
Hay una broma en los círculos de TI de que el aprendizaje automático (ML) es como el sexo entre adolescentes: todo el mundo habla de ello, todo el mundo pretende hacerlo, pero, de hecho, muy pocas personas tienen éxito. FunCorp ha logrado introducir ML en la mecánica principal de su producto y lograr una mejora radical (¡casi un 40%!) En las métricas clave. ¿Interesante? Bienvenido a cat.
Un poco de historia
Para aquellos que leen el blog de FunCorp de manera irregular, permítanme recordarles que nuestro producto más exitoso es la aplicación iFunny UGC con elementos de una red social para los amantes de los memes. Los usuarios (y este es uno de cada cuatro representantes de la generación joven en los EE. UU.) Cargan o crean nuevas imágenes o videos directamente en la aplicación, y un algoritmo inteligente selecciona (o, como decimos, "características", de la palabra "destacados") lo mejor de ellos y forma cada uno día de 7 números de 30-60 unidades de contenido en un feed separado, con el que interactúa el 99% de la audiencia. Como resultado, al ingresar a la aplicación, cada usuario ve los mejores memes, videos e imágenes divertidas. Si visita con frecuencia, el feed se desplaza rápidamente y el usuario espera el próximo número en unas pocas horas. Sin embargo, si visitas con menos frecuencia, el contenido destacado se acumula y el feed puede crecer hasta 1000 elementos en unos pocos días.
Así surgió la tarea: mostrar a cada usuario el contenido más relevante para él, agrupando los memes que le interesan personalmente al inicio del feed.
Durante más de 9 años de existencia de iFunny, ha habido varios enfoques para esta tarea.
Primero, probamos la forma obvia de clasificar el feed por el número de sonrisas (nuestro análogo de "me gusta"): tasa de sonrisas . Era mejor que ordenar en orden cronológico, pero al mismo tiempo llevó al efecto de la "temperatura promedio en el hospital": hay poco humor que gusta a todos, y siempre habrá quienes no estén interesados (e incluso francamente molestos) temas populares de la actualidad. ... Pero también quieres ver todos los nuevos chistes divertidos de tu caricatura favorita.
En el siguiente experimento, intentamos tener en cuenta los intereses de las microcomunidades individuales: fanáticos del anime, deportes, memes con perros y gatos, etc. Para ello, empezaron a formar varios feeds destacados temáticos y ofrecer a los usuarios elegir temas de su interés, utilizando etiquetas y texto reconocido en imágenes. Algo ha mejorado, pero el efecto de la red social se ha perdido: hay menos comentarios sobre el contenido destacado, que jugó un papel importante en la participación de los usuarios. Además, en el camino hacia los feeds segmentados, perdimos muchos de los memes más populares. Vieron "Dibujos animados favoritos", pero no vieron los chistes sobre "Los últimos vengadores".
Dado que ya comenzamos a implementar algoritmos de aprendizaje automático en nuestro producto, que presentamos en nuestra propia reunión, querían hacer otro enfoque utilizando esta tecnología.
Se decidió intentar construir un sistema de recomendaciones basado en el principio de filtrado colaborativo. Este principio es bueno en los casos en los que la aplicación tiene muy pocos datos sobre los usuarios: pocos indican su edad o sexo al registrarse, y solo por la dirección IP se puede asumir su ubicación geográfica (aunque se sabe sin adivinos que la gran mayoría de los usuarios de iFunny son residentes Estados Unidos) y por modelo de teléfono: nivel de ingresos. Sobre esto, en general, todo. El filtrado colaborativo funciona así: se toma el historial de valoraciones positivas del contenido del usuario, hay otros usuarios con valoraciones similares, luego se recomienda lo que a los mismos usuarios ya les ha gustado (con valoraciones similares).
Características de la tarea
Los memes son contenido bastante específico. Primero, es muy susceptible a las tendencias que cambian rápidamente. El contenido y la forma que subió a lo más alto e hizo sonreír al 80% de la audiencia hace una semana, hoy puede causar molestia por su carácter secundario e irrelevante.
