El hecho es que todos nuestros equipos se basan en sistemas de información, microservicios y frentes separados, por lo que los equipos no ven el estado general de todo el sistema como un todo. Por ejemplo, es posible que no sepan cómo una pequeña parte del backend profundo afecta al front end. La gama de sus intereses se limita a los sistemas con los que se integra su sistema. Si el equipo y su servicio A no tienen casi nada que ver con el servicio B, entonces dicho servicio es casi invisible para el equipo.
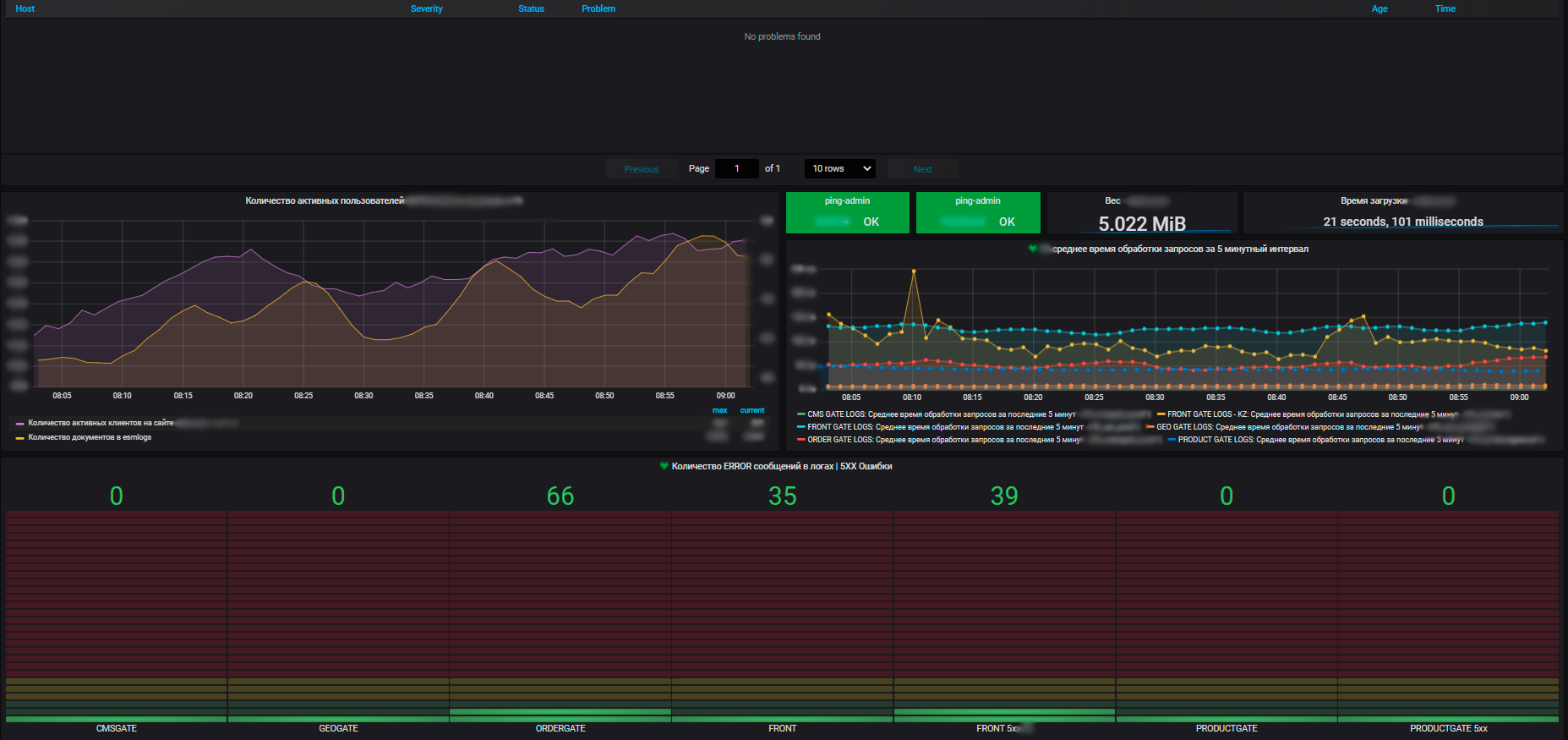
Nuestro equipo, a su vez, trabaja con sistemas que están muy fuertemente integrados entre sí: hay muchas conexiones entre ellos, esta es una infraestructura muy grande. Y el trabajo de la tienda online depende de todos estos sistemas (de los cuales, por cierto, tenemos un gran número).
