Veamos qué soluciones tiene este problema.
Distribución de objetos "por capacidad"
Para no ahondar en abstracciones poco interesantes, lo consideraremos usando el ejemplo de una tarea específica: el monitoreo . Estoy seguro de que podrá relacionar los métodos propuestos con sus tareas específicas por su cuenta.
Objetos de supervisión "equivalentes"
Un ejemplo son nuestros recopiladores de métricas para Zabbix , que históricamente comparten una arquitectura común con los recopiladores de registros de PostgreSQL. De hecho
, cada objeto de monitoreo (host) genera para zabbix casi de manera estable el mismo conjunto de métricas con la misma frecuencia todo el tiempo:
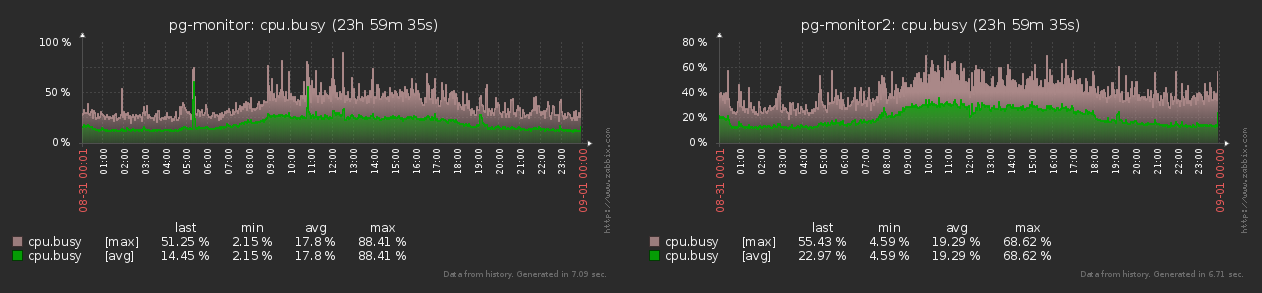
Como puede ver en el gráfico, la diferencia entre los valores mínimo y máximo del número de métricas generadas no supera el 15% . Por tanto, podemos considerar que todos los objetos son iguales en los mismos "loros" .
Fuerte "desequilibrio" entre objetos
A diferencia del modelo anterior, los hosts monitoreados están lejos de ser homogéneos para los recolectores de registros .
Por ejemplo, un host puede generar un millón de planes por día en el registro, otras decenas de miles y algunos, incluso solo unos pocos. Y los planes en sí son muy diferentes en términos de volumen y complejidad y en términos de distribución a lo largo del día. Entonces resulta que la carga "tiembla" fuertemente , a veces:

Bueno, dado que la carga puede cambiar tanto, entonces necesitas aprender a manejarla ...
Coordinador
Entendemos de inmediato que obviamente necesitamos escalar el sistema colector, ya que un nodo separado con toda la carga algún día dejará de funcionar. Y para ello necesitamos un coordinador , alguien que gestione todo el zoológico.
Resulta algo como esto:

Cada trabajador su carga "en loros" y como un porcentaje de la CPU restablece periódicamente el maestro, esos - al colector. Y él, sobre la base de estos datos, puede emitir un comando como "poner un nuevo host en un trabajador n. ° 4 descargado" o "el hostA debe transferirse al trabajador n. ° 3" .
Aquí también debe recordar que, a diferencia de los objetos de monitoreo, los colectores en sí no tienen la misma "potencia" en absoluto ; por ejemplo, en uno puede tener 8 núcleos de CPU y en el otro, solo 4, e incluso una frecuencia más baja. Y si los carga con tareas "igualmente", entonces el segundo comenzará a "callarse" y el primero estará inactivo. De ahí se sigue ...
Tareas del coordinador
De hecho, solo hay una tarea: garantizar la distribución más uniforme de toda la carga (en% cpu) entre todos los trabajadores disponibles. Si podemos resolverlo perfectamente, entonces la uniformidad de la distribución de% cpu-load sobre los colectores se obtendrá “automáticamente”.
Está claro que incluso si cada objeto genera la misma carga, con el tiempo, algunos de ellos pueden "morir" y aparecen otros nuevos. Por lo tanto, debe poder gestionar toda la situación de forma dinámica y mantener un equilibrio constantemente .
Equilibrio dinámico
Podemos resolver un problema simple (zabbix) de manera bastante trivial:
- calculamos la capacidad relativa de cada recolector "en tareas"
- dividir todas las tareas entre ellos proporcionalmente
- distribuimos uniformemente entre trabajadores

Pero, ¿qué hacer en caso de objetos "fuertemente desiguales", como para un recolector de registros? ...
Evaluación de uniformidad
Anteriormente, usamos el término " distribución máximamente uniforme " todo el tiempo , pero ¿cómo se pueden comparar formalmente dos distribuciones, cuál es "más uniforme"?
