1.1 ¿Qué es el árbol de decisiones?
1.1.1 Ejemplo de árbol de decisión
Por ejemplo, tenemos el siguiente conjunto de datos (fecha establecida): clima, temperatura, humedad, viento, golf. Dependiendo del clima y todo lo demás, íbamos (〇) o no (×) jugamos al golf. Supongamos que tenemos 14 opciones preconcebidas.

A partir de estos datos, podemos componer una estructura de datos que muestre en qué casos fuimos al golf. Esta estructura se llama Árbol de decisión debido a su forma ramificada.
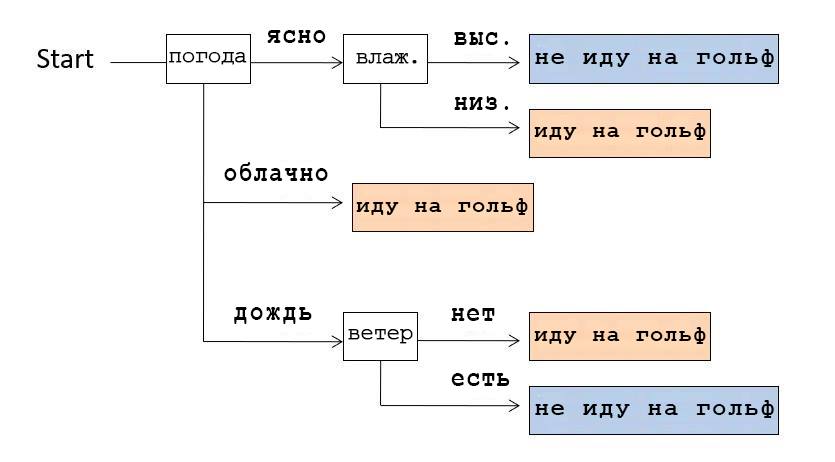
Por ejemplo, si miramos el árbol de decisiones que se muestra en la imagen de arriba, nos damos cuenta de que primero verificamos el clima. Si estaba claro, comprobamos la humedad: si es alta, entonces no fuimos a jugar al golf, si es baja, fuimos. Y si el tiempo estaba nublado, iban a jugar al golf, independientemente de otras condiciones.
1.1.2 Acerca de este artículo
Existen algoritmos que crean dichos árboles de decisión automáticamente en función de los datos disponibles. En este artículo, usaremos el algoritmo ID3 en Python.
Este artículo es el primero de una serie. Los siguientes artículos:
(Nota del traductor: “si está interesado en la secuela, háganoslo saber en los comentarios”).
- Fundamentos de la programación Python
- Conceptos básicos esenciales de la biblioteca para el análisis de datos de Pandas
- Conceptos básicos de la estructura de datos (en el caso del árbol de decisiones)
- Fundamentos de la entropía de la información
- Aprender un algoritmo para generar un árbol de decisiones
1.1.3 Un poco sobre el árbol de decisiones
La generación de árboles de decisión está relacionada con el aprendizaje automático y la clasificación supervisados. La clasificación en el aprendizaje automático es una forma de crear un modelo que conduzca a la respuesta correcta en función del entrenamiento en la fecha establecida con las respuestas correctas y los datos que las conducen. El Deep Learning, que ha sido muy popular en los últimos años, especialmente en el campo del reconocimiento de imágenes, también forma parte del aprendizaje automático basado en el método de clasificación. La diferencia entre Deep Learning y Decision Tree es si el resultado final se reduce a una forma en la que una persona comprende los principios de generación de la estructura de datos final. La peculiaridad del Deep Learning es que obtenemos el resultado final, pero no entendemos el principio de su generación. A diferencia del aprendizaje profundo, el árbol de decisiones es fácil de entender para los humanos, lo que también es una característica importante.
Esta característica de Decision Tree es buena no solo para el aprendizaje automático, sino también para la minería de datos, donde la comprensión de los datos por parte del usuario también es importante.
1.2 Sobre el algoritmo ID3
ID3 es un algoritmo de generación de árboles de decisión desarrollado en 1986 por Ross Quinlan. Tiene dos características importantes:
- Datos categóricos. Estos son datos similares a nuestro ejemplo anterior (vaya al golf o no), datos con una etiqueta categórica específica. ID3 no puede utilizar datos numéricos.