Entonces resulta que nuestro departamento no pertenece a ningún equipo, pero es un poco distante. En toda esta historia, nuestra tarea es comprender de manera compleja cómo funcionan los sistemas de información, su funcionalidad, integraciones, software, red, hardware, y cómo todo esto se interconecta.
La plataforma en la que operan nuestras tiendas online tiene este aspecto:
- frente
- oficina central
- back-office
Tanto como nos gustaría, pero no existe tal cosa que todos los sistemas funcionen sin problemas y sin problemas. El punto, nuevamente, es la cantidad de sistemas e integraciones; con los que tenemos, algunos incidentes son inevitables, a pesar de la calidad de las pruebas. Además, tanto dentro de un sistema separado como en términos de su integración. Y debe monitorear el estado de toda la plataforma de manera integral, y no una parte separada de ella.
Idealmente, la supervisión del estado de toda la plataforma debería estar automatizada. Y llegamos al seguimiento como una parte inevitable de este proceso. Inicialmente, se construyó solo para la parte frontal, mientras que los administradores de redes, software y hardware tenían sus propios sistemas de monitoreo por capas. Todas estas personas siguieron el monitoreo solo a su propio nivel; nadie tenía una comprensión integral tampoco.
Por ejemplo, si una máquina virtual falla, en la mayoría de los casos solo el administrador responsable del hardware y la máquina virtual lo saben. En tales casos, el equipo frontal vio el hecho mismo del bloqueo de la aplicación, pero no tenían datos sobre el bloqueo de la máquina virtual. Y el administrador puede saber quién es el cliente e imaginar aproximadamente lo que se está ejecutando en esta máquina virtual en este momento, siempre que se trate de algún tipo de proyecto grande. Probablemente no sepa sobre los pequeños. En cualquier caso, el administrador debe dirigirse al propietario, preguntar qué había en esta máquina, qué se debe restaurar y qué cambiar. Y si se averiaba algo muy grave, empezaban a correr en círculos, porque nadie veía el sistema en su conjunto.
En última instancia, estas historias dispares afectan a todo el front-end, los usuarios y nuestra función comercial principal, las ventas en línea. Como no formamos parte de un equipo, sino que participamos en el funcionamiento de todas las aplicaciones de comercio electrónico como parte de una tienda en línea, asumimos la tarea de crear un sistema de monitoreo integral para la plataforma de comercio electrónico.
Estructura y pila del sistema
Comenzamos identificando varias capas de monitoreo para nuestros sistemas, en cuyo contexto necesitamos recopilar métricas. Y todo esto tenía que combinarse, lo que hicimos en la primera etapa. Ahora, en esta etapa, estamos finalizando la colección de métricas de la más alta calidad para todas nuestras capas con el fin de construir una correlación y comprender cómo los sistemas se afectan entre sí.
La falta de un monitoreo integral en las etapas iniciales de lanzamiento de aplicaciones (desde que comenzamos a construirlo cuando la mayoría de los sistemas estaban en funcionamiento) llevó al hecho de que teníamos una deuda técnica significativa para configurar el monitoreo de toda la plataforma. No podíamos permitirnos el lujo de centrarnos en configurar el monitoreo de un solo SI y trabajar en el monitoreo en detalle, ya que el resto de los sistemas se habrían dejado sin monitoreo durante algún tiempo. Para solucionar este problema, hemos identificado una lista de las métricas más necesarias para evaluar el estado del sistema de información por capas y comenzamos a implementarlo.
Por lo tanto, decidieron comerse al elefante en partes.
Nuestro sistema consta de:
- hardware;
- sistema operativo;
- software;
- Partes de la interfaz de usuario en la aplicación de monitoreo;
- métricas comerciales;
- aplicaciones de integración;
- seguridad de información;
- redes;
- equilibrador de tráfico.
