En este artículo intentaremos escribir un clasificador para definir artículos sarcásticos usando aprendizaje automático y TensorFlow.
El artículo es una traducción de Machine Learning Foundations: Part 10 - Using NLP to build a sarcasm clasifier
El conjunto de datos Sarcasm in News Headlines de Rishab Mishra se utiliza como conjunto de datos de entrenamiento . Es un conjunto de datos interesante que recopila titulares de noticias de fuentes de noticias convencionales, así como algunos más cómicos de sitios de noticias falsos.
El conjunto de datos es un archivo JSON con tres columnas.
is_sarcastic- 1 si la entrada es sarcástica, de lo contrario 0headline- título del artículoarticle_link- URL del texto del artículo
Solo veremos los encabezados aquí. Así que tenemos un conjunto de datos muy simple con el que trabajar. El encabezado es nuestra característica e is_sarcastic es nuestro atajo.
Los datos JSON se parecen a esto.
{
"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5",
"headline": "former versace store clerk sues over secret 'black code' for minority shoppers",
"is_sarcastic": 0
}Cada registro es un campo JSON con pares de nombre-valor que muestran la columna y los datos asociados.
Aquí está el código para cargar datos en Python
import json
with open("sarcasm.json", 'r') as f:
datastore = json.load(f)
sentences = []
labels = []
urls = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
urls.append(item['article_link']) . -, import json json Python. sarcasm.json. json.load(), . , URL-. . , URL- .
.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(oov_token="")
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(len(word_index))
print(word_index)
sequences = tokenizer.texts_to_sequences(sentences)
padded = pad_sequences(sequences, padding='post')
print(padded[0])
print(padded.shape) . 25 000 , . word_index . .
... 'blowing': 4064, 'packed': 4065, 'deficit': 4066, 'essential': 4067, 'explaining': 4068, 'pollution': 4069, 'braces': 4070, 'protester': 4071, 'uncle': 4072 ..., , . , , , .
[ 308 15115 679 3337 2298 48 382 2576 15116 6 2577 8434
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0]
(26709, 40). , . 26 709 , 40 .
, .
voiceab_size = 10000
embedding_dim = 16
max_length = 100
trunc_type = 'post'
padding_type = 'post'
oov_tok = ""
training_size = 20000 26 000 20 000 , training_size, 6000 .
training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:], , , , .
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
training_sequences = tokenizer.texts_to_sequences(training_sentences)
training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type) , , . training_sentence. . test_sentences , . training_sequences training_sentences. , . testing_sentences .
, , , . — , , . , . .
, «Bad» «Good». , . , .

«meh» , . .
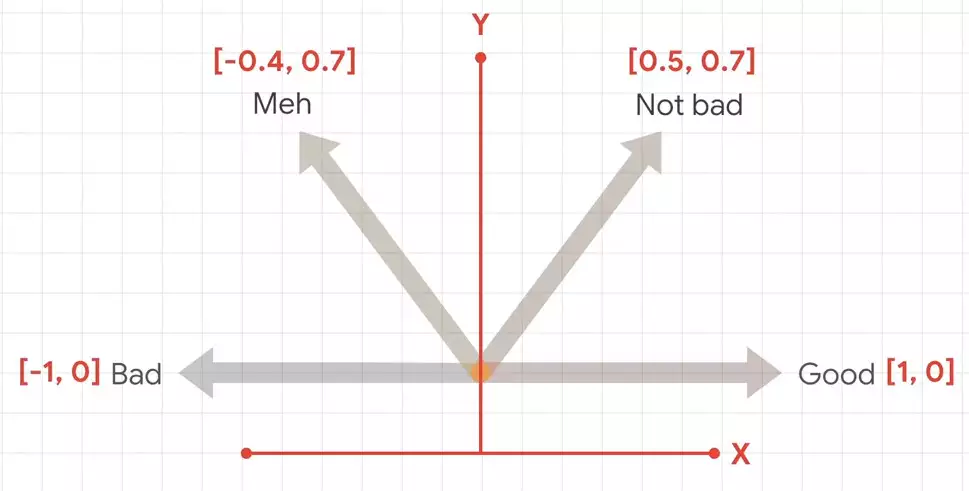
«not bad», , «Good», , . , .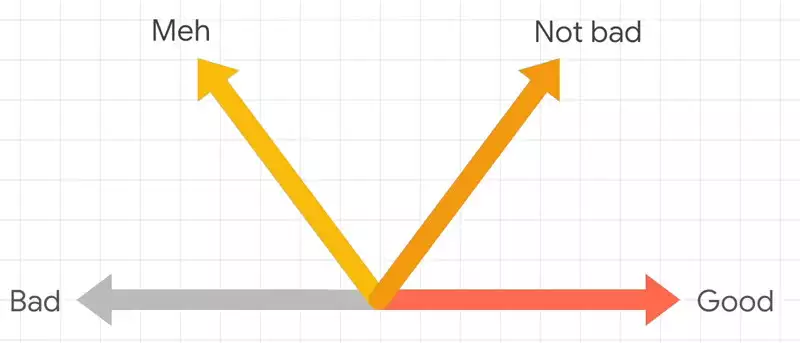
, . .
, .
, Keras, Embedding.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])Embedding . , , , . 16, . , Embedding 10 016 , . , , .
, .
num_epochs = 30
history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2) training_padded, .
, Google Colab, .