- Buenas noches, mi nombre es Masha, trabajo en el departamento de análisis de datos de Eddila y hoy tenemos una conferencia sobre pruebas contigo.

Primero, discutiremos con usted qué tipos de pruebas hay en general, y trataré de convencerlo de por qué necesita escribir pruebas. Luego hablaremos de lo que tenemos en Python para trabajar directamente con las pruebas, con sus módulos de escritura y auxiliares. Al final, les contaré un poco sobre CI, una parte inevitable de la vida en una gran empresa.
Me gustaría empezar con un ejemplo. Intentaré explicar con ejemplos muy aterradores por qué vale la pena escribir pruebas.
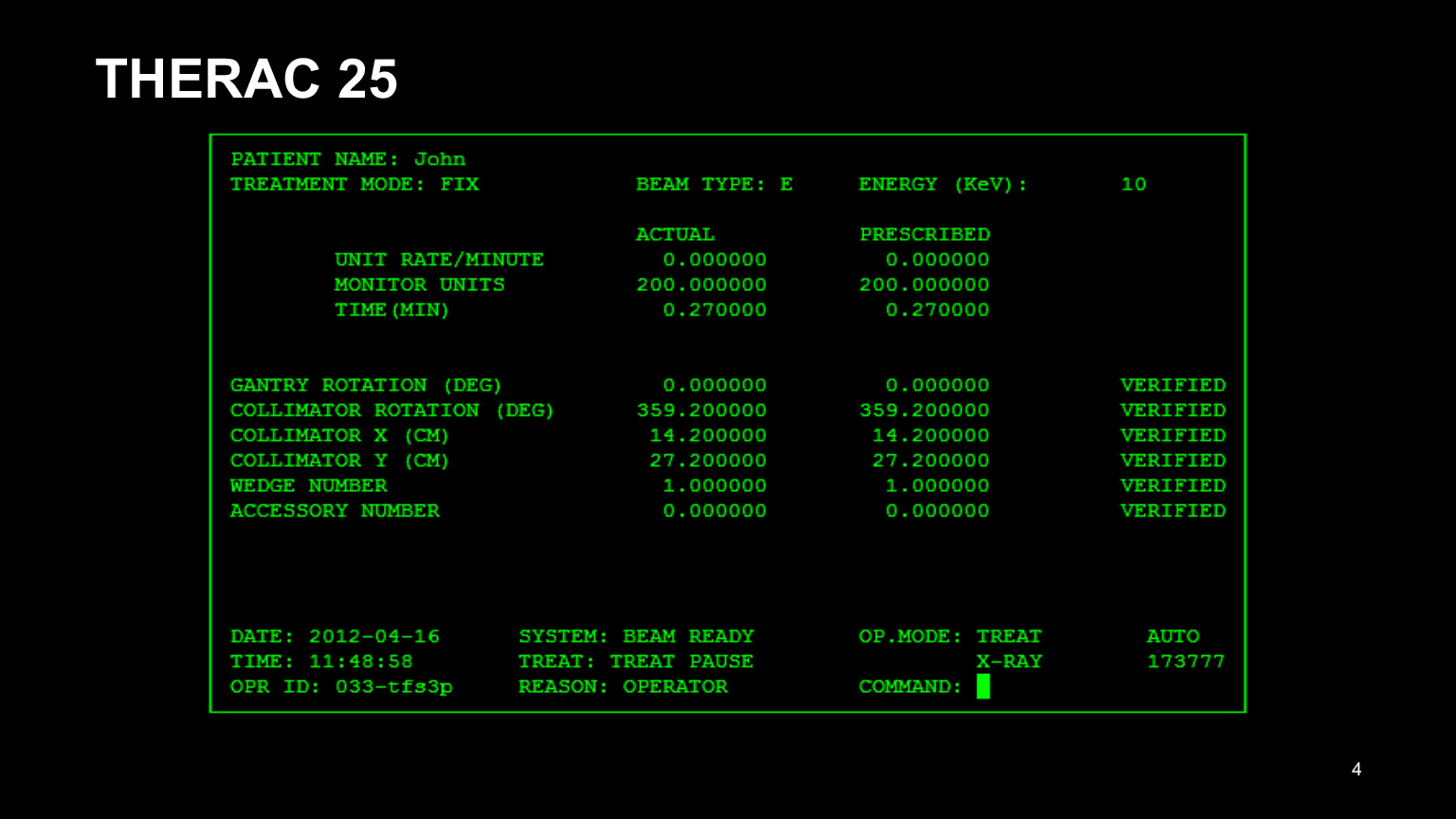
Aquí está la interfaz del programa THERAC 25. Ese era el nombre del dispositivo para la radioterapia de pacientes con cáncer, y todo salió muy mal con él. Primero que nada, tenía una mala interfaz. Mirándolo, ya se puede entender que no es muy bueno: era un inconveniente para los médicos conducir en todas estas cifras. Como resultado, copiaron los datos del registro del paciente anterior e intentaron editar solo lo que era necesario editar.
Está claro que se olvidaron de corregir la mitad y se equivocaron. Como resultado, los pacientes fueron tratados incorrectamente. También vale la pena probar la interfaz de usuario, nunca hay demasiadas pruebas.
Pero además de la mala interfaz, hubo muchos más problemas en el backend. He identificado dos que me parecieron los más atroces:
- . , . , . , .
- C . THERAC , — , . . , , , - , - — .
Valdría la pena escribir pruebas. Porque terminó con cinco muertes registradas, y no está claro cuántas personas más han sufrido por recibir demasiados medicamentos.

