Límites y aceleración de la CPU
Como muchos otros usuarios de Kubernetes, Google recomienda encarecidamente ajustar los límites de la CPU . Sin esta configuración, los contenedores del nodo pueden consumir toda la potencia del procesador, lo que, a su vez, hará que los procesos importantes de Kubernetes (por ejemplo
kubelet) dejen de responder a las solicitudes. Por lo tanto, establecer límites de CPU es una buena forma de proteger sus nodos.
Los límites del procesador establecen el contenedor el tiempo máximo de procesador que puede usar durante un período específico (100 ms por defecto), y el contenedor nunca excederá este límite. Kubernetes utiliza una herramienta especial CFS Quota para acelerar el contenedor y evitar que supere el límite.Sin embargo, al final, dicho procesador artificial limita el rendimiento inferior y aumenta el tiempo de respuesta de sus contenedores.
¿Qué puede pasar si no establecemos límites de CPU?
Desafortunadamente, nosotros mismos tuvimos que lidiar con este problema. Cada nodo tiene un proceso responsable de administrar contenedores
kubelety ha dejado de responder a las solicitudes. El nodo, cuando esto suceda, entrará en el estado NotReady, y los contenedores se redirigirán a otro lugar y crearán los mismos problemas en los nuevos nodos. No es un escenario ideal, por decirlo suavemente.
Manifestación de problemas de aceleración y capacidad de respuesta
La métrica clave para rastrear contenedores es
trottlingcuántas veces se ha limitado su contenedor. Llamamos la atención sobre la presencia de estrangulamiento en algunos contenedores, independientemente de si la carga en el procesador era máxima o no. Por ejemplo, echemos un vistazo a una de nuestras API principales:
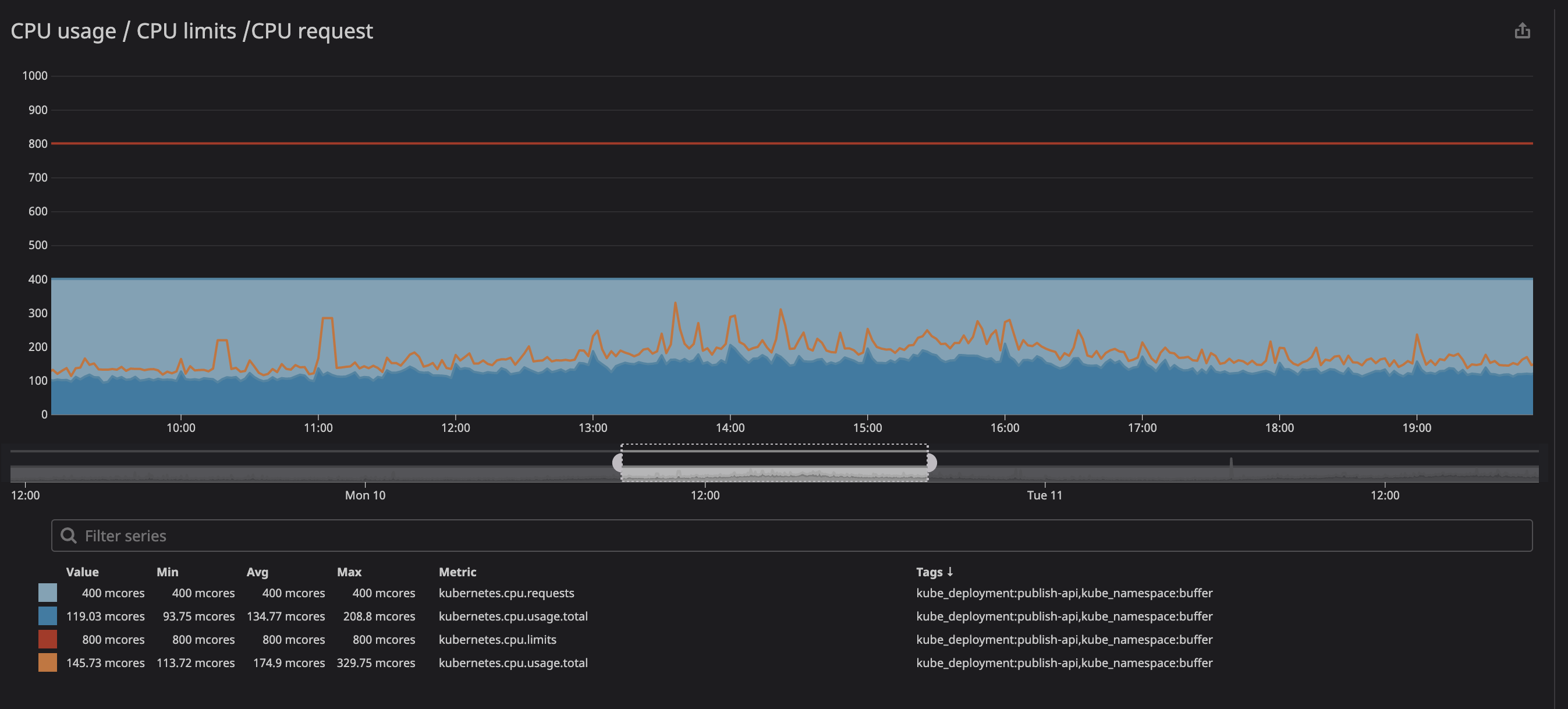
como puede ver a continuación, establecemos el límite en
800m(0,8 u 80% del núcleo), y los valores máximos son en el mejor de los casos 200m(20% del núcleo). Parece que todavía tenemos mucha potencia de procesador antes de estrangular el servicio, sin embargo ...
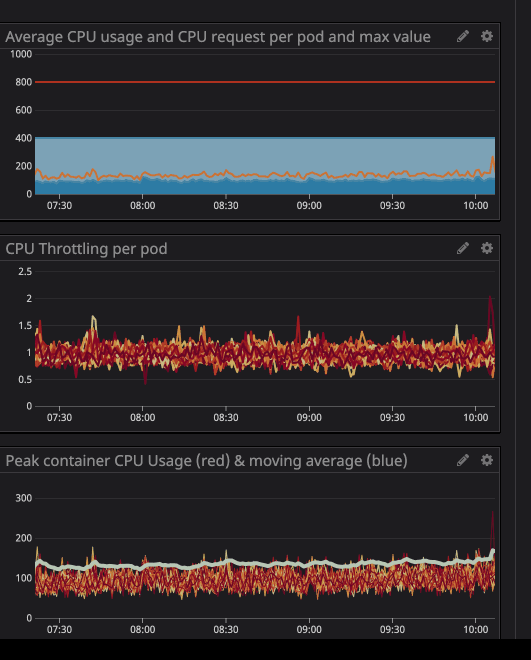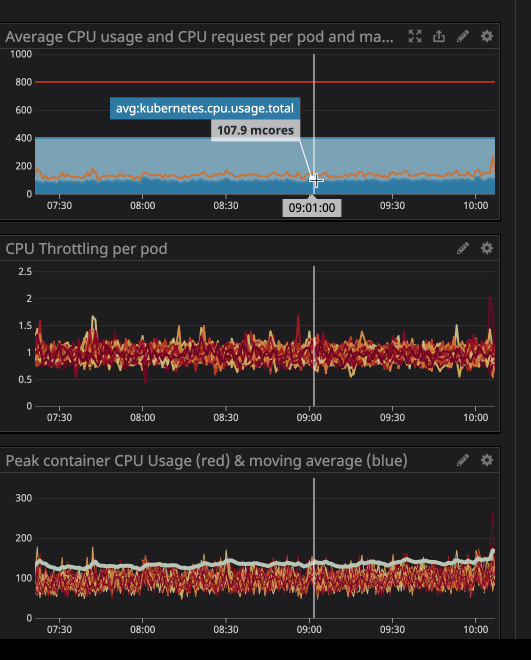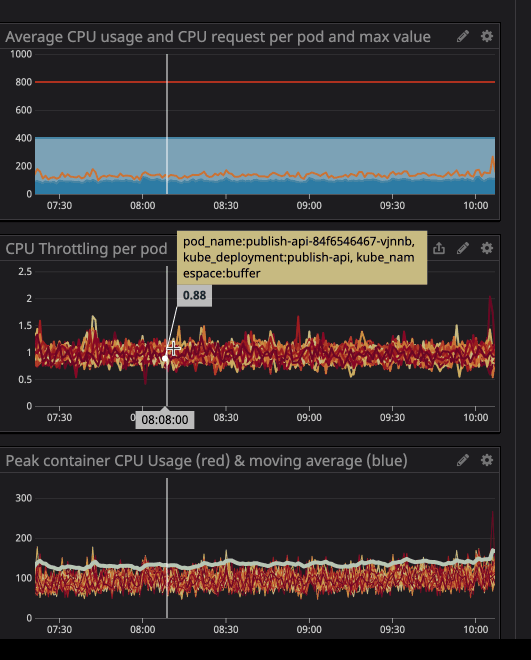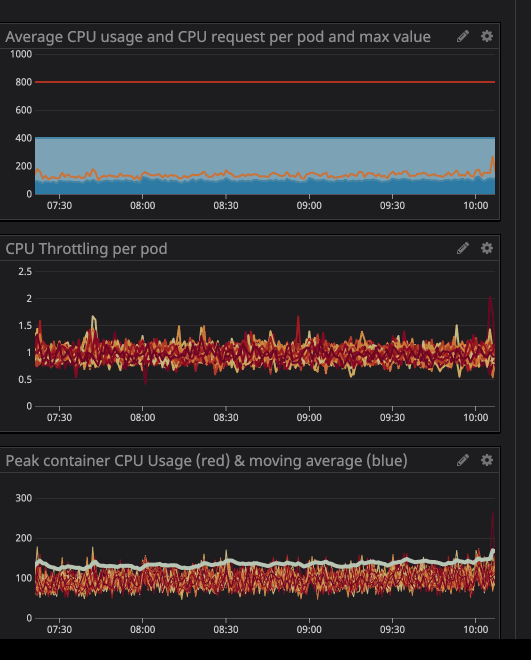
Es posible que haya notado que incluso cuando la carga en el procesador está por debajo de los límites especificados, mucho más bajos, la regulación sigue funcionando.
Ante esto, pronto descubrimos varios recursos (un problema en github , una presentación en zadano , una publicación en omio ) sobre la caída en el rendimiento y el tiempo de respuesta de los servicios debido a la aceleración.
¿Por qué vemos estrangulamiento con un uso bajo de CPU? La versión corta dice así: "Hay un error en el kernel de Linux que desencadena una limitación innecesaria de los contenedores con límites de procesador específicos". Si está interesado en la naturaleza del problema, puede leer la presentación ( video y texto variantes) de Dave Chiluk.
Eliminar los límites del procesador (con extrema precaución)
Después de largas discusiones, decidimos eliminar las restricciones de procesador de todos los servicios, lo que afectaba directa o indirectamente la funcionalidad crítica para nuestros usuarios.
La decisión resultó difícil, ya que valoramos mucho la estabilidad de nuestro clúster. En el pasado, ya hemos experimentado con la inestabilidad de nuestro clúster, y luego los servicios consumieron demasiados recursos y ralentizaron el trabajo de todo nuestro nodo. Ahora todo era un poco diferente: teníamos un claro entendimiento de lo que esperábamos de nuestros clústeres, así como una buena estrategia para implementar los cambios planeados.

Correspondencia comercial sobre un tema urgente.
¿Cómo proteger sus nodos al eliminar restricciones?
Aislamiento de servicios "ilimitados":
en el pasado, hemos visto algunos nodos entrar en un estado
notReady, principalmente debido a servicios que consumían demasiados recursos.
Decidimos colocar dichos servicios en nodos separados ("etiquetados") para que no interfirieran con los servicios "vinculados". Como resultado, al marcar algunos nodos y agregar un parámetro de tolerancia a los servicios "no relacionados", obtuvimos más control sobre el clúster y nos resultó más fácil identificar problemas con los nodos. Para llevar a cabo procesos similares usted mismo, puede familiarizarse con la documentación .
