
Volvemos al aire y continuamos con la serie de notas de Data Scientist, y hoy presento mi lista de verificación completamente subjetiva para elegir un modelo de aprendizaje automático.
Estas son las 10 principales propiedades del problema y solo puntos (sin orden en ellas), desde el punto de vista del cual comienzo a elegir un modelo y, en general, a modelar una tarea de análisis de datos.
No es en absoluto necesario que lo tengas igual, todo es subjetivo aquí, pero comparto mi experiencia de vida.
¿Cuál es nuestro objetivo en general? Interpretabilidad y precisión: espectro

Fuente
Quizás la pregunta más importante a la que se enfrenta un científico de datos antes de comenzar a modelar es:
¿Qué es exactamente una tarea empresarial?
O investigación, si hablamos de la academia, etc.
Por ejemplo, necesitamos análisis basados en un modelo de datos, o viceversa, solo nos interesan las predicciones cualitativas de la probabilidad de que un correo electrónico sea spam.
El equilibrio clásico que he visto es el espectro entre la interpretabilidad del método y su precisión (como en el gráfico anterior).
Pero, de hecho, no solo necesita manejar Catboost / Xgboost / Random Forest y elegir un modelo, sino comprender qué quiere la empresa, qué datos tenemos y cómo se aplicarán.
En mi práctica, esto establecerá inmediatamente un punto en el espectro de interpretabilidad y precisión (sea lo que sea que eso signifique aquí). Y en base a esto, ya se pueden pensar en métodos para modelar el problema.
El tipo de tarea en sí
Además, una vez que comprendamos lo que quiere la empresa, debemos comprender a qué tipo matemático de problemas de aprendizaje automático pertenece el nuestro, por ejemplo
- Análisis exploratorio: análisis puro de los datos disponibles y pegar un palo
- Agrupación: recopile datos en grupos en función de algunos atributos comunes
- Regresión: debe devolver un resultado entero o existe la probabilidad de un evento
- Clasificación: debe devolver una etiqueta de clase
- Etiquetas múltiples: debe devolver una o más etiquetas de clase para cada entrada
Ejemplos de
datos: hay dos clases y un conjunto de registros sin etiqueta:

Y necesita construir un modelo que marque estos mismos datos:

O, como opción, no hay etiquetas y debe seleccionar los grupos:

Como aquí:
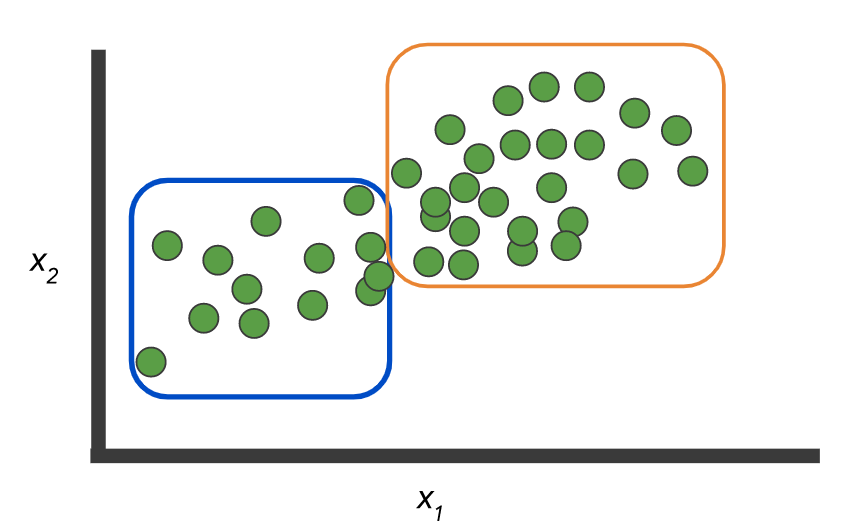
Imágenes de aquí .
