceso de reconstrucción de datos y recuperación del clúster. Este proceso, por cierto, no suele tardar más de un par de minutos.
Esta es, por supuesto, una situación de emergencia: las aplicaciones que no pueden escribir y leer "caerán" inmediatamente, pero perder incluso una parte tan grande de la infraestructura no destruirá los datos. Aunque la probabilidad de falla de dos racks en diferentes partes de la sala de turbinas es extremadamente pequeña, esto no significa que no deba tenerse en cuenta.
En términos de versatilidad, PowerFlex OS (anteriormente ScaleIO) también es ideal para nuestros requisitos. De hecho, este es un constructor, listo para aceptar cualquier carga de trabajo y capaz de "aceptar" unidades de disco duro SATA / SAS lentas, SSD rápidas y unidades NVME ultrarrápidas. Y esto es realmente cierto: ha sido probado en numerosos escenarios y puestos de prueba de equipos de desarrollo y mantenimiento, puede ensamblar un grupo prácticamente con
Música de cinco a seis
Echemos un vistazo a uno de los escenarios en los que un cliente podría necesitar un rendimiento flexible con un ejemplo del mundo real. Entre nuestros clientes existe una red de tiendas de instrumentos musicales. Los técnicos de la empresa controlan cuántos visitantes visitan su sitio todos los días y horas. Esto incluso se refleja en nuestro SLA: de 17:00 a 18:00 la tienda recibe el número máximo de clientes, por lo que no debe haber trabajos técnicos ni tiempos muertos.
La práctica de cálculo estándar es cuando el 100% de la carga se divide en 24 horas. Resulta aproximadamente un 4% por cada hora. Para una cadena de tiendas de música, esta hora en particular "pesa" no 4, sino 10%, esto es, decenas de miles de visitantes y clientes.
En consecuencia, sería muy conveniente para el cliente si en esta hora "dorada" sus discos se volvieran más rápidos como por arte de magia,