Hay otro ejemplo de que, en algunas situaciones, escribir pruebas puede ahorrarle mucho dinero. Este es el Mars Climate Orbiter, un dispositivo que se suponía que debía medir la atmósfera en la atmósfera de Marte, ver cómo era el clima.
Pero el módulo, que estaba en el suelo, dio órdenes en el sistema SI, en el sistema métrico. Y el módulo en la órbita de Marte pensó que era un sistema de medidas británico, lo interpretó incorrectamente.
Como resultado, el módulo entró en la atmósfera en el ángulo incorrecto y colapsó. 125 millones de dólares acaban de irse a la basura, aunque parece que es posible simular la situación en las pruebas y evitarlo. Pero no funcionó.
Ahora hablaré sobre razones más prosaicas por las que debería escribir pruebas. Hablemos de cada elemento por separado:
- Las pruebas aseguran que el código funciona y te calman un poco. En aquellos casos para los que escribió pruebas, puede estar seguro de que el código funciona, si, por supuesto, lo escribió bien. Duerme mejor. Es muy importante.
- . . , , , . , . , .
, - , — , - . , . , , . , , , git blame, , , , . - . , . , . , , . - - , - - . , , , . - .
- , . ? , , , , : , . 500 -, . . .
- : — . , , . , , .
, , , . , , . - . — , . , , . , .
: - . , , . , , , - , .
Ahora me gustaría hablar un poco sobre cuáles son las clasificaciones de tipos de pruebas. Hay muchos de ellos. Solo mencionaré algunos.
El proceso de prueba se divide en pruebas de caja negra, pruebas blancas y grises.
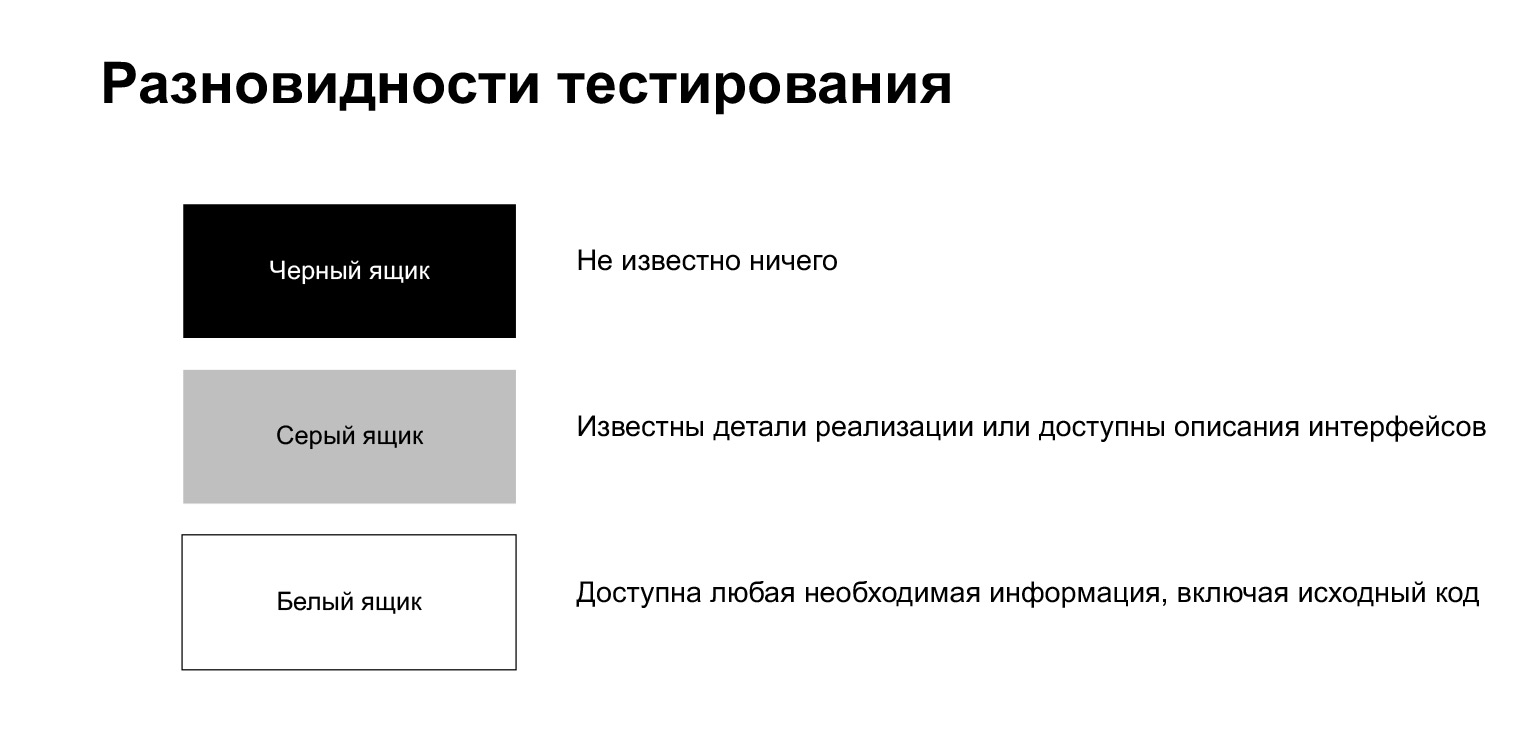
La prueba de caja negra es un proceso en el que el evaluador no sabe nada sobre lo que hay dentro. Él, como un usuario común, hace algo sin conocer los detalles de implementación.
Las pruebas de caja blanca significan que el evaluador tiene acceso a cualquier información que necesite, incluido el código fuente. Estamos en una situación así cuando escribimos una prueba en nuestro propio código.
La prueba de caja gris es algo intermedio. Aquí es cuando conoce algunos detalles de implementación, pero no todo.
Además, el proceso de prueba se puede dividir en manual, semiautomático y automático. La prueba manual la realiza una persona. Digamos que hace clic en los botones del navegador, hace clic en algún lugar, mira para ver qué está roto o no. La prueba semiautomatizada es cuando un evaluador ejecuta scripts de prueba. Podemos decir que estamos en tal situación cuando ejecutamos y ejecutamos nuestras pruebas localmente. Las pruebas automatizadas no implican la participación humana: las pruebas deben ejecutarse automáticamente, no a mano.
Además, las pruebas se pueden dividir por nivel de detalle. Aquí se suelen dividir en pruebas unitarias y de integración. Puede haber discrepancias. Hay personas que llaman pruebas unitarias a cualquier autotest. Pero una división más clásica es algo como esto.
Las pruebas unitarias verifican el funcionamiento de los componentes individuales del sistema y las pruebas de integración verifican el paquete de algunos módulos. A veces también hay pruebas del sistema que verifican el funcionamiento de todo el sistema en su conjunto. Pero parece que esta es más una gran variante de las pruebas de integración.
Las pruebas para nuestro código son pruebas unitarias y de integración. Hay personas que creen que solo se deben escribir pruebas de integración. No soy uno de esos, creo que todo debería ser con moderación, y tanto las pruebas unitarias, cuando estás probando un componente, como las pruebas de integración, cuando estás probando algo grande, son útiles.
¿Por qué creo eso? Porque las pruebas unitarias suelen ser más rápidas. Cuando necesite modificar algo, le molestará mucho haber hecho clic en el botón "ejecutar prueba" y luego esperar tres minutos para que la base de datos se inicie, se realizan las migraciones y sucede algo más. Para tales casos, las pruebas unitarias son útiles. Se pueden ejecutar de forma rápida y cómoda, de uno en uno. Pero cuando haya arreglado las pruebas unitarias, genial, arreglemos las pruebas de integración.
Las pruebas de integración también son algo muy necesario, una gran ventaja es que son más sobre el sistema. Otra gran ventaja: son más resistentes a la refactorización de código. Si es más probable que reescriba alguna función pequeña, es poco probable que cambie la canalización general con la misma frecuencia.