Pero el ejemplo en sí ilustra la diferencia entre los dos conceptos: clasificación, cuando N> 2 clases - clase múltiple vs. multi label
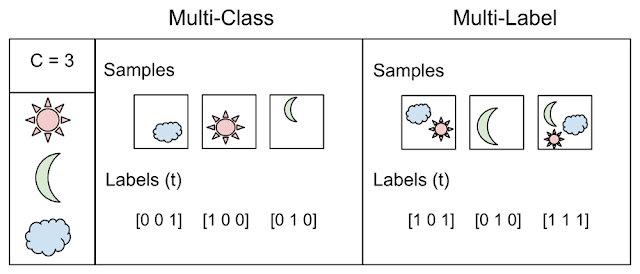
Tomado de aquí
Se sorprenderá, pero muy a menudo también vale la pena hablar sobre este punto directamente con la empresa; esto realmente puede ahorrarle mucho tiempo y esfuerzo. Siéntase libre de hacer dibujos y dar ejemplos simples (pero no demasiado simplistas).
Exactitud y como se determina
Comenzaré con un ejemplo simple, si usted es un banco y emite un préstamo, entonces en un préstamo no exitoso perdemos cinco veces más de lo que obtenemos en uno exitoso.
Por lo tanto, ¡la cuestión de medir la calidad del trabajo es primordial! O imagine que tiene un desequilibrio significativo en los datos, clase A = 10% y clase B = 90%, ¡entonces un clasificador que simplemente devuelve B siempre tiene una precisión del 90%! Lo más probable es que esto no sea lo que deseaba ver al entrenar el modelo.
Por lo tanto, es fundamental definir una métrica de puntuación del modelo que incluya:
- clase de peso: como en el ejemplo anterior, el mal crédito es 5 y el buen crédito es 1
- Matriz de costos - es posible confundir riesgo bajo y medio - esto no importa, pero riesgo bajo y alto riesgo ya es un problema
- ¿Debe la métrica reflejar el equilibrio? como ROC AUC
- ¿Generalmente contamos probabilidades o las etiquetas de clase son rectas?
- ¿O tal vez la clase es generalmente "una" y tenemos precisión / recuerdo y otras reglas del juego?
En general, la elección de una métrica está determinada por la tarea y su formulación, y es para aquellos que establecen esta tarea (generalmente personas de negocios) que todos estos detalles deben aclararse y aclararse, de lo contrario, habrá costuras en la salida.
Modelo de análisis posterior
A menudo es necesario realizar análisis basados en el modelo en sí. Por ejemplo, cuál es la contribución de diferentes características al resultado original: como regla, la mayoría de los métodos pueden producir algo similar a esto:
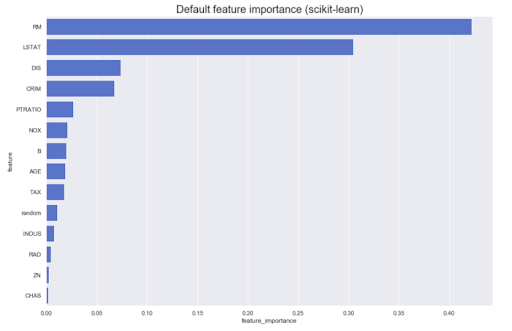
Sin embargo, ¿qué sucede si necesitamos conocer la dirección? Los valores grandes del atributo A aumentan la pertenencia a la clase Z, o viceversa. Llamémoslos importancia de característica dirigida: se pueden obtener de algunos modelos, por ejemplo, lineal (a través de coeficientes en datos normalizados)
Para una serie de modelos basados en árboles y refuerzo, por ejemplo, el método de explicaciones de aditivos SHapley es adecuado.
FORMA
Es uno de los métodos de análisis del modelo que le permite mirar bajo el capó del modelo.