Ahora tenemos la oportunidad de brindar a los clientes al menos 30, al menos 50 mil IOPS durante las horas de mayor actividad, y el resto del tiempo para mantener el rendimiento en el nivel habitual. A este tipo de almacenamiento lo llamamos io2: Ultimate (SSD). ¡El tiempo de respuesta de los discos basados en este tipo de almacenamiento no es superior a 1 ms!
Y nuevamente sobre confiabilidad: st2, gp2 y el nuevo io2 son independientes, independientes entre sí. Grupos de almacenamiento en un clúster PowerFlex.
Si anteriormente el cliente seleccionó un disco y recibió un rendimiento fijo, ahora puede seleccionarlo y configurarlo, rendimiento. Independientemente del volumen. La filosofía es la siguiente: puede obtener un disco enorme y rápido de una gran cantidad de proveedores, pero ¿está listo para pagarlo el 100% del tiempo?
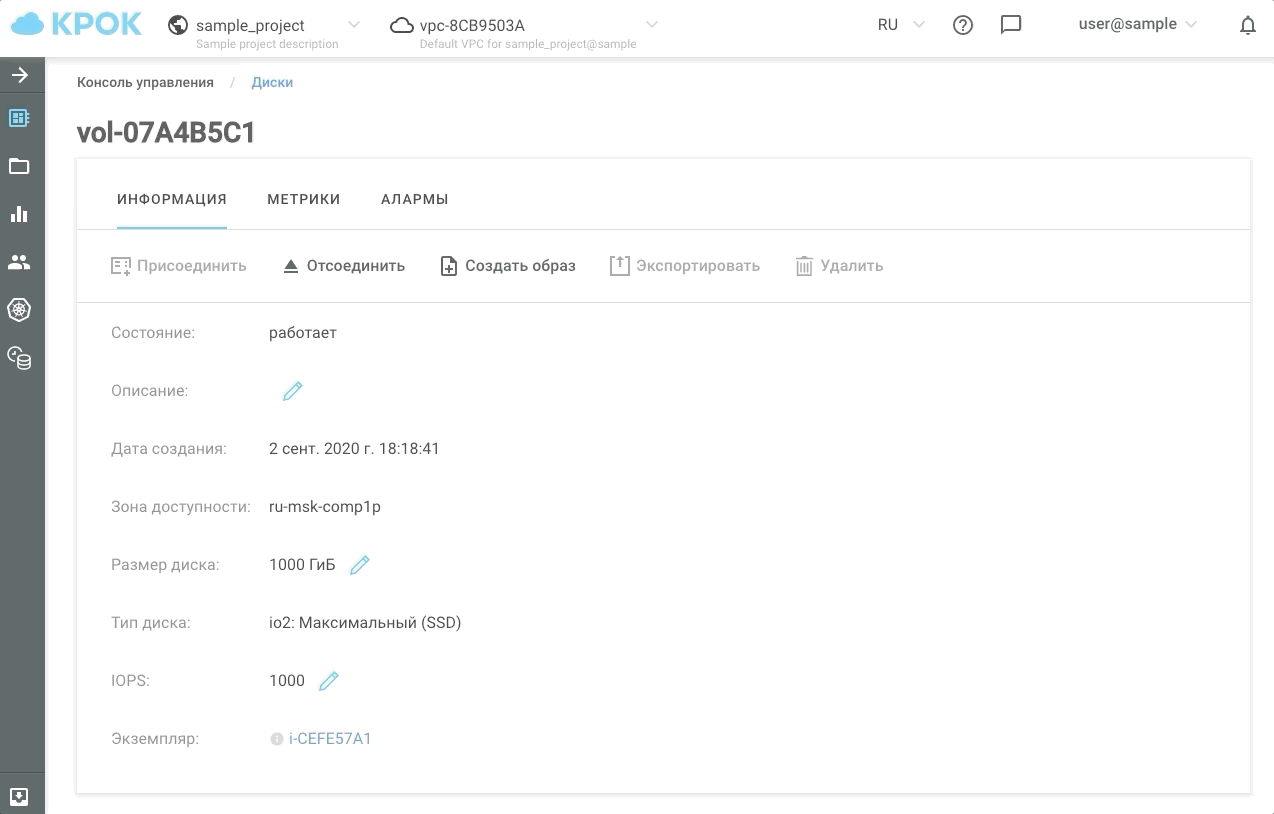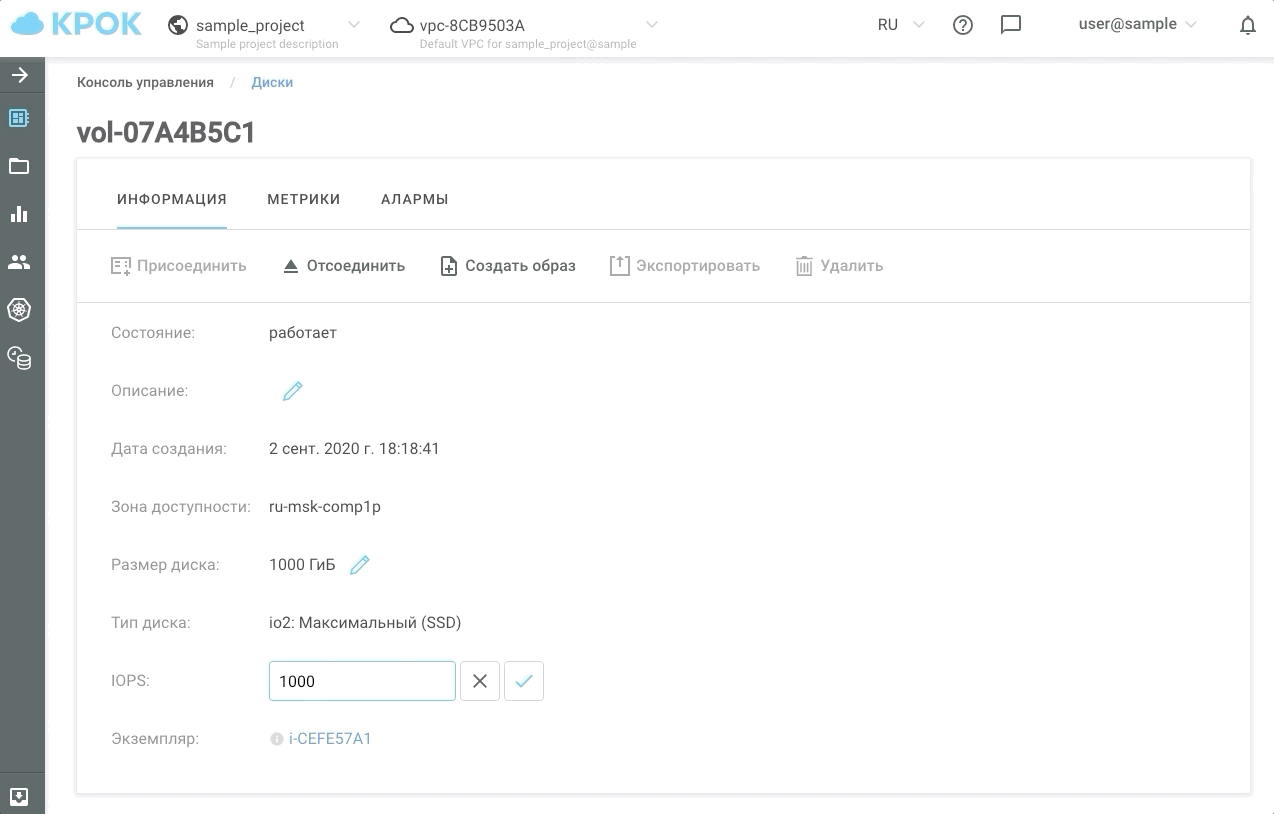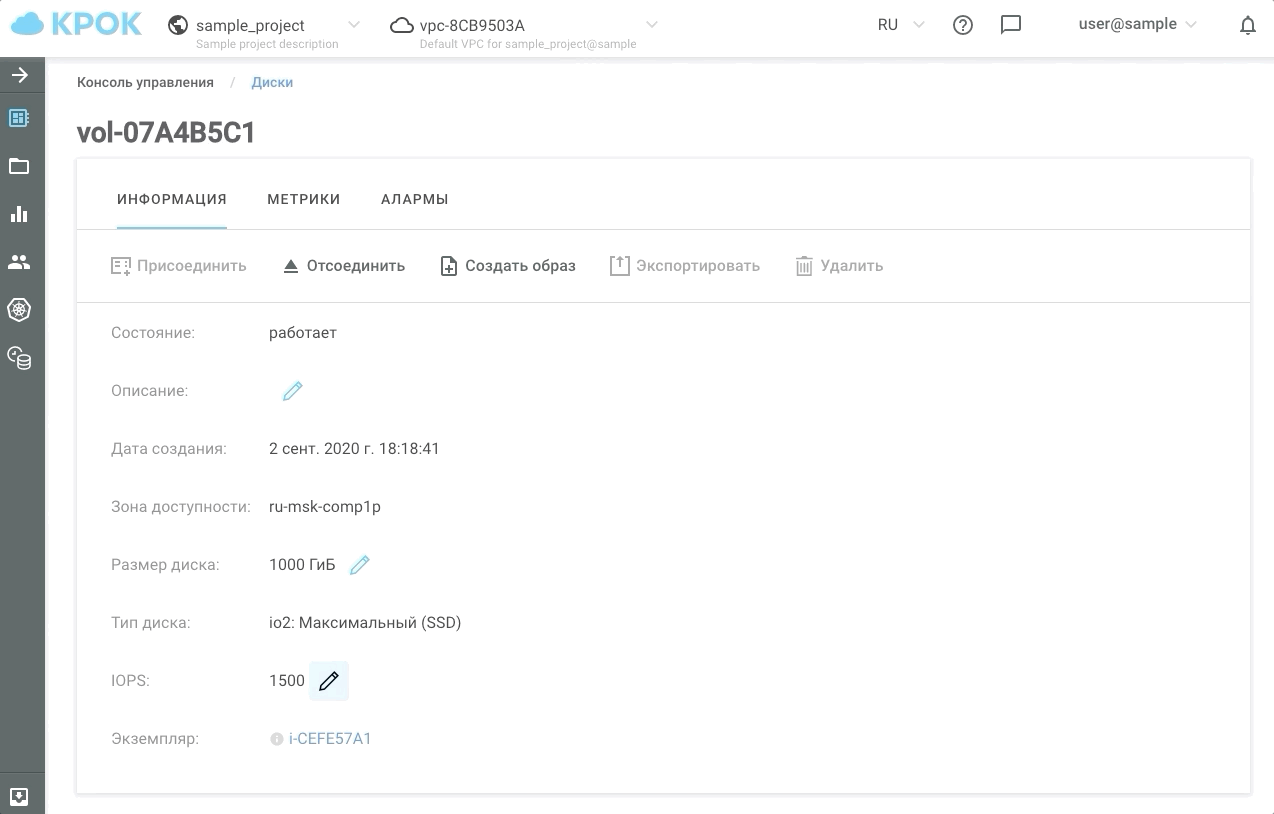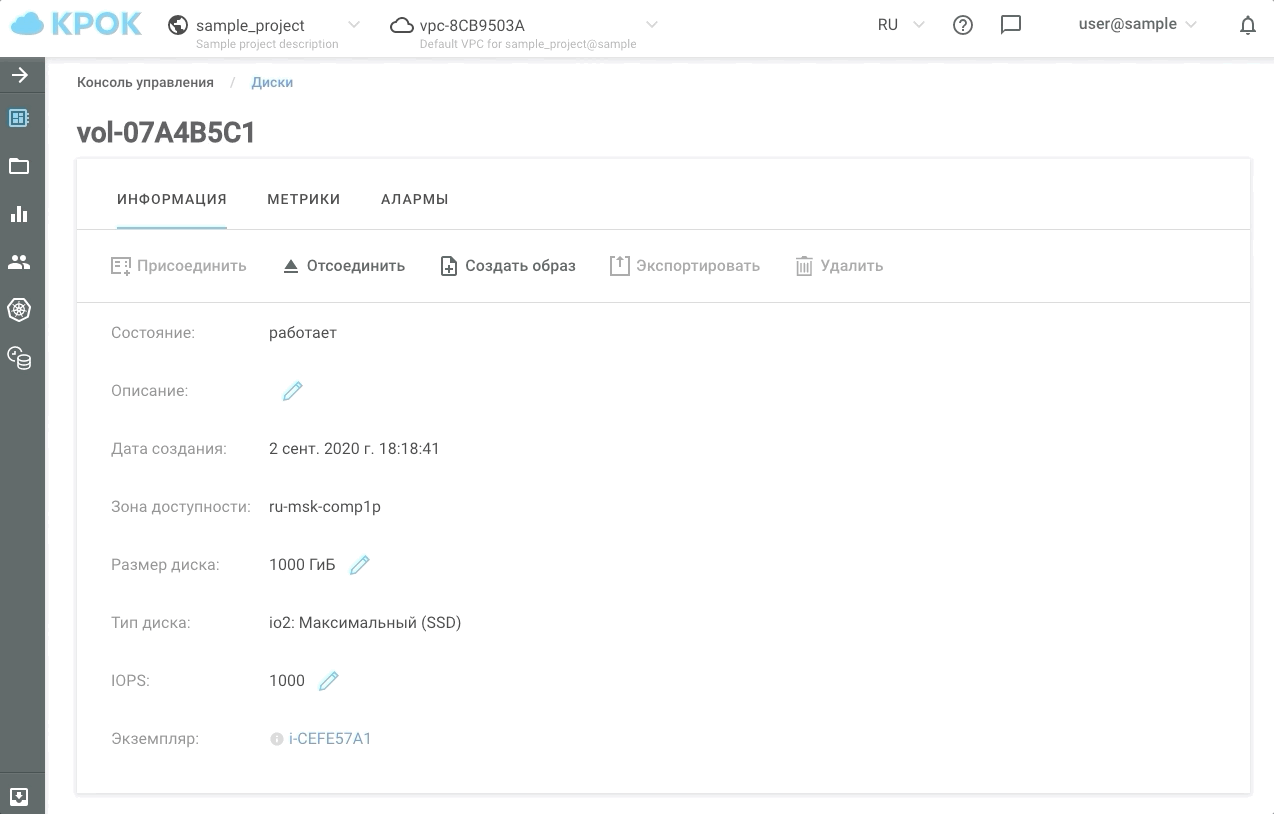
Como administrar
Hay dos formas de gestionar el rendimiento: a la antigua, a través de la interfaz web y utilizando la API. Esto hace posible escribir scripts simples que "acelerarán" o "ralentizarán" los discos en un horario y, en consecuencia, le ahorrarán dinero.
Mientras que antes podíamos llevar cualquier carga requerida por el cliente, ahora podemos hacerlo al mejor precio.
Así es como se ve en la práctica.
Aumentar la adaptabilidad de la infraestructura en la nube es una tendencia relevante y muy correcta. No puede decirle al cliente: "¡Toma lo que te dan, o incluso esto no sucederá!" Debe poder decidir qué recursos, cuándo y cuánto necesita. El futuro está en soluciones tan flexibles y fiables.
Respondemos por nuestros servicios: todos los parámetros están detallados en el SLA, y puede contar con el hecho de que las cifras "en papel" no diferirán de las reales.
Y cómo verificar su proveedor de nube, ya lo escribimos en el artículo anterior .