... en una consulta bien diseñada con sugerencias contextuales para los nodos del plan correspondientes:

En esta transcripción de la segunda parte de mi charla en PGConf.Russia 2020, les contaré cómo logramos hacerlo.
La transcripción de la primera parte, que trata de los problemas típicos de rendimiento de las consultas y sus soluciones, se puede encontrar en el artículo "Recetas para consultas SQL en problemas" .
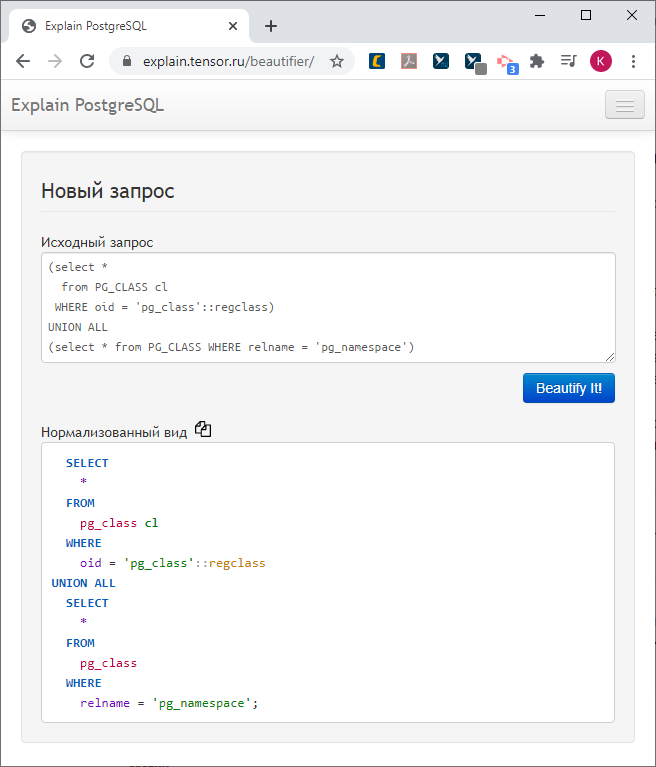
Primero, pintaremos, y ya no pintaremos el plan, ya lo hemos pintado, ya lo tenemos hermoso y comprensible, pero una solicitud.
Nos pareció que la consulta extraída del registro usando una "hoja" sin formato se ve muy fea y por lo tanto incómoda.

