 ¡Hola habitantes! El libro Ingeniería de confiabilidad del sitio provocó una acalorada discusión. ¿Qué funciona hoy en día y por qué son tan fundamentales los problemas de fiabilidad? Ahora, los ingenieros de Google detrás de este libro más vendido proponen pasar de la teoría a la práctica: el Libro de trabajo de confiabilidad del sitio muestra cómo los principios y prácticas de SRE se traducen en su producción La experiencia de Google se complementa con los casos de usuario de Google Cloud Platform. Representantes de Evernote, The Home Depot, The New York Times y otras compañías describen su experiencia de combate, dicen qué prácticas han adoptado y cuáles no. Este libro le ayudará a adaptar la SRE a las realidades de su propia práctica, sin importar el tamaño de su empresa. Aprenderás a:
¡Hola habitantes! El libro Ingeniería de confiabilidad del sitio provocó una acalorada discusión. ¿Qué funciona hoy en día y por qué son tan fundamentales los problemas de fiabilidad? Ahora, los ingenieros de Google detrás de este libro más vendido proponen pasar de la teoría a la práctica: el Libro de trabajo de confiabilidad del sitio muestra cómo los principios y prácticas de SRE se traducen en su producción La experiencia de Google se complementa con los casos de usuario de Google Cloud Platform. Representantes de Evernote, The Home Depot, The New York Times y otras compañías describen su experiencia de combate, dicen qué prácticas han adoptado y cuáles no. Este libro le ayudará a adaptar la SRE a las realidades de su propia práctica, sin importar el tamaño de su empresa. Aprenderás a:
- Garantice la confiabilidad de los servicios en las nubes y los entornos que no controla por completo;
- aplicar diversos métodos de creación, lanzamiento y seguimiento de servicios, centrándose en SLO;
- transformar equipos de administración en ingenieros de SRE;
- Implementar métodos para iniciar SRE desde cero y basados en sistemas existentes. Betsy Beyer, Neil Richard Murphy, David Renzin, Kent Kawahara y Stephen Thorne están involucrados en garantizar la confiabilidad de los sistemas de Google.
Gestión del sistema de seguimiento
Su sistema de monitoreo es tan importante como cualquier otro servicio que utilice. Por tanto, la monitorización debe tratarse con el debido cuidado.
Trate su configuración como código Tratar la
configuración de su sistema como código y almacenarla en un sistema de control de versiones es una práctica común, con características como almacenar el historial de cambios, vincular cambios específicos al sistema de administración de tareas, reversiones simplificadas, análisis de código estático para detectar errores y procedimientos de inspección de código forzado.
También recomendamos encarecidamente tratar la configuración de monitorización como código (más sobre configuración en el capítulo 14). Un sistema de monitoreo que admite la personalización mediante descripciones bien formadas de objetivos y funciones, en lugar de sistemas que solo proporcionan interfaces web o API de estilo CRUD (http://bit.ly/1G4WdV1). Este enfoque de configuración es estándar para muchos binarios de código abierto que solo leen un archivo de configuración. Algunas soluciones de terceros como grafanalib (http://bit.ly/2so5Wrx) admiten este enfoque para componentes que tradicionalmente se pueden personalizar mediante la interfaz de usuario.
Fomentar la coherencia
Las grandes empresas con varios equipos de proyectos que utilizan la supervisión deben lograr un equilibrio delicado: por un lado, un enfoque centralizado garantiza la coherencia, pero por otro lado, los equipos individuales pueden querer tener un control total sobre cómo funciona su configuración.
La decisión correcta depende del tipo de organización. Con el tiempo, el enfoque de Google ha evolucionado para reunir todas las mejores prácticas en una única plataforma que funciona como un servicio centralizado. Esta es una buena decisión para nosotros y hay varias razones para ello. Una infraestructura unificada permite a los ingenieros pasar de un equipo a otro de forma más rápida y sencilla y facilita la colaboración durante la depuración. Además, hay un servicio de tablero centralizado donde los tableros de cada equipo están abiertos y accesibles. Si comprende bien la información proporcionada por el otro equipo, puede solucionar rápidamente sus propios problemas y los problemas de otros equipos.
Siempre que sea posible, mantenga la cobertura de monitoreo básica lo más simple posible. Si todos sus servicios exportan un conjunto coherente de líneas base, puede recopilar automáticamente esas métricas en toda su organización y proporcionar un conjunto coherente de paneles. Este enfoque significa que existe un monitoreo básico para cualquier componente nuevo que inicie automáticamente. De esta forma, muchos equipos de su empresa, ni siquiera los de ingeniería, podrán utilizar los datos de supervisión.
