Ruta de investigación
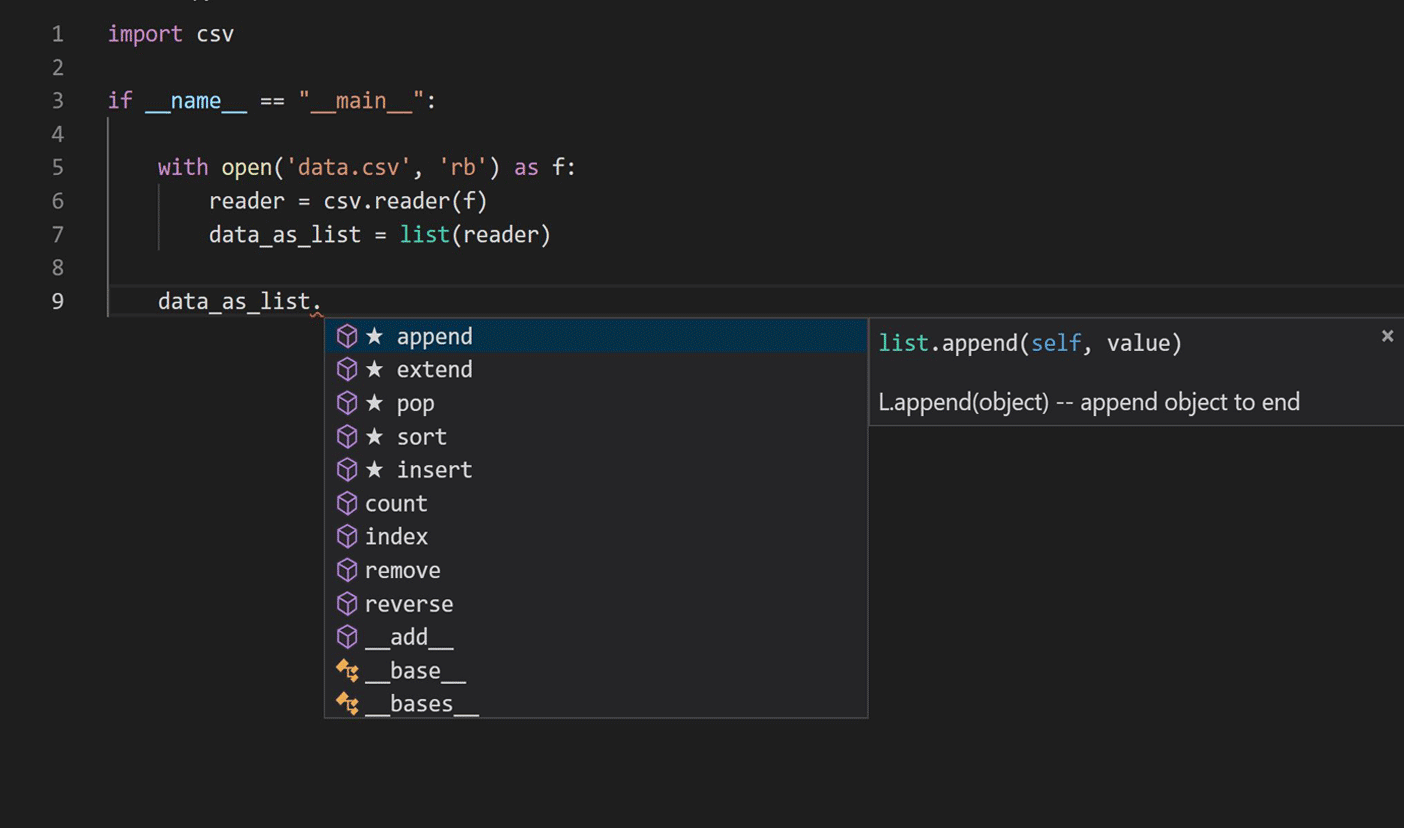
El viaje comenzó investigando la aplicación de técnicas de modelado de lenguaje en el procesamiento del lenguaje natural para aprender código Python. Nos centramos en el script de finalización de IntelliCode actual, como se muestra en la imagen a continuación.