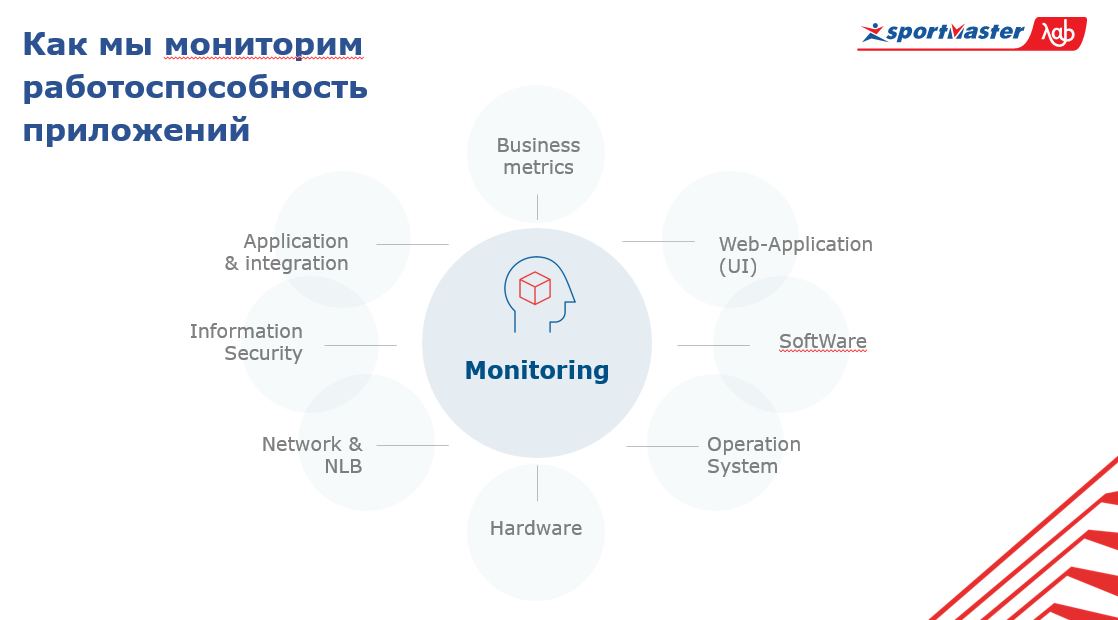
En el centro de este sistema se encuentra el monitoreo a sí mismo. Para comprender en general el estado de todo el sistema, debe saber qué está sucediendo con las aplicaciones en todas estas capas y en el contexto de todo el conjunto de aplicaciones.
Entonces, sobre la pila.

Usamos software de código abierto. En el centro tenemos Zabbix, que usamos principalmente como sistema de alerta. Todo el mundo sabe que es ideal para supervisar la infraestructura. ¿Qué significa esto? Estas son las métricas de bajo nivel que tiene cada empresa que tiene su propio centro de datos (y Sportmaster tiene sus propios centros de datos): temperatura del servidor, estado de la memoria, incursión, métricas de dispositivos de red.
Hemos integrado Zabbix con Telegram messenger y Microsoft Teams, que se utilizan activamente en equipos. Zabbix cubre la capa de la red real, el hardware y parcialmente el software, pero no es una panacea. Enriquecemos estos datos de algunos otros servicios. Por ejemplo, en términos de nivel de hardware, nos conectamos directamente a través de la API a nuestro sistema de virtualización y recopilamos datos.
Qué más. Además de Zabbix, usamos Prometheus, que permite monitorear métricas en una aplicación de entorno dinámico. Es decir, podemos recibir métricas de la aplicación a través del punto final HTTP y no preocuparnos por qué métricas cargar en él y cuáles no. Basándose en estos datos, puede realizar consultas analíticas.
Las fuentes de datos para otras capas, por ejemplo, métricas comerciales, se dividen en tres componentes.
En primer lugar, estos son sistemas comerciales externos, Google Analytics, recopilamos métricas de registros. De ellos obtenemos datos de usuarios activos, conversiones y todo lo demás relacionado con el negocio. En segundo lugar, es un sistema de monitoreo de UI. Debería describirse con más detalle.
