
En abril de 2020, Citizenlab informó un cifrado bastante débil para Zoom y declaró que Zoom estaba usando el códec de audio SILK. Desafortunadamente, el artículo no contenía los datos iniciales para confirmar esto y darme la oportunidad de consultarlo en el futuro. Sin embargo, gracias a Natalie Silvanovich de Google Project Zeroy para la herramienta de rastreo Frida, pude obtener un volcado de algunos marcos de SILK sin procesar. Su análisis me inspiró a echar un vistazo a cómo WebRTC maneja el audio. Cuando se trata de la calidad de llamada percibida en general, es la calidad de audio la que más afecta, ya que tendemos a notar incluso pequeños fallos. Solo diez segundos de análisis fueron suficientes para emprender una verdadera aventura: buscar opciones para mejorar la calidad del sonido proporcionada por WebRTC.
Traté con el cliente Zoom nativo en 2017 (antes de la publicación de DataChannel ) y noté que sus paquetes de audio a veces eran muy grandes en comparación con los paquetes de soluciones basados en WebRTC:

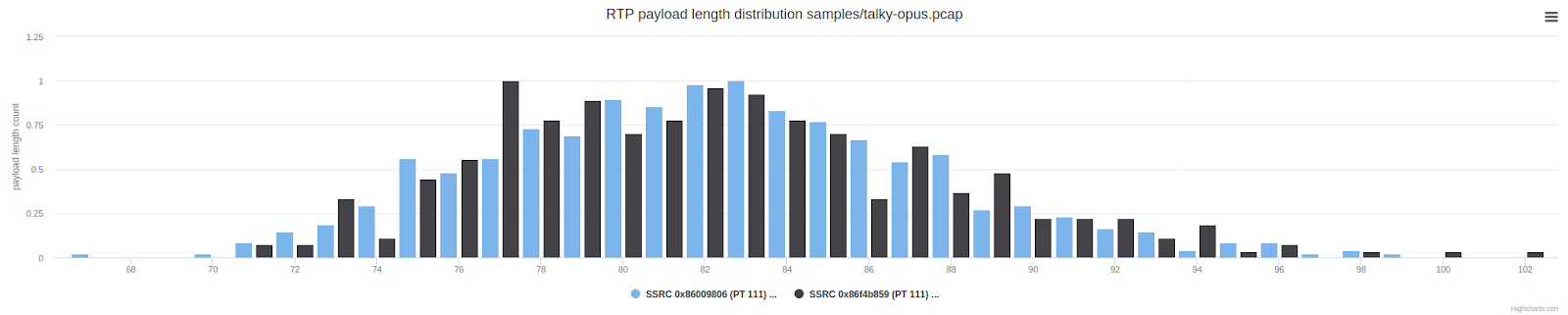
El gráfico anterior muestra la cantidad de paquetes con una longitud de carga útil UDP específica. Los paquetes entre 150 y 300 bytes son inusuales en comparación con una llamada típica de WebRTC. Son mucho más largos que los paquetes que solemos recibir de Opus. Sospechamos que había control de errores hacia adelante (FEC) o redundancia, pero sin acceso a marcos no cifrados, era difícil sacar más conclusiones o hacer algo.
Las tramas SILK sin cifrar del nuevo volcado mostraron una distribución muy similar. Después de convertir los marcos en un archivo y luego reproducir un mensaje corto (gracias a Giacomo Vacca por una publicación de blog muy útildescribiendo los pasos necesarios) volví a Wireshark y miré los paquetes. Aquí hay un ejemplo de tres paquetes que encontré particularmente interesantes:
packet 7:
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbb7f
packet 8:
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
packet 9:
e93997d503c0601e918d1445e5e985d2f57736614e7f1201711760e4772b020212dc
854000ac6a80fb9a5538741ddd2b5159070ebbf79d5d83363be59f10ef
e790ba4908639115e02b457676ea75bfe50727bb1c44144d37f74756f90e1ab926ef
930a3ffc36c6a8e773a780202af790acfbd6a4dff79698ea2d96365271c3dff86ce6396
203453951f00065ec7d26a03420496f
e9e4ab17ad8b9b5176b1659995972ac9b63737f8aa4d83ffc3073d3037b452fe6e1ee
5e6e68e6bcd73adbd59d3d31ea5fdda955cbaefEl paquete 9 contiene dos paquetes anteriores, paquete 8 - 1 paquete anterior. Esta redundancia es causada por el uso del formato LBRR - Low Bit-Rate Redundancy, que se demostró mediante un estudio profundo del decodificador SILK (se puede encontrar en el proyecto de Internet proporcionado por el equipo de Skype , o en el repositorio de GitHub ):

Zoom usa SKP_SILK_LBRR_VER1 pero con dos paquetes de respaldo. Si cada paquete UDP contiene no solo el cuadro de audio actual, sino también los dos anteriores, será robusto incluso si pierde dos de los tres paquetes. Entonces, ¿quizás la clave para la calidad del sonido de Zoom es la receta secreta de Skype de la abuela?