Prefiera los lazos débiles
Los requisitos comerciales cambian y su sistema de producción se verá diferente en un año. Al igual que los servicios que usted controla, su sistema de monitoreo debe desarrollarse y evolucionar con el tiempo, pasando por varios problemas típicos.
Recomendamos que el acoplamiento entre los componentes de su sistema de control no sea muy fuerte. Debe tener interfaces confiables para configurar cada componente y transferir datos de monitoreo. Los diferentes componentes deben ser responsables de recopilar, almacenar, alertar y visualizar sus datos de monitoreo. Las interfaces estables facilitan la sustitución de cualquier componente en particular por la alternativa más adecuada.
En el mundo del código abierto, se está volviendo popular dividir la funcionalidad en componentes separados. Hace diez años, los sistemas de monitoreo como Zabbix (https://www.zabbix.com/) combinaban todas las funciones en un solo componente. El diseño moderno generalmente implica separar la recopilación y ejecución de reglas (utilizando soluciones como el servidor Prometheus (https://prometheus.io/)), almacenar series de tiempo a largo plazo (InfluxDB, www.influxdata.com ), agregar alertas ( Alertmanager, bit.ly/2soB22b ) y creación de cuadros de mando (Grafana, grafana.com ).
En el momento de escribir este artículo, existen al menos dos estándares abiertos populares que le permiten equipar el software con las herramientas necesarias y proporcionar métricas:
- statsd — , Etsy, ;
- Prometheus — , . Prometheus OpenMetrics (https://openmetrics.io/).
Un sistema de tablero separado que utiliza múltiples fuentes de datos proporciona una vista centralizada y unificada de su servicio. Google experimentó recientemente esta ventaja en la práctica: nuestro sistema de monitoreo heredado (Borgmon1) incluía paneles en la misma configuración que las reglas de alerta. Al cambiar a un nuevo sistema (Monarch, youtu.be/LlvJdK1xsl4 ), decidimos mover los paneles a un servicio separado (Viceroy, bit.ly/2sqRwad ). Viceroy no era un componente Borgmon o Monarch, por lo que Monarch tenía menos requisitos funcionales. Dado que los usuarios pueden usar Viceroy para mostrar gráficos basados en datos de ambos sistemas de monitoreo, pudieron migrar gradualmente de Borgmon a Monarch.
Métricas significativas El
Capítulo 5 le muestra cómo utilizar las métricas de calidad de servicio (SLI) para rastrear e informar sobre las amenazas a su presupuesto. Las métricas SLI son las primeras métricas que se comprueban cuando se activan las alertas en función de los objetivos de calidad de servicio (SLO). Estas métricas deben aparecer en el panel de tu servicio, idealmente en la página principal.
Al investigar la causa raíz de una infracción de SLO, lo más probable es que no obtenga suficiente información de los paneles de SLO. Estos paneles muestran que hay violaciones, pero es poco probable que conozca las razones que las llevaron. ¿Qué otros datos deben mostrarse en el tablero?
Creemos que las siguientes pautas serán útiles al implementar métricas: Estas métricas deben proporcionar un seguimiento significativo que le permita investigar problemas operativos y proporcionar una amplia gama de información sobre sus servicios.
Cambios intencionales
Al diagnosticar alertas relacionadas con SLO, debe poder pasar de las métricas de alerta que le notifican los problemas que afectan a los usuarios a las métricas que le alertan sobre la causa raíz de esos problemas. Tales razones podrían ser cambios deliberados recientes en su servicio. Agregue monitoreo que le informe de cualquier cambio en la producción. Para detectar el hecho de que se han realizado cambios, recomendamos lo siguiente:
- monitorear la versión de un archivo binario;
- , ;
- , .
Si alguno de estos componentes no está versionado, debe rastrear cuándo se ensambló o empaquetó el componente por última vez.
Al intentar correlacionar los problemas emergentes del servicio con una implementación, es mucho más fácil mirar un gráfico o panel al que se hace referencia en una alerta que hojear los registros de CI / CD después del hecho.
Dependencias
Incluso si su servicio no ha cambiado, cualquiera de sus dependencias puede cambiar. Por lo tanto, también debe realizar un seguimiento de las respuestas provenientes de dependencias directas.