Érase una vez, comenzamos con las pruebas manuales y se ha convertido en pruebas automáticas funcionales y de integración. Hicimos un seguimiento de él, dejando solo la funcionalidad principal, y lo atamos a marcadores que son lo más estables posible y que no cambian a menudo con el tiempo.
La nueva estructura de equipo implica que toda la actividad de la aplicación está bloqueada en equipos de producto, por lo que dejamos de hacer pruebas puras. En su lugar, realizamos el monitoreo de la interfaz de usuario a partir de pruebas, escritas en Java, Selenium y Jenkins (utilizadas como un sistema para iniciar y generar informes).
Tuvimos muchas pruebas, pero al final decidimos ir a la carretera principal, la métrica de nivel superior. Y si tenemos muchas pruebas específicas, será difícil mantener los datos actualizados. Cada versión posterior romperá significativamente todo el sistema, y solo nos ocuparemos de arreglarlo. Por lo tanto, nos atamos a cosas muy fundamentales que rara vez cambian y solo las monitoreamos.
Finalmente, en tercer lugar, la fuente de datos es un sistema de registro centralizado. Para los registros, usamos Elastic Stack y luego podemos arrastrar estos datos a nuestro sistema de monitoreo para métricas comerciales. Además de todo esto, funciona nuestro propio servicio de API de monitorización, escrito en Python, que sondea cualquier servicio a través de la API y lleva datos de ellos a Zabbix.
Otro atributo insustituible del seguimiento es la visualización. Lo construimos sobre la base de Grafana. Entre otros sistemas de visualización, destaca que es posible visualizar métricas de diferentes fuentes de datos en el tablero. Podemos recopilar las métricas de nivel superior de la tienda online, por ejemplo, el número de pedidos realizados en la última hora desde el DBMS, las métricas de rendimiento del sistema operativo que está ejecutando esta tienda online desde Zabbix, y las métricas de las instancias de esta aplicación de Prometheus. Y todo esto estará en un solo tablero. Visual y accesible.
Permítanme señalar acerca de la seguridad: ahora estamos finalizando el sistema, que posteriormente integraremos con el sistema de monitoreo global. En mi opinión, los principales problemas a los que se enfrenta el comercio electrónico en el ámbito de la seguridad de la información están asociados a los bots, los analizadores sintácticos y la fuerza bruta. Esto debe ser monitoreado porque todos pueden afectar críticamente tanto el desempeño de nuestras aplicaciones como la reputación desde un punto de vista comercial. Y con la pila elegida, cubrimos con éxito estas tareas.
Otro punto importante es que Prometheus recopila la capa de aplicación. Él mismo también está integrado con Zabbix. Y también tenemos sitespeed, un servicio que nos permite mirar en consecuencia parámetros como la velocidad de carga de nuestra página, cuellos de botella, representación de la página, carga de scripts, etc., también está integrado a través de la API. Entonces las métricas se recopilan en Zabbix, respectivamente, también alertamos desde allí. Todas las alertas hasta ahora van a los principales métodos de envío (por ahora, estos son correo electrónico y telegrama, se han conectado recientemente a MS Teams). Los planes son impulsar la alerta a un estado tal que los bots inteligentes funcionen como un servicio y proporcionen información de monitoreo a todos los equipos de productos interesados.
Para nosotros, no solo las métricas de los sistemas de información individuales son importantes, sino también las métricas generales para toda la infraestructura que utilizan las aplicaciones: clústeres de servidores físicos que ejecutan máquinas virtuales, balanceadores de tráfico, balanceadores de carga de red, la red misma, utilización de canales de comunicación. Más métricas para nuestros propios centros de datos (tenemos varios de ellos y la infraestructura es bastante significativa).