Hay muchas más clasificaciones diferentes. Voy a repasar rápidamente lo que he escrito aquí, pero no me extenderé en detalle, estas son palabras que puedes escuchar en otro lugar.
Las pruebas de humo son pruebas de funcionalidad crítica, las primeras y más simples pruebas. Si se rompen, ya no es necesario realizar la prueba, pero debe ir a repararlos. Digamos que la aplicación se inició, no se bloqueó; genial, pasó la prueba de humo.
Hay pruebas de regresión: pruebas de funcionalidad antigua. Digamos que lanza una nueva versión y debe verificar que no haya nada roto en la anterior. Ésta es la tarea de las pruebas de regresión.
Hay pruebas de compatibilidad, pruebas de instalación. Verifican que todo funcione correctamente para usted en diferentes sistemas operativos y diferentes versiones de sistemas operativos, en diferentes navegadores y diferentes versiones de navegadores.
Las pruebas de aceptación son pruebas de aceptación. Ya hablé de ellos, ellos hablan de si su cambio se puede implementar o no en producción.
También hay pruebas alfa y beta. Ambos conceptos están más relacionados con el producto. Por lo general, cuando tienes una versión más o menos lista de un lanzamiento, pero no todo está arreglado allí, puedes dárselo a personas condicionalmente externas, oa personas externas, voluntarios, para que encuentren errores por ti, los informen y puedas lanzar una muy buena versión. Cuanto menos terminada es la versión alfa, más terminada es la beta. En las pruebas beta, casi todo debería estar bien ahora.
Luego están las pruebas de rendimiento y estrés, las pruebas de carga. Verifican, por ejemplo, cómo su aplicación maneja la carga. Hay algún código. Ha calculado cuántos usuarios, solicitudes tendrá, qué RPS, cuántas solicitudes llegarán por segundo. Simulamos esta situación, la lanzamos, miramos, se sostiene, no se sostiene. Si no es así, piense qué hacer a continuación. Quizás para optimizar el código o aumentar la cantidad de hardware, existen diferentes soluciones.
Las pruebas de esfuerzo son casi iguales, solo que la carga es más alta de lo esperado. Si las pruebas de rendimiento dan el nivel de carga que espera, entonces en las pruebas de estrés puede aumentar la carga hasta que se rompa.
Los linters están un poco separados aquí. Te hablaré sobre linters un poco más tarde, estas son pruebas de formato de código, una guía de estilo. En Python, tenemos la suerte de tener PEP8, una guía de estilo sencilla que todos deberían seguir. Y cuando escribe algo, normalmente le resulta difícil seguir el código. Suponga que olvidó poner una línea vacía, hizo una línea adicional o dejó una línea demasiado larga. Se interpone porque te acostumbras al hecho de que tu código está escrito con el mismo estilo. Linters le permite capturar automáticamente tales cosas.
Con la teoría, todo, luego hablaré de lo que hay en Python.

Aquí hay una lista de algunas de las bibliotecas. No entraré en detalles sobre todos ellos, pero sí sobre la mayoría. Por supuesto, hablaremos de unittest y pytest. Estas son bibliotecas que se utilizan directamente para escribir pruebas. Mock es una biblioteca auxiliar para crear objetos simulados. También hablaremos de ella. doctest es un módulo para probar la documentación, flake8 es un linter, también los veremos. No hablaré de pylama y tox. Si está interesado, puede comprobarlo usted mismo. Pylama es también linter, incluso metalinter, combina varios paquetes, muy conveniente y bueno. Y la biblioteca tox es necesaria si necesita probar su código en diferentes entornos, por ejemplo, con diferentes versiones de Python o con diferentes versiones de bibliotecas. Tox ayuda mucho en este sentido.
Pero antes de hablar de distintas bibliotecas, empezaré por la banalidad. Siéntase libre de usar assert en su código. No es una pena. A menudo es útil comprender lo que está sucediendo.

Suponga que hay una función que calcula estadísticas ordinales, se le escriben dos afirmaciones. Assert debe escribirse en una función en los casos en los que es una tontería extrema que no debe estar en el código. Estos son casos muy extremos, lo más probable es que ni siquiera los encuentre en producción. Es decir, si se equivoca en el código, lo más probable es que falle en sus pruebas.
Assert ayuda cuando está creando prototipos, aún no tiene código de producción, puede pegar assert en todas partes: en la función llamada, en cualquier lugar. Esto no es bueno para proyectos serios, pero bastante bueno en la etapa de creación de prototipos.
Supongamos que desea deshabilitar la aserción por alguna razón; por ejemplo, desea que nunca se active en producción. Python tiene una opción especial para esto.

Te diré qué es doctest. Este es un módulo, una biblioteca estándar de Python para probar la documentación. ¿Por qué es bueno? La documentación que está escrita en código tiende a romperse con mucha frecuencia. Aquí hay una función de juguete muy pequeña, puedes ver todo. Pero cuando tiene un código grande, muchos parámetros y ha agregado algo al final, es muy probable que se olvide de corregir las cadenas de documentación. Doctest evita estas cosas. Arregla algo, no actualice aquí, ejecute doctest y se bloqueará. Entonces recuerde exactamente lo que no corrigió, vaya y corrija.
Cómo se ve? Doctest busca estos árboles de Navidad en docstrings, luego los ejecuta y compara lo que se obtiene.