Es aconsejable exportar el tamaño de la solicitud y la respuesta en bytes, los tiempos de respuesta y los códigos de respuesta para cada dependencia. Al elegir una métrica para un gráfico, tenga en cuenta estas cuatro señales doradas (consulte la sección"Las cuatro señales de oro", Capítulo 6 de Ingeniería de confiabilidad del sitio ).
Puede utilizar etiquetas adicionales en las métricas para separarlas por código de respuesta, nombre del método RPC (llamada a procedimiento remoto) y el nombre del servicio al que se llama.
Idealmente, en lugar de pedir a cada biblioteca de cliente RPC que exporte dichas etiquetas, puede utilizar la biblioteca de cliente RPC de nivel inferior para este propósito una vez. Esto proporciona una mayor coherencia y le permite monitorear fácilmente nuevas dependencias.
Hay dependencias que ofrecen una API muy limitada, donde toda la funcionalidad está disponible a través de un único método RPC llamado Get, Query, o simplemente no informativo, y el comando real se especifica como argumentos para ese método. El enfoque de un solo punto para las herramientas en la biblioteca cliente no funciona para este tipo de dependencia: verá mucha variabilidad en la latencia y un cierto porcentaje de errores que pueden o no indicar que alguna parte de esta "turbia" La API se ha caído por completo. Si esta dependencia es crítica, se puede implementar una buena supervisión de la siguiente manera.
- Exporte métricas individuales diseñadas específicamente para esta dependencia, donde las solicitudes se descompondrán para obtener una señal válida.
- Solicite a los propietarios de la dependencia que la reescriban para exportar una API extendida que admita la separación de funciones entre métodos y servicios RPC individuales.
Nivel de carga
Es recomendable controlar y rastrear el uso de todos los recursos con los que trabaja el servicio. Algunos recursos tienen límites estrictos que no puede superar. Por ejemplo, el tamaño de la RAM, el disco duro asignado a su aplicación o la cuota de CPU. Es posible que otros recursos, como descriptores de archivos abiertos, subprocesos activos en cualquier grupo de subprocesos, tiempos de espera de cola o la cantidad de registros escritos, no tengan un límite estricto claro, pero aún así deben administrarse.
Dependiendo del lenguaje de programación que esté utilizando, debe realizar un seguimiento de algunos recursos adicionales:
- en Java, tamaño de montón y metaespacio (http://bit.ly/2J9g3Ha), así como métricas más específicas según el tipo de recolección de basura utilizada;
- en Go, el número de goroutines.
Los propios lenguajes de programación brindan soporte para realizar un seguimiento de estos recursos.
Además de alertarlo sobre eventos importantes, como se describe en el Capítulo 5, es posible que también desee configurar alertas que se activen cuando ciertos recursos se acercan al agotamiento crítico. Esto es útil, por ejemplo, en las siguientes situaciones:
- cuando el recurso tiene un límite estricto;
- cuando se produce una degradación del rendimiento cuando se supera el umbral de uso.
El seguimiento es fundamental para todos los recursos, incluso aquellos que el servicio gestiona bien. Estas métricas son vitales al planificar recursos y capacidades.
Estado del tráfico emitido
Se recomienda agregar métricas o etiquetas de métricas en el tablero que le permitirán dividir el tráfico emitido por código de estado (si las métricas utilizadas por su servicio para propósitos de SLI no contienen esta información). A continuación se muestran algunas pautas.
- Realice un seguimiento de todos los códigos de respuesta para el tráfico HTTP, incluso aquellos que, debido a un posible comportamiento incorrecto del cliente, no sean motivo para emitir alertas.
- Si está aplicando límites de tiempo o límites de cuota a sus usuarios, lleve un registro de la cantidad de solicitudes denegadas por falta de cuota.
Los gráficos de estos datos pueden ayudarlo a determinar cuándo cambia notablemente la tasa de error durante un cambio de producción.
Implementación de métricas objetivo
Cada métrica debe cumplir su propósito. No se sienta tentado a exportar varias métricas solo porque son fáciles de generar. En su lugar, piense en cómo se utilizarán. La arquitectura de métricas (o la falta de ella) tiene implicaciones. Idealmente, los valores métricos usados para alertar cambian abruptamente solo cuando ocurre un problema en el sistema, pero durante el funcionamiento normal permanecen sin cambios. Por otro lado, estos requisitos no se imponen a las métricas de depuración; deberían dar una idea de lo que sucede cuando se activa una alerta. Una buena métrica de depuración indicará partes potencialmente problemáticas del sistema. Al escribir una autopsia, considere qué métricas adicionales le permitirían diagnosticar el problema más rápido.