Para evaluar la uniformidad en matemáticas, existe desde hace mucho tiempo la desviación estándar . ¿Quién es perezoso para leer?
S[X] = sqrt( sum[ ( x - avg[X] ) ^ 2 of X ] / count[X] )Dado que el número de trabajadores en cada uno de los colectores también puede diferir para nosotros, es necesario normalizar la distribución de la carga no solo entre ellos, sino también entre los colectores en su conjunto .
Es decir, la distribución de la carga sobre los trabajadores de los dos recolectores
[ (10%, 10%, 10%, 10%, 10%, 10%) ; (20%) ]tampoco es muy buena, ya que el primero resulta ser el 10% y el segundo el 20% , que es, por así decirlo, el doble en términos relativos.
Por lo tanto, introducimos una distancia métrica única para una estimación general de "uniformidad":
d([%wrk], [%col]) = sqrt( S[%wrk] ^ 2 + S[%col] ^ 2 )Modelado
Si tuviéramos algunos objetos, entonces podríamos "descomponerlos" por la fuerza bruta entre los trabajadores para que la métrica fuera mínima . Pero tenemos miles de objetos, por lo que este método no funcionará. Pero sabemos que el recolector puede "mover" un objeto de un trabajador a otro; modelemos esta opción usando el método de descenso de gradiente .
Está claro que es posible que no encontremos el mínimo “ideal” de la métrica, pero el local es seguro. Y la carga en sí puede variar tanto en el tiempo que no hay absolutamente ninguna necesidad de buscar un "ideal" durante un tiempo infinito .
Es decir, solo tenemos que determinar qué objeto ya qué trabajador es más eficiente "mover". Y hagámoslo un modelado exhaustivo trivial:
- ( host, worker)
- host worker' «»
«» . - « »
- d «»
Alineamos todos los pares en métrica ascendente . Idealmente, siempre deberíamos implementar la transferencia del primer par, ya que da la métrica objetivo mínima. Desafortunadamente, en realidad, el proceso de transferencia en sí "cuesta recursos", por lo que no debe ejecutarlo para el mismo objeto con más frecuencia que un cierto intervalo de "enfriamiento" .
En este caso, podemos tomar el segundo, tercer, ... par por rango, si solo la métrica objetivo disminuyera en relación con el valor actual.
Si no hay ningún lugar donde disminuir, ¡aquí es un mínimo local!
Ejemplo en la imagen:

No es necesario iniciar iteraciones "hasta el final". Por ejemplo, puede realizar un análisis de carga promedio en un intervalo de 1 minuto y, al finalizar, realizar una sola transferencia.
Microoptimizaciones
Está claro que un algoritmo con complejidad
T() x W()no es muy bueno. Pero en él no debes olvidarte de aplicar algunas optimizaciones más o menos obvias que pueden acelerarlo por momentos.
Cero "loros"
Si un objeto / tarea / host ha generado una carga de "0 piezas" en el intervalo medido , entonces no es algo que se mueva a alguna parte, ni siquiera necesita ser considerado y analizado.
Auto-transferencia
Al generar pares, no es necesario evaluar la eficiencia de transferir un objeto al mismo trabajador , donde ya está ubicado. Después de todo, ya lo será
T x (W - 1), ¡un poco, pero bueno!
Carga indiscernible
Dado que estamos modelando la transferencia de la carga, y el objeto es solo una herramienta, no tiene sentido intentar transferir el "mismo"% cpu ; los valores de las métricas permanecerán exactamente iguales, aunque para una distribución diferente de objetos.
Es decir, basta con evaluar un solo modelo para la tupla (wrkSrc, wrkDst,% cpu) . Bueno, y puede considerar "igual", por ejemplo, valores de% de CPU que coinciden con hasta 1 lugar decimal.