A continuación, se muestra un ejemplo de ejecución de doctest. Lo comenzamos, vemos que tenemos dos pruebas y una de ellas cayó, completamente en el caso. Genial, vimos buena información clara sobre el error.

Enlace de la diapositiva
El doctest tiene algunas directivas útiles que pueden resultar útiles. No hablaré de todos ellos, pero algunos que me parecieron los más comunes, los puse en la diapositiva. La directiva SKIP le permite no ejecutar una prueba en un ejemplo marcado. La directiva IGNORE_EXCEPTION_DETAIL ignora la prueba EXCEPTION. ELLIPSIS le permite escribir puntos suspensivos en lugar de en cualquier lugar de la salida. FAIL_FAST se detiene después de la primera prueba fallida. Todo lo demás se puede leer en la documentación, hay mucho. Será mejor que te muestre con un ejemplo.

Este ejemplo tiene una directiva ELLIPSIS y una directiva IGNORE_EXCEPTION_DETAIL. Verá en la directiva ELLIPSIS estadísticas ordinales K-ésimo, y esperamos que algo venga, comenzando con un nueve y terminando con un nueve. Podría haber cualquier cosa en el medio. Tal prueba no fallará.
A continuación se muestra la directiva IGNORE_EXCEPTION_DETAIL, solo verificará lo que vino en AssertionError. Mira, escribimos bla, bla, bla allí. La prueba pasará, no comparará bla bla bla con el iterable esperado como primer argumento. Solo comparará AssertionError con AssertionError. Estas son cosas útiles que puede utilizar.

Entonces el plan es el siguiente: te contaré sobre unittest, luego sobre pytest. Diré de inmediato que probablemente no conozca las ventajas de unittest, aparte de que es parte de la biblioteca estándar. No veo una situación que me obligue a usar unittest ahora. Pero hay proyectos que lo utilizan, en cualquier caso es útil saber cómo es la sintaxis y para qué sirve.
Otro punto: las pruebas escritas en unittest saben cómo ejecutar pytest desde el primer momento. No le importa. (…)
Unittest se ve así. Hay una clase que comienza con la prueba de palabras. En el interior, una función que comienza con la palabra prueba. La clase de prueba hereda de unittest.TestCase. Debo decir de inmediato que una prueba aquí está escrita correctamente y la otra prueba es incorrecta.
La prueba superior, donde se escribe la aserción normal, fallará, pero tendrá un aspecto extraño. Echemos un vistazo.

Comando de inicio. Puede escribir unittest main en el código mismo, puede llamarlo desde Python.

Ejecutamos esta prueba y vemos que escribió un AssertionError, pero no escribió dónde cayó, a diferencia de la siguiente prueba, que usó self.assertEqual. Está claramente escrito aquí: tres no es igual a dos.

Debe ser reparado, por supuesto. Pero entonces esta salida mágica no fue visible en la pantalla.
Echemos otro vistazo. En el primer caso, escribimos assert, en el segundo, self.assertEqual. Desafortunadamente, esta es la única forma en unittest. Hay funciones especiales: self.assertEqual, self.assertnotEqual y 100.500 funciones más que debe utilizar si desea ver un mensaje de error adecuado.
¿Por qué sucede? Porque assert es una declaración que recibe un bool y posiblemente una cadena, pero en este caso bool. Y ve que tiene verdadero o falso, y no tiene a dónde tomar los lados izquierdo y derecho. Por lo tanto, unittest tiene funciones especiales que mostrarán correctamente los mensajes de error.
En mi opinión, esto no es muy conveniente. Más precisamente, no es conveniente en absoluto, porque estos son algunos métodos especiales que están solo en esta biblioteca. Son diferentes a los que estamos acostumbrados en el lenguaje corriente.

No tienes que recordar esto, hablaremos de pytest más adelante, y espero que escribas en él principalmente. Unittest tiene un zoológico de funciones para usar si desea probar algo y obtener buenos mensajes de error.
A continuación, hablemos sobre cómo escribir accesorios en unittest. Pero para hacer eso, primero necesito decirte qué son los accesorios. Estas son funciones que se llaman antes o después de ejecutar la prueba. Son necesarios si la prueba necesita realizar una configuración especial: cree un archivo temporal después de la prueba, elimine el archivo temporal; crear una base de datos, eliminar una base de datos; crea una base de datos, escribe algo en ella. En general, lo que sea. Veamos cómo se ve en unittest.

Unittest tiene métodos especiales setUp y tearDown para escribir un accesorio. Por qué todavía no están escritos de acuerdo con PEP8 es un gran misterio para mí. (...)
SetUp es lo que se hace antes de la prueba, tearDown es lo que se hace después de la prueba. Me parece que este es un diseño extremadamente inconveniente. ¿Por qué? Porque, en primer lugar, mi mano no se levanta para escribir estos nombres: ya vivo en un mundo donde todavía hay PEP8. En segundo lugar, tiene un archivo temporal, sobre el que no tiene nada en los argumentos de la prueba en sí. ¿De donde vino el? No está muy claro por qué existe y de qué se trata.
Cuando tenemos una clase pequeña que se adhiere a la pantalla, es genial, se puede capturar con una mirada. Y cuando tienes esta hoja enorme, te torturan para buscar qué era y por qué él es así, por qué se comporta así.
Hay otra característica no tan conveniente con accesorios en unittest. Supongamos que tenemos una clase de prueba que necesita un archivo temporal y otra clase de prueba que necesita una base de datos. Excelente. Escribió una clase, configuró, rasgó, creó / eliminó un archivo temporal. Escribimos otra clase, en ella también escribimos setUp, tearDown, creamos / borramos una base de datos en ella.
Pregunta. Hay un tercer grupo de pruebas que necesitan ambos. ¿Qué hacer con todo esto? Veo dos opciones. O tome y copie y pegue el código, pero no es muy conveniente. O cree una nueva clase, herede de las dos anteriores, llame a super. En general, esto también funcionará, pero parece una exageración para las pruebas.

Por lo tanto, quiero que su familiaridad con Unittest se mantenga así, en un nivel teórico. A continuación, hablaremos sobre una forma más conveniente de escribir pruebas, una biblioteca más conveniente, esto es pytest.
Primero, intentaré decirte por qué Pytest es conveniente.