En segundo lugar, una interpretación muy no lineal y situacional del significado del meme. En la selección de noticias, puede encontrar nombres conocidos, temas que un usuario en particular usa de manera bastante consistente. En una selección de películas, puede conocer el reparto, el género y mucho más. Sí, puedes captar todo esto en una selección de memes personales. ¡Pero qué decepcionante sería perderse una verdadera obra maestra del humor, que utiliza imágenes o vocabulario que no encaja en absoluto en el contenido semántico!

Finalmente, una gran cantidad de contenido generado dinámicamente. En iFunny, los usuarios crean decenas de miles de publicaciones todos los días. Todo este contenido debe ser "rastrillado" lo más rápido posible, y en el caso de un sistema de recomendación personalizado, no solo para encontrar "diamantes", sino también para poder predecir la valoración del contenido por parte de diversos representantes de la sociedad.
¿Qué significan estas características para el desarrollo de modelos de aprendizaje automático? En primer lugar, el modelo debe entrenarse constantemente con los datos más recientes. Al comienzo mismo de la inmersión en el desarrollo de un sistema de recomendación, todavía no está del todo claro si estamos hablando de decenas de minutos o de un par de horas. Pero ambos significan la necesidad de un reentrenamiento constante del modelo, o mejor aún, entrenamiento en línea sobre un flujo continuo de datos. Todas estas no son las tareas más sencillas desde el punto de vista de encontrar una arquitectura de modelo adecuada y seleccionar sus hiperparámetros: tales que garanticen que en un par de semanas las métricas no empezarán a degradarse con seguridad.
Otra dificultad es la necesidad de seguir el protocolo de prueba a / b adoptado por nosotros. Nunca implementamos nada sin verificar primero a una parte de los usuarios, comparando los resultados con un grupo de control.
Luego de largos cálculos, se decidió iniciar un MVP con las siguientes características: solo usamos información sobre la interacción de los usuarios con el contenido, entrenamos el modelo en tiempo real, directamente en un servidor equipado con una gran cantidad de memoria, lo que permite almacenar todo el historial de interacción del grupo de prueba de usuarios por un período bastante largo. Decidimos limitar el tiempo de entrenamiento a 15-20 minutos para mantener el efecto de novedad, así como tener tiempo para utilizar los últimos datos de los usuarios que llegan masivamente a la aplicación durante los lanzamientos.
Modelo
Primero, comenzamos a torcer el filtrado colaborativo más clásico con descomposición matricial y entrenamiento en ALS (mínimos cuadrados alternos) o SGD (descenso de gradiente estocástico). Pero rápidamente se dieron cuenta: ¿por qué no empezar de inmediato con la red neuronal más simple? Con una malla simple de una sola capa, en la que solo hay una capa de incrustación lineal, y no hay envoltura de capas ocultas, para no enterrarse en semanas de seleccionar sus hiperparámetros. ¿Un poco más allá de MVP? Tal vez. Pero entrenar una malla de este tipo no es más difícil que una arquitectura más clásica, si tiene hardware equipado con una buena GPU (tuvo que desembolsarlo).
Inicialmente, estaba claro que solo hay dos opciones para el desarrollo de eventos: o el desarrollo dará un resultado significativo en las métricas del producto, luego será necesario profundizar en los parámetros de usuarios y contenido, en capacitación adicional sobre contenido nuevo y nuevos usuarios, en redes neuronales profundas, o la clasificación de contenido personalizado no traerá el aumento tangible y la "compra" se pueden cubrir. Si ocurre la primera opción, entonces todo lo anterior tendrá que ajustarse a la capa de incrustación inicial.
Decidimos optar por la Máquina de Factorización Neural . El principio de su funcionamiento es el siguiente: cada usuario y cada contenido son codificados por vectores de la misma longitud fija - embeddings, que luego son entrenados en un conjunto de interacciones conocidas entre el usuario y el contenido.
El conjunto de formación utiliza todos los datos de los usuarios que ven el contenido. Además de las sonrisas, se decidió considerar los clics en los botones "compartir" o "guardar", así como escribir un comentario, para obtener comentarios positivos sobre el contenido. Si está presente, la interacción se marca con 1 (uno). Si, después de ver, el usuario no dejó comentarios positivos, la interacción se marca con 0 (cero). Así, incluso en ausencia de una escala de calificación explícita, se utiliza un modelo explícito (un modelo con una calificación explícita del usuario), y no uno implícito, que tomaría en cuenta solo acciones positivas.
También probamos el modelo implícito, pero no funcionó de inmediato, por lo que nos enfocamos en el modelo explícito. Quizás, para el modelo implícito, necesita usar funciones de pérdida de clasificación más complicadas que una simple entropía cruzada binaria.
La diferencia entre la factorización de matriz neuronal y el filtrado colaborativo neuronal estándar está en la presencia de la denominada capa de agrupación de bi-interacción en lugar de la capa habitual completamente conectada que simplemente conectaría al usuario y los vectores de incrustación de contenido. La capa de Bi-Interacción convierte un conjunto de vectores de incrustación (solo hay 2 vectores en iFunny: usuario y contenido) en un vector multiplicándolos elemento por elemento.
En ausencia de capas ocultas adicionales sobre Bi-Interaction, obtenemos el producto escalar de estos vectores y, agregando sesgo del usuario y sesgo de contenido, lo envolvemos en un sigmoide. Esta es una estimación de la probabilidad de comentarios positivos del usuario después de ver este contenido. De acuerdo con esta evaluación, clasificamos el contenido disponible antes de demostrarlo en un dispositivo específico.
Por lo tanto, la tarea de la capacitación es asegurarse de que las inserciones de contenido y de usuario para las que hay una interacción positiva estén cerca entre sí (tengan el producto punto máximo), y las inserciones de contenido y de usuario para las que hay una interacción negativa estén lejos unas de otras. (producto escalar mínimo).
Como resultado de esta capacitación, las incorporaciones de usuarios que sonríen de la misma manera se acercan por sí mismos. Y esta es una descripción matemática conveniente de los usuarios que se puede utilizar en muchas otras tareas. Pero esa es otra historia.
Entonces, el usuario ingresa al feed y comienza a ver el contenido. Cada vez que ve, sonríe, comparte, etc. el cliente envía estadísticas a nuestro almacenamiento analítico (sobre el cual, si está interesado, escribimos anteriormente en el artículo Moving from Redshift to Clickhouse ). En el camino, seleccionamos los eventos que nos interesan y los enviamos al servidor ML, donde se almacenan en la memoria.
Cada 15 minutos, el modelo se vuelve a entrenar en el servidor, después de lo cual las estadísticas de los nuevos usuarios se tienen en cuenta en las recomendaciones.
El cliente solicita la siguiente página del feed, se forma de manera estándar, pero en el camino se envía la lista de contenido al servicio ML, que la ordena según los pesos dados por el modelo entrenado para este usuario en particular.

Como resultado, el usuario ve primero aquellas imágenes y videos que, según el modelo, le serán más preferibles.
Arquitectura de servicios internos
El servicio funciona a través de HTTP. Flask se utiliza como servidor HTTP junto con Gunicorn. Maneja dos solicitudes: add_event y get_rates.
La solicitud add_event agrega una nueva interacción entre el usuario y el contenido. Se agrega a una cola interna y luego se procesa en un proceso separado (alcanzando un máximo de 1600 rps).
La solicitud get_rates calcula los pesos para la lista user_id y content_id según el modelo (en el pico del orden de cientos de rps).
El principal proceso interno es el Dispatcher. Está escrito en asyncio e implementa la lógica básica:
- procesa la cola de solicitudes add_event y las almacena en un mapa hash enorme (200 millones de eventos por semana);
- recalcula el modelo en un círculo;
- guarda nuevos eventos en el disco cada media hora, mientras borra los eventos anteriores a una semana del mapa de hash.

El modelo entrenado se coloca en la memoria compartida, desde donde los trabajadores HTTP lo leen.
resultados
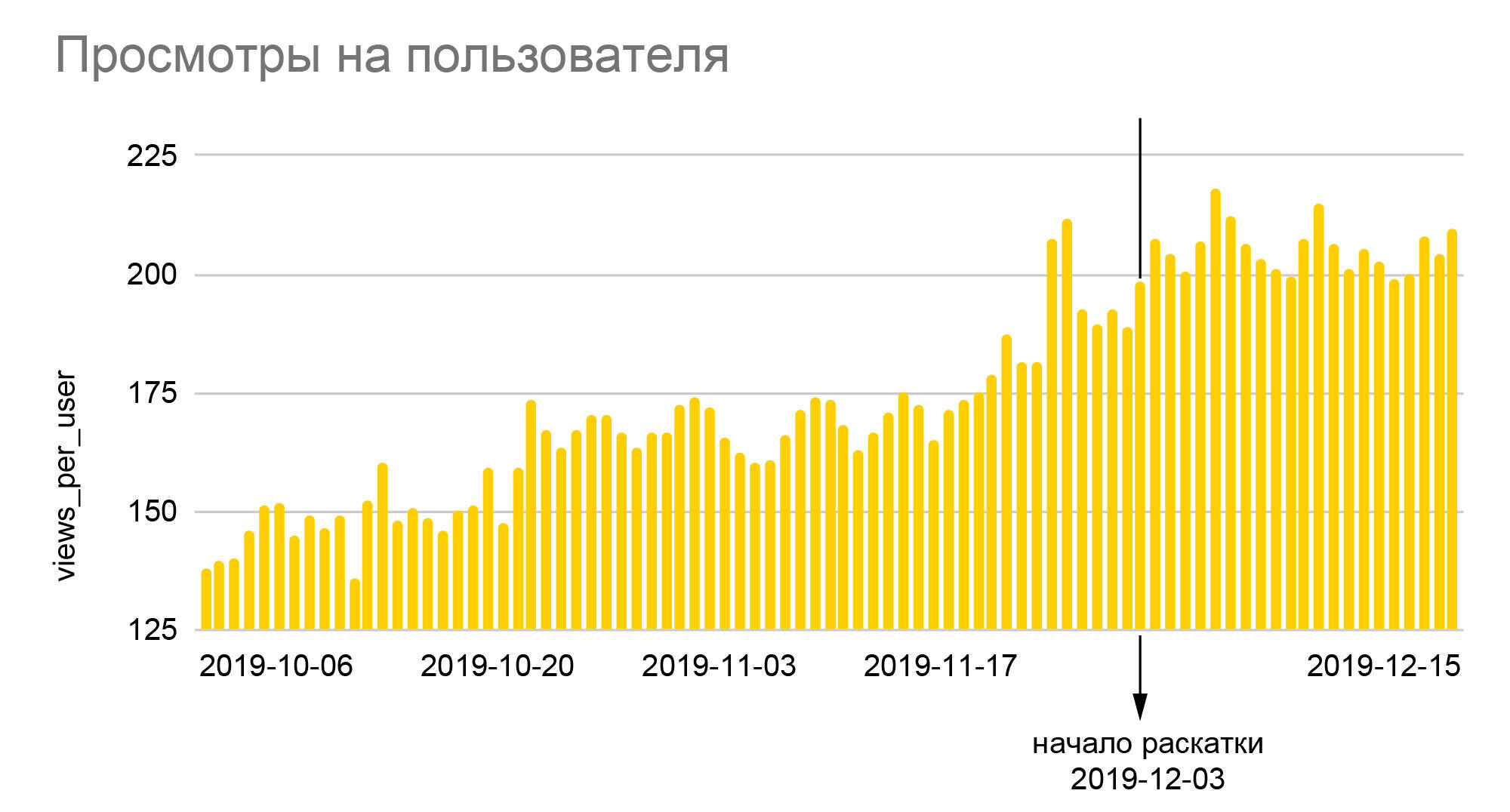

Los gráficos hablan por sí mismos. El crecimiento del 25% en el número relativo de emoticones y casi el 40% en la profundidad de las vistas que vemos en ellos es el resultado de implementar el nuevo algoritmo a toda la audiencia al final de la prueba A / B 50/50, es decir, un aumento real en relación con los valores base. era casi el doble de grande. Dado que iFunny gana dinero con la publicidad, el aumento de profundidad significa un aumento proporcional de los ingresos, lo que, a su vez, nos permitió atravesar los meses de crisis de 2020 con bastante tranquilidad. Un aumento en el número de emoticones se traduce en una mayor lealtad, lo que significa una menor probabilidad de abandonar la aplicación en el futuro; Los usuarios leales comienzan a ir a otras secciones de la aplicación, dejan comentarios, se comunican entre sí. Y lo más importante, no solo hemos creado una base confiable para mejorar la calidad de las recomendaciones,pero también sentó las bases para la creación de nuevas funciones basadas en la colosal cantidad de datos de comportamiento anónimos que hemos acumulado durante los años de la aplicación.
Conclusión
El servicio ML Content Rate es el resultado de una gran cantidad de mejoras y mejoras menores.
Primero, los usuarios no registrados también fueron tomados en cuenta en la capacitación. Inicialmente, hubo preguntas sobre ellos, ya que a priori no podían dejar emoticonos, el comentario más frecuente después de ver el contenido. Pero pronto quedó claro que estos temores eran en vano y cerraban un gran punto de crecimiento. Se realizan muchos experimentos con la configuración de la muestra de entrenamiento: para colocar una mayor proporción de audiencia en ella o para ampliar el intervalo de tiempo de las interacciones tomadas en cuenta. En el curso de estos experimentos, resultó que no solo la cantidad de datos juega un papel importante para las métricas del producto, sino también el tiempo para actualizar el modelo. A menudo, el aumento en la calidad del ranking se ahogaba en los 10-20 minutos adicionales para volver a calcular el modelo, lo que hacía necesario abandonar las innovaciones.
Muchas mejoras, incluso las más pequeñas, han dado resultados: mejoraron la calidad del aprendizaje, aceleraron el proceso de aprendizaje o salvaron la memoria. Por ejemplo, había un problema con el hecho de que las interacciones no encajaban en la memoria, tenían que optimizarse. Además, se modificó el código y fue posible introducirlo, por ejemplo, más interacciones para volver a calcularlo. También condujo a una mejor estabilidad del servicio.
Ahora estamos trabajando en cómo utilizar de manera efectiva los parámetros conocidos del usuario y el contenido, hacer un modelo de reentrenamiento rápido incremental y también están surgiendo nuevas hipótesis para futuras mejoras.
Si está interesado en conocer cómo desarrollamos este servicio y qué otras mejoras logramos implementar, escriba en los comentarios, después de un tiempo estaremos listos para escribir la segunda parte.
Sobre los autores
Desafortunadamente, Habr no permite indicar varios autores del artículo. Aunque el artículo se publicó desde mi cuenta, la mayor parte fue escrito por el desarrollador principal de los servicios de FunCorp ML: Grisha Kuzovnikov (PhoenixMSTU), así como un analista y científico de datos: Dima Zemtsov. Su servidor recalcitrante es el principal responsable de los chistes sobre sexo adolescente, la sección de introducción y resultados, además del trabajo editorial. Y, por supuesto, todos estos logros no hubieran sido posibles sin la ayuda de los equipos de desarrollo de backend, QA, analistas y el equipo de producto, quienes inventaron todo esto y pasaron varios meses realizando y ajustando experimentos A / B.