Especialmente cuando los desarrolladores en el código "pegan" el cuerpo de la solicitud (esto es, por supuesto, un anti-patrón, pero sucede) en una línea. ¡Horror!
Dibujémoslo de alguna manera más bellamente.
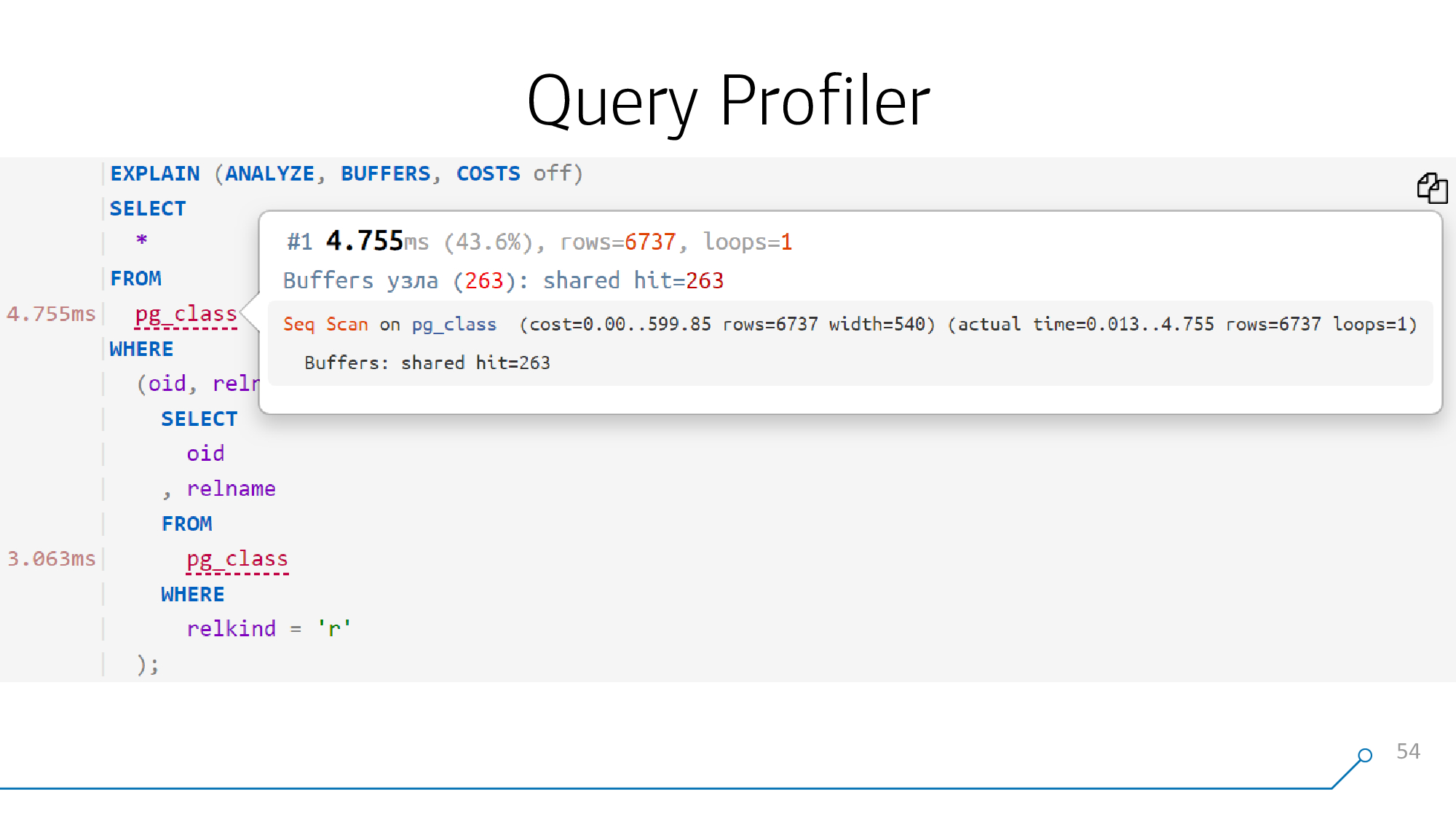
Y si podemos dibujarlo maravillosamente, es decir, desmontar y volver a montar el cuerpo de la solicitud, entonces podemos adjuntar una pista a cada objeto de esta solicitud, lo que sucedió en el punto correspondiente del plan.
Árbol de consulta de sintaxis
Para hacer esto, primero se debe analizar la solicitud.
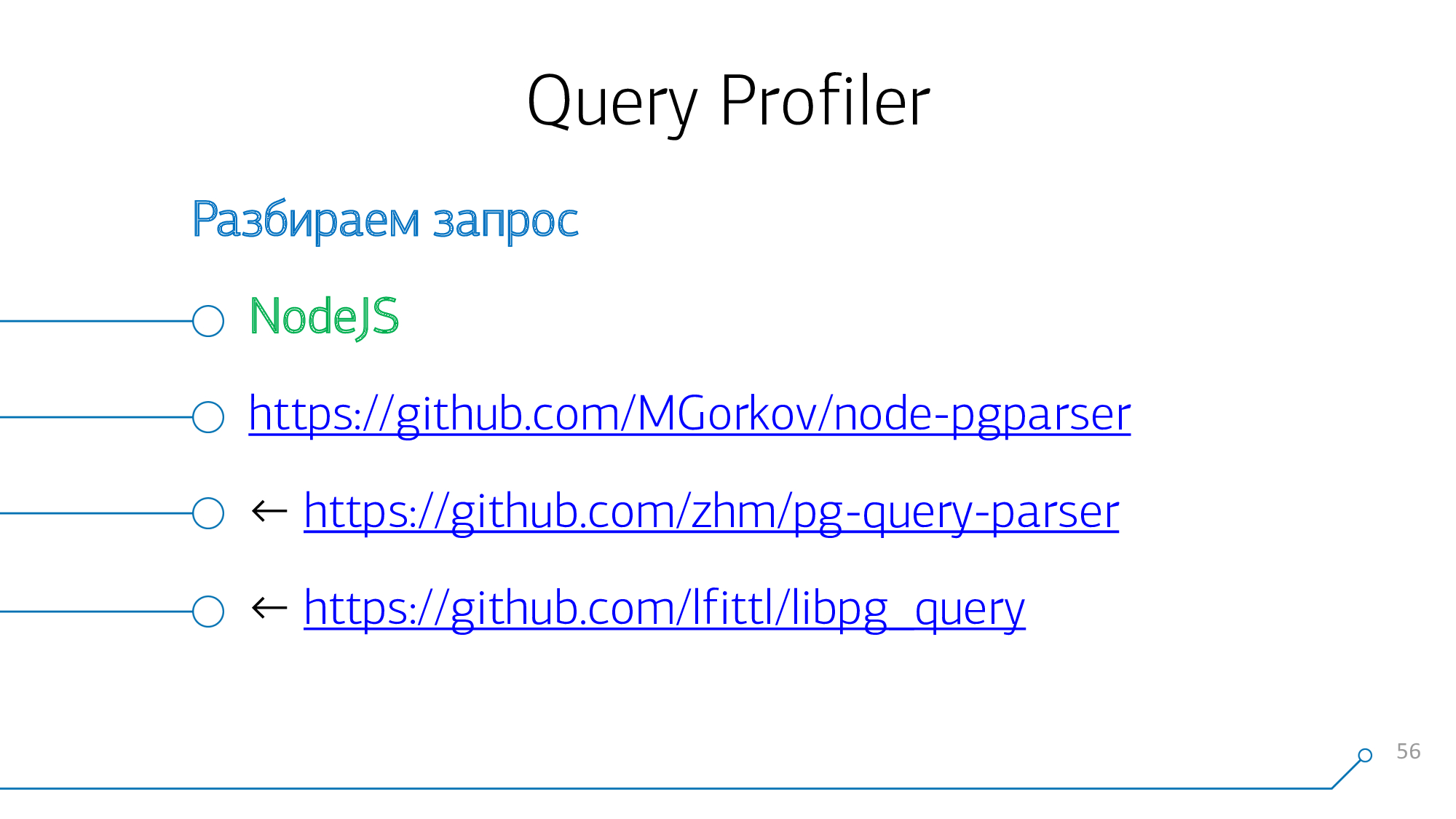
Dado que el núcleo de nuestro sistema se ejecuta en NodeJS , creamos módulos para él, puede encontrarlo en GitHub . De hecho, estos son "enlaces" extendidos a los componentes internos del analizador PostgreSQL. Es decir, la gramática simplemente se compila en binario y los enlaces se realizan desde el lado de NodeJS. Tomamos los módulos de otras personas como base, no hay un gran secreto aquí.
Alimentamos el cuerpo de la solicitud a la entrada de nuestra función; en la salida obtenemos un árbol de sintaxis analizado en forma de un objeto JSON.

Ahora puedes pasar por este árbol en sentido contrario y recoger la solicitud con las sangrías, coloreando, formateando que queramos. No, no es configurable, pero nos ha parecido conveniente.

Asignación de nodos de consulta y plan
Ahora veamos cómo podemos combinar el plan que analizamos en el primer paso y la consulta que analizamos en el segundo.
Tomemos un ejemplo simple: tenemos una solicitud que genera un CTE y lo lee dos veces. Genera tal plan.

CTE
Si lo mira con atención, antes de la versión 12 (o comenzando desde ella con una palabra clave
MATERIALIZED), la formación de CTE es una barrera absoluta para el planificador .
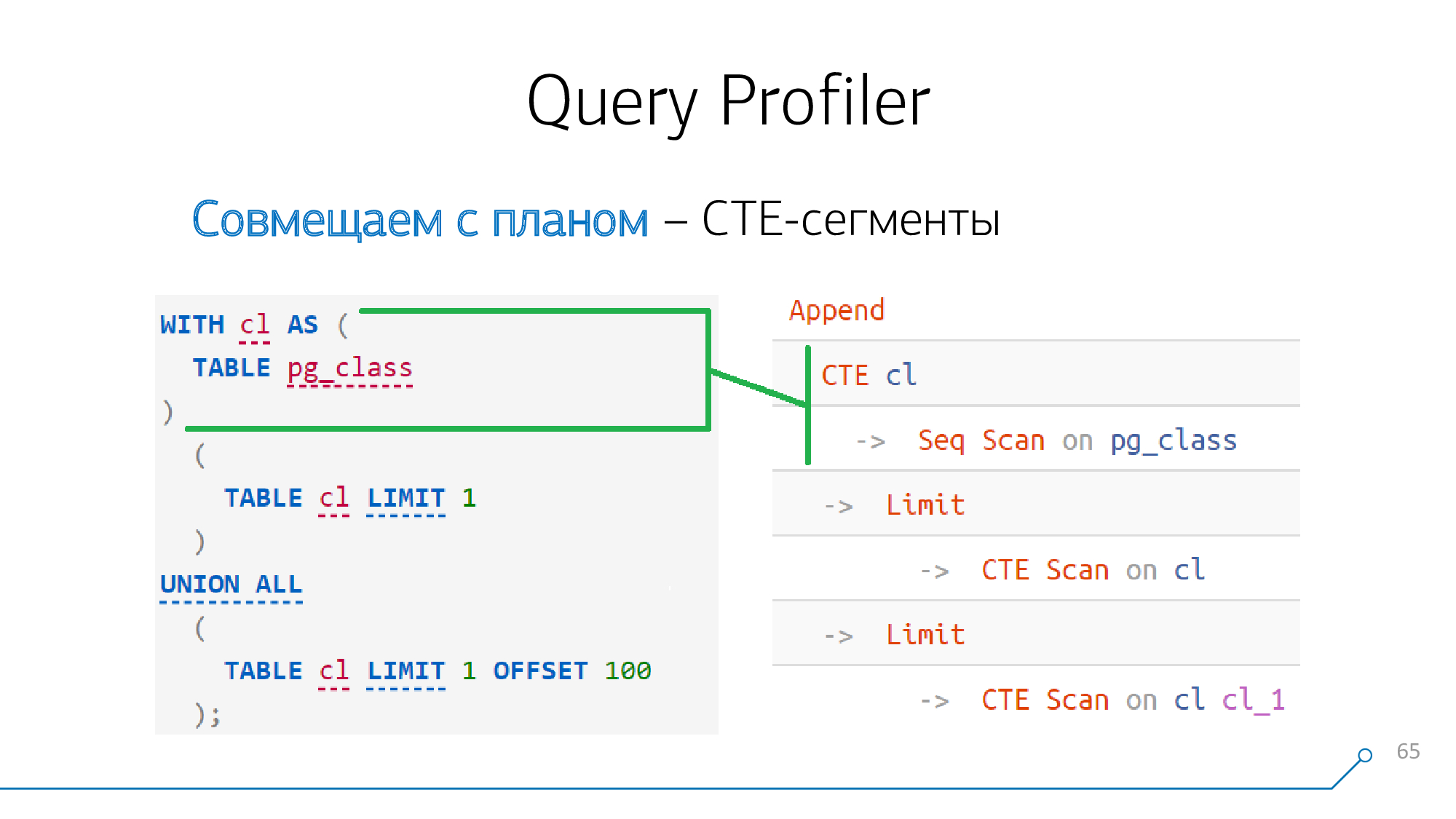
Esto significa que si vemos la generación de CTE en algún lugar de la solicitud y en algún lugar del plan un nodo
CTE, entonces estos nodos definitivamente "pelean" entre sí, podemos combinarlos inmediatamente.
Problema de asterisco : los CTE se pueden anidar.