Enlace de la diapositiva
Primer punto: en pytest, las afirmaciones suelen funcionar, a las que está acostumbrado, y dan información de error normal. Segundo: hay buena documentación para pytest, donde se desmontan un montón de ejemplos y se puede ver todo lo que desee, todo lo que no comprenda.
En tercer lugar, las pruebas son solo funciones que comienzan con test_. Es decir, no necesita una clase adicional, solo escribe una función regular, llámala test_ y se ejecutará a través de pytest. Esto es conveniente porque cuanto más fácil es escribir pruebas, es más probable que escriba la prueba en lugar de calificarla.
Pytest tiene un montón de funciones útiles. Puedes escribir pruebas parametrizadas, es conveniente escribir accesorios de diferentes niveles, también hay algunas sutilezas que puedes usar: xfail, raises, skip, y algunas otras. Hay muchos complementos en pytest, además puede escribir el suyo propio.

Veamos un ejemplo. Así es como se ven las pruebas escritas en pytest. El significado es el mismo que en unittest, solo que parece mucho más conciso. La primera prueba es generalmente de dos líneas.

Ejecute el comando python -m pytest. Excelente. Pasaron dos pruebas, todo está bien, podemos ver qué pasaron y en qué tiempo.

Ahora rompamos una prueba y hagamos que tengamos información sobre el error. Imprimir aseveración 3 == 2 y error. Es decir, vemos: a pesar de que escribimos una aserción regular, mostramos correctamente la información sobre el error, aunque antes de eso en unittest dijimos que la aserción lleva un bool a una cadena o bool, por lo que es problemático mostrar información sobre el error.
Uno podría preguntarse por qué funciona todo esto. Porque pytest hizo todo lo posible y limpió la parte fea de la interfaz. Pytest primero analiza su código y aparece como una especie de estructura de árbol, un árbol de sintaxis abstracta. En esta estructura, tiene operadores en los vértices y operandos en las hojas. Assert es un operador. Se encuentra en la parte superior del árbol, y en este momento, antes de darle todo al intérprete, puedes reemplazar esta afirmación con una función interna que hace introspección y entiende lo que hay en tu lado izquierdo y derecho. De hecho, esto ya se envía al intérprete, reemplazando la aserción.
No entraré en detalles, hay un enlace, en él puedes leer cómo lo hicieron. Pero me encanta que todo funcione bajo el capó. el usuario no ve esto. Escribe para afirmar, como está acostumbrado, que la propia biblioteca hace el resto. Ni siquiera tienes que pensar en eso.
Además, en pytest para tipos estándar, tendrá buena información de error de todos modos. Porque pytest sabe cómo mostrar esta información de error. Pero puede comparar tipos de datos personalizados en su prueba, por ejemplo, árboles o algo complejo, y es posible que pytest no sepa cómo mostrar información de error para ellos. Para tales casos, puede agregar un gancho especial (aquí hay una sección en la documentación) y en este gancho escriba cómo debería verse la información de error. Todo es muy flexible y conveniente.

Veamos cómo se ven los accesorios en pytest. Si en unittest es necesario escribir setUp y tearDown, aquí llama a la función habitual como quieras. Escribimos el decorador pytest.fixture en la parte superior; genial, es un accesorio.
Y este no es el ejemplo más simple. El dispositivo puede simplemente hacer una devolución, devolver algo, será análogo a la configuración. En este caso, hará una especie de tearDown, es decir, exactamente aquí, después del final de la prueba, llamará a close y se borrará el archivo temporal.
Parece conveniente. Tienes una función arbitraria que puedes nombrar como quieras. Lo pasas explícitamente a la prueba. Pasado fill_file, ya sabes lo que es. No se requiere nada especial de usted. En general, utilícelo. Esto es mucho más conveniente que unittest.

Un poco más sobre accesorios. En pytest es muy fácil crear accesorios de diferentes ámbitos. Por defecto, el aparato se crea con el nivel de función. Esto significa que se llamará para cada prueba que haya pasado. Es decir, si hay un rendimiento o algo más a la tearDown, esto también sucederá después de cada prueba.
Puede declarar scope = 'module' y luego el dispositivo se ejecutará una vez por módulo. Supongamos que desea crear una base de datos una vez y no desea eliminar y ejecutar todas las migraciones después de cada prueba.
También en los dispositivos es posible especificar el argumento autouse = True, y luego se llamará al dispositivo independientemente de si lo solicitó o no. Parece que esta opción nunca debería usarse, o debería serlo, pero con mucho cuidado, porque es una cosa implícita. Es mejor evitar lo implícito.

Ejecutamos este código, veamos qué sucedió. Hay una prueba que depende del dispositivo, llámame una vez, úsame cuando sea necesario, llámame cada vez. Al mismo tiempo, llámame una vez, usa cuando sea necesario un accesorio de nivel de módulo. Vemos que la primera vez que llamamos a los dispositivos, llámame una vez, usa cuando sea necesario, llámame cada vez, lo que genera esto, pero también se llamó al dispositivo con uso automático porque no le importa, siempre se llama.
La segunda prueba depende de los mismos accesorios. Vemos que la segunda vez que me llamamos una vez no se imprimió el uso cuando se necesitaba, porque está a nivel de módulo, ya se ha llamado una vez y no se volverá a llamar.
Además, en este ejemplo, puede ver que pytest no tiene los problemas de los que hablamos en unittest, cuando en una prueba puede necesitar una base de datos, en otra, un archivo temporal. No está claro cómo agregarlos normalmente. Aquí está la respuesta a esta pregunta en pytest. Si se aprobaron dos accesorios, entonces habrá dos accesorios adentro.
Excelente, muy cómodo, no hay problema. Los accesorios son muy flexibles y pueden depender de otros accesorios. No hay ninguna contradicción en esto, y pytest los llamará en el orden correcto.

