Los principios de nuestro sistema
Cuando escuche términos como "automático" y "fraude", probablemente esté pensando en el aprendizaje automático, Apache Spark, Hadoop, Python, Airflow y otras tecnologías del ecosistema y la ciencia de datos de Apache Foundation. Creo que hay un aspecto del uso de estas herramientas que generalmente no se menciona: requieren ciertos requisitos previos en su sistema corporativo antes de que pueda comenzar a usarlas. En resumen, necesita una plataforma de datos empresarial que incluya un lago de datos y almacenamiento. Pero, ¿qué pasa si no tiene una plataforma de este tipo y aún necesita desarrollar esta práctica? Los siguientes principios, que analizo a continuación, nos han ayudado a llegar al punto en el que podemos concentrarnos en mejorar nuestras ideas, en lugar de encontrar una que funcione. Sin embargo, esto no es una "meseta" del proyecto.Aún quedan muchas cosas en el plan desde el punto de vista tecnológico y de producto.
Principio 1: El valor comercial es lo primero
Hemos puesto el valor empresarial en el centro de todos nuestros esfuerzos. En general, cualquier sistema de análisis automático pertenece al grupo de sistemas complejos con un alto nivel de automatización y complejidad técnica. Llevará mucho tiempo crear una solución completa si la crea desde cero. Decidimos dar prioridad al valor comercial y la integridad tecnológica en segundo lugar. En la vida real, esto significa que no aceptamos la tecnología avanzada como dogma. Elegimos la tecnología que mejor nos funciona en este momento. Con el tiempo, puede parecer que tendremos que volver a implementar algunos módulos. Este compromiso que aceptamos.
Principio 2: inteligencia aumentada
Apuesto a que la mayoría de las personas que no están profundamente involucradas en el desarrollo de soluciones de aprendizaje automático podrían pensar que reemplazar a las personas es el objetivo. De hecho, las soluciones de aprendizaje automático están lejos de ser perfectas y solo pueden reemplazarse en ciertas áreas. Abandonamos esta idea desde el principio por varias razones: datos desequilibrados sobre actividad fraudulenta y la incapacidad de proporcionar una lista exhaustiva de características para los modelos de aprendizaje automático. Por el contrario, elegimos la opción de inteligencia mejorada. Es un concepto alternativo de inteligencia artificial que se centra en el papel de apoyo de la IA, destacando el hecho de que las tecnologías cognitivas están diseñadas para mejorar la inteligencia humana, no para reemplazarla. [1]
Con esto en mente, desarrollar una solución completa de aprendizaje automático desde el principio requeriría un esfuerzo tremendo que retrasaría la creación de valor para nuestro negocio. Decidimos construir un sistema con un aspecto de aprendizaje automático en constante crecimiento bajo la guía de nuestros expertos en el dominio. La parte complicada de desarrollar un sistema de este tipo es que debe proporcionar a nuestros analistas casos no solo en términos de si es una actividad fraudulenta o no. En general, cualquier anomalía en el comportamiento del cliente es un caso sospechoso que los especialistas deben investigar y responder de alguna manera. Solo una fracción de estos casos notificados puede realmente clasificarse como fraude.