Los hay muy mal anidados, e incluso los mismos nombres. Por ejemplo, puedes
CTE Ahacerlo por dentro CTE Xy CTE Bvolver a hacerlo al mismo nivel por dentro CTE X:
WITH A AS (
WITH X AS (...)
SELECT ...
)
, B AS (
WITH X AS (...)
SELECT ...
)
...Debe comprender esto al comparar. Es muy difícil entender esto con “ojos”, incluso viendo el plan, incluso viendo el cuerpo de la solicitud. Si su generación de CTE es compleja, anidada, las solicitudes son grandes, entonces es completamente inconsciente.
UNIÓN
Si tenemos una palabra clave en nuestra consulta
UNION [ALL](el operador de unir dos selecciones), entonces un nodo Appendo alguien le corresponde en el plan Recursive Union.

Lo que "arriba" está arriba
UNIONes el primer hijo de nuestro nodo, lo que está "abajo" es el segundo. Si UNIONvarios bloques están "pegados" a través de nosotros a la vez, entonces Appendtodavía habrá un solo nodo, pero no tendrá dos hijos, sino muchos, en el orden en que avanzan, respectivamente:
(...) -- #1
UNION ALL
(...) -- #2
UNION ALL
(...) -- #3Append
-> ... #1
-> ... #2
-> ... #3
Problema "con un asterisco" : dentro de la generación de una selección recursiva (
WITH RECURSIVE) también puede haber más de una UNION. Pero solo el último bloque después del último es siempre recursivo UNION. Todo lo anterior es uno pero diferente UNION:
WITH RECURSIVE T AS(
(...) -- #1
UNION ALL
(...) -- #2,
UNION ALL
(...) -- #3, T
)
...También debe poder "pegar" tales ejemplos. En este ejemplo, vemos que
UNIONhabía 3 segmentos en nuestra solicitud. En consecuencia, uno UNION corresponde a un Append-nodo y el otro corresponde a Recursive Union.

Datos de lectura y escritura
Eso es todo, lo distribuimos, ahora sabemos qué parte de la solicitud corresponde a qué parte del plan. Y en estas piezas podemos encontrar fácil y naturalmente aquellos objetos que sean "legibles".
Desde el punto de vista de la consulta, no sabemos si se trata de una tabla o CTE, pero están denotados por el mismo nodo
RangeVar. Y en términos de "legible", este es también un conjunto bastante limitado de nodos:
Seq Scan on [tbl]Bitmap Heap Scan on [tbl]Index [Only] Scan [Backward] using [idx] on [tbl]CTE Scan on [cte]Insert/Update/Delete on [tbl]
Conocemos la estructura del plano y la consulta, conocemos la correspondencia de los bloques, conocemos los nombres de los objetos, hacemos una comparación inequívoca.

Nuevamente, un problema de asterisco . Tomamos la solicitud, la ejecutamos, no tenemos ningún alias, solo la leemos dos veces desde un CTE.

Miramos el plan, ¿cuál es el problema? ¿Por qué salió nuestro alias? No lo ordenamos. ¿De dónde viene de tal "matrícula"?
PostgreSQL lo agrega él mismo. Solo debe comprender que ese alias no tiene ningún sentido para nosotros a efectos de comparación con el plan, simplemente se agrega aquí. No le prestemos atención.
La segunda tarea es "con un asterisco" : si estamos leyendo de una tabla particionada, obtendremos un nodo
AppendoMerge Append, Que consistirá en un gran número de "niños", y cada uno de los cuales es de alguna manera Scan'th de la sección de la tabla: Seq Scan, Bitmap Heap Scano Index Scan. Pero, en cualquier caso, estos "hijos" no serán consultas complejas; así es como se pueden distinguir estos nodos de Appendcuándo UNION.

También entendemos esos nodos, los recopilamos "en una pila" y decimos: " todo lo que lees de megatable está aquí y abajo del árbol ".
Nodos "simples" para recibir datos

Values Scanen plan coincide VALUEScon la solicitud.
Result- esta es una solicitud sin me FROMgusta SELECT 1. O cuando tiene una expresión falsa a sabiendas en el WHERE-bloque (entonces aparece el atributo One-Time Filter):
EXPLAIN ANALYZE
SELECT * FROM pg_class WHERE FALSE; -- 0 = 1Result (cost=0.00..0.00 rows=0 width=230) (actual time=0.000..0.000 rows=0 loops=1)
One-Time Filter: false
Function Scan"Asignar" a la SRF del mismo nombre.
Pero con las consultas anidadas, todo es más complicado; desafortunadamente, no siempre se convierten en
InitPlan/ SubPlan. A veces se convierten en ... Joino ... Anti Join, especialmente cuando escribes algo como WHERE NOT EXISTS .... Y no siempre es posible combinar allí: no hay operadores correspondientes a los nodos del plan en el texto del plan.
Nuevamente, la tarea es "con un asterisco" : varios
VALUESen la solicitud. En este caso, y en el plan, recibirás varios nodos Values Scan.

Los sufijos "numerados" ayudarán a distinguirlos entre sí; se agregan exactamente en el orden en que se encuentran los
VALUESbloques correspondientes a lo largo de la solicitud de arriba a abajo.
Procesamiento de datos
Parece que todo en nuestra solicitud se resolvió, solo quedaba uno
Limit.
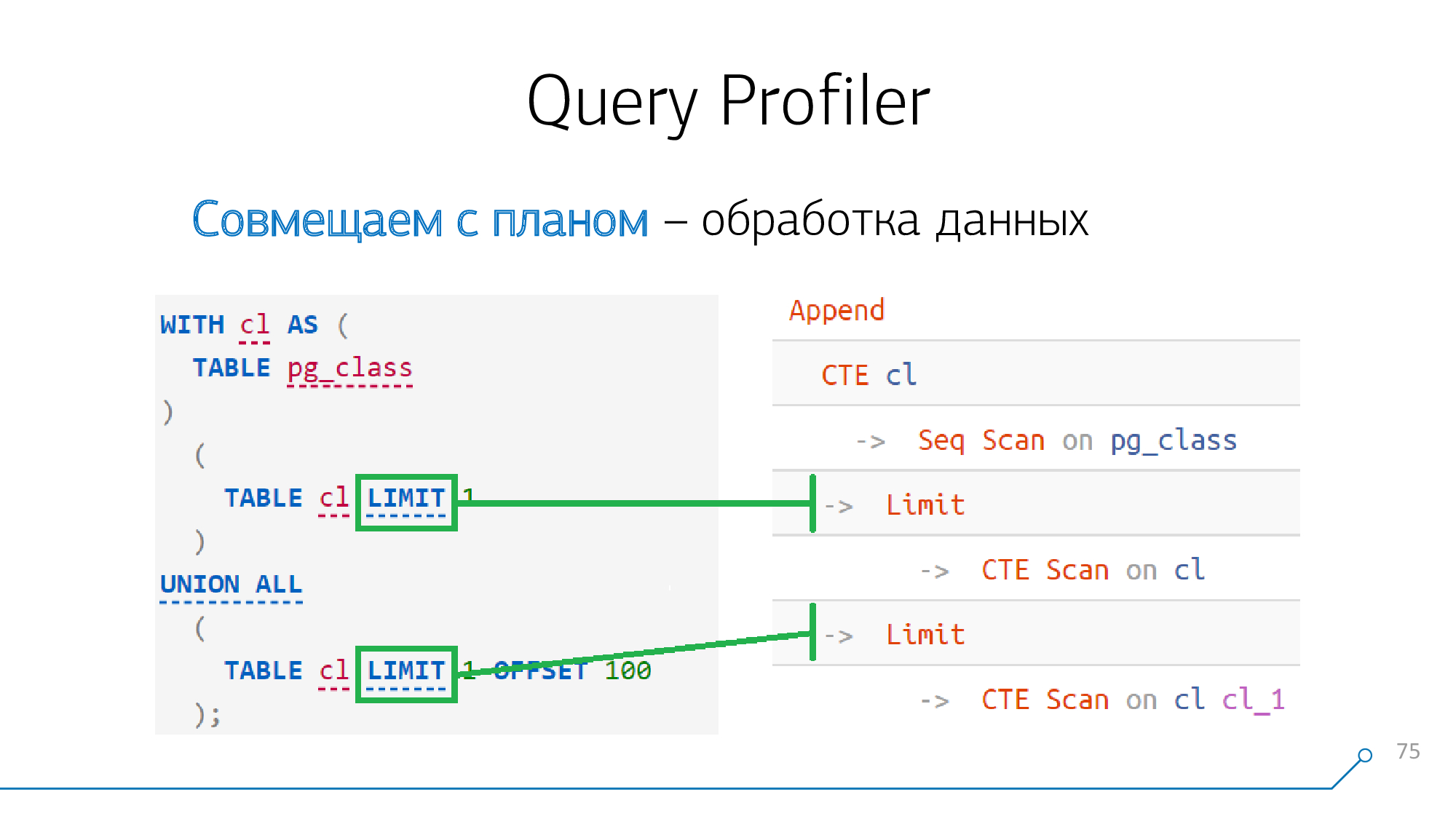
Pero todo es simple - tales como los nodos
Limit, Sort, Aggregate, WindowAgg, Unique"mapyatsya" uno a uno a los estados correspondientes de la solicitud, si están allí. No hay "estrellas" ni dificultades.

UNIRSE
Las dificultades surgen cuando queremos combinarnos
JOIN. Esto no siempre se hace, pero puede hacerlo.

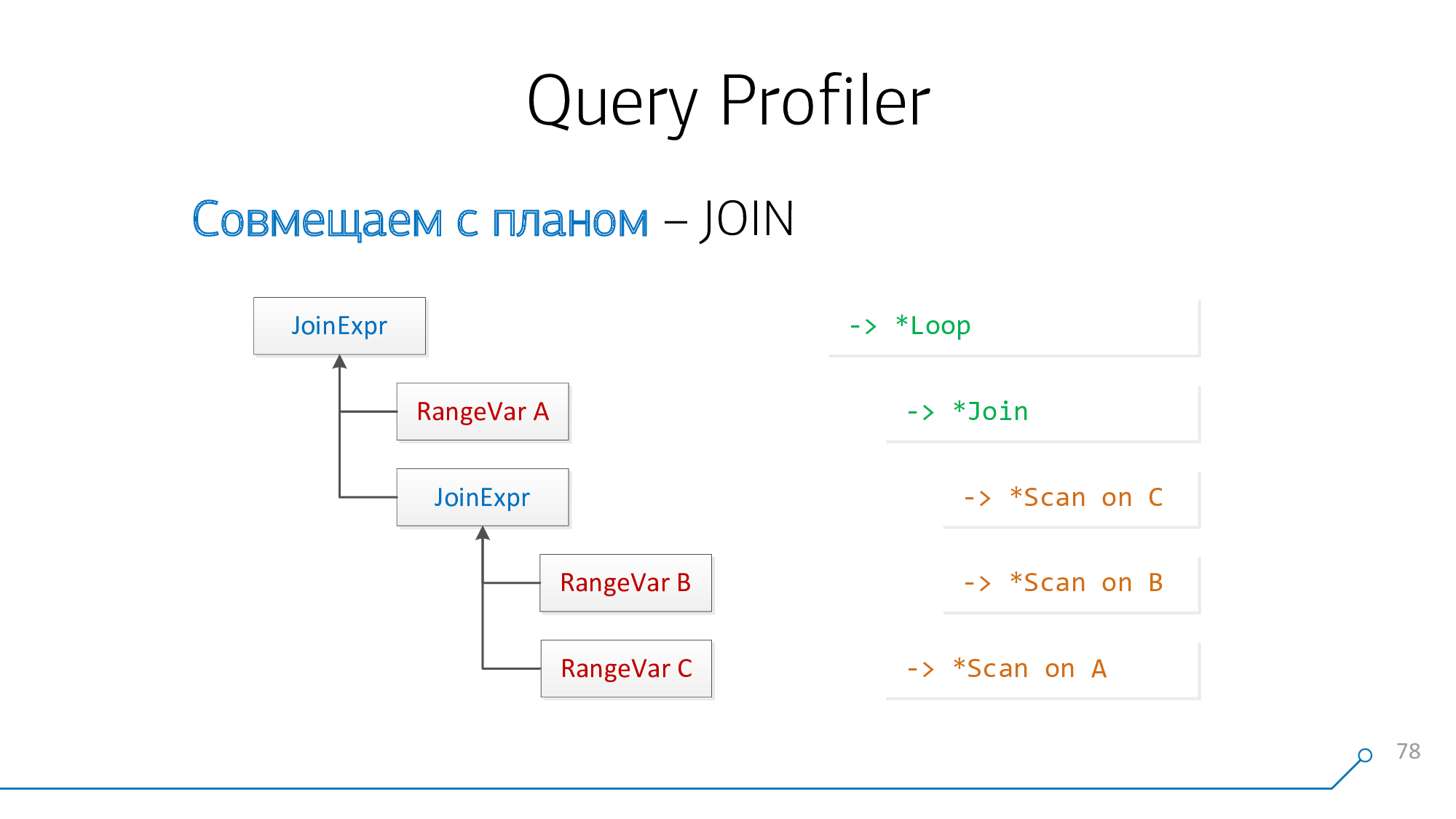
Desde el punto de vista del analizador de consultas, tenemos un nodo
JoinExprque tiene exactamente dos hijos: izquierdo y derecho. Esto, respectivamente, es lo que está "arriba" de su JOIN y lo que está "debajo" en la solicitud está escrito.
Y desde el punto de vista del plan, estos son dos descendientes de algún
* Loop/ * Join-nodo. Nested Loop, Hash Anti Join... - eso es algo.
Usemos una lógica simple: si tenemos las placas A y B que se "unen" entre sí en el plan, entonces en la solicitud podrían ubicarse
A-JOIN-Bo bien B-JOIN-A. Intentemos combinar de esta manera, intentemos combinarlo al revés, y así sucesivamente hasta que se agoten esos pares.
Tome nuestro árbol de sintaxis, tome nuestro esquema, mírelos ... ¡no lo parece!
Vamos a redibujarlo en forma de gráficos - ¡oh, ya se ha convertido en algo así!
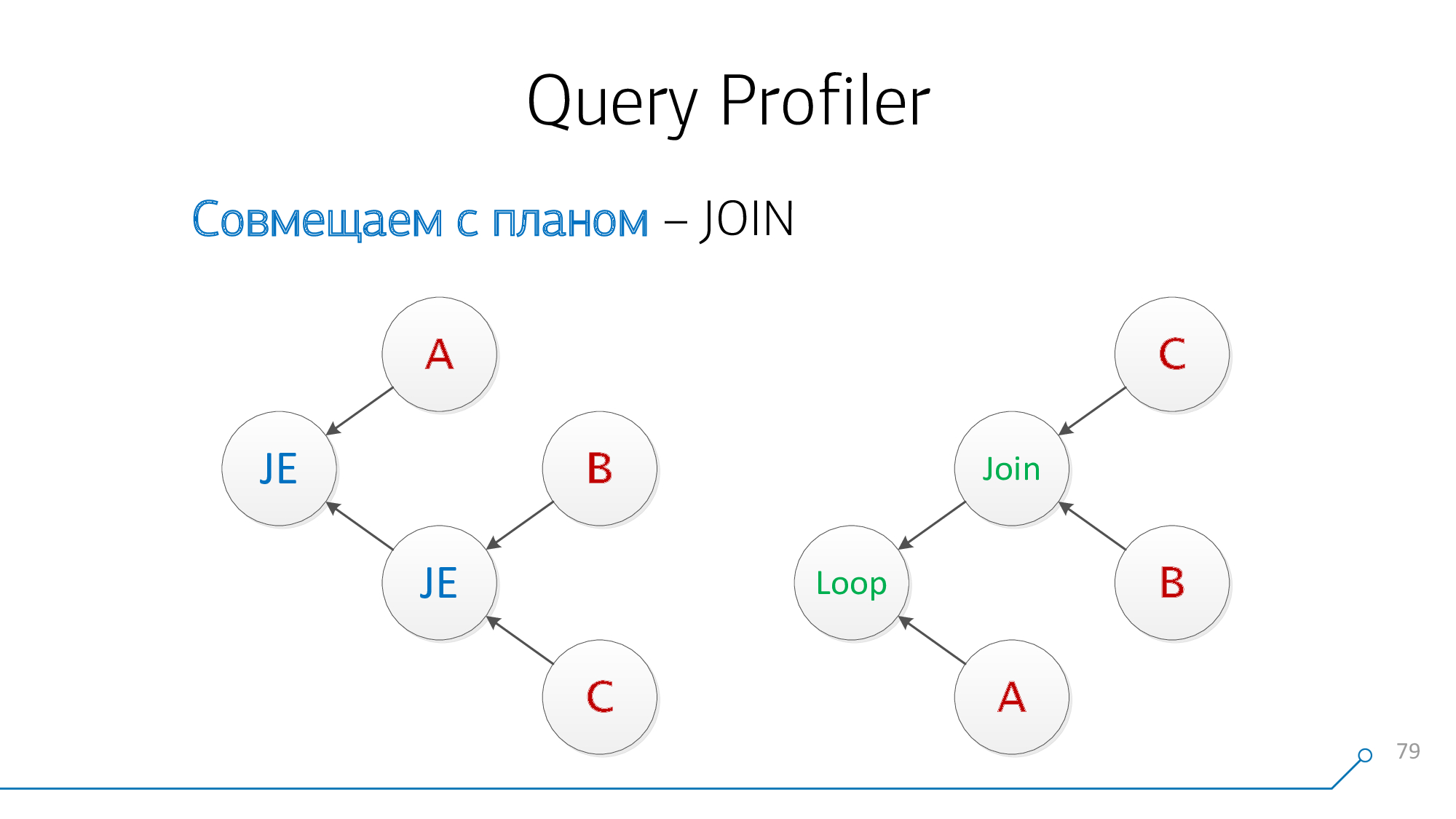
Observemos que tenemos nodos que tienen hijos B y C al mismo tiempo, no nos importa en qué orden. Combinémoslos y giremos la imagen del nudo.

Veámoslo de nuevo. Ahora tenemos nodos con hijos A y pares (B + C), compatibles con ellos también.
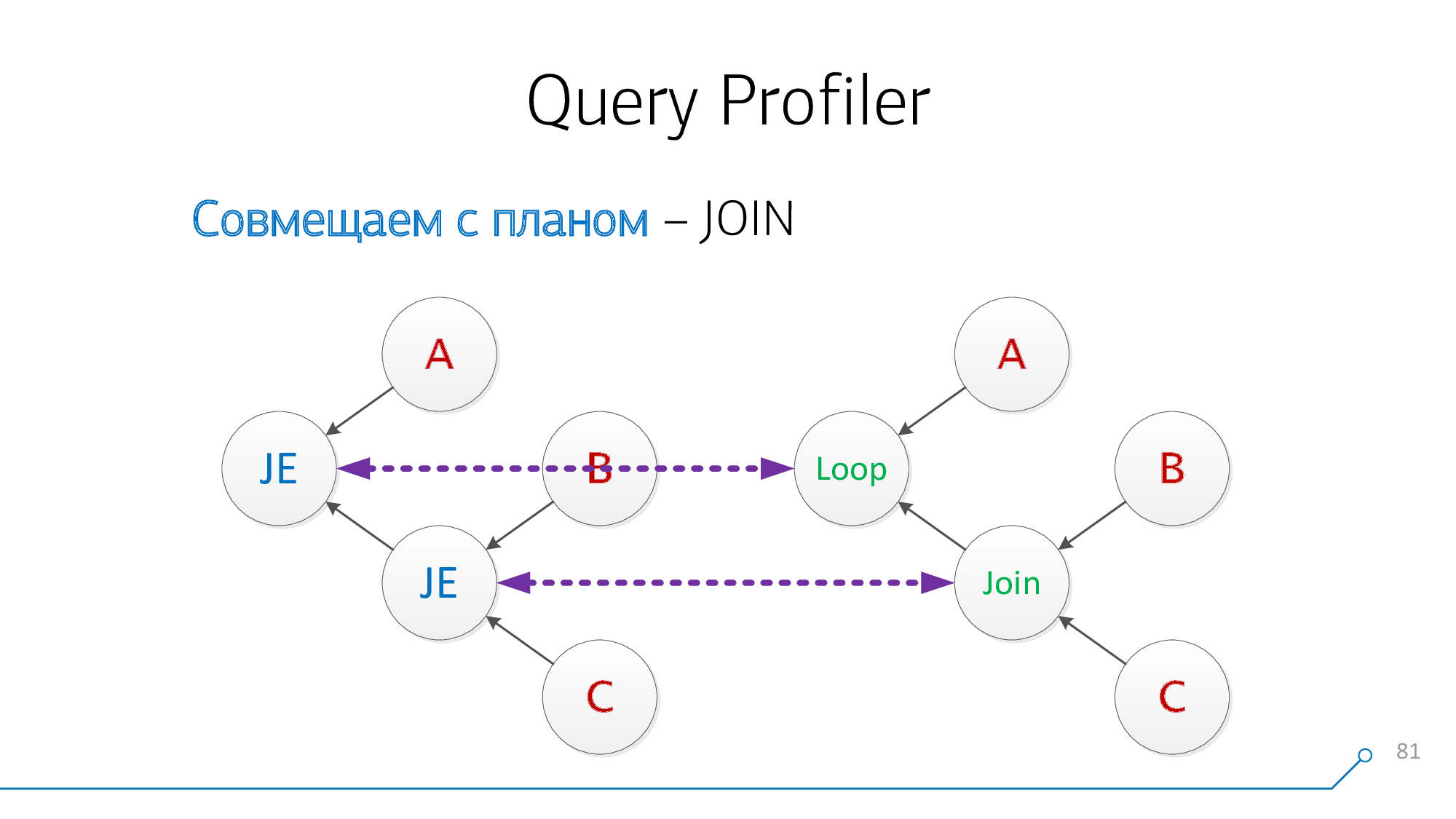
¡Excelente! Resulta que hemos
JOINcombinado con éxito estos dos de la consulta con los nodos del plan.
Por desgracia, esta tarea no siempre se resuelve.
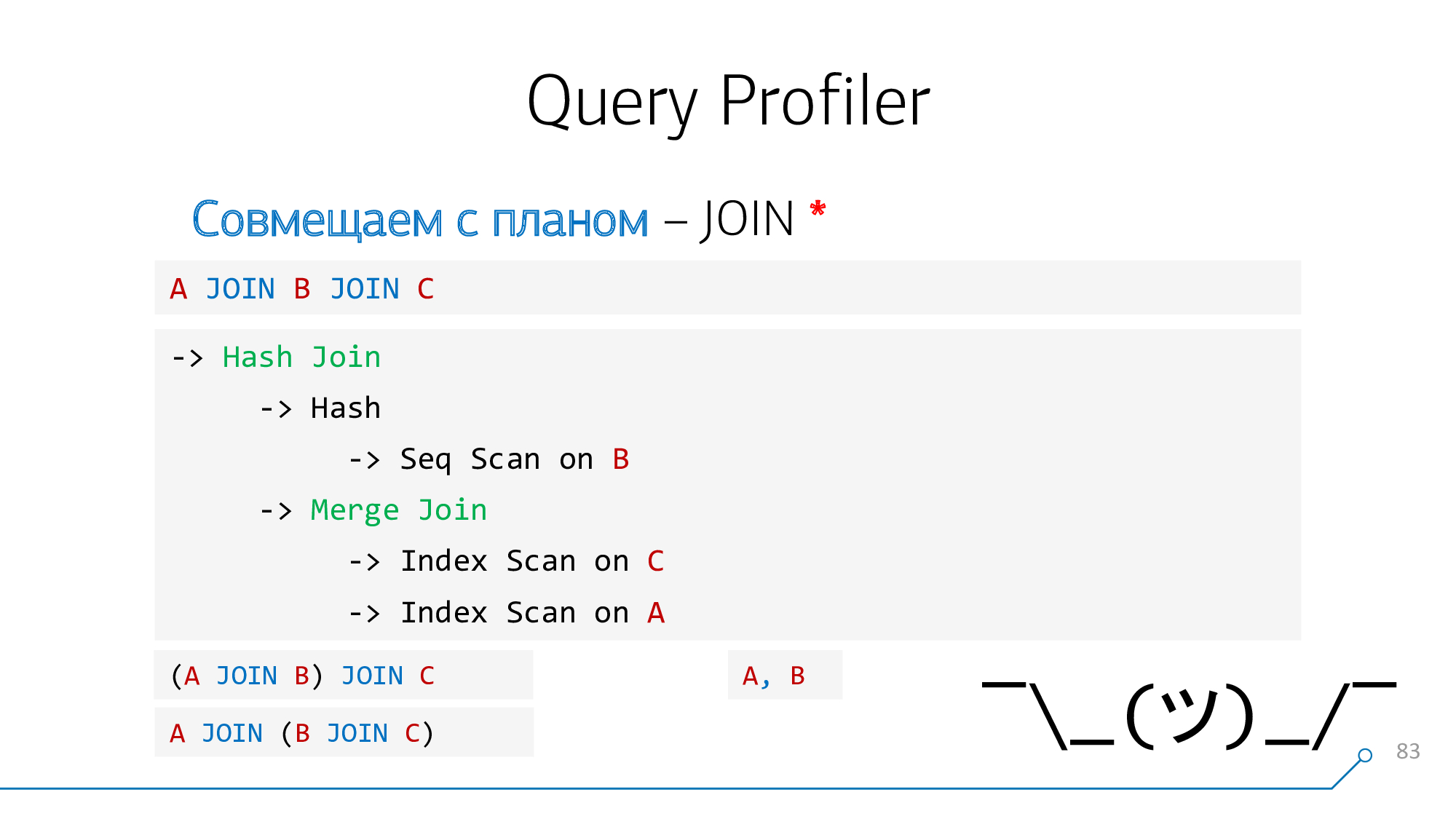
Por ejemplo, si en la consulta
A JOIN B JOIN C, pero en el plan, se conectaron en primer lugar los nodos "extremos" A y C. Y en la consulta no existe tal operador, no tenemos nada que resaltar, no hay nada a lo que enlazar la pista. Lo mismo ocurre con la "coma" cuando escribe A, B.
Pero, en la mayoría de los casos, casi todos los nodos se pueden "desatar" y obtienes este tipo de perfil a la izquierda en el tiempo, literalmente, como en Google Chrome, cuando analizas el código JavaScript. Puede ver cuánto tiempo se "ejecutaron" cada línea y cada declaración.

Y para que le resulte más conveniente usar todo esto, creamos un almacenamiento de archivos , donde puede guardar y luego encontrar sus planes junto con las solicitudes asociadas o compartir un enlace con alguien.
Si solo necesita traer una consulta ilegible en una forma adecuada, use nuestro "normalizador" .