Es conveniente procesar texto en lenguaje natural usando Python, ya que es una herramienta de programación de bastante alto nivel, tiene una infraestructura bien desarrollada y ha demostrado su eficacia en el campo del análisis de datos y el aprendizaje automático. La comunidad ha desarrollado varias bibliotecas y marcos para resolver problemas de PNL en Python. En nuestro trabajo, utilizaremos una herramienta web interactiva para desarrollar scripts de Python, Jupyter Notebook, la biblioteca NLTK para análisis de texto y la biblioteca de wordcloud para construir una nube de palabras.
La red contiene una cantidad bastante grande de material sobre el tema del análisis de texto, pero muchos artículos (incluidos los en idioma ruso) sugieren analizar el texto en inglés. El análisis del texto ruso tiene algunos detalles sobre el uso de las herramientas de PNL. Como ejemplo, considere el análisis de frecuencia del texto del cuento "Tormenta de nieve" de A. Pushkin.
El análisis de frecuencia se puede dividir aproximadamente en varias etapas:
- Carga y navegación de datos
- Limpieza y preprocesamiento de texto
- Eliminar palabras vacías
- Traducir palabras a forma básica
- Calcular las estadísticas de ocurrencia de palabras en el texto.
- Visualización en la nube de la popularidad de las palabras
El script está disponible en github.com/Metafiz/nlp-course-20/blob/master/frequency-analisys-of-text.ipynb , fuente: github.com/Metafiz/nlp-course-20/blob/master/pushkin -metel.txt
Cargando datos
Abrimos el archivo usando la función abierta incorporada, especificamos el modo de lectura y la codificación. Leemos todo el contenido del archivo, como resultado obtenemos la cadena de texto:
f = open('pushkin-metel.txt', "r", encoding="utf-8")
text = f.read()
La longitud del texto (el número de caracteres) se puede obtener con la función estándar len:
len(text)
Una cadena en Python se puede representar como una lista de caracteres, por lo que el acceso al índice y las operaciones de corte también son posibles para trabajar con cadenas. Por ejemplo, para ver los primeros 300 caracteres de texto, simplemente ejecute el comando:
text[:300]
Preprocesamiento (preprocesamiento) de texto
Para realizar análisis de frecuencia y determinar el tema del texto, se recomienda borrar el texto de signos de puntuación, espacios en blanco adicionales y números. Puede hacer esto de varias formas: utilizando funciones de cadena integradas, utilizando expresiones regulares, utilizando el procesamiento de listas o de otra forma.
Primero, convierta los caracteres a un solo caso, por ejemplo, inferior:
text = text.lower()
Usamos el juego de caracteres de puntuación estándar del módulo de cadena:
import string
print(string.punctuation)
string.punctuation es una cadena. El conjunto de caracteres especiales que se eliminarán del texto se puede ampliar. Es necesario analizar el texto fuente e identificar los caracteres que deben eliminarse. Agreguemos saltos de línea, tabulaciones y otros caracteres que se encuentran en nuestro texto fuente a los signos de puntuación (por ejemplo, el carácter con el código \ xa0):
spec_chars = string.punctuation + '\n\xa0«»\t—…'
Para eliminar caracteres, usamos el procesamiento elemento por elemento de la cadena: dividimos la cadena de texto original en caracteres, dejamos solo los caracteres que no están incluidos en el conjunto spec_chars y nuevamente combinamos la lista de caracteres en una cadena:
text = "".join([ch for ch in text if ch not in spec_chars])
Puede declarar una función simple que elimina el juego de caracteres especificado del texto fuente:
def remove_chars_from_text(text, chars):
return "".join([ch for ch in text if ch not in chars])
Se puede utilizar tanto para eliminar caracteres especiales como para eliminar números del texto original:
text = remove_chars_from_text(text, spec_chars)
text = remove_chars_from_text(text, string.digits)
Tokenizando texto
Para su posterior procesamiento, el texto limpio debe dividirse en sus partes componentes: tokens. El análisis de texto en lenguaje natural utiliza desgloses de símbolos, palabras y oraciones. El proceso de partición se llama tokenización. Para nuestra tarea de análisis de frecuencia, es necesario descomponer el texto en palabras. Para hacer esto, puede usar el método listo para usar de la biblioteca NLTK:
from nltk import word_tokenize
text_tokens = word_tokenize(text)
La variable text_tokens es una lista de palabras (tokens). Para calcular la cantidad de palabras en el texto preprocesado, puede obtener la longitud de la lista de tokens:
len(text_tokens)
Para mostrar las primeras 10 palabras, usemos la operación de división:
text_tokens[:10]
Para utilizar las herramientas de análisis de frecuencia de la biblioteca NLTK, debe convertir la lista de tokens a la clase Text, que se incluye en esta biblioteca:
import nltk
text = nltk.Text(text_tokens)
Deduzcamos el tipo de texto variable:
print(type(text))
Las operaciones de corte también son aplicables a una variable de este tipo. Por ejemplo, esta acción generará los primeros 10 tokens del texto:
text[:10]
Calcular las estadísticas de ocurrencia de palabras en el texto.