De hecho, en el interior puede heredar dispositivos de otros dispositivos, hacer que tengan un alcance diferente y usarlos automáticamente sin usarlos automáticamente. Él mismo los organizará en el orden correcto y los llamará.
Aquí tenemos la primera prueba, una prueba, que depende de rare_dependency_for_test_one, donde este dispositivo depende de otro dispositivo, y uno más. Veamos qué pasa en el escape.
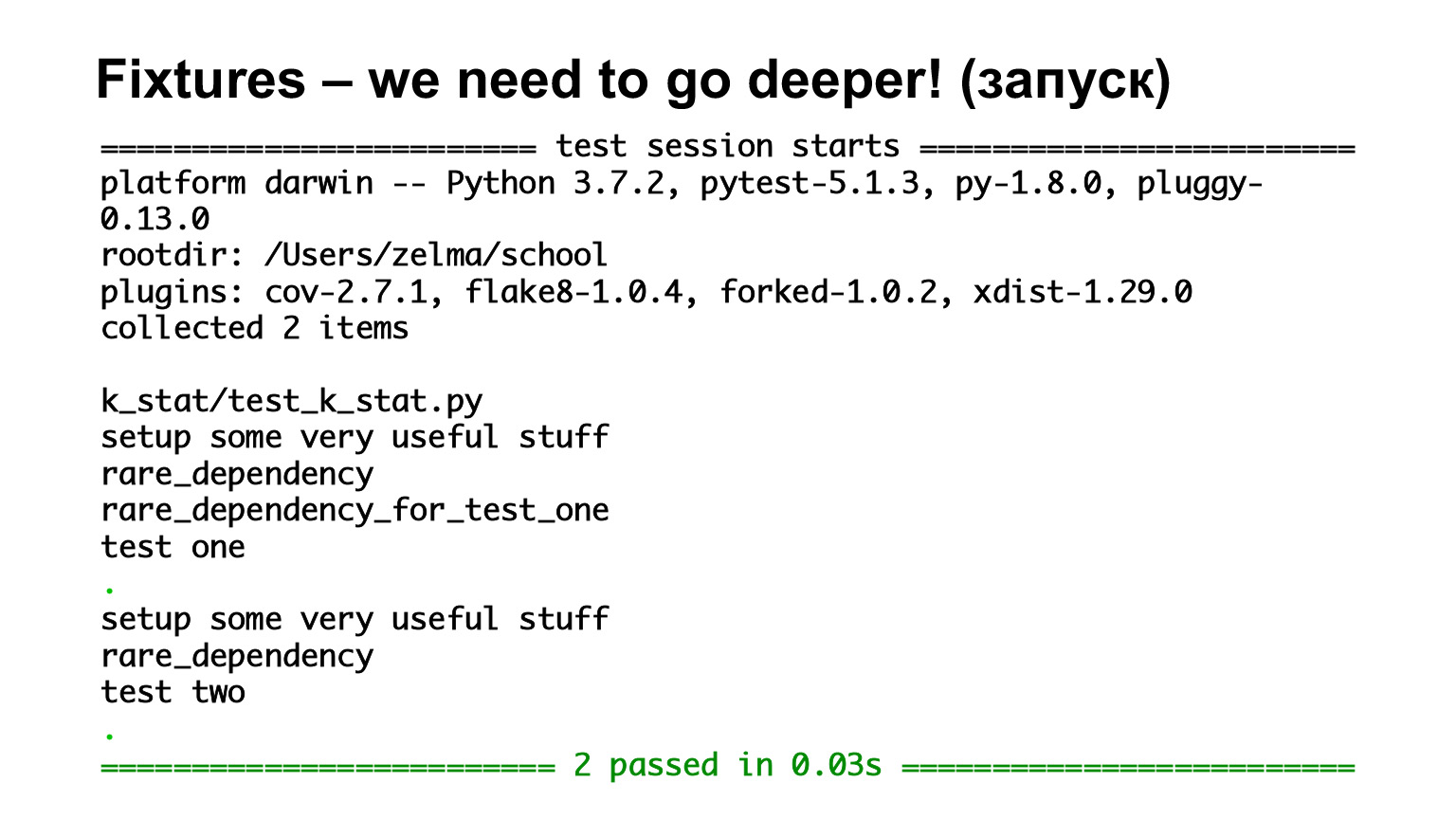
Hemos visto que se llaman por orden de herencia. Hay todos los accesorios de nivel de función, por lo que todos se llaman para cada prueba. La segunda prueba depende de rare_dependency y rare_dependency depende de some_common_dependency. Miramos el escape y vemos que se llamaron dos accesorios antes de la prueba.
Pytest tiene un archivo de configuración especial conftest.py donde puedes poner todos los accesorios, y es bueno si lo pones: por lo general, cuando una persona mira el código de otra persona, por lo general va a ver los accesorios en concurso.
No es obligatorio. Si hay un accesorio que solo necesita en este archivo, y sabe con certeza que es específico, de aplicación limitada y que no lo necesitará en otro archivo, puede declararlo en el archivo. O cree mucho concurso y todos funcionarán en diferentes niveles.

Hablemos de las características que se encuentran en pytest. Como dije, es muy fácil parametrizar las pruebas. Aquí vemos una prueba que tiene tres conjuntos de parámetros: dos de entrada y uno esperado. Los pasamos a los argumentos de la función y vemos si lo que pasamos a la entrada coincide con lo esperado.

Veamos cómo queda. Vemos que hay tres pruebas aquí. Es decir, pytest cree que se trata de tres pruebas. Pasaron dos, se cayó uno. ¿Qué hay de bueno aquí? Para la prueba que cayó, vemos los argumentos, vemos en qué conjunto de parámetros cayó.
Nuevamente, cuando tiene una función pequeña y parametrizar dice tres, puede ver con sus ojos qué cayó exactamente. Pero cuando hay muchos conjuntos en los parámetros, no lo verá con sus ojos. Más bien, verás, pero te resultará muy difícil. Y es muy conveniente que pytest muestre todo de esta manera: puede ver inmediatamente en qué caso falló la prueba.