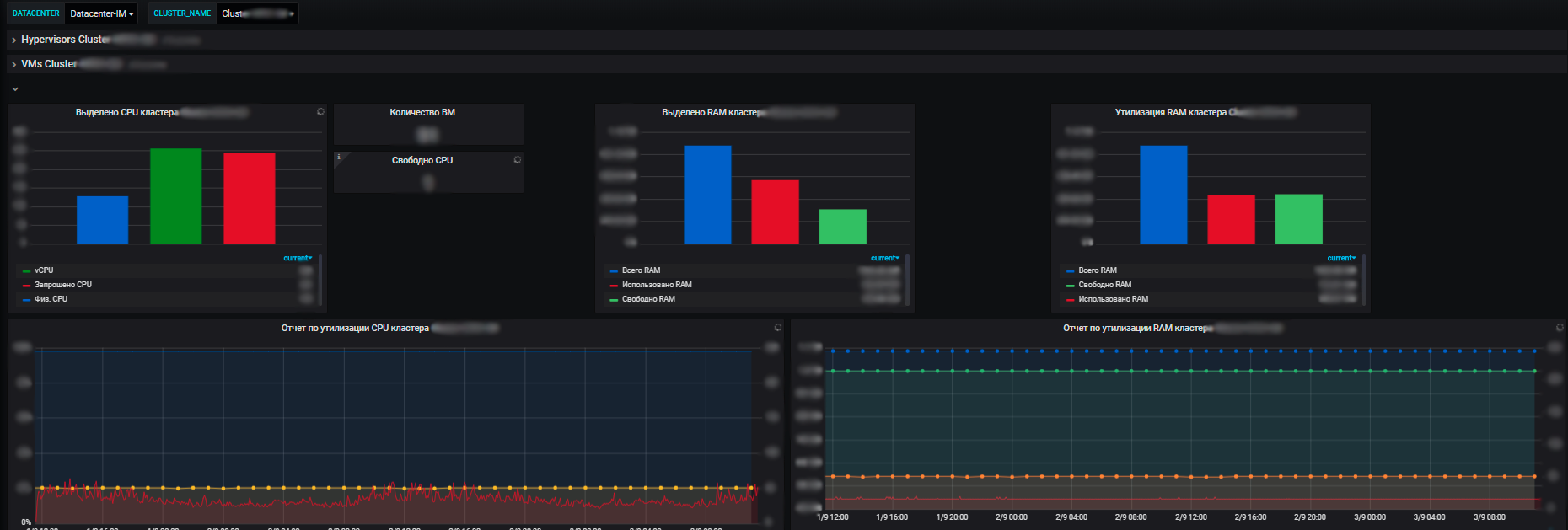
Las ventajas de nuestro sistema de monitorización son que con su ayuda vemos el estado de salud de todos los sistemas, podemos evaluar su impacto entre sí y sobre los recursos comunes. Y, en última instancia, permite la planificación de recursos, que también es nuestra responsabilidad. Gestionamos los recursos del servidor: un grupo en el marco del comercio electrónico, introducimos y desmantelamos nuevos equipos, compramos nuevos equipos, realizamos una auditoría de la utilización de recursos, etc. Cada año los equipos planifican nuevos proyectos, desarrollan sus sistemas y es importante para nosotros brindarles recursos.
Y con la ayuda de métricas, vemos la tendencia de consumo de recursos de nuestros sistemas de información. Y ya sobre su base podemos planear algo. A nivel de virtualización, recopilamos datos y vemos información sobre la cantidad disponible de recursos en el contexto de los centros de datos. Y ya dentro del centro de datos, puede ver la utilización y la distribución real, el consumo de recursos. Además, tanto con servidores independientes como con máquinas virtuales y clústeres de servidores físicos, en los que todas estas máquinas virtuales están girando vigorosamente.
Perspectivas
Ahora tenemos listo el núcleo del sistema en su conjunto, pero todavía quedan suficientes puntos en los que trabajar. Al menos esta es una capa de seguridad de la información, pero también es importante llegar a la red, desarrollar alertas y resolver el problema con correlación. Tenemos muchas capas y sistemas, hay muchas más métricas en cada capa. Resulta una matrioska al grado de una matrioska.
Nuestra tarea es, en última instancia, realizar las alertas adecuadas. Por ejemplo, si hubo un problema con el hardware, nuevamente, con una máquina virtual, y había una aplicación importante, y el servicio no fue respaldado de ninguna manera. Descubrimos que la máquina virtual ha muerto. Luego alertarán las métricas comerciales: los usuarios han desaparecido en algún lugar, no hay conversión, la interfaz de usuario en la interfaz no está disponible, el software y los servicios también han muerto.
