Parte 1. Comienzo
1.1 Introducción y planteamiento del problema
En MTS controlamos de forma centralizada la calidad de las redes de transmisión de datos o, más simplemente, la red de transporte (que no debe confundirse con la red de transporte logístico), en lo sucesivo TS. Y, en el marco de nuestra actividad, tenemos que resolver constantemente dos tareas principales:
- Se ha detectado degradación de los servicios del cliente (en relación con el TS); es necesario determinar la ruta de su conexión a través del TS y averiguar si el motivo de la degradación de los servicios es parte del TS. Además, lo llamaremos el problema directo.
- Se detecta una degradación de la calidad del canal de transporte o de la secuencia de canales; es necesario determinar qué servicios dependen de este canal / canales para determinar el impacto. Además, llamaremos a esto el problema inverso.
Los servicios TS se entienden como cualquier conexión de los equipos del cliente. Estos pueden ser estaciones base (BS), clientes B2B (que utilizan MTS TS para organizar el acceso a Internet y / o redes VPN superpuestas), clientes de acceso fijo (el llamado acceso de banda ancha), etc. etc.
Tenemos a nuestra disposición dos sistemas de información centralizados:
| Sistema de monitoreo de desempeño | Parámetros de red y datos de topología |
|---|---|
 |
 |
| Métricas, KPI TS | Parámetros de configuración, canales L2 / L3 |
Cualquier red de transporte es inherentemente un grafo dirigido en el que cada borde tiene un ancho de banda no negativo. Por tanto, desde el principio, la búsqueda de soluciones a estos problemas se llevó a cabo en el marco de la teoría de grafos.
En primer lugar, el problema de comparar los indicadores de calidad del TS y los servicios con la topología del TS se resolvió combinando y presentando literalmente la topología y los datos de calidad en forma de gráfico de red.
La vista del gráfico formado de acuerdo con la topología y los datos de rendimiento se implementó utilizando el software Gephi de código abierto . Esto permitió solucionar el problema de la representación automática de la topología, sin trabajo manual en su actualización. Se parece a esto:
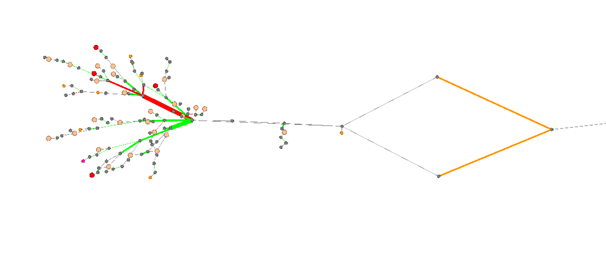
Aquí, los nodos son, de hecho, los nodos del TS (enrutadores, conmutadores) y los básicos, los bordes son los canales del TS. La codificación de colores, respectivamente, denota la presencia de degradaciones de la calidad y el estado de tratamiento de estas degradaciones.
Parecería que está bastante claro y se puede trabajar, pero:
- El problema directo (desde el servicio hasta la ruta del servicio) se puede resolver con bastante precisión solo siempre que la topología TS en sí sea bastante simple: un árbol o simplemente una conexión en serie, sin anillos ni rutas alternativas.
- El problema inverso se puede resolver bajo una condición similar, pero al mismo tiempo, a nivel de agregación y el núcleo de la red, es imposible resolver este problema en principio, ya que estos segmentos se rigen por protocolos de enrutamiento dinámico y tienen muchas rutas alternativas potenciales.
Además, tenga en cuenta que, en general, la topología de la red es mucho más complicada (el fragmento anterior está encerrado en un círculo rojo):

Y este no es el segmento más pequeño, hay mucho más y más complejo en topología:

Entonces, esta opción era adecuada para el análisis meditativo de casos individuales, pero de ninguna manera para un trabajo simplificado y, además, no para automatizar la solución de directo e inverso.
Parte 2. Automatización v1.0
Déjame recordarte qué tareas resolvimos:
- Determinación del recorrido del servicio a través del vehículo - Tarea directa.
- Determinación de servicios dependientes del canal TC - Problema inverso.
2.1. Servicios de transporte para estaciones base (BS)
Generalmente, la organización del transporte desde el nodo central (controlador / puerta de enlace) a la BS se ve así:

Sobre los segmentos de agregación y el núcleo del TS, las conexiones se realizan a través de los servicios de transporte de la red MPLS: L2 / L3 VPN, VLL. En los segmentos de acceso, las conexiones se realizan, por regla general, a través de VLAN dedicadas.
Permítanme recordarles que tenemos una base de datos donde se encuentran todos los parámetros reales (dentro de un período determinado) y la topología del vehículo.
2.2. Solución de segmento de marcación (acceso)
Tomamos datos sobre la VLAN de la interfaz lógica BS, y paso a paso "vamos" por los enlaces, cuyos puertos contienen esta ID de Vlan, hasta llegar al enrutador de borde (MBN).

Para resolver un enunciado de problema tan simple, terminé teniendo que:
- Escriba un algoritmo para el seguimiento paso a paso de la "propagación" de VlanID desde BS a través de los canales de la red de agregación.
- Considere las lagunas de datos existentes. Esto fue especialmente cierto para las articulaciones entre los nodos en los sitios.
- De hecho, escriba un algoritmo SPF para eliminar las ramas sin salida al final que no conducen al enrutador MVN.
El algoritmo surgió de un proceso principal y siete subprocesos. Se necesitaron de 3 a 4 semanas de tiempo de trabajo puro para implementarlo y depurarlo.
Además, tuvimos un placer especial ...
2.2.1. SQL JOIN
En virtud de su estructura, el modelo relacional para atravesar el gráfico requiere un enfoque recursivo explícito con operaciones de unión en cada nivel, mientras atraviesa repetidamente el mismo conjunto de registros. Esto, a su vez, implica una degradación del rendimiento del sistema, especialmente en grandes conjuntos de datos.
Por razones obvias, no puedo citar el contenido de las consultas a la base de datos aquí, pero evaluar: cada "repisa" en el texto de la consulta es la conexión de la siguiente tabla, que es necesaria para, en este caso, obtener una correspondencia unificada entre Port y VlanID:

Y esta solicitud es para obtener, de forma unificada, conexiones cruzadas VlanID dentro del switch:

Teniendo en cuenta que la cantidad de puertos era de varias decenas de miles, y la VLAN era 10 veces más, todo esto era muy reacio a dar vueltas y vueltas. Y esas solicitudes debían realizarse para cada nodo y VlanID. Y "descargar todo de una vez y calcular" es imposible, ya que es un cálculo secuencial de la ruta c con operaciones paso a paso que dependen de los resultados del paso anterior.
2.3. Determinación de la ruta del servicio en segmentos enrutados
Aquí comenzamos con un proveedor de MVN cuyo sistema de gestión proporcionaba datos sobre los LSP actuales y en espera en el segmento MPLS. Conociendo la interfaz de Access que estaba conectada al acceso (L2 Vlan), fue posible encontrar el LSP y luego, a través de una serie de solicitudes al sistema NBI, obtener la ruta LSP, que consta de enrutadores y enlaces entre ellos.

- Al igual que en el segmento conmutado, la descripción de la descarga de la ruta LSP del servicio MPLS resultó en un algoritmo con 17 subrutinas.
- La solución funcionó solo en los segmentos atendidos por este proveedor
- Era necesario resolver la definición de uniones entre servicios MPLS (por ejemplo, en el centro del segmento había un servicio VPLS general, y EPIPE o L3VPN divergían de él)
Trabajamos en el problema para otros proveedores de MVN, donde no había sistemas de control o, en principio, no proporcionaban datos sobre el pasaje LSP actual. Encontramos una solución para varios, pero el número de LSP que pasan a través del enrutador ya no es el número de VanID, que está registrado en el conmutador. Retrasar tal volumen de datos "bajo demanda" (después de todo, necesitamos información operativa) - existe el riesgo de dejar de funcionar el hardware.
Además, surgieron preguntas adicionales:
- – , , . .. – MPLS .
- , LSP, . . .
2.4. .
Los datos recibidos sobre las rutas de conexión de los servicios deben anotarse en algún lugar, para que luego podamos referirnos a ellos a la hora de resolver nuestros problemas Directos e Inversos.
La opción de almacenar en una base de datos relacional se descartó inmediatamente: ¿es tan difícil agregar datos de muchas fuentes para luego poder clasificarlos en los siguientes conjuntos de tablas? Este no es nuestro método. Además, recuerde las uniones de varios pisos y su rendimiento.
Los datos deben contener información sobre la estructura del servicio y las dependencias de sus componentes: enlaces, nodos, puertos, etc.
Como solución de prueba, se eligió el formato XML y Native-XML DB - Exist.
Como resultado, cada servicio se registró en la base de datos en el formato (los detalles se omiten en aras de la compacidad):
<services>
<service>
<id>,<description> (, )
<source>
<target> Z
<<segment>> L2/L3
<topology> (, /, )
<<joints>> (, /, )
</service>
</services>La consulta de datos para problemas directos e inversos se realizó utilizando el protocolo XPath:

Todos. Ahora el sistema está funcionando: para una solicitud con el nombre de la BS, se devuelve la topología de su conexión a través de la red de transporte, para una solicitud con el nombre del nodo y el puerto del TS, se devuelve una lista de BS que dependen de ella para la conexión. Por tanto, sacamos las siguientes conclusiones ...
2.5.

En lugar de seguir los hallazgos de la Parte 2
2.5.1. Para el segmento conmutado (redes en conmutadores Ethernet L2)
- Se requieren datos completos sobre topología y correspondencia Port-VlanID. Si no hay datos VlanID en algún enlace, el algoritmo se detiene, no se encontró la ruta
- Consultas improductivas multinivel contra una base de datos relacional. Cuando aparece un nuevo proveedor con sus propios detalles, parámetros: agregar solicitudes en todas las etapas del trabajo
2.5.2. Para un segmento enrutado
- Limitado por las capacidades de MVN SU para proporcionar datos sobre la topología de los servicios LSP MPLS.
- – , .. LSP .
- LSP – ( , “” ).
2.5.3.
- , , , , ( – , ), , – .
- . 3-4 .
- , .. , MPLS .
- – , .
2.6. -
- , , .. – .
- , -
- (, VlanID)
Después de evaluar las posibles opciones para la implementación de nuestros deseos, decidimos la clase de sistemas que proporcionarían todo esto "fuera de la caja" - este es el llamado. bases de datos de gráficos.
Aunque la última frase se lee como algo lineal y simple, dado que anteriormente ninguno de nosotros (y nuestros especialistas en TI, como resultó, tampoco) habíamos encontrado una clase de base de datos de este tipo, tomaron la decisión un tanto por accidente: se mencionaron bases de datos similares (pero no entendió) en el curso de descripción general de Big Data. En particular, mencionó el producto Neo4j... No solo, a juzgar por la descripción, cumplió todos nuestros requisitos, sino que también tiene una versión comunitaria funcional completamente gratuita. Aquellos. - no es una prueba de 30 días, no corta la funcionalidad principal, sino un producto completamente funcional que puede estudiar lentamente. No fue el último (si no el principal) papel en la elección el amplio apoyo de los algoritmos de gráficos .
Parte 3. Un ejemplo de la implementación del problema directo en Neo4j
Para no alargar la narrativa lineal sobre cómo se implementa el modelo TS en la base de datos de gráficos de Neo4j, mostraremos inmediatamente el resultado final con un ejemplo.
3.1. Seguimiento de la ruta de la interfaz Iub para 3G BS

La ruta de conexión del servicio pasa por dos segmentos: un MVN enrutado y una línea de relevo de radio conmutada (las estaciones de relevo de radio funcionan como conmutadores Ethernet). La ruta a través del segmento RRL se determina de la misma manera que se describe en la Parte 2: mediante el paso de la interfaz BS VlanID a lo largo del segmento RRL hasta el enrutador de borde MVN. El segmento MVN conecta el enrutador de borde (con el segmento RRL), con el enrutador al que está conectado el controlador BS (RNC).
Inicialmente, a partir del parámetro Iub, sabemos exactamente qué MVN es la puerta de enlace para la BS (MVN límite) y qué controlador es servido por la BS.
Con base en estas condiciones iniciales, crearemos 2 consultas a la base de datos para cada uno de los segmentos. Todas las consultas a la base de datos se crean en lenguaje cifrado.... Para no distraerse con su descripción ahora, piense en él simplemente como "SQL para gráficos".
3.1.1. Segmento RRL. Ruta de VlanID
Solicitud de cifrado para rastrear la ruta del servicio según los datos de topología VlanID y L2 disponibles:
| Fragmento de una consulta cifrada
(CON construcción: pasar los resultados de una etapa de la consulta a la siguiente (canalización del procesamiento)) |
Resultados de consultas intermedias (representación visual en la consola de Neo4j - " Navegador de Neo4j ") |
|---|---|
Recepción de nodos BS y MVN entre los que se buscará la ruta del servicio Iub
|
 |
Recepción de nodos Vlan de interfaz BS Iub
|
 |
Seleccionamos los nodos del vehículo en el mismo sitio con el BS, en cuyos puertos está registrado VlanID Iub BS
|
 |
utilizando el algoritmo de Dijkstra, encontramos el camino más corto desde el VlanID del TS del sitio de la BS hasta el límite MVN
|
 |
De la cadena Vlan, obtenemos una lista de nodos, puertos y conexiones entre puertos, que, al final, será la forma de conectar el servicio Iub desde la BS al enrutador de borde.
Resultado: |
|
 |
|
Como puede ver, se ha obtenido la ruta, incluso a pesar de una falta parcial de datos. En este caso, no hay información sobre la unión del puerto BS con el puerto de la estación de retransmisión de radio.
3.1.2. Segmento RRL. Ruta de topología L2
Digamos que se hace un intento en la cláusula 3.1.1. falló debido a la ausencia total o parcial de datos en el parámetro VlanID. En otras palabras, dicha cadena continua que llega al nodo MVN no está construida:
Luego, puede intentar definir la conexión de servicio como la ruta más corta al MVN de acuerdo con la topología L2:
Resultado: |
 |
Como puede ver, se obtiene el mismo resultado. Aquí, la falta de información sobre la unión de las BS con las RRS se compensa pasando la conexión por el objeto (nodo) del sitio donde se ubican. Por supuesto, la precisión de este método será menor, porque en general, Vlan puede no registrarse a lo largo de la ruta más corta asumida por el algoritmo de Dijkstra. Pero la solicitud consta de solo dos operaciones.
3.1.3 Segmento MVN. Seguimiento de la ruta desde el MVN límite hasta el controlador
Aquí también usamos el algoritmo de Dijkstra.
Un camino con un costo mínimo
|
 |
2 rutas principales con costo mínimo (principal + alternativa)
|
 |
Top 3 rutas con costo mínimo (principal + dos alternativas)
|
 |
Asimismo, en este caso, no existe información sobre las articulaciones directas del MVN con el RNC. Pero esto no le impide crear una ruta de servicio, incluso si el algoritmo la asume (más sobre esto más adelante).
3.2. Costes laborales
La implementación del Problema Directo, que se muestra ahora, es sorprendentemente diferente del enfoque "desarrollar un algoritmo, programa, método para almacenar y recuperar resultados"; todo se reduce a "escribir una consulta en la base de datos". De cara al futuro, notamos que todo el ciclo desde el desarrollo de un modelo de gráfico simple, la carga de datos en Neo4j desde una base de datos relacional, la escritura de consultas y hasta que se obtuvo el resultado, tomó un total de un día.
3-4 meses vs 1 día !!! Esta fue la última razón para la salida final a la base de datos de gráficos.
Parte 4. Grafica la base de datos Neo4j y carga los datos en ella
4.1. Comparación de bases de datos relacionales y gráficas



4.2. Modelo de datos
El modelo básico de la presentación TS hasta el nivel de topología L3 inclusive:

Por supuesto, el modelo es más extenso que el presentado, y también contiene servicios MPLS e interfaces virtuales, pero por simplicidad, consideraremos un fragmento limitado del mismo.
En tal modelo, la relación entre dos elementos de red de la misma región se puede representar como:

4.3. Cargando datos
Cargamos datos de la base de datos de los parámetros y topología del vehículo. Para cargar en Neo4j desde una base de datos SQL, se utiliza la biblioteca APOC - apoc.load.jdbc , que toma como entrada una cadena de conexión a un RDBMS y el texto de una consulta SQL, y devuelve un conjunto de cadenas que se asignan a nodos, enlaces o parámetros a través de expresiones CYHPER. Estas operaciones se realizan capa por capa para cada tipo de objeto de modelo.
Por ejemplo, un pase para cargar / actualizar nodos que representan elementos de red (nodos):
|
Llamar al procedimiento apoc.load.jdbc,
obtener un conjunto de datos |
|
Para cada fila del conjunto
de datos por región y código de sitio, se buscan nodos que representan los sitios correspondientes. |
|
Para cada objeto de sitio, se actualizan los
elementos de red asociados (nodo). Se utiliza la instrucción MERGE + SET, que actualiza los parámetros del objeto, si ya existe en la base de datos, si no , crea el objeto. También se registran los parámetros del nodo Nodo y sus conexiones con el nodo PL . |
Y así sucesivamente, en todos los niveles del modelo TS.
El campo Actualizado se utiliza para controlar la relevancia de los datos en la columna; se eliminan los objetos que no se actualizan durante más de un período determinado.
Parte 5. Resolver el problema inverso en Neo4j
Cuando comenzamos, la expresión "seguimiento de servicio" primero trajo las siguientes asociaciones:

Es decir, que la ruta actual del servicio se traza directamente, en un momento dado.
Esto no es exactamente lo que tenemos en una base de datos gráfica. En la GDB, un servicio se rastrea según las relaciones de objetos que determinan su configuración en cada elemento de red involucrado. Es decir, una configuración se representa en forma de modelo de gráfico y la traza resultante es un paso a través del modelo que representa esta configuración.
Dado que, a diferencia del segmento conmutado, las rutas de servicio reales en el segmento mpls están determinadas por protocolos dinámicos, tuvimos que aceptar algunos ...
5.1. Supuestos para segmentos enrutados
Porque a partir de los datos de configuración de los servicios mpls, no es posible determinar su ruta exacta a través de los segmentos controlados por los protocolos de enrutamiento dinámico (especialmente si se utiliza la ingeniería de tráfico); para la solución, se utiliza el algoritmo de Dijkstra.
Sí, existen sistemas de gestión que pueden proporcionar la ruta real de los LSP de servicio a través de la interfaz NBI, pero hasta ahora solo tenemos un proveedor de este tipo, y hay más de un proveedor en el segmento MVN.
Sí, existen sistemas de análisis de protocolos de enrutamiento dentro del AS que, al escuchar el intercambio de protocolos IGP, pueden determinar la ruta actual del prefijo de interés. Pero existen tales sistemas, como el Boeing derribado, y dado que dicho sistema debe implementarse en todos los AS del mismo backhole móvil, el costo de la solución, junto con todas las licencias, será el costo de un Boeing derribado por un puente de hierro fundido atado al cohete Angara cuando esté completamente repostado. Y esto a pesar del hecho de que tales sistemas no resuelven completamente el problema de contabilizar rutas a través de varios AS usando BGP.
Por lo tanto, hasta ahora. Por supuesto, agregamos varios accesorios a las condiciones del algoritmo estándar de Dijkstra:
- Contabilización del estado de interfaces / puertos. El enlace desconectado aumenta de costo y llega al final de las posibles opciones de ruta.
- Contabilización del estado del enlace de respaldo. De acuerdo con el sistema Performance Monitoring, se calcula la presencia de solo tráfico keepalive en el canal mpls, respectivamente, el costo de dicho canal también aumenta.
5.2. Cómo resolver el problema inverso en Neo4j
Recordatorio. La tarea inversa es obtener una lista de servicios que dependen de un canal o nodo específico de la red de transporte (TS).
5.2.1. Segmento L2 conmutado
Para el segmento conmutado, donde la ruta del servicio y la configuración del servicio son prácticamente iguales, el problema aún se puede resolver a través de solicitudes de CYPHER. Por ejemplo, para un vuelo de relevo de radio a partir de los resultados de la resolución del problema directo en la cláusula 3.1.1., Haremos una solicitud desde el módem de enlace de relevo de radio: "expandiremos" todas las cadenas Vlan que lo atraviesan:
match (tn:node {name:'RRN_29_XXXX_1'})-->(tn_port:port {name:'Modem-1'})-->(tn_vlan:vlan)
with tn, tn_vlan, tn_port
call apoc.path.spanningTree(tn_vlan,{relationshipFilter:"ptp_vlan>|v_ptp_vlan>", maxLevel:20}) yield path as pp
with tn_vlan,pp,nodes(pp)[-1] as last_node, tn_port
match (last_node)-[:vlan]->(:port)-->(n:node)
return pp, n, tn_portEl nodo rojo indica el módem cuyo Vlan estamos implementando. Se rodearon 3 BS en las que, como resultado, condujo el despliegue de tránsito Vlan con Modem1.

Este enfoque tiene varios problemas:
- El Vlan configurado debe ser conocido por los puertos y cargado en el modelo.
- Debido a la posible fragmentación, la cadena Vlan no siempre se envía al nodo terminal
- Es imposible determinar si el último nodo de la cadena Vlan pertenece a un nodo terminal o si el servicio realmente continúa.
Es decir, siempre es más conveniente rastrear un servicio entre los nodos / puntos finales de su segmento, en lugar de hacerlo desde un "medio" arbitrario y desde una capa OSI.
5.2.2. Segmento enrutado
Con un segmento enrutado, como ya se describió en la cláusula 5.1, no hay necesidad de elegir; no hay forma de resolver el problema inverso basado en los datos de la configuración actual de algún enlace MPLS intermedio; la configuración no define explícitamente el seguimiento del servicio.
5.3. Decisión
La decisión se tomó de la siguiente manera.
- Se realiza la carga completa del modelo del vehículo, incluidos BS y controladores
- Para todas las BS, el problema directo está resuelto: rastreo de los servicios Iub, S1 desde la BS hasta el MVN límite, y luego desde el MVN límite hasta los controladores o pasarelas correspondientes.
- Los resultados de seguimiento se escriben en una base de datos SQL normal en el formato: Nombre de BS: una matriz de elementos de ruta de servicio
En consecuencia, cuando se accede a la base de datos con la condición Nodo TS o Nodo TS + Puerto, se devuelve una lista de servicios (BS), cuya matriz de ruta contiene el Nodo o Nodo + Puerto requerido.

Parte 6. Resultados y conclusiones
6.1. resultados
Como resultado, el sistema funciona de la siguiente manera:

Por el momento, para resolver el problema directo, es decir Al analizar las causas de degradación de los servicios individuales, se desarrolló una aplicación web que muestra el resultado de la traza (ruta) de Neo4j, con datos superpuestos sobre la calidad y el rendimiento de las secciones individuales de la ruta.

Para obtener una lista de servicios que dependen de nodos o canales del TS (solución del problema inverso), se ha desarrollado una API para sistemas externos (en particular, Remedy).
6.2. conclusiones
- Ambas soluciones elevaron la automatización del análisis de la calidad de los servicios y la red de transporte a un nivel cualitativamente nuevo.
- Además, en presencia de datos prefabricados sobre las rutas de los servicios BS, fue posible proporcionar rápidamente datos para las unidades de negocio sobre la posibilidad técnica de incluir clientes B2B en sitios específicos, en términos de capacidad y calidad de la ruta.
- Neo4j ha demostrado ser una herramienta muy poderosa para resolver problemas de gráficos de red. La solución está bien documentada , tiene un amplio soporte en varias comunidades de desarrolladores y se desarrolla y mejora constantemente.
6.3. Planes
Tenemos planes:
- expansión de segmentos tecnológicos modelados en la base de datos Neo4j
- desarrollo e implementación de algoritmos de rastreo para servicios de banda ancha
- aumento del rendimiento de la plataforma del servidor
¡Gracias por su atención!