Opus FEC
¿Cómo puedo lograr lo mismo con WebRTC? El siguiente paso obvio fue considerar Opus FEC.
El LBRR de SILK (Low Rate Reservation) también se encuentra en Opus (recuerde que Opus es un códec híbrido que usa SILK para el extremo inferior del rango de bitrate). Sin embargo, Opus SILK es muy diferente del SILK original, cuyo código fuente fue descubierto una vez por Skype, al igual que la parte de LBRR que se usa en el modo de control de errores.
En Opus, el control de errores no se agrega simplemente después del cuadro de audio original, sino que lo precede y se codifica en el flujo de bits. Intentamos experimentar agregando nuestro propio control de errores usando la API Insertable Streams , pero esto requirió una transcodificación completa para insertar la información en el bitstream antes del paquete real.
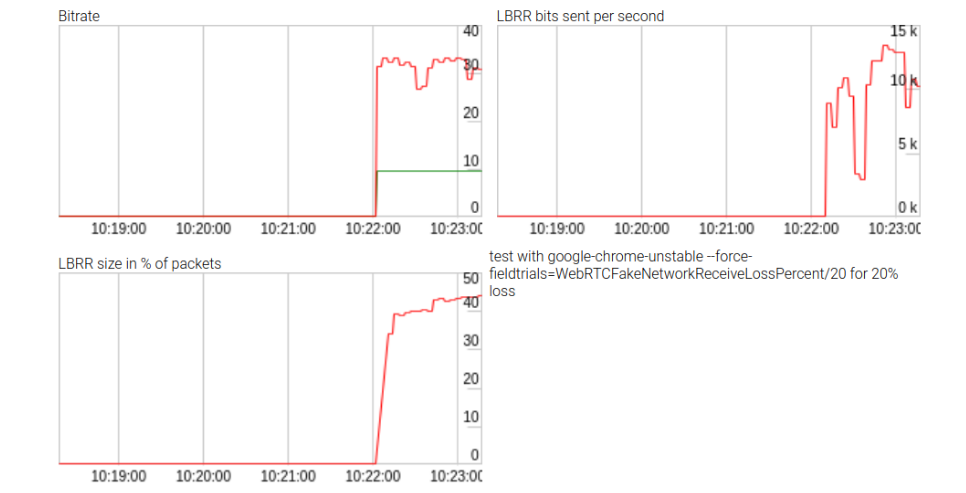
Aunque los esfuerzos no tuvieron éxito, generaron algunas estadísticas sobre el impacto de LBRR, que se muestran en la figura anterior. LBRR utiliza una tasa de bits de hasta 10 kbps (o dos tercios de la velocidad de datos) para una alta pérdida de paquetes. El repositorio está disponible aquí . Estas estadísticas no se muestran al llamar a la
getStats() API de WebRTC , por lo que los resultados fueron bastante entretenidos.
La necesidad de transcodificación no es el único problema con Opus FEC. Al final resultó que, su configuración en WebRTC es algo inútil:
- , , - . Slack 2016 . , .
- 25%. .
- FEC (. ).