Parametrizar es algo bueno. Y cuando haya escrito una prueba una vez y luego haya realizado muchos, muchos conjuntos de parámetros, esta es una buena práctica. No cree muchas variantes de código para pruebas similares, escriba una prueba una vez, luego cree un gran conjunto de parámetros y funcionará.
Hay muchas más cosas útiles en pytest. Si habla de ellos, la conferencia claramente no es suficiente, por lo que mostraré, nuevamente, solo algunos. La primera prueba usa pytest.raises () para mostrar que está esperando una excepción. Es decir, en este caso, si se genera un AssertionError, la prueba pasará. Debería lanzar una excepción.
La segunda cosa útil es xfail. Es un decorador que permite que la prueba falle. Digamos que tienes muchas pruebas, mucho código. Refactorizó algo, la prueba comenzó a fallar. Al mismo tiempo, comprende que no es crítico o será muy costoso repararlo. Y tú eres así: está bien, le colgaré un decorador, se pondrá verde, lo arreglaré más tarde. O supongamos que la prueba comienza a inundar. Está claro que este es un acuerdo con la propia conciencia, pero a veces es necesario. Además, xfail en esta forma será verde independientemente de si la prueba ha caído o no. Aún puede pasarlo al parámetro Strict = True, entonces será una situación ligeramente diferente, pytest esperará a que la prueba falle. Si la prueba pasa, se devolverá un mensaje de error y viceversa.
Otra cosa útil es skipif. Solo hay un salto que no ejecutará pruebas. Y hay skipif. Si coloca el cursor sobre este decorador, la prueba no se ejecutará en determinadas condiciones.
En este caso, está escrito que si tengo una plataforma Mac, entonces no arranque, porque la prueba por alguna razón cae. Sucede. Pero, en general, hay pruebas específicas de la plataforma que siempre fallarán en una plataforma específica. Entonces es útil.

Vamos a ponerlo en marcha. Vimos la letra X, vimos S. X tenemos se refiere a xfail, S - a skipif. Es decir, pytest muestra qué prueba nos perdimos por completo y cuál ejecutamos, pero no miramos el resultado.

Hay muchas opciones útiles diferentes en pytest. Yo, por supuesto, no podré mostrarlos aquí, puedes ver la documentación. Pero te hablaré de algunos.
Aquí hay una opción útil: solo recolectar. Muestra una lista de pruebas encontradas. Hay una opción -k - que filtra por nombre de prueba. Esta es una de mis opciones favoritas: si una prueba falla, especialmente si es compleja y aún no sabes cómo solucionarla, fíltrala y ejecútala.
Desea ahorrar tiempo y probablemente no sea divertido ejecutar otras 15 pruebas; sabe que pasan o no, pero aún no las ha realizado. Ejecute la prueba que falla, corríjala y continúe.
También hay una muy buena opción -s, habilita la salida de stdout y stderr en las pruebas. De forma predeterminada, pytest solo generará stdout y stderr para las pruebas fallidas. Pero hay ocasiones, generalmente en la etapa de depuración, en las que desea generar algo en la prueba y no sabe si la prueba fallará. Puede que no se caiga, pero desea ver en la prueba en sí lo que llega y sale. Luego ejecute -s y debería ver lo que quiere.
-v es la opción verbosa estándar, aumenta la verbosidad.
--lf, --last-failed es una opción que le permite reiniciar solo aquellas pruebas que fallaron en la última ejecución. --sw, --stepwise también son funciones útiles como -k. Si repara las pruebas secuencialmente, entonces ejecuta con --stepwise, pasa por las verdes, y tan pronto como ve la prueba fallida, se detiene. Y cuando ejecuta --sw de nuevo, comienza con esta prueba que falló. Si vuelve a caer, se detendrá de nuevo; si no cae, seguirá hasta el próximo otoño.

Enlace de la diapositiva
En pytest hay un archivo de configuración principal pytest.ini. En él, puede cambiar el comportamiento predeterminado de pytest. He dado aquí las opciones que se encuentran muy a menudo en el archivo de configuración.
Las rutas de prueba son las rutas que pytest buscará para las pruebas. addopts es lo que se agrega a la línea de comando al inicio. Aquí he agregado flake8 y complementos de cobertura a addopts. Los veremos un poco más tarde.

Enlace de la diapositiva
Hay muchos complementos diferentes en pytest. Escribí los que, nuevamente, se usan en todas partes. flake8 es un linter, la cobertura es la cobertura del código mediante pruebas. Luego, hay un conjunto completo de complementos que facilitan el trabajo con ciertos marcos: pytest-flask, pytest-django, pytest-twisted, pytest-tornado. Probablemente haya algo más.
El complemento xdist se utiliza si desea ejecutar pruebas en paralelo. El complemento de tiempo de espera le permite limitar el tiempo de ejecución de la prueba: es útil. Cuelga un decorador de tiempo de espera en la prueba y, si la prueba tarda más, falla.

Echemos un vistazo. Agregué cobertura y flake8 a pytest.ini. Coverage me dio un informe, tengo un archivo con pruebas allí, algo de él no llamó, pero está bien :)
Aquí está el archivo k_stat.py, contiene hasta cinco declaraciones. Esto es aproximadamente lo mismo que cinco líneas de código. Y la cobertura es del 100%, pero eso es porque mi archivo es muy pequeño.
De hecho, la cobertura no suele ser del cien por cien y, además, no se debe conseguir por todos los medios. Subjetivamente, parece que una cobertura de prueba del 60-70% es suficiente y normal para el trabajo.
La cobertura es una métrica tal que, incluso siendo cien por ciento, no dice que seas genial. El hecho de que haya llamado a este código no significa que haya verificado algo. También puede escribir afirmar True al final. Debe abordar la cobertura de manera razonable, para una cobertura de prueba del 100% hay desvanecimientos y robots, pero la gente no necesita hacer eso.
En pytest.ini he conectado un complemento más. Aquí puede ver --flake8, este es el linter que muestra mis errores de estilo, y algunos otros, no de PEP8, sino de pyflakes.

Aquí en el escape está escrito el número de error en PEP8 o en pyflakes. En general, todo está claro. La línea es demasiado larga, para la redefinición necesita dos líneas en blanco, necesita una línea en blanco al final del archivo. Al final dice que CitizenImport no se usa para mí. En general, los linters le permiten detectar errores graves y errores en el diseño del código.

Ya hemos hablado sobre el complemento de tiempo de espera, que le permite limitar el tiempo de ejecución de la prueba. Para algunas pruebas, el tiempo de ejecución es importante. Y puede limitarlo dentro de las pruebas con time.time y timeit. O usando el complemento de tiempo de espera, que también es muy conveniente. Si la prueba funciona demasiado, se puede perfilar de diferentes maneras, por ejemplo cProfile, pero Yura hablará de esto en su conferencia .
Si usa un IDE, y vale la pena usar herramientas auxiliares, aquí tengo, en particular, PyCharm, entonces las pruebas son muy fáciles de ejecutar directamente desde él.