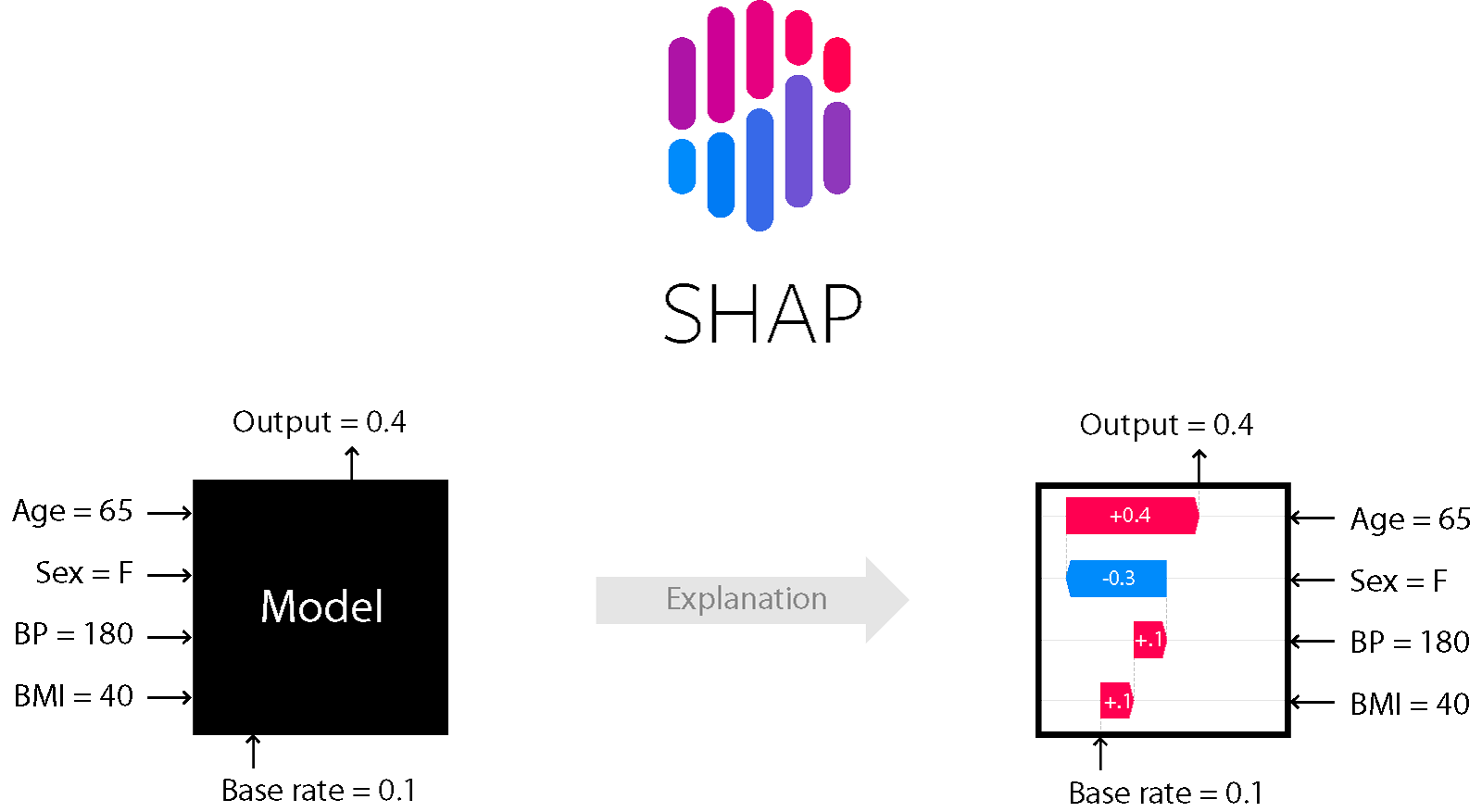
Le permite evaluar la dirección del efecto:

Además, para los árboles (y los métodos basados en ellos) es preciso. Lea más sobre esto aquí .
Nivel de ruido: estabilidad, dependencia lineal, detección de valores atípicos, etc.
La resistencia al ruido y todas estas alegrías de la vida es un tema aparte y debe analizar cuidadosamente el nivel de ruido, así como seleccionar los métodos adecuados. Si está seguro de que habrá valores atípicos en los datos, debe limpiarlos correctamente y aplicar métodos resistentes al ruido (alto sesgo, regularización, etc.).