Restar la tasa de bits de FEC de la tasa de bits máxima de destino no tiene ningún sentido: FEC está reduciendo activamente la tasa de bits del flujo principal. Un flujo de velocidad de bits más bajo generalmente resulta en una calidad más baja. Si no hay pérdida de paquetes que pueda corregirse con FEC, FEC solo degradará la calidad, no la mejorará. ¿Por qué sucede? La teoría principal es que la congestión es una de las razones de la pérdida de paquetes. Si experimenta congestión, no querrá enviar más datos porque eso solo empeorará el problema. Sin embargo, como describe Emil Ivov en su excelente charla KrankyGeek de 2017la congestión no siempre es la causa de la pérdida de paquetes. Además, este enfoque también ignora las transmisiones de video que lo acompañan. La estrategia FEC basada en la congestión para el audio Opus no tiene mucho sentido cuando está enviando cientos de kilobits de video junto con una transmisión Opus relativamente pequeña de 50 kbps. Quizás en el futuro veremos algunos cambios en libopus, pero por ahora me gustaría intentar deshabilitarlo, porque actualmente está habilitado en WebRTC por defecto .
Concluimos que esto no nos conviene ...
ROJO
Si queremos una redundancia real, RTP tiene una solución llamada RTP Payload for Redundant Audio Data, o RED. Es bastante antiguo, RFC 2198 se escribió en 1997 . La solución permite colocar múltiples cargas útiles RTP con diferentes marcas de tiempo en el mismo paquete RTP a un costo relativamente bajo.
Usar RED para colocar una o dos tramas de audio redundantes en cada paquete sería mucho más robusto contra la pérdida de paquetes que Opus FEC. Pero esto solo es posible duplicando o triplicando la tasa de bits de audio de 30 kbps a 60 o 90 kbps (con 10 kbps adicionales para el encabezado). Sin embargo, en comparación con más de 1 megabit de datos de video por segundo, eso no es tan malo.
La biblioteca WebRTC incluyó un segundo codificador y decodificador para RED, que ahora es redundante. A pesar de los intentos de eliminar el código RED de audio no utilizado , pude aplicar este codificador con relativamente poco esfuerzo. El historial completo de la solución está disponible en el sistema de seguimiento de errores de WebRTC.