La clase FreqDist (distribuciones de frecuencia) se utiliza para calcular las estadísticas de distribución de frecuencia de palabras en el texto:
from nltk.probability import FreqDist
fdist = FreqDist(text)
Al intentar mostrar la variable fdist, se mostrará un diccionario que contiene tokens y sus frecuencias: la cantidad de veces que estas palabras aparecen en el texto:
FreqDist({'': 146, '': 101, '': 69, '': 54, '': 44, '': 42, '': 39, '': 39, '': 31, '': 27, ...})
También puede usar el método most_common para obtener una lista de tuplas con los tokens más comunes:
fdist.most_common(5)
[('', 146), ('', 101), ('', 69), ('', 54), ('', 44)]
La frecuencia de distribución de palabras en un texto se puede visualizar mediante un gráfico. La clase FreqDist contiene un método de trazado incorporado para trazar dicho trazado. Es necesario indicar el número de tokens, cuyas frecuencias se mostrarán en el gráfico. Con el parámetro cumulative = False, el gráfico ilustra la ley de Zipf : si todas las palabras de un texto suficientemente largo se ordenan en orden descendente de frecuencia de uso, entonces la frecuencia de la enésima palabra en dicha lista será aproximadamente inversamente proporcional a su número ordinal n.
fdist.plot(30,cumulative=False)
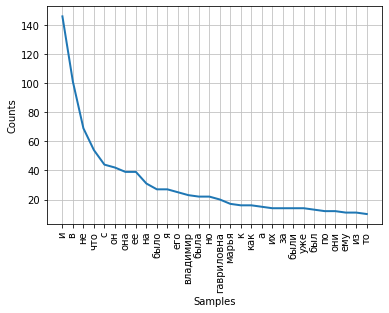
Se puede notar que en este momento las frecuencias más altas tienen conjunciones, preposiciones y otras partes de servicio del habla que no llevan carga semántica, sino que solo expresan relaciones semántico-sintácticas entre palabras. Para que los resultados del análisis de frecuencia reflejen el tema del texto, es necesario eliminar estas palabras del texto.
Eliminar palabras vacías
Las palabras vacías (o palabras irrelevantes), por regla general, incluyen preposiciones, conjunciones, interjecciones, partículas y otras partes del habla que a menudo se encuentran en el texto, son de servicio y no tienen una carga semántica, son redundantes.
La biblioteca NLTK contiene listas de palabras vacías listas para usar para varios idiomas. Consigamos una lista de cien palabras para el idioma ruso:
from nltk.corpus import stopwords
russian_stopwords = stopwords.words("russian")
Cabe señalar que las palabras vacías son sensibles al contexto; para textos de diferentes temas, las palabras vacías pueden diferir. Como en el caso de los caracteres especiales, es necesario analizar el texto fuente e identificar las palabras vacías que no están incluidas en el conjunto estándar.
La lista de palabras vacías se puede ampliar utilizando el método de ampliación estándar:
russian_stopwords.extend(['', ''])
Después de eliminar las palabras vacías, la frecuencia de distribución de los tokens en el texto es la siguiente:
fdist_sw.most_common(10)
[('', 23),
('', 20),
('', 17),
('', 9),
('', 9),
('', 8),
('', 7),
('', 6),
('', 6),
('', 6)]
Como puede ver, los resultados del análisis de frecuencia se han vuelto más informativos y reflejan con mayor precisión el tema principal del texto. Sin embargo, vemos en los resultados fichas como "vladimir" y "vladimira", que son, de hecho, una palabra, pero en formas diferentes. Para corregir esta situación, es necesario llevar las palabras del texto fuente a sus bases o su forma original, para realizar la derivación o lematización.
Visualización en la nube de la popularidad de las palabras
Al final de nuestro trabajo, visualizamos los resultados del análisis de frecuencia del texto en forma de "nube de palabras".
Para ello, necesitamos las bibliotecas wordcloud y matplotlib:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
%matplotlib inline
Para crear una nube de palabras, se debe pasar una cadena al método como entrada. Para convertir la lista de tokens después de preprocesar y eliminar palabras vacías, usaremos el método join, especificando un espacio como separador:
text_raw = " ".join(text)
Llamemos al método para construir la nube:
wordcloud = WordCloud().generate(text_raw)
Como resultado, obtenemos una "nube de palabras" para nuestro texto:

mirándolo, puede obtener una idea general del tema y los personajes principales del trabajo.