- La entropía de la información es un indicador que indica una secuencia de datos con la menor variación de las propiedades de una clase de valores.
1.2.1 Acerca del uso de datos numéricos
El algoritmo C4.5, que es una versión más avanzada de ID3, puede usar datos numéricos, pero como la idea básica es la misma en esta serie, usaremos ID3 primero.
1.3 Entorno de desarrollo
El programa que describí a continuación, lo probé y ejecuté en las siguientes condiciones:
- Jupyter Notebooks (con Azure Notebooks)
- Python 3.6
- Bibliotecas: matemáticas, pandas, functools (no usó scikit-learn, tensorflow, etc.)
1.4 Programa de muestra
1.4.1 En realidad, el programa
Primero, copiemos el programa en Jupyter Notebook y ejecútelo.
import math
import pandas as pd
from functools import reduce
#
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
# - , ,
# .
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],
}
df0 = pd.DataFrame(d)
# - , - pandas.Series,
# -
# s value_counts() ,
# , , items().
# , sorted,
#
# , , : (k) (v).
cstr = lambda s:[k+":"+str(v) for k,v in sorted(s.value_counts().items())]
# Decision Tree
tree = {
# name: ()
"name":"decision tree "+df0.columns[-1]+" "+str(cstr(df0.iloc[:,-1])),
# df: , ()
"df":df0,
# edges: (), ,
# , .
"edges":[],
}
# , , open
open = [tree]
# - .
# - pandas.Series、 -
entropy = lambda s:-reduce(lambda x,y:x+y,map(lambda x:(x/len(s))*math.log2(x/len(s)),s.value_counts()))
# , open
while(len(open)!=0):
# open ,
# ,
n = open.pop(0)
df_n = n["df"]
# , 0,
#
if 0==entropy(df_n.iloc[:,-1]):
continue
# ,
attrs = {}
# ,
for attr in df_n.columns[:-1]:
# , ,
# , .
attrs[attr] = {"entropy":0,"dfs":[],"values":[]}
# .
# , sorted ,
# , .
for value in sorted(set(df_n[attr])):
#
df_m = df_n.query(attr+"=='"+value+"'")
# ,
attrs[attr]["entropy"] += entropy(df_m.iloc[:,-1])*df_m.shape[0]/df_n.shape[0]
attrs[attr]["dfs"] += [df_m]
attrs[attr]["values"] += [value]
pass
pass
# , ,
# .
if len(attrs)==0:
continue
#
attr = min(attrs,key=lambda x:attrs[x]["entropy"])
#
# , , open.
for d,v in zip(attrs[attr]["dfs"],attrs[attr]["values"]):
m = {"name":attr+"="+v,"edges":[],"df":d.drop(columns=attr)}
n["edges"].append(m)
open.append(m)
pass
#
print(df0,"\n-------------")
# , - tree: ,
# indent: indent,
# - .
# .
def tstr(tree,indent=""):
# .
# ( 0),
# df, , .
s = indent+tree["name"]+str(cstr(tree["df"].iloc[:,-1]) if len(tree["edges"])==0 else "")+"\n"
# .
for e in tree["edges"]:
# .
# indent .
s += tstr(e,indent+" ")
pass
return s
# .
print(tstr(tree))1.4.2 Resultado
Si ejecuta el programa anterior, nuestro árbol de decisiones se representará como una tabla de símbolos como se muestra a continuación.
decision tree ['×:5', '○:9']
=
=['○:2']
=['×:3']
=['○:4']
=
=['×:2']
=['○:3']
1.4.3 Cambiar los atributos (matrices de datos) que queremos explorar
La última matriz en el conjunto de fechas d es un atributo de clase (la matriz de datos que queremos clasificar).
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],}
# - , , .
"":["","","","","","","","","","","","","",""],
}Por ejemplo, si intercambia las matrices "Golf" y "Viento", como se muestra en el ejemplo anterior, obtendrá el siguiente resultado:
decision tree [':6', ':8']
=×
=
=
=[':1', ':1']
=[':1']
=[':2']
=○
=
=[':1']
=[':1']
=
=[':2']
=[':1']
=[':1']
=[':3']En esencia, creamos una regla en la que le decimos al programa que se ramifique primero por la presencia y ausencia de viento y por si vamos a jugar al golf o no.
¡Gracias por leer!
Estaremos muy contentos si nos dices si te gustó este artículo, fue clara la traducción, te fue útil?