La tarea principal es encontrar el fragmento (miembro) más probable del tipo, teniendo en cuenta el fragmento de código que precede a la llamada del fragmento (miembro). En otras palabras, dado el fragmento de código original C, el vocabulario V y el conjunto de todos los métodos posibles M ⊂ V, nos gustaría definir:
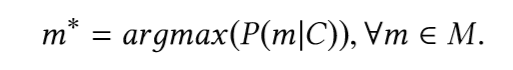
Para encontrar este fragmento, necesitamos construir un modelo que pueda predecir la probabilidad de fragmentos disponibles.
Los enfoques modernos anteriores basados en redes neuronales recurrentes ( RNN ) usaban solo la naturaleza secuencial del código fuente, tratando de transmitir técnicas de lenguaje natural sin usar las características únicas de la sintaxis del lenguaje de programación y la semántica del código. La naturaleza del problema de finalización del código lo ha convertido en un candidato prometedor para la memoria a corto plazo a largo plazo ( LSTM). Al preparar los datos para entrenar el modelo, usamos un árbol de sintaxis abstracta parcial (AST) correspondiente a fragmentos de código que contienen expresiones de acceso a miembros (miembro) y llamadas a funciones de módulo para capturar la semántica transportada por el código remoto.
El entrenamiento de redes neuronales profundas es una tarea intensiva en recursos que requiere clústeres informáticos de alto rendimiento. Usamos el marco de entrenamiento paralelo distribuido de Horovod con el optimizador de Adam , manteniendo una copia del modelo neuronal completo en cada trabajador, procesando diferentes mini lotes del conjunto de datos de entrenamiento en paralelo. Usamos Azure Machine Learningpara el entrenamiento de modelos y el ajuste de hiperparámetros, ya que su servicio de clúster bajo demanda de GPU facilitó el escalado de nuestra capacitación según fuera necesario y también ayudó a aprovisionar y administrar clústeres de VM, programar trabajos, recopilar resultados y manejar fallas. La tabla muestra los modelos de arquitectura que probamos, así como su respectiva precisión y tamaño de modelo.

Elegimos la fabricación de Implementación Predictiva debido al tamaño del modelo más pequeño y una mejora del 20% en la precisión del modelo con respecto al modelo de producción anterior durante la evaluación del modelo fuera de línea; El tamaño del modelo es fundamental para las implementaciones de producción.
La arquitectura del modelo se muestra en la siguiente figura:

Para implementar LSTM en producción, tuvimos que mejorar la velocidad de inferencia del modelo y la huella de memoria para cumplir con los requisitos de finalización del código durante la edición. Nuestro presupuesto de memoria era de alrededor de 50 MB y necesitábamos mantener la velocidad de salida promedio por debajo de 50 milisegundos. IntelliCode LSTM se entrenó con TensorFlow y elegimos ONNX Runtime para la inferencia para obtener el mejor rendimiento. ONNX Runtime funciona con marcos de aprendizaje profundo populares y facilita la integración en una variedad de entornos de servicio al proporcionar API que abarcan varios lenguajes, incluidos Python, C, C ++, C #, Java y JavaScript; usamos API C # que son compatibles con .NET Core para integrarse en Microsoft Python Language Server .
La cuantificación es un enfoque eficaz para reducir el tamaño del modelo y mejorar el rendimiento cuando la caída en la precisión causada por la aproximación de números de dígitos bajos es aceptable. Con la cuantificación INT8 posterior al entrenamiento proporcionada por ONNX Runtime, la mejora resultante fue significativa: la huella de memoria y el tiempo de inferencia se redujeron a aproximadamente una cuarta parte de los valores cuantificados previamente en comparación con el modelo original, con una reducción aceptable del 3% en la precisión del modelo. Puede encontrar información detallada sobre el diseño de la arquitectura del modelo, el ajuste de hiperparámetros, la precisión y el rendimiento en un artículo de investigación que publicamos en la conferencia KDD 2019.
La etapa final de lanzamiento a producción fue la realización de experimentos A / B en línea comparando el nuevo modelo LSTM con el modelo de trabajo anterior. Los resultados del experimento A / B en línea de la siguiente tabla mostraron una mejora de aproximadamente un 25% en la precisión de las recomendaciones de primer nivel (precisión del primer elemento de finalización recomendado en la lista de finalización) y una mejora del 17% en el rango inverso medio (MRR), lo que nos convenció de que el nuevo modelo LSTM es significativamente mejor. el modelo anterior.

Desarrolladores de Python: ¡Pruebe los complementos de IntelliCode y envíenos sus comentarios!
Gracias a un gran esfuerzo en equipo, hemos completado la implementación por fases del primer modelo de aprendizaje profundo para todos los usuarios de IntelliCode Python en Visual Studio Code . En la última versión de la extensión IntelliCode para Visual Studio Code, también integramos el tiempo de ejecución de ONNX y LSTM para trabajar con la nueva extensión de Pylance , que está escrita completamente en TypeScript. Si eres un desarrollador de Python, instala la extensión IntelliCode y comparte tu opinión con nosotros.