Principio 3: plataforma de inteligencia enriquecida
La parte más difícil de nuestro sistema es la verificación de un extremo a otro del flujo de trabajo del sistema. Los analistas y desarrolladores deberían poder recuperar fácilmente conjuntos de datos históricos con todas las métricas utilizadas para su análisis. Además, la plataforma de datos debería proporcionar una forma sencilla de complementar un conjunto de métricas existente con uno nuevo. Los procesos que creamos, y estos no son solo procesos de software, deberían facilitar el recalcular períodos anteriores, agregar nuevas métricas y cambiar la previsión de datos. Podríamos lograrlo acumulando todos los datos que genera nuestro sistema de producción. En este caso, los datos se convertirían gradualmente en un obstáculo. Necesitaríamos almacenar y proteger la creciente cantidad de datos que no usamos. En tal escenario, con el tiempo, los datos se volverán cada vez más irrelevantes,pero aún requieren nuestros esfuerzos para gestionarlos. Para nosotros, el acaparamiento de datos no tenía sentido y decidimos adoptar un enfoque diferente. Decidimos organizar almacenes de datos en tiempo real alrededor de las entidades objetivo que queremos clasificar, y solo almacenar datos que nos permitan verificar los períodos más recientes y actuales. El desafío de este esfuerzo es que nuestro sistema es heterogéneo con múltiples almacenes de datos y módulos de software que requieren una planificación cuidadosa para funcionar de manera consistente.que le permiten consultar los períodos más recientes y actuales. El desafío de este esfuerzo es que nuestro sistema es heterogéneo con múltiples almacenes de datos y módulos de software que requieren una planificación cuidadosa para funcionar de manera consistente.que le permiten consultar los períodos más recientes y actuales. El desafío de este esfuerzo es que nuestro sistema es heterogéneo con múltiples almacenes de datos y módulos de software que requieren una planificación cuidadosa para funcionar de manera consistente.
Conceptos constructivos de nuestro sistema
Tenemos cuatro componentes principales en nuestro sistema: sistema de ingestión, computacional, análisis de BI y sistema de seguimiento. Sirven para fines aislados específicos y los mantenemos aislados siguiendo enfoques de diseño específicos.
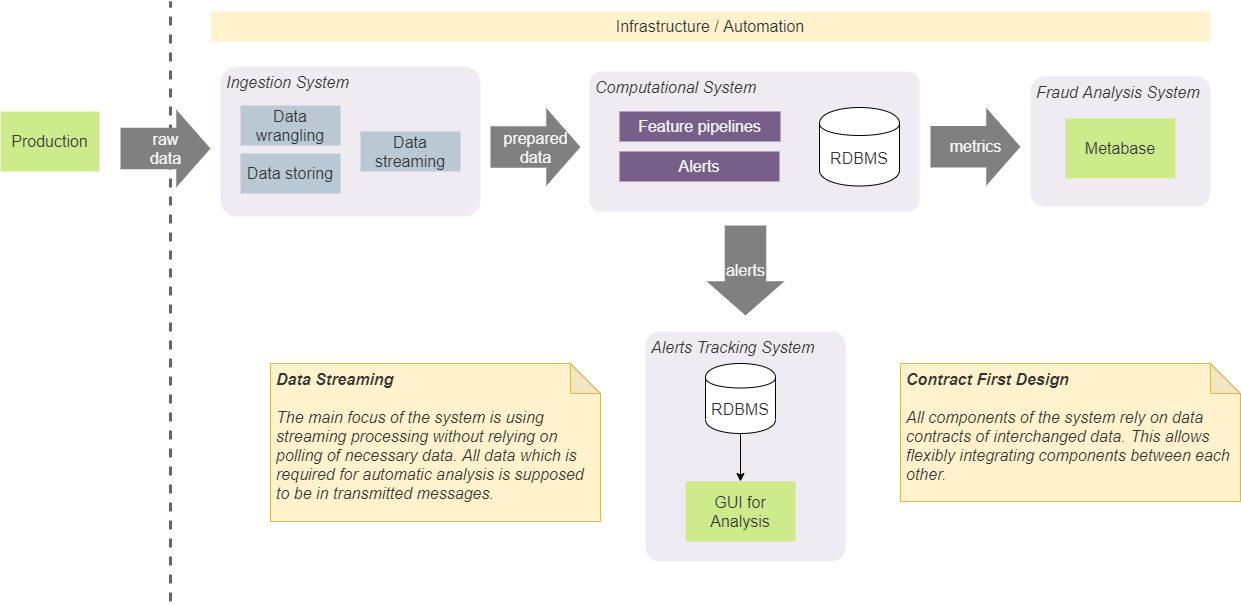
Diseño basado en contrato
En primer lugar, acordamos que los componentes solo deberían depender de ciertas estructuras de datos (contratos) que se pasan entre ellos. Esto facilita la integración entre ellos y no impone una composición (y orden) específico de componentes. Por ejemplo, en algunos casos esto nos permite integrar directamente el sistema de recepción con el sistema de seguimiento de alertas. Si es así, esto se hará de acuerdo con el contrato de notificación acordado. Esto significa que ambos componentes se integrarán mediante un contrato que puede utilizar cualquier otro componente. No agregaremos un contrato adicional para agregar alertas al sistema de seguimiento desde el sistema de entrada. Este enfoque requiere el uso de un número mínimo predeterminado de contratos y simplifica el sistema y la comunicación. De hecho,Usamos un enfoque llamado "Contract First Design" y lo aplicamos a los contratos de transmisión. [2]
El mantenimiento y la gestión del estado en el sistema conducirá inevitablemente a complicaciones en su implementación. En general, el estado debe ser accesible desde cualquier componente, debe ser consistente y proporcionar el valor más relevante para todos los componentes, y debe ser confiable con los valores correctos. Además, tener llamadas al almacenamiento persistente para obtener el último estado aumentará la cantidad de E / S y la complejidad de los algoritmos utilizados en nuestras canalizaciones en tiempo real. Debido a esto, decidimos eliminar el almacenamiento estatal lo más completamente posible de nuestro sistema. Este enfoque requiere la inclusión de todos los datos necesarios en el bloque de datos transmitidos (mensaje). Por ejemplo, si necesitamos calcular el número total de algunas observaciones (el número de operaciones o casos con determinadas características),lo calculamos en la memoria y generamos un flujo de tales valores. Los módulos dependientes utilizarán la partición y el lote para dividir el flujo en entidades y operar con los valores más recientes. Este enfoque eliminó la necesidad de tener almacenamiento en disco persistente para dichos datos. Nuestro sistema utiliza Kafka como intermediario de mensajes y se puede utilizar como base de datos con KSQL. [3] Pero usarlo vincularía fuertemente nuestra solución a Kafka, y decidimos no usarlo. El enfoque que hemos adoptado nos permite reemplazar Kafka con otro agente de mensajes sin cambios importantes en el sistema interno.Este enfoque eliminó la necesidad de tener almacenamiento en disco persistente para dichos datos. Nuestro sistema utiliza Kafka como intermediario de mensajes y se puede utilizar como base de datos con KSQL. [3] Pero usarlo vincularía fuertemente nuestra solución a Kafka, y decidimos no usarlo. El enfoque que hemos adoptado nos permite reemplazar Kafka con otro agente de mensajes sin cambios importantes en el sistema interno.Este enfoque eliminó la necesidad de tener almacenamiento en disco persistente para dichos datos. Nuestro sistema utiliza Kafka como intermediario de mensajes y se puede utilizar como base de datos con KSQL. [3] Pero usarlo vincularía fuertemente nuestra solución a Kafka, y decidimos no usarlo. El enfoque que hemos adoptado nos permite reemplazar Kafka con otro agente de mensajes sin cambios importantes en el sistema interno.
Este concepto no significa que no utilicemos almacenamiento en disco ni bases de datos. Para verificar y analizar el rendimiento del sistema, necesitamos almacenar una parte significativa de los datos en el disco, que representa varios indicadores y estados. El punto importante aquí es que los algoritmos en tiempo real son independientes de tales datos. En la mayoría de los casos, utilizamos los datos almacenados para el análisis, la depuración y el seguimiento fuera de línea de casos y resultados específicos que produce el sistema.
Los problemas de nuestro sistema
Hay ciertos problemas que hemos resuelto hasta cierto nivel, pero requieren soluciones más reflexivas. Por ahora, solo me gustaría mencionarlos aquí, porque cada punto vale un artículo separado.
- , , .
- . , .
- IF-ELSE ML. - : «ML — ». , ML, , . , , .
- .
- (true positive) . — , . , , — . , , .
- , .
- : , () .
- Por último, si bien no menos importante. Necesitamos crear una amplia plataforma de validación de rendimiento en la que podamos analizar nuestros modelos. [4]