En esta situación, recibiremos spam de alertas, y esto ya no encaja en el formato de un sistema de monitoreo correcto. Surge la cuestión de la correlación. Por lo tanto, idealmente, nuestro sistema de monitoreo debería decir: "Chicos, su máquina física ha muerto, y junto con ella esta aplicación y esas métricas", con la ayuda de una alerta en lugar de bombardearnos furiosamente con cien alertas. Ella debe informar lo principal: el motivo, que contribuye a la rapidez de la eliminación del problema debido a su localización.
Nuestro sistema de manejo de alertas y alertas se basa en un servicio de línea directa 24/7. Todas las alertas que se consideran imprescindibles para nosotros y están incluidas en la lista de verificación se envían allí. Cada alerta debe tener una descripción: qué sucedió, qué significa realmente, qué afecta. Y también un enlace al tablero e instrucciones sobre qué hacer en este caso.
Eso es todo por los requisitos para la construcción de la alerta. Además, la situación puede desarrollarse en dos direcciones: o hay un problema y necesita ser resuelto, o hubo una falla en el sistema de monitoreo. Pero en cualquier caso, debes ir y resolverlo.
En promedio, nos están cayendo alrededor de un centenar de alertas por día ahora, esto es teniendo en cuenta que la correlación de alertas aún no se ha configurado correctamente. Y si necesitamos realizar un trabajo técnico, y apagamos algo por la fuerza, su número crece significativamente.
Además de monitorear los sistemas que operamos y recopilar métricas que se consideran importantes de nuestro lado, el sistema de monitoreo nos permite recopilar datos para los equipos de productos. Pueden influir en la composición de las métricas dentro de los sistemas de información que se monitorean aquí.
Nuestro colega puede venir y pedirnos agregar alguna métrica que sea útil para nosotros y para el equipo. O, por ejemplo, es posible que el equipo no tenga suficientes métricas básicas que nosotros tenemos, necesitan rastrear alguna específica. En Grafana, creamos un espacio para cada equipo y otorgamos derechos de administrador. Además, si un equipo necesita cuadros de mando, pero ellos mismos no pueden / no saben cómo hacerlo, les ayudamos.
Dado que estamos fuera del flujo de creación de valor del equipo, sus lanzamientos y planificación, gradualmente llegamos a la conclusión de que los lanzamientos de todos los sistemas son perfectos y se pueden implementar a diario, sin coordinarnos con nosotros. Y es importante para nosotros hacer un seguimiento de estas versiones, porque pueden afectar potencialmente el funcionamiento de la aplicación y romper algo, y esto es fundamental. Para gestionar lanzamientos, utilizamos Bamboo, de donde obtenemos datos a través de la API y podemos ver qué lanzamientos en qué sistemas de información salieron y su estado. Y lo más importante es a qué hora. Colocamos marcadores de lanzamiento en las principales métricas críticas, lo cual es visualmente muy indicativo en caso de problemas.
De esta manera podemos ver la correlación entre los nuevos lanzamientos y los problemas emergentes. La idea principal es comprender cómo funciona el sistema en todas las capas, para localizar rápidamente el problema y solucionarlo con la misma rapidez. De hecho, a menudo sucede que la mayor parte del tiempo no se dedica a resolver el problema, sino a encontrar la causa.
Y en esta dirección en el futuro queremos centrarnos en la proactividad. Idealmente, me gustaría saber de antemano sobre un problema inminente, y no después del hecho, para tratar su prevención, no una solución. En ocasiones hay falsos positivos del sistema de monitorización, tanto por error humano como por cambios en la aplicación. Y estamos trabajando en esto, depurando e intentando advertir a los usuarios sobre esto ante cualquier manipulación en el sistema de monitorización, que lo utilizan con nosotros. , o realizar estos eventos en la ventana técnica.
Entonces, el sistema se ha lanzado y ha estado funcionando con éxito desde principios de la primavera ... y muestra un beneficio muy real. Por supuesto, esta no es su versión final, presentaremos muchas más funciones útiles. Pero ahora mismo, con tantas integraciones y aplicaciones, la automatización del monitoreo es realmente indispensable.
Si también supervisa proyectos grandes con una gran cantidad de integraciones, escriba en los comentarios qué fórmula mágica encontró para esto.