Queda por hablar de simulacro. Digamos que tenemos el módulo A, queremos probarlo y hay otros módulos que no queremos probar. Uno de ellos va a la red, el otro a la base de datos, y el tercero es un módulo sencillo que no nos molesta de ninguna manera. En tales casos, el simulacro nos ayudará. Nuevamente, si estamos escribiendo una prueba de integración, lo más probable es que generemos una base de datos de prueba, escribiremos un cliente de prueba, y eso también está bien. Es solo una prueba de integración.
Hay ocasiones en las que queremos hacer una prueba unitaria cuando solo queremos probar una pieza. Entonces necesitamos una burla.

Mock es una colección de objetos que se pueden usar para reemplazar el objeto real. En cualquier llamada a métodos, a atributos, también devuelve mock.

En este ejemplo, tenemos un módulo simple. Lo dejaremos y reemplazaremos algunos más complejos con simulacros. Ahora veremos cómo funciona.

Aquí se muestra claramente. Lo importamos, decimos que m es un simulacro. Llamado simulacro. Dijeron que m tiene un método f. Llamado, simulacro regresó. Dijeron que m es el atributo is_alive. Genial, ha vuelto otro simulacro. Y vemos que myf se llaman una vez. Es decir, es un objeto tan complicado, dentro del cual se reescribe el método getattr.

Echemos un vistazo a un ejemplo más claro. Digamos que hay un AliveChecker. Utiliza algún tipo de http_session, necesita un objetivo y tiene una función do_check que devuelve Verdadero o falso, dependiendo de lo que haya recibido: 200 o no 200. Este es un ejemplo ligeramente artificial. Pero suponga que dentro de do_check puede terminar una lógica compleja.
Digamos que no queremos probar nada sobre la sesión, no queremos saber nada sobre el método get. Solo queremos probar do_check. Genial, probémoslo.

Puedes hacerlo así. Mock http_session, aquí se llama pseudo_client. Nos burlamos del método get de ella, decimos que get es un simulacro que devuelve 200. Lanzamos, creamos un AliveChecker a partir de esto, lo lanzamos. Esta prueba funcionará.
Además, verifiquemos que se haya llamado a get una vez y con exactamente los mismos argumentos que los escritos. Es decir, llamamos a do_check sin saber nada sobre qué sesión era ni cuáles eran sus métodos. Simplemente los congelamos. Lo único que sabemos es que devolvió 200.

Otro ejemplo. Es muy similar al anterior. Lo único aquí es side_effect en lugar de return_value. Pero eso es algo que hace la simulación. En este caso, lanza una excepción. La línea de aserción se ha cambiado para afirmar no AliveChecker.do_check (). Es decir, vemos que el cheque no pasa.
Estos son dos ejemplos de cómo probar la función do_check sin saber nada sobre lo que entró en ella desde arriba, lo que entró en esta clase.
El ejemplo, por supuesto, parece artificial: no está del todo claro por qué cheque, 200 o no 200, solo hay un mínimo de lógica. Pero imaginemos hacer algo complicado según el código de retorno. Y luego, tal prueba comienza a parecer mucho más significativa. Vimos que viene 200, y luego comprobamos la lógica de procesamiento. Si no 200, lo mismo.

También puede parchear bibliotecas usando mock. Digamos que ya tiene una biblioteca y necesita cambiar algo en ella. Aquí hay un ejemplo, hemos parcheado el seno. Ahora siempre devuelve un deuce. Excelente.
También vemos que m se ha llamado dos veces. Mock, por supuesto, no sabe nada sobre las API internas de los métodos que se burlan y, en general, no está obligado a coincidir con ellos. Pero el simulacro le permite verificar lo que llamó, cuántas veces y con qué argumentos. En este sentido, ayuda a probar el código.

Quiero advertirle sobre un caso en el que hay un módulo y una gran simulación. Por favor, acérquese a todo de manera razonable. Si tienes cosas sencillas, no las mojes. Cuanto más simulacros tenga en su prueba, más se alejará de la realidad: es posible que su API no coincida y, en general, esto no es exactamente lo que está probando. No necesitas remojar todo sin necesidad. Aborde el proceso de manera inteligente.

Nos queda la última pequeña parte sobre la integración continua. Cuando está desarrollando un proyecto favorito solo, puede ejecutar pruebas localmente, y no es gran cosa, funcionarán.
Tan pronto como el proyecto crece y hay más de un desarrollador en él, deja de funcionar. Primero, la mitad no ejecutará pruebas localmente. En segundo lugar, los ejecutarán en sus versiones. Habrá conflictos en alguna parte, todo se estropeará constantemente.
Para eso, existe la Integración Continua, una práctica de desarrollo que implica inyectar rápidamente candidatos a la corriente principal. Pero al mismo tiempo, deben pasar por algún tipo de autoensamblaje o pruebas automáticas en un sistema especial. Tiene el código en el repositorio, las confirmaciones que desea fusionar en la rama principal de su proyecto. En estas confirmaciones, las pruebas se pasan en un sistema especial. Si las pruebas son verdes, entonces la confirmación se agrega por sí sola o tienes la oportunidad de agregarla.
Tal esquema, por supuesto, tiene sus inconvenientes, así como todo. Como mínimo, necesita hardware adicional, no el hecho de que CI será gratuito. Pero en cualquier empresa más o menos grande, y tampoco en una grande, no se puede ir a ningún lado sin CI.
Como ejemplo, una captura de pantalla de TeamCity, uno de los CI. Hay un montaje, se completó con éxito. Hubo muchos cambios en él, se lanzó en tal o cual agente en tal o cual momento. Este es un ejemplo de cuando todo está bien y se puede infundir.
Hay muchos sistemas de CI diferentes. Escribí una lista, si está interesado, eche un vistazo: AppVeyor, Jenkins, Travis, CircleCI, GoCD, Buildbot. Gracias.
Otras conferencias del curso de video sobre Python se encuentran en una publicación sobre Habré .