Probando la lógica de alerta
En un mundo ideal, el código de monitoreo y alerta debería seguir los mismos estándares de prueba que el código de desarrollo. Actualmente no existe un sistema ampliamente aceptado que le permita implementar tal concepto. Una de las primeras señales es la funcionalidad de prueba de unidad de reglas recién agregada a Prometheus.
En Google, probamos nuestros sistemas de monitoreo y alerta utilizando un lenguaje específico de dominio que nos permite crear series de tiempo sintéticas. Luego, verificamos los valores en la serie de tiempo derivada o aclaramos si se ha activado una alerta específica y tiene la etiqueta requerida.
El monitoreo y la emisión de alertas es a menudo un proceso de varios pasos, por lo que se requieren varias familias de pruebas unitarias.
Si bien esta área permanece en gran parte subdesarrollada, si desea implementar las pruebas de monitoreo en algún momento, recomendamos un enfoque de tres niveles, como se muestra en la Figura 1. 4.1.
- Archivos binarios. Asegúrese de que las variables métricas exportadas cambien los valores como se esperaba en determinadas condiciones.
- Monitoreo de infraestructura. Asegúrese de que se sigan las reglas y que las condiciones específicas sean las alertas esperadas.
- Gestor de alertas. Verifique que las alertas generadas se envíen a un destino predefinido según los valores de la etiqueta.
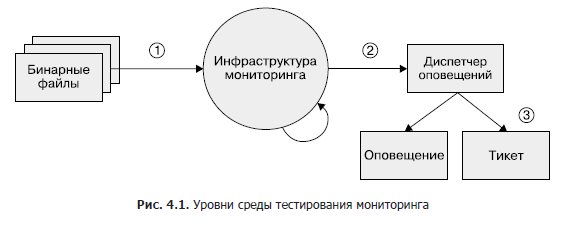
Si no puede probar su sistema de monitoreo con herramientas sintéticas, o si un paso no se puede probar en absoluto, considere la posibilidad de crear un sistema de producción que exporte métricas conocidas, como solicitudes y errores. Puede utilizar este sistema para comprobar series de tiempo y alertas. Es probable que sus reglas de alerta no se activen durante meses o años después de haberlas configurado, y debe asegurarse de que cuando la métrica exceda un cierto umbral, las alertas sigan siendo significativas y se envíen a los ingenieros previstos.
Resumen del capítulo
Dado que los ingenieros de SR deben ser responsables de la confiabilidad de los sistemas de producción, a menudo se requiere que estos especialistas tengan un conocimiento profundo del sistema de monitoreo y sus funciones y que trabajen en estrecha colaboración con él. Sin estos datos, es posible que los SRE no sepan dónde buscar y cómo identificar el comportamiento anormal del sistema o cómo encontrar la información que necesitan durante una emergencia.
Esperamos que al señalar las funciones del sistema de monitoreo que son útiles desde nuestro punto de vista y justificar nuestra elección, podamos ayudarlo a evaluar cómo su sistema de monitoreo satisface sus necesidades. Además, lo ayudaremos a explorar algunas de las funciones adicionales que puede utilizar y a revisar los cambios que probablemente desee realizar. Lo más probable es que le resulte útil combinar fuentes de métricas y registros en su estrategia de seguimiento. La combinación correcta de métricas y registros depende en gran medida del contexto.
Asegúrese de recopilar métricas que tengan un propósito específico. Estos son objetivos como mejorar la programación del ancho de banda, la depuración o la notificación de problemas que surjan.
Cuando tiene monitoreo, debe ser visual y útil. Para hacer esto, recomendamos probar su configuración. Un buen sistema de seguimiento paga dividendos. La planificación previa minuciosa de qué soluciones utilizar para cubrir mejor sus requisitos específicos, así como las continuas mejoras iterativas del sistema de monitoreo, es una inversión que dará sus frutos.
»Se pueden encontrar más detalles sobre el libro en el sitio web de la editorial
» Tabla de contenido
» Extracto
para los habitantes un 25% de descuento en el cupón - Google
Tras el pago de la versión impresa del libro, se envía un libro electrónico al correo electrónico.