Y está disponible como una prueba que se incluye cuando Chrome comienza con las siguientes banderas:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/Entonces, RED se puede habilitar mediante la negociación SDP; se mostrará así:
a=rtpmap:someid red/48000/2No está habilitado de forma predeterminada ya que hay entornos en los que usar ancho de banda adicional no es una buena idea. Para usar RED, cambie el orden de los códecs para que venga antes del códec Opus. Esto se puede hacer usando la API
RTCRtpTransceiver.setCodecPreferencescomo se muestra aquí . Obviamente otra alternativa es cambiar manualmente el SDP. El formato SDP también podría proporcionar una forma de configurar el nivel máximo de redundancia, pero la semántica de oferta-respuesta de RFC 2198 no era completamente clara, por lo que decidí posponer esto por un tiempo.
Puede demostrar cómo funciona todo esto ejecutándolo en un ejemplo de audio . Así es como se ve la versión anterior con un paquete de respaldo:
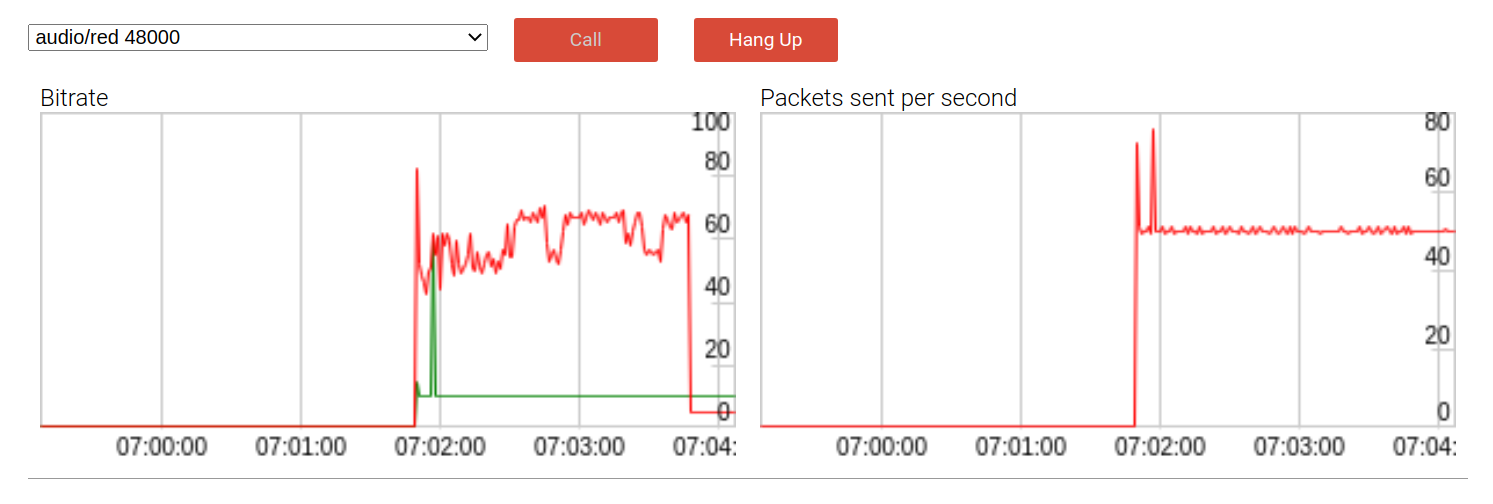
De forma predeterminada, la tasa de bits de la carga útil (línea roja) es casi el doble que sin redundancia, a casi 60 kbps. DTX (transferencia discontinua) es un mecanismo de conservación de ancho de banda que solo envía paquetes cuando se detecta voz. Como era de esperar, al usar DTX, el efecto de la tasa de bits se suaviza un poco, como podemos ver al final de la llamada.
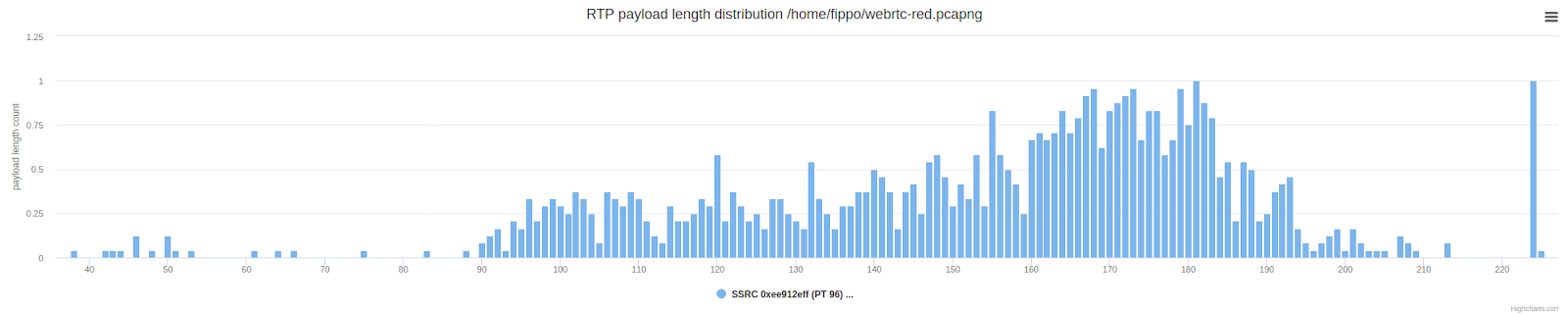
Verificar la longitud del paquete muestra el resultado esperado: los paquetes son, en promedio, dos veces más largos (más altos) en comparación con la distribución normal de la longitud de la carga útil que se muestra a continuación.
Esto sigue siendo ligeramente diferente de lo que hace Zoom, donde vimos reservas fraccionarias. Revisemos el gráfico de longitud de paquete de Zoom que se mostró anteriormente para ver una comparación:
Adición de compatibilidad con detección de actividad de voz (VAD)
Opus FEC envía datos de respaldo solo si hay actividad de voz en el paquete. Lo mismo debería aplicarse a la implementación de RED. Para ello, el codificador Opus debe cambiarse para mostrar la información correcta del VAD , que se define en el nivel SILK. Con esta configuración, la tasa de bits alcanza los 60 kbps solo en presencia de voz (en comparación con los 60+ kbps constantes):

y el "espectro" se parece más a lo que vimos con Zoom:

El cambio para lograrlo aún no ha aparecido.