Implementación de ejemplo de JavaScript
var col = {
'c1' : {
'wrk' : {
'w1' : {
'hst' : {
'h1' : 5
, 'h2' : 1
, 'h3' : 1
}
, 'cpu' : 80.0
}
, 'w2' : {
'hst' : {
'h4' : 1
, 'h5' : 1
, 'h6' : 1
}
, 'cpu' : 20.0
}
}
}
, 'c2' : {
'wrk' : {
'w1' : {
'hst' : {
'h7' : 1
, 'h8' : 2
}
, 'cpu' : 100.0
}
, 'w2' : {
'hst' : {
'h9' : 1
, 'hA' : 1
, 'hB' : 1
}
, 'cpu' : 50.0
}
}
}
};
// ""
let $iv = (obj, fn) => Object.values(obj).forEach(fn);
let $mv = (obj, fn) => Object.values(obj).map(fn);
// initial reparse
for (const [cid, c] of Object.entries(col)) {
$iv(c.wrk, w => {
w.hst = Object.keys(w.hst).reduce((rv, hid) => {
if (typeof w.hst[hid] == 'object') {
rv[hid] = w.hst[hid];
return rv;
}
// ,
if (w.hst[hid]) {
rv[hid] = {'qty' : w.hst[hid]};
}
return rv;
}, {});
});
c.wrk = Object.keys(c.wrk).reduce((rv, wid) => {
// ID -
rv[cid + ':' + wid] = c.wrk[wid];
return rv;
}, {});
}
//
let S = col => {
let wsum = 0
, wavg = 0
, wqty = 0
, csum = 0
, cavg = 0
, cqty = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += w.cpu;
wqty++;
});
csum += c.cpu;
cqty++;
});
wavg = wsum/wqty;
wsum = 0;
cavg = csum/cqty;
csum = 0;
$iv(col, c => {
$iv(c.wrk, w => {
wsum += (w.cpu - wavg) ** 2;
});
csum += (c.cpu - cavg) ** 2;
});
return [Math.sqrt(wsum/wqty), Math.sqrt(csum/cqty)];
};
// -
let distS = S => Math.sqrt(S[0] ** 2 + S[1] ** 2);
//
let iterReOrder = col => {
let qty = 0
, max = 0;
$iv(col, c => {
c.qty = 0;
c.cpu = 0;
$iv(c.wrk, w => {
w.qty = 0;
$iv(w.hst, h => {
w.qty += h.qty;
});
w.max = w.qty * (100/w.cpu);
c.qty += w.qty;
c.cpu += w.cpu;
});
c.cpu = c.cpu/Object.keys(c.wrk).length;
c.max = c.qty * (100/c.cpu);
qty += c.qty;
max += c.max;
});
$iv(col, c => {
c.nrm = c.max/max;
$iv(c.wrk, w => {
$iv(w.hst, h => {
h.cpu = h.qty/w.qty * w.cpu;
h.nrm = h.cpu * c.nrm;
});
});
});
// ""
console.log(S(col), distS(S(col)));
//
let wrk = {};
let hst = {};
for (const [cid, c] of Object.entries(col)) {
for (const [wid, w] of Object.entries(c.wrk)) {
wrk[wid] = {
wid
, cid
, 'wrk' : w
, 'col' : c
};
for (const [hid, h] of Object.entries(w.hst)) {
hst[hid] = {
hid
, wid
, cid
, 'hst' : h
, 'wrk' : w
, 'col' : c
};
}
}
}
// worker
let move = (col, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
let wsrc = col[h.cid].wrk[h.wid]
, wdst = col[w.cid].wrk[w.wid];
wsrc.cpu -= h.hst.cpu;
wsrc.qty -= h.hst.qty;
wdst.qty += h.hst.qty;
// "" CPU
if (h.cid != w.cid) {
let csrc = col[h.cid]
, cdst = col[w.cid];
csrc.qty -= h.hst.qty;
csrc.cpu -= h.hst.cpu/Object.keys(csrc.wrk).length;
wsrc.hst[hid].cpu = h.hst.cpu * csrc.nrm/cdst.nrm;
cdst.qty += h.hst.qty;
cdst.cpu += h.hst.cpu/Object.keys(cdst.wrk).length;
}
wdst.cpu += wsrc.hst[hid].cpu;
wdst.hst[hid] = wsrc.hst[hid];
delete wsrc.hst[hid];
};
// (host, worker)
let moveCheck = (orig, hid, wid) => {
let w = wrk[wid]
, h = hst[hid];
// -
if (h.wid == w.wid) {
return;
}
let col = JSON.parse(JSON.stringify(orig));
move(col, hid, wid);
return S(col);
};
// (hsrc,hdst,%cpu)
let checked = {};
// ( -> )
let moveRanker = col => {
let currS = S(col);
let order = [];
for (hid in hst) {
for (wid in wrk) {
// ( 0.1%) ""
let widsrc = hst[hid].wid;
let idx = widsrc + '|' + wid + '|' + hst[hid].hst.cpu.toFixed(1);
if (idx in checked) {
continue;
}
let _S = moveCheck(col, hid, wid);
if (_S === undefined) {
_S = currS;
}
checked[idx] = {
hid
, wid
, S : _S
};
order.push(checked[idx]);
}
}
order.sort((x, y) => distS(x.S) - distS(y.S));
return order;
};
let currS = S(col);
let order = moveRanker(col);
let opt = order[0];
console.log('best move', opt);
//
if (distS(opt.S) < distS(currS)) {
console.log('move!', opt.hid, opt.wid);
move(col, opt.hid, opt.wid);
console.log('after move', JSON.parse(JSON.stringify(col)));
return true;
}
else {
console.log('none!');
}
return false;
};
// -
while(iterReOrder(col));Como resultado, la carga en nuestros embalses se distribuye casi igual en cada momento del tiempo, nivelando rápidamente los picos emergentes: