
Hola a todos, mi nombre es Igor Sidorenko. El seguimiento es una de las principales áreas de mi trabajo y también mi afición. Hablaré sobre Zabbix y cómo usarlo para monitorear la información que necesitamos sobre los volúmenes de NetApp, con acceso solo a través de SSH. ¿Quién está interesado en el tema de seguimiento y Zabbix, por favor, bajo cat.
Inicialmente, monitoreamos los volúmenes montándolos en un servidor específico, en el cual colgaba una plantilla especial que captura los montajes NFS en el nodo y los pone bajo monitoreo, por analogía con los sistemas de archivos de la plantilla básica de Linux. La montura tuvo que registrarse en fstab y montarse manualmente; debido a esto, se perdió y se olvidó mucho.
Entonces se me ocurrió una gran idea: necesitamos automatizar todo esto. Había varias opciones:
Hay plantillas listas para usar que funcionan con SNMP, pero no tienen acceso.Obtener una lista de volúmenes y montaje automático en un nodo: necesitas crear una carpeta, registrar fstab, montar, eso es todo, demasiadas hemorroides.Existe una gran API , pero como solo alquilamos espacio, en nuestra versión de ONTAP se recorta y no brinda al usuario la información necesaria.- De alguna manera, use el acceso SSH para obtener volúmenes y configurarlos para su monitoreo.
La elección recayó en el agente SSH .
Descubrimiento de bajo nivel (LLD)
Primero, necesitamos crear un descubrimiento de bajo nivel (LLD) , estos serán los nombres de nuestros volúmenes. Todo esto es necesario para poder extraer información específica sobre el volumen que necesitamos. Los datos sin procesar se parecen a esto (114 en el momento de escribir este artículo):
set -unit B; volume show -state online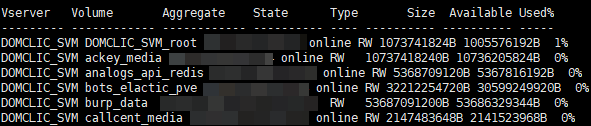
Bueno, ¿cómo podemos hacerlo sin muletas? Escribamos un script bash de una línea que muestre los nombres de los volúmenes en formato JSON (dado que se trata de una verificación externa , los scripts están en el servidor Zabbix en el directorio
/usr/lib/zabbix/externalscripts):
netapp_volume_discovery.sh
#!/usr/bin/bash
SVM_NAME=""
SVM_ADDRESS=""
USERNAME=""
PASSWORD=""
for i in $(sshpass -p $PASSWORD ssh -o StrictHostKeyChecking=no $USERNAME@$SVM_ADDRESS 'set -unit B; volume show -state online' | grep $SVM_NAME | awk {'print $2'}); do echo '{"volume_name":"'$i'"}'; done | jq -s '.
Ahora necesita crear una plantilla y crear elementos de datos basados en los datos recibidos:
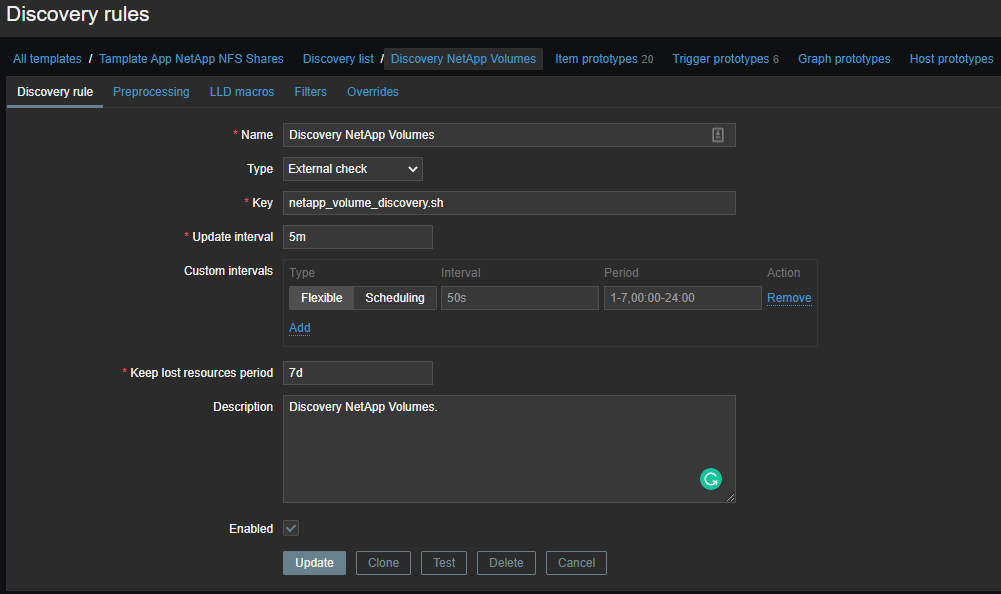
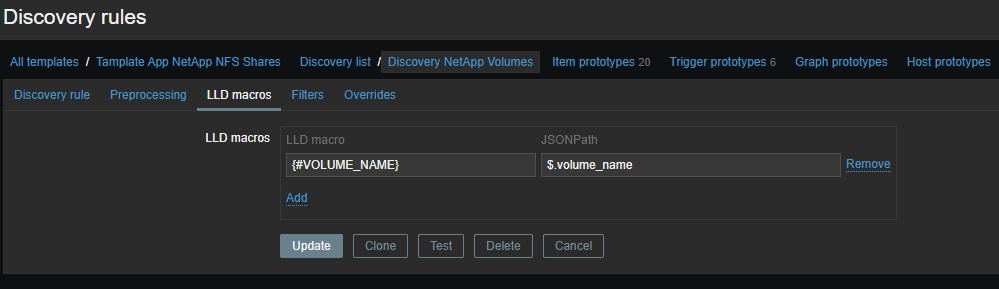
Elementos de datos
Para crear artículos automáticamente, debe crear un prototipo de artículos : utilizaremos artículos maestros y varios artículos dependientes . Por lo tanto, para cada volumen, se crea un elemento maestro en el que se ejecuta un conjunto de comandos sobre SSH:
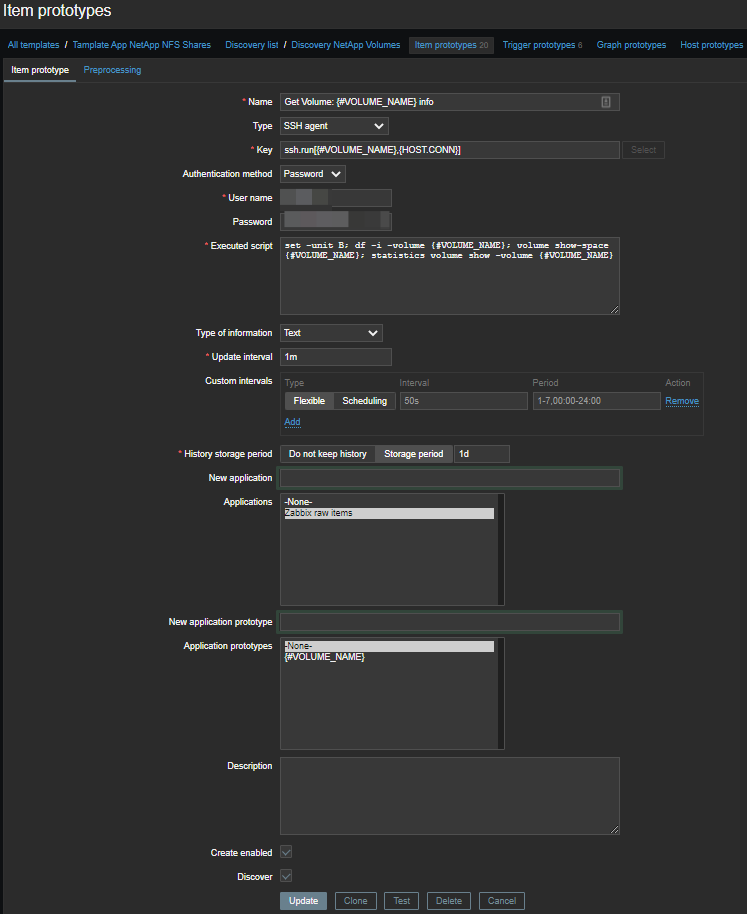
set -unit B; df -i -volume {#VOLUME_NAME}; volume show-space {#VOLUME_NAME}; statistics volume show -volume {#VOLUME_NAME}Obtenemos tal hoja:
Obtener volumen: información de ackey_media
Last login time: 9/15/2020 12:42:45
Filesystem iused ifree %iused Mounted on
/vol/ackey_media/ 96 311191 0% /ackey_media
Volume Name: ackey_media
Volume MSID: 2159592810
Volume DSID: 1317
Vserver UUID: 46a00e5d-c22d-11e8-b6ed-00a098d48e6d
Aggregate Name: NGHF_FAS2720_04
Aggregate UUID: 7ec21b4d-b4db-4f84-85e2-130750f9f8c3
Hostname: FAS2720_04
User Data: 20480B
User Data Percent: 0%
Deduplication: -
Deduplication Percent: -
Temporary Deduplication: -
Temporary Deduplication Percent: -
Filesystem Metadata: 1150976B
Filesystem Metadata Percent: 0%
SnapMirror Metadata: -
SnapMirror Metadata Percent: -
Tape Backup Metadata: -
Tape Backup Metadata Percent: -
Quota Metadata: -
Quota Metadata Percent: -
Inodes: 12288B
Inodes Percent: 0%
Inodes Upgrade: -
Inodes Upgrade Percent: -
Snapshot Reserve: -
Snapshot Reserve Percent: -
Snapshot Reserve Unusable: -
Snapshot Reserve Unusable Percent: -
Snapshot Spill: -
Snapshot Spill Percent: -
Performance Metadata: 28672B
Performance Metadata Percent: 0%
Total Used: 1212416B
Total Used Percent: 0%
Total Physical Used Size: 1212416B
Physical Used Percentage: 0%
Logical Used Size: 1212416B
Logical Used Percent: 0%
Logical Available: 10736205824B
DOMCLIC_SVM : 9/15/2020 12:42:51
*Total Read Write Other Read Write Latency
Volume Vserver Ops Ops Ops Ops (Bps) (Bps) (us)
----------- ----------- ------ ---- ----- ----- ----- ----- -------
ackey_media DOMCLIC_SVM 0 0 0 0 0 0 0De esta hoja, debemos seleccionar las métricas que necesitamos.
La magia de las expresiones regulares
Inicialmente, quería usar JavaScript para el preprocesamiento , pero de alguna manera no lo dominé, no funcionó. Por lo tanto, me detuve en los habituales y los uso en casi todas partes.
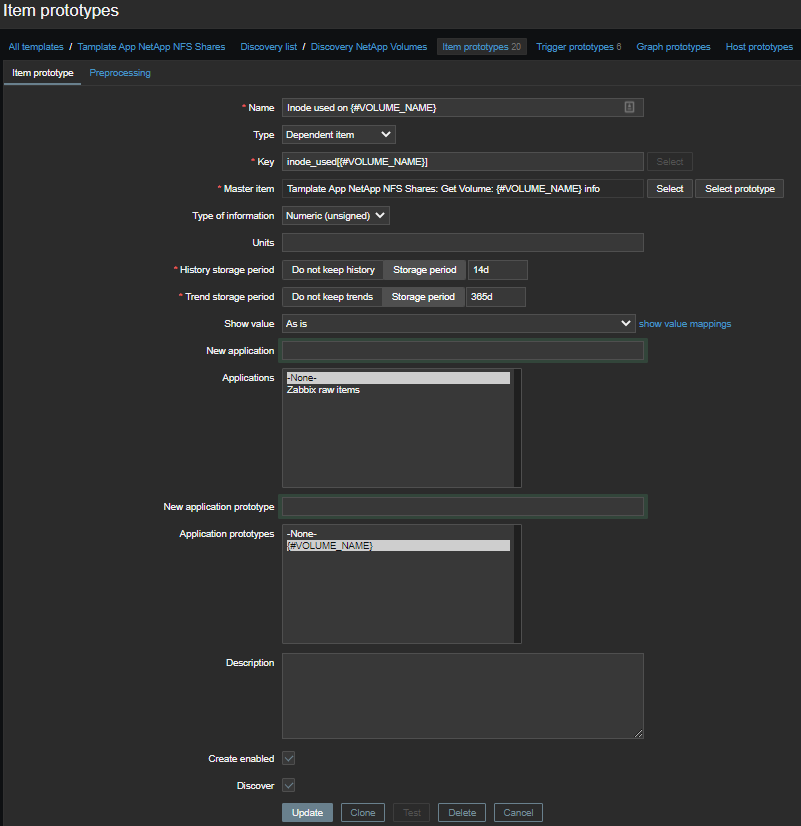
Número de inodos utilizados
Seleccionaremos información solo sobre inodos para cada volumen en dos etapas: Primero, toda la información:
\/vol\/\w+\/.*

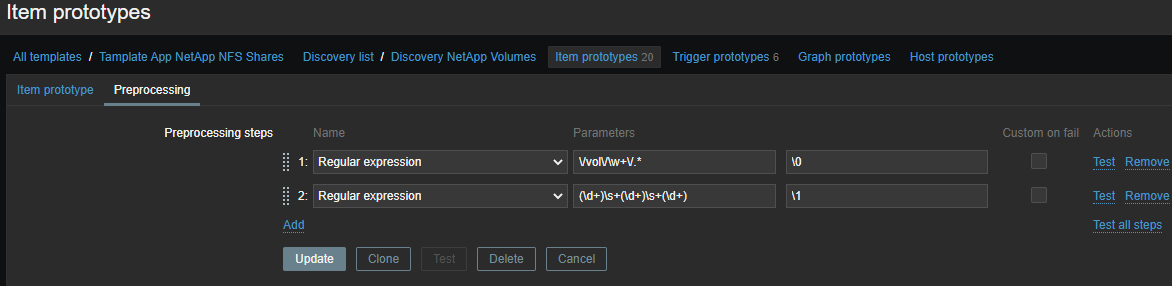
Luego, específicamente por métricas:
(\d+)\s+(\d+)\s+(\d+)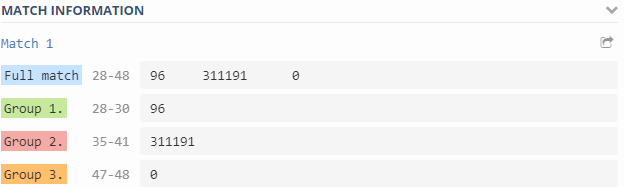

Salida: plantilla de formato de salida.
\N ( N=1..9)- la secuencia de escape se reemplaza por el grupo de coincidencia N-ésimo. La secuencia de escape \0se reemplaza con el texto correspondiente:
\1 - Inode used on {#VOLUME_NAME}- el número de inodos utilizados;\2 - Inode free on {#VOLUME_NAME}- el número de inodos libres;\3 - Inode used percentage on {#VOLUME_NAME}- inodos usados como porcentaje;Inode total on {#VOLUME_NAME}- elemento calculado , el número de inodos disponibles.
last(inode_free[{#VOLUME_NAME}])+last(inode_used[{#VOLUME_NAME}])Espacio usado
Aquí todo es más simple, los datos y los habituales están en un formato más agradable: sacamos la métrica que necesitamos y tomamos solo el número:
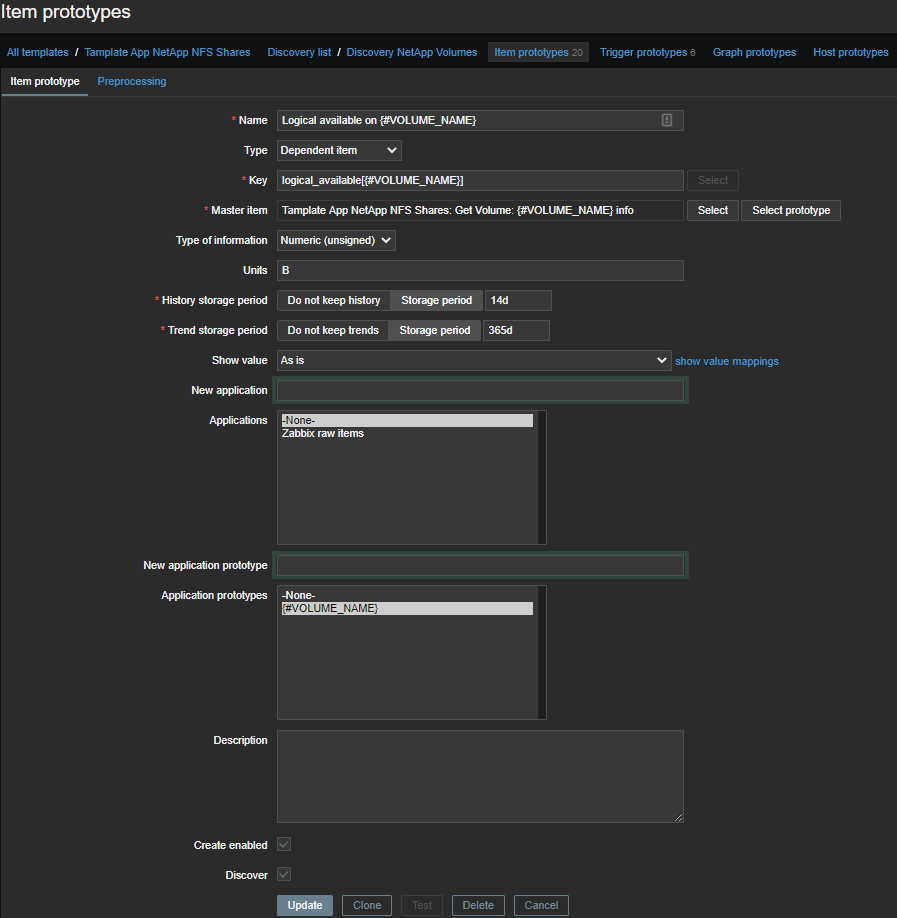
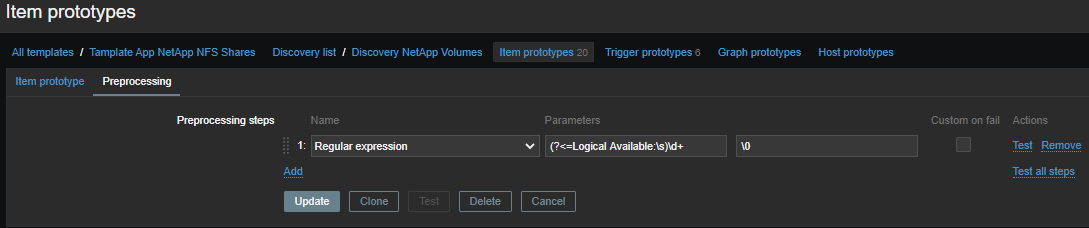
(?<=Logical Available:\s)\d+

Métricas recopiladas:
Logical available on {#VOLUME_NAME}- la cantidad de espacio lógico disponible;Logical used percent on {#VOLUME_NAME}- lugar lógico utilizado en porcentaje;Logical used size on {#VOLUME_NAME}- la cantidad de espacio lógico utilizado;Physical used percentage on {#VOLUME_NAME}- espacio físico utilizado en porcentaje;Total physical used size on {#VOLUME_NAME}- la cantidad de espacio físico utilizado;Total used on {#VOLUME_NAME}- espacio total utilizado;Total used percent on {#VOLUME_NAME}- total de plazas utilizadas en porcentaje;Logical size on {#VOLUME_NAME}- elemento calculado , la cantidad de espacio lógico disponible.
last(logical_available[{#VOLUME_NAME}])+last(total_used[{#VOLUME_NAME}])Rendimiento de volumen
Después de leer la documentación y hurgar con diferentes comandos, descubrí que podemos obtener métricas sobre el rendimiento de nuestros volúmenes. Una pequeña pieza es responsable de esto:
statistics volume show -volume {#VOLUME_NAME}
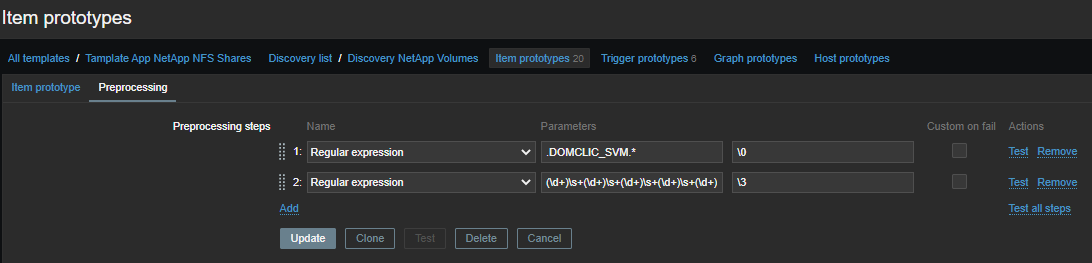
Seleccionamos métricas de rendimiento de la hoja común con la primera regularidad:
.DOMCLIC_SVM.*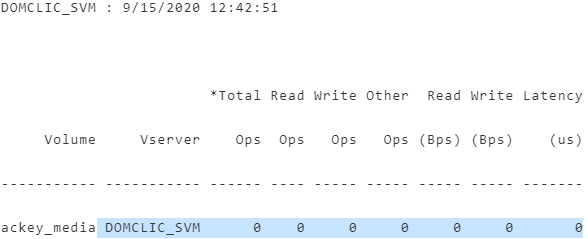

En segundo lugar, agrupamos los números:
(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)\s+(\d+)
Dónde:
\1 - Total number of operations per second on {#VOLUME_NAME}- el número total de operaciones por segundo;\2 - Read operations per second on {#VOLUME_NAME}- leer operaciones por segundo;\3 - Write operations per second on {#VOLUME_NAME}- operaciones de escritura por segundo;\4 - Other operations per second on {#VOLUME_NAME}- otras operaciones por segundo (no sé qué es, pero por alguna razón disparo);\5 - Read throughput in bytes per second on {#VOLUME_NAME}- velocidad de lectura en bytes por segundo;\6 - Write throughput in bytes per second on {#VOLUME_NAME}- velocidad de escritura en bytes por segundo;\7 - Average latency for an operation in microseconds on {#VOLUME_NAME}- latencia media de las operaciones en microsegundos.
Alertando
El conjunto de disparadores es estándar, lugar e inodos:
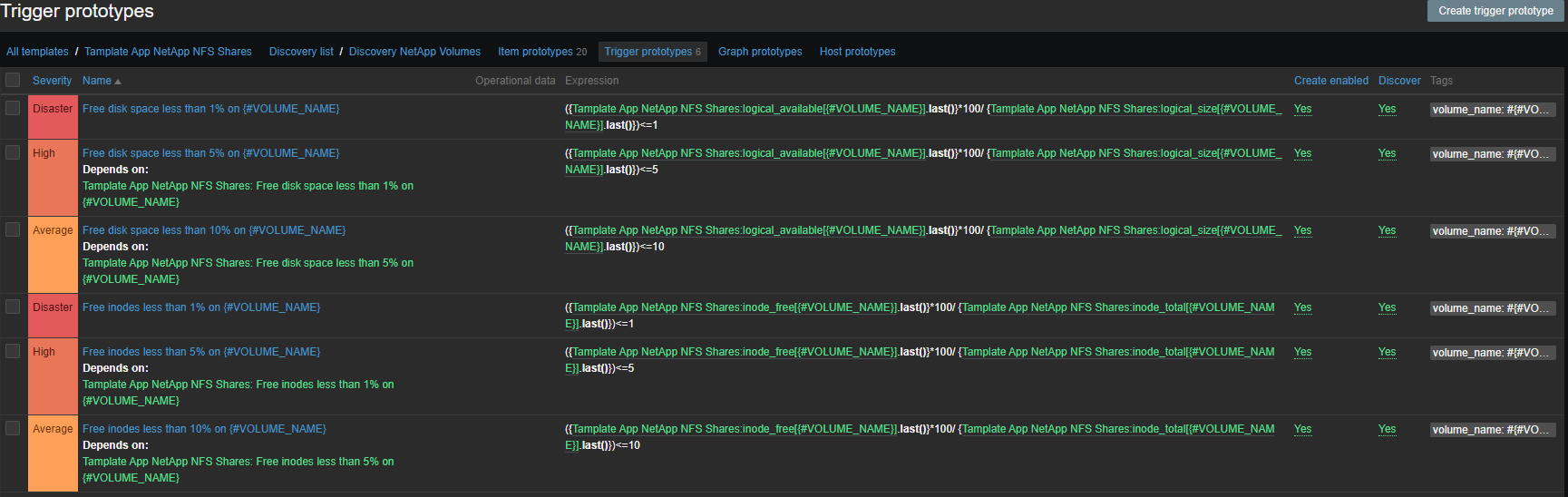
- Espacio libre en disco menos del 1% en {#VOLUME_NAME}
- Espacio libre en disco inferior al 5% en {#VOLUME_NAME}
- Espacio libre en disco inferior al 10% en {#VOLUME_NAME}
- Inodos libres de menos del 1% en {#VOLUME_NAME}
- Inodos libres de menos del 5% en {#VOLUME_NAME}
- Inodos libres de menos del 10% en {#VOLUME_NAME}
Visualización
La visualización se realiza principalmente en Grafana , es hermosa y conveniente. Por ejemplo, un volumen se parece a esto: En la esquina superior derecha hay un botón Mostrar en Zabbix , con el que puedes caer en Zabbix y ver todas las métricas del volumen seleccionado.
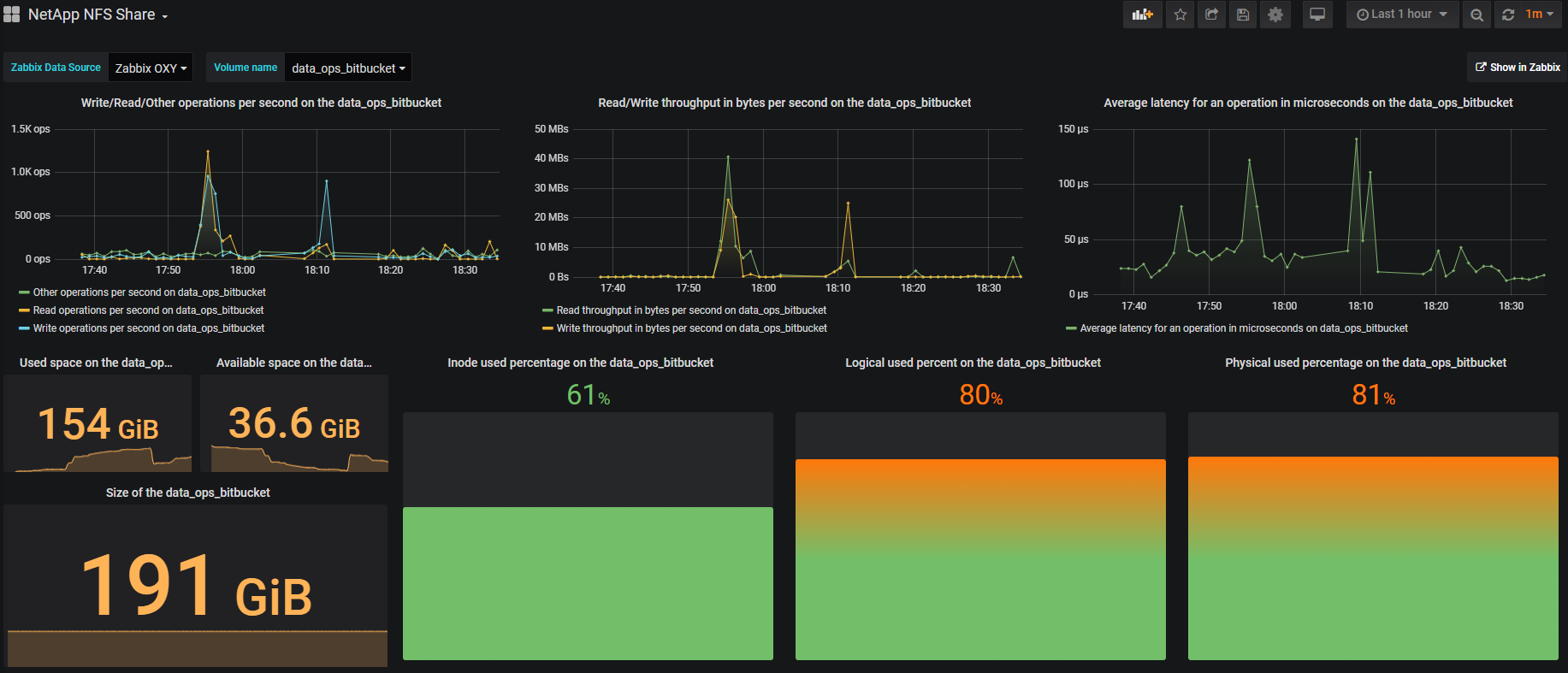
Salir
- Configuración automática de volúmenes para monitoreo.
- Eliminación automática de volúmenes de la supervisión, si el volumen se elimina de NetApp.
- Eliminamos el enlace a un servidor y el montaje manual de volúmenes.
- Métricas de rendimiento agregadas para cada volumen. Ahora es menos probable que retiremos el soporte del centro de datos por el bien de los gráficos de NetApp.
Pronto prometen actualizar ONTAP y traer una API extendida, la plantilla se moverá a un agente HTTP .
Plantilla, guión y tablero
github.com/domclick/netapp-volume-monitoring
Enlaces útiles
docs.netapp.com/ontap-9/index.jsp
www.zabbix.com/documentation/current