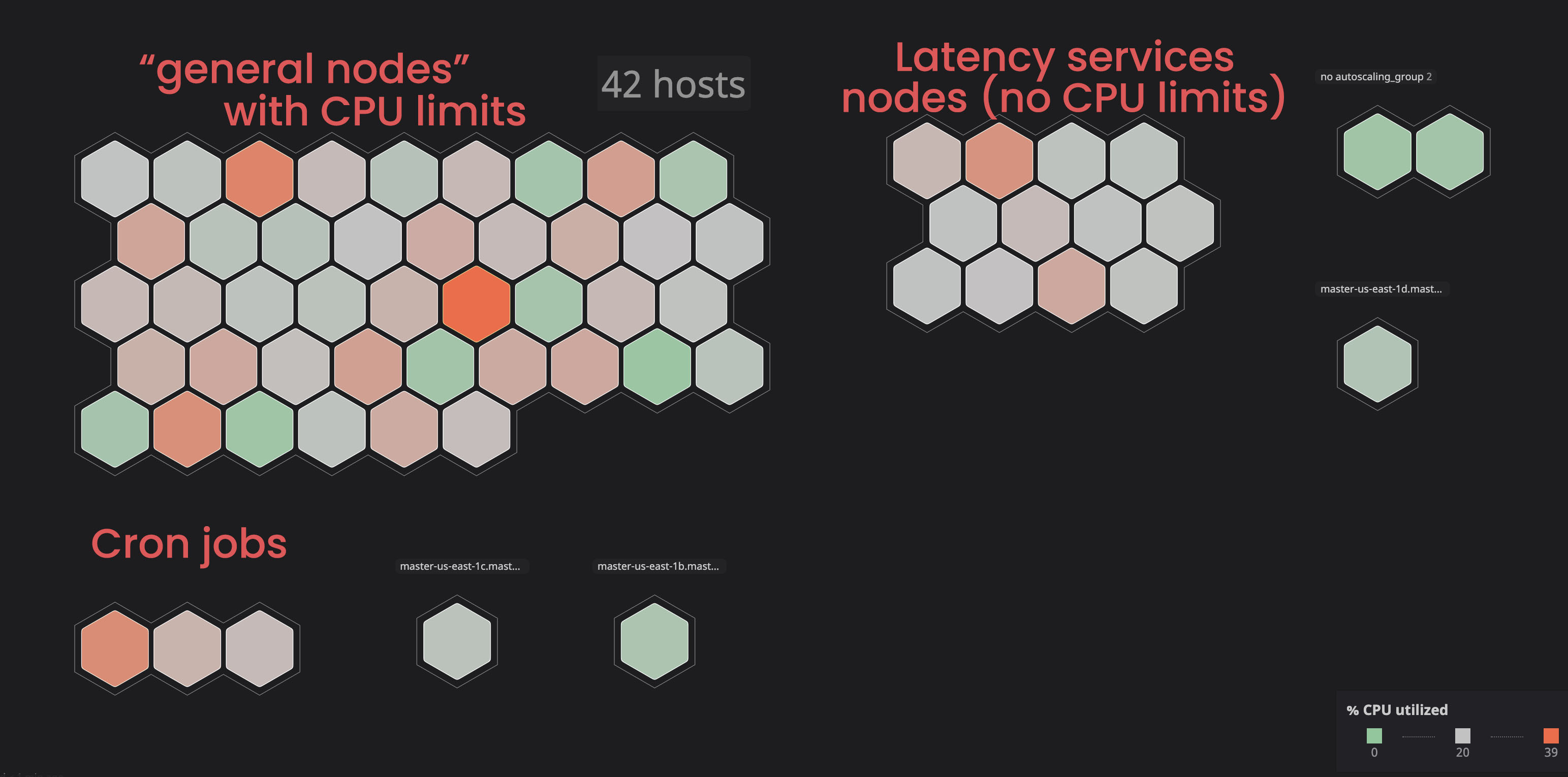
Asignar el procesador correcto y la solicitud de memoria:
Sobre todo, temíamos que el proceso consumiera demasiados recursos y que el nodo dejara de responder a las solicitudes. Como ahora (gracias a Datadog) pudimos observar claramente todos los servicios en nuestro clúster, analicé varios meses de funcionamiento de los que teníamos previsto designar como "no relacionados". Simplemente establezco la utilización máxima de la CPU con un margen del 20% y, por lo tanto, asigno espacio en el nodo en caso de que k8s intente asignar otros servicios al nodo.
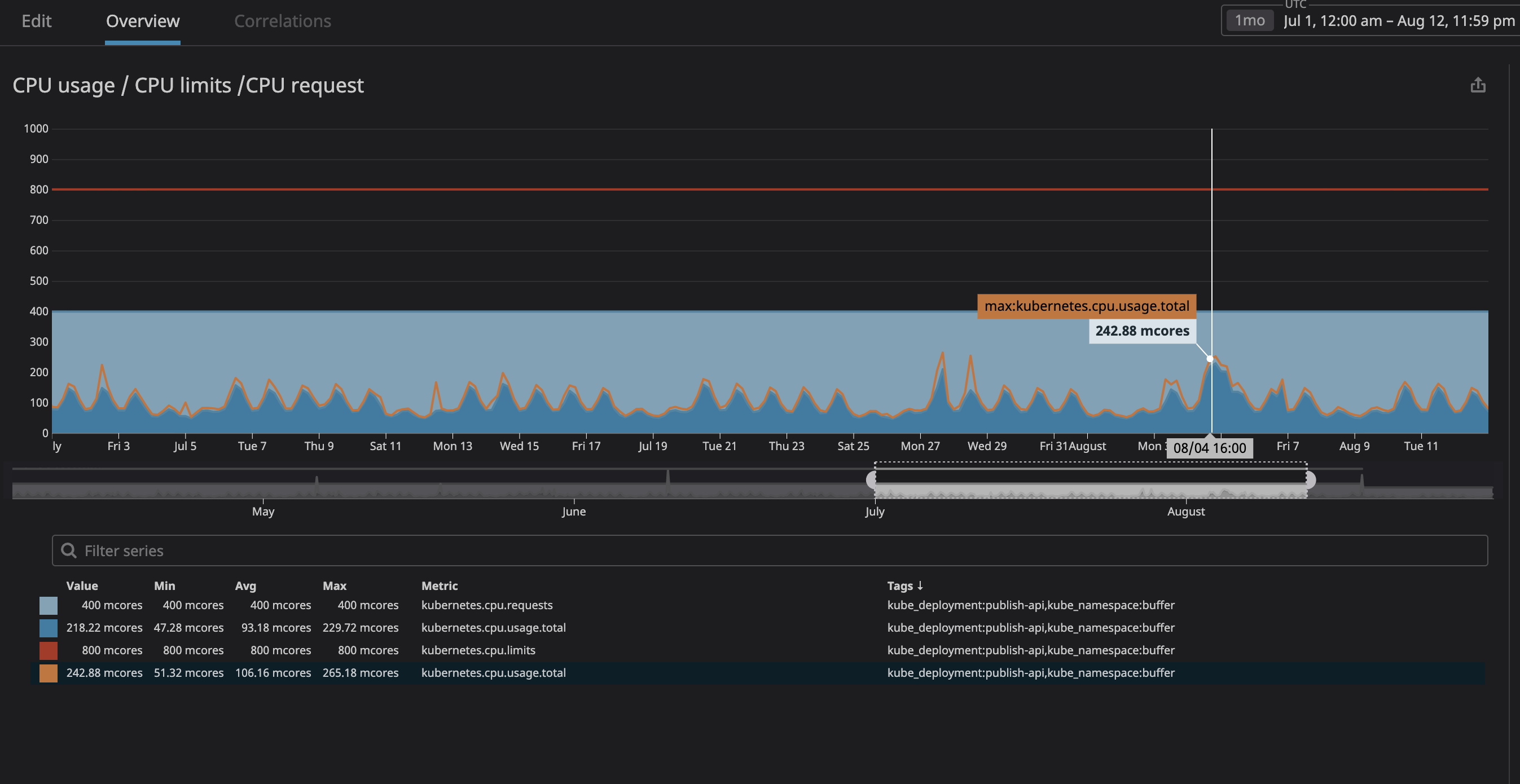
Como puede ver en el gráfico, la carga máxima del procesador ha alcanzado los
242mnúcleos de la CPU (0,242 núcleos de procesador). Para una solicitud de procesador, es suficiente tomar un número ligeramente mayor que este valor. Tenga en cuenta que, dado que los servicios están centrados en el usuario, los picos de carga coinciden con el tráfico.
Haga lo mismo con el uso de la memoria y las consultas, y listo, ¡ya está todo listo! Para mayor seguridad, puede agregar ajuste de escala automático horizontal de pods. Por lo tanto, cada vez que la carga de los recursos es alta, el ajuste de escala automático creará nuevos pods y kubernetes los distribuirá a los nodos con espacio libre. En caso de que no quede espacio en el clúster en sí, puede configurarse una alerta o configurar la adición de nuevos nodos a través de su autoescalado.