Además, las señales pueden ser colineales y pueden estar presentes señales sin sentido; diferentes modelos reaccionan de manera diferente a esto. Aquí hay un ejemplo del conjunto de datos clásico German Credit Data (UCI) y tres modelos de aprendizaje simples (relativamente):
- Clasificador de regresión de crestas: regresión clásica con el regularizador de Tikhonov
- Árboles de decisión
- CatBoost de Yandex
Regresión de crestas
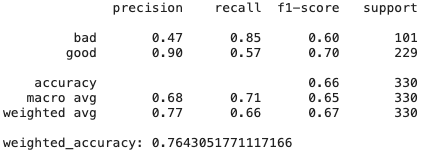
# Create Ridge regression classifier
ridge_clf = RidgeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
ridge_model = ridge_clf.fit(X_train, y_train)
y_pred = ridge_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Árboles de decisión
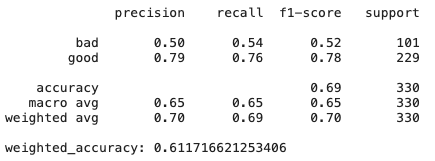
# Create Ridge regression classifier
dt_clf = DecisionTreeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
dt_model = dt_clf.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:", weighted_accuracy(y_test,y_pred))
CatBoost

# Create boosting classifier
catboost_clf = CatBoostClassifier(class_weights=class_weight, random_state=42, cat_features = X.select_dtypes(include=['category', object]).columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# Train model
catboost_model = catboost_clf.fit(X_train, y_train, verbose=False)
y_pred = catboost_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
Como podemos ver, simplemente el modelo de regresión de cresta, que tiene un alto sesgo y regularización, muestra resultados incluso mejores que CatBoost; hay muchas características que no son muy útiles y colineales, por lo que los métodos que son resistentes a ellas muestran buenos resultados.
Más sobre DT: ¿qué pasa si cambia un poco el conjunto de datos? La importancia de las características puede variar ya que los árboles de decisión son generalmente métodos sensibles, incluso para la mezcla de datos.
Conclusión: a veces más fácil es mejor y más eficaz.
Escalabilidad
¿Realmente necesitas Spark o redes neuronales con miles de millones de parámetros?
En primer lugar, debe evaluar con sensatez la cantidad de datos, ya hemos visto el uso masivo de Spark en tareas que caben fácilmente en la memoria de una máquina.
Spark complica la depuración, agrega gastos generales y complica el desarrollo; no debe usarlo donde no lo necesite. Clásicos .
En segundo lugar, por supuesto, debe evaluar la complejidad del modelo y relacionarlo con la tarea. Si sus competidores muestran excelentes resultados y tienen RandomForest en ejecución, puede valer la pena pensarlo dos veces si necesita una red neuronal con miles de millones de parámetros.
Y, por supuesto, debe tener en cuenta que si realmente tiene grandes datos, entonces el modelo debe poder trabajar con ellos: cómo aprender de los lotes o tener algún tipo de mecanismo de aprendizaje distribuido (y así sucesivamente). Y en el mismo lugar, no pierdas demasiado de velocidad con un aumento en la cantidad de datos. Por ejemplo, sabemos que los métodos del kernel requieren un cuadrado de memoria para los cálculos en el espacio dual; si espera un aumento de 10 veces en el tamaño de los datos, debe pensar dos veces antes de encajar en los recursos disponibles.
Disponibilidad de modelos confeccionados
Otro detalle importante es la búsqueda de modelos ya entrenados que puedan ser entrenados previamente, ideal si:
- No hay muchos datos, pero son muy específicos de nuestra tarea, por ejemplo, textos médicos.
- El tema en general es relativamente popular, por ejemplo, resaltar temas de texto, muchos trabajos en PNL.
- Su enfoque permite, en principio, el preaprendizaje, como por ejemplo con algún tipo de redes neuronales.
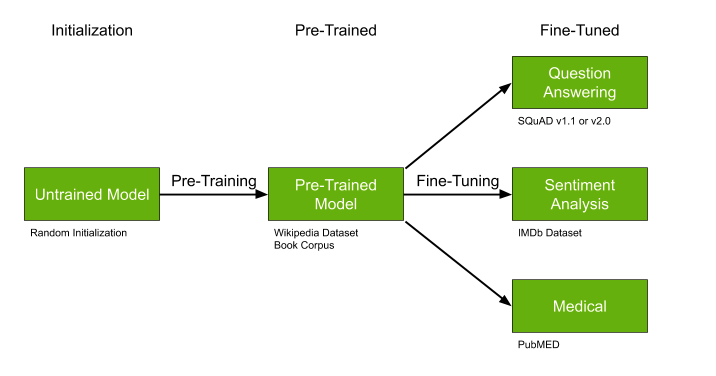
Los modelos previamente entrenados como GPT-2 y BERT pueden simplificar significativamente la solución de su problema, y si ya existen modelos entrenados, le recomiendo que no se pierda y aproveche esta oportunidad.
Interacciones de características y modelos lineales
Algunos modelos funcionan mejor cuando no hay interacciones complejas entre características, por ejemplo, toda la clase de modelos lineales, modelos aditivos generalizados. Hay una extensión de estos modelos para el caso de interacción entre dos características llamadas GA2M - Modelos aditivos generalizados con interacciones por pares.
Por regla general, estos modelos muestran buenos resultados con dichos datos, están excelentemente regularizados, son interpretables y resistentes al ruido. Por lo tanto, definitivamente vale la pena prestarles atención.
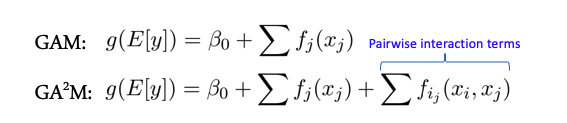
Sin embargo, si los signos interactúan activamente en grupos de más de 2, estos métodos ya no muestran tan buenos resultados.
Compatibilidad con paquetes y modelos
Muchos algoritmos y modelos interesantes de artículos están diseñados como un módulo o paquete para python, R, etc. Realmente vale la pena pensarlo dos veces antes de usar y confiar en una solución de este tipo a largo plazo (digo esto, como una persona que ha escrito muchos artículos sobre ML con dicho código). La probabilidad de que en un año no haya soporte es muy alta, porque lo más probable es que el autor ahora necesite involucrarse en otros proyectos, no hay tiempo ni incentivos para invertir en el desarrollo del módulo o repositorio.
En este sentido, las bibliotecas a la scikit learn son buenas precisamente porque tienen un grupo garantizado de entusiastas alrededor y si algo se rompe seriamente, tarde o temprano lo arreglarán.
Sesgos y equidad
Junto con la toma de decisiones automática, las personas que no están satisfechas con tales decisiones cobran vida; imagine que tenemos algún tipo de sistema de clasificación para las solicitudes de beca o beca de investigación en una universidad. Nuestra universidad será inusual: solo hay dos grupos de estudiantes: historiadores y matemáticos. Si de repente el sistema, sobre la base de sus datos y lógica, entregó repentinamente todas las subvenciones a los historiadores y no las otorgó a ningún matemático, esto no puede ofender débilmente a los matemáticos. Llamarán sesgado a tal sistema. Ahora solo los perezosos no hablan de esto, y las empresas y las personas se están demandando entre sí.
De manera convencional, imagine un modelo simplificado que simplemente cuente las citas de los artículos y deje que los historiadores se citen entre sí de forma activa (el promedio es de 100 citas, pero no hay matemáticas, tienen un promedio de 20) y escriben poco, entonces el sistema reconoce a todos los historiadores como "buenos" porque la tasa de citas es alta 100> 60 (promedio), y matemáticos, como "malos" porque todos tienen una tasa de citas mucho más baja que el promedio de 20 <60. Un sistema así difícilmente puede parecer adecuado para alguien.
Los clásicos ahora presentan la lógica de la toma de decisiones y los modelos de entrenamiento que luchan contra un enfoque tan sesgado. Por lo tanto, para cada decisión, tiene una explicación (condicional) por qué se tomó y cómo realmente hizo un esfuerzo para asegurarse de que el modelo no hiciera tonterías (ELI5 GDPR).

Leer más de Google aquí, o en el artículo aquí .
En general, muchas empresas han comenzado tales actividades, especialmente a la luz de la publicación del RGPD; tales medidas y controles pueden ayudar a evitar problemas en el futuro.
Si algún tema le interesó más que otros, escriba en los comentarios, profundizaremos. (DFS)!
