
¿Puede una consulta que se ejecuta en paralelo usar menos CPU y ejecutarse más rápido que una consulta que se ejecuta secuencialmente?
¡Si! Para la demostración, usaré dos tablas con un tipo de columna
integer.

Nota: el script TSQL en forma de texto se encuentra al final del artículo.
Generando datos de demostración
#BuildIntInsertamos 5,000 enteros aleatorios en la
tabla (para que tenga los mismos valores que el mío, yo uso RAND con semilla y un bucle WHILE). Inserte 5,000,000 de registros en la

tabla
#Probe.

Plan secuencial
Ahora escribamos una consulta para contar el número de coincidencias de valores en estas tablas. Usamos la sugerencia MAXDOP 1 para asegurarnos de que la consulta no se ejecutará en paralelo.
Su plan de ejecución y estadísticas son los siguientes:

Esta consulta toma 891ms y usa 890ms de CPU.
Plano paralelo
Ahora ejecutemos la misma consulta con MAXDOP 2. La

consulta tarda 221 ms y utiliza 436 ms de CPU. El tiempo de ejecución se ha reducido cuatro veces y el uso de la CPU se ha reducido a la mitad.
Mapa de bits mágico
La razón por la que la ejecución de consultas en paralelo es mucho más eficiente se debe al operador Bitmap.
Echemos un vistazo de cerca al plan de ejecución real para la consulta paralela:

y compárelo con el plan secuencial:

el principio del operador de mapa de bits está bien documentado, por lo que aquí solo proporcionaré una breve descripción con enlaces a la documentación al final del artículo.
Hash Join
La combinación hash se realiza en dos pasos:
- La etapa de "construcción" (inglés - build). Se leen todas las filas de una de las tablas y se crea una tabla hash para las claves de combinación.
- La etapa de "verificación" (inglés - probe). Se leen todas las filas de la segunda tabla, el hash se calcula mediante la misma función hash utilizando las mismas claves de conexión y se encuentra un depósito coincidente en la tabla hash.
Naturalmente, debido a posibles colisiones hash, aún es necesario comparar los valores reales de las claves.
Nota del traductor: para más detalles sobre cómo hash trabajos, consulte el artículo de la visualización y Tratar con Hash Partido de Ingreso
Mapa de bits en planes secuenciales
Mucha gente no sabe que Hash Match, incluso en solicitudes secuenciales, siempre usa un mapa de bits. Pero de esta manera, no lo verá explícitamente, porque es parte de la implementación interna del operador Hash Match.
HASH JOIN en la etapa de construcción y creación de una tabla hash establece uno (o más) bits en el mapa de bits. Luego, puede usar el mapa de bits para hacer coincidir de manera eficiente los valores hash sin la sobrecarga de acceder a la tabla hash.
Con un plan secuencial, se calcula un hash para cada fila de la segunda tabla y se compara con un mapa de bits. Si se establecen los bits correspondientes en el mapa de bits, entonces puede haber una coincidencia en la tabla hash, por lo que la tabla hash se verifica a continuación. Por el contrario, si no se establece ninguno de los bits correspondientes al valor hash, podemos estar seguros de que no hay coincidencias en la tabla hash y podemos descartar inmediatamente la cadena marcada.
El costo relativamente bajo de construir un mapa de bits se compensa con el ahorro de tiempo al no verificar cadenas para las que definitivamente no hay coincidencia en la tabla hash. Esta optimización suele ser eficaz porque comprobar el mapa de bits es mucho más rápido que comprobar la tabla hash.
Mapa de bits en planes paralelos
En un plan paralelo, el mapa de bits se muestra como una declaración de mapa de bits separada.
Al pasar de la etapa de construcción a la etapa de verificación, el mapa de bits se pasa al operador HASH MATCH desde el lado de la segunda tabla (sonda). Como mínimo, el mapa de bits se pasa al lado de la sonda antes de JOIN y el operador de intercambio (paralelismo).
Aquí, el mapa de bits puede excluir cadenas que no satisfacen la condición de combinación antes de que se pasen a la declaración de intercambio.
Por supuesto, no hay declaraciones de intercambio en planes secuenciales, por lo