Encontrar la distancia correcta
La distancia es la cantidad de paquetes de respaldo, es decir, la cantidad de paquetes anteriores en el actual. En el proceso de trabajar para encontrar la distancia correcta, encontramos que si ROJO en la distancia 1 es frío, entonces ROJO en la distancia 2 es aún más frío. Nuestra estimación de laboratorio simuló una pérdida aleatoria de paquetes del 60%. En este entorno, Opus + RED tuvo un sonido excelente, mientras que Opus sin RED se desempeñó mucho peor. La API getStats () de WebRTC proporciona una capacidad muy útil para medir esto comparando el porcentaje de muestras ocultas obtenidas al dividir las muestras ocultas por totalSamplesReceived .
En la página de muestras de audio, estos datos se pueden recuperar fácilmente con este fragmento de JavaScript pegado en la consola:
(await pc2.getReceivers()[0].getStats()).forEach(report => {
if(report.type === "track") console.log(report.concealmentEvents, report.concealedSamples, report.totalSamplesReceived, report.concealedSamples / report.totalSamplesReceived)})Ejecuté un par de pruebas de pérdida de paquetes usando una bandera no muy conocida pero muy útil
WebRTCFakeNetworkReceiveLossPercent:
--force-fieldtrials=WebRTC-Audio-Red-For-Opus/Enabled/WebRTCFakeNetworkReceiveLossPercent/20/Con una pérdida de paquetes del 20% y FEC habilitado de forma predeterminada, no hubo mucha diferencia en la calidad del audio, pero hubo una ligera diferencia en la métrica:
| guión | porcentaje de pérdida |
|---|---|
| sin rojo | Dieciocho% |
| no rojo, FEC desactivado | 20% |
| rojo con distancia 1 | 4% |
| rojo con distancia 2 | 0,7% |
Sin RED o FEC, la métrica casi coincide con la pérdida de paquetes solicitada. Hay un efecto de FEC, pero es pequeño.
Sin RED, con una pérdida del 60%, la calidad del sonido se volvió bastante pobre, un poco metálica y las palabras difíciles de entender:
| guión | porcentaje de pérdida |
|---|---|
| sin rojo | 60% |
| rojo con distancia 1 | 32% |
| rojo con distancia 2 | Dieciocho% |
Hubo algunos artefactos audibles en RED con distancia = 1, pero un sonido casi perfecto a distancia 2 (que es la cantidad de redundancia actualmente en uso).
Existe la sensación de que el cerebro humano puede soportar cierto nivel de silencio que se produce de forma irregular. (Y Google Duo parece estar usando un algoritmo de aprendizaje automático para llenar el silencio).
Midiendo el desempeño en el mundo real
Esperamos que la inclusión de RED en Opus mejore la calidad del sonido, aunque en algunos casos puede empeorarlo. Emil Ivov se ofreció como voluntario para realizar un par de pruebas auditivas utilizando el método POLQA-MOS. Esto ya se ha hecho para Opus, por lo que tenemos una línea de base para comparar.
Si las pruebas iniciales muestran resultados prometedores, realizaremos un experimento a gran escala en el escaneo principal de Jitsi Meet, aplicando las métricas de pérdida porcentual que usamos anteriormente.
Tenga en cuenta que para los servidores de medios y las SFU, habilitar RED es un poco más difícil porque es posible que el servidor necesite administrar la retransmisión RED para clientes seleccionados, como si no todos los clientes admitieran conferencias RED. Además, algunos clientes pueden estar en un canal de ancho de banda limitado donde no se requiere RED. Si el punto final no admite RED, la SFU puede eliminar la codificación innecesaria y enviar Opus sin un contenedor. Asimismo, puede implementar RED por sí mismo y usarlo al reenviar paquetes desde un punto final que transmite Opus a un punto final que admita RED.
Muchas gracias a Jitsi / 8 × 8 Inc por patrocinar esta emocionante aventura y a la gente de Google que analizaron y proporcionaron comentarios sobre los cambios necesarios.
¡Y sin Natalie Silvanovich, me habría sentado mirando los bytes cifrados!