De las desventajas, vale la pena señalar que hemos perdido en la " densidad de contenedores ", es decir el número de contenedores que trabajan en un nodo. También es posible que tengamos muchas "indulgencias" con una densidad de tráfico baja, y también existe la posibilidad de que alcance una carga de procesador alta, pero el escalado automático de nodos debería ayudar con esto último.
resultados
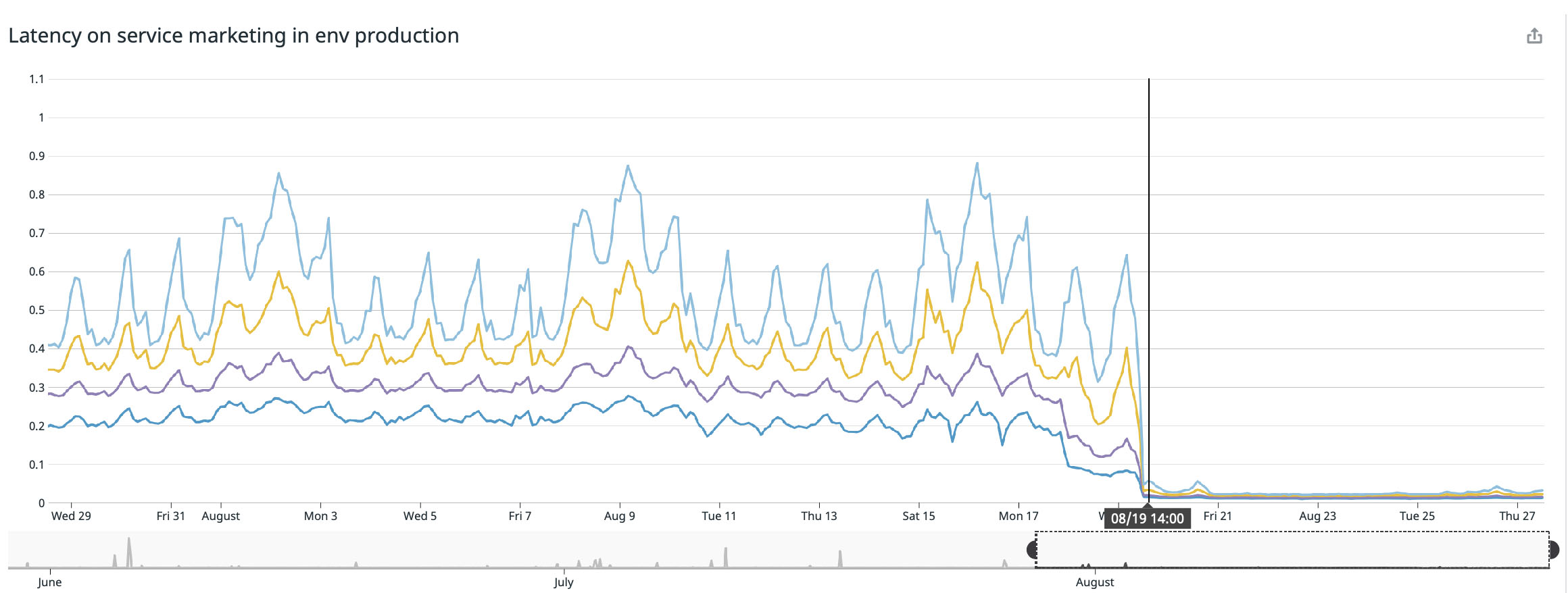
Estoy encantado de publicar estos excelentes resultados de experimentos durante las últimas semanas, ya hemos notado mejoras significativas en la respuesta entre todos los servicios modificados:
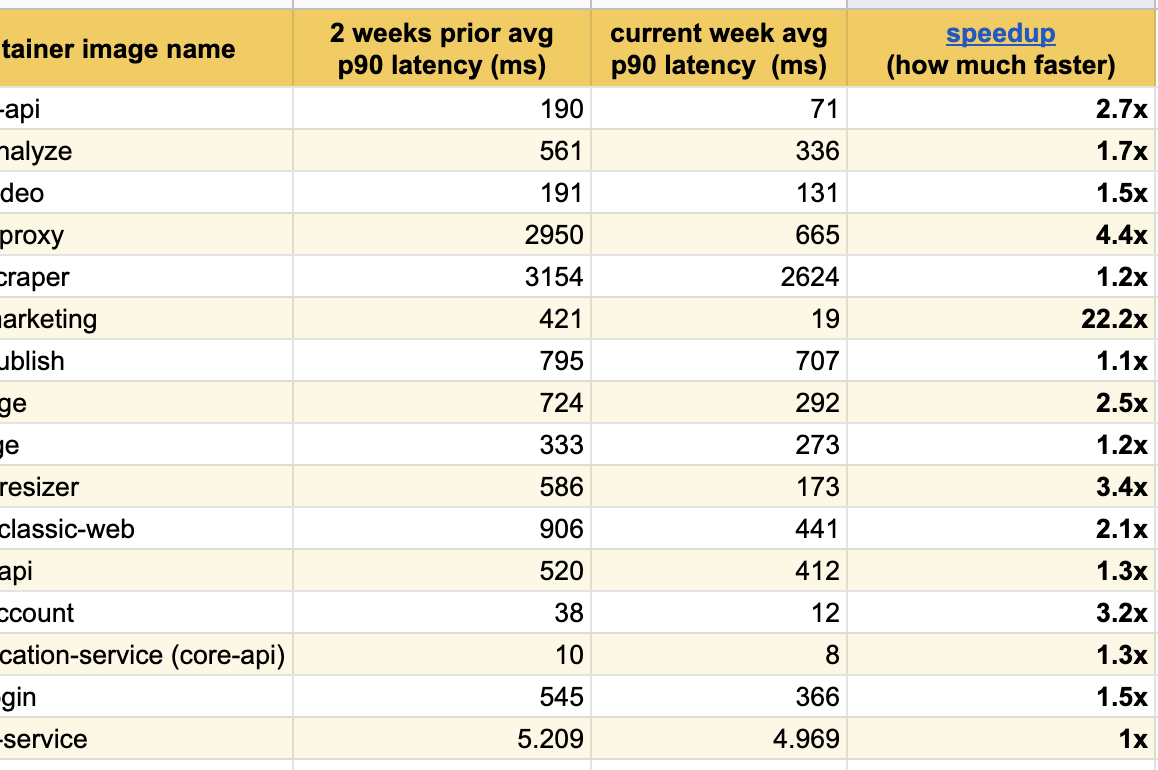
Logramos el mejor resultado en nuestra página principal ( buffer.com ), ¡allí el servicio fue veintidós veces más rápido !
¿Se corrigió el error del kernel de Linux?
Sí, el error ya se ha corregido y la corrección se ha agregado al kernel de distribuciones versión 4.19 y superior.
Sin embargo, mientras leemos el número de kubernetes en github del 2 de septiembre de 2020, todavía encontramos referencias a algunos proyectos de Linux con un error similar. Creo que algunas distribuciones de Linux todavía tienen este error y actualmente están trabajando para solucionarlo.
Si su versión de la distribución es inferior a 4.19, recomendaría actualizar a la última, pero debería intentar eliminar los límites del procesador de todos modos y ver si persiste la limitación. A continuación, puede encontrar una lista incompleta de la administración de servicios de Kubernetes y distribuciones de Linux:
- Debian: , buster, ( 2020 ). .
- Ubuntu: Ubuntu Focal Fossa 20.04
- EKS 2019 . , AMI.
- kops: 2020
kops 1.18+Ubuntu 20.04. kops , , , . . - GKE (Google Cloud): 2020 , .
¿Qué pasa si la solución solucionó el problema de aceleración?
No estoy seguro de que el problema se haya resuelto por completo. Cuando lleguemos a la versión fija del kernel, probaré el clúster y actualizaré la publicación. Si alguien ya ha actualizado, me gustaría revisar sus resultados con interés.
Conclusión
- Si trabaja con contenedores Docker en Linux (no importa Kubernetes, Mesos, Swarm o lo que sea), sus contenedores pueden perder rendimiento debido a la limitación;
- Intente actualizar a la última versión de su distribución con la esperanza de que el error ya se haya solucionado;
- Eliminar los límites del procesador resolverá el problema, pero esta es una técnica peligrosa que debe usarse con extrema precaución (es mejor actualizar el kernel primero y comparar los resultados);
- Si eliminó los límites del procesador, controle cuidadosamente el uso de su procesador y memoria, y asegúrese de que los recursos de su procesador excedan el consumo;
- Una opción segura sería autoescalar los pods para crear nuevos pods en caso de una gran carga de hardware, de modo que kubernetes los asigne a los nodos libres.
Espero que esta publicación te ayude a mejorar el rendimiento de tus sistemas de contenedores.
PD: Aquí el autor está en correspondencia con lectores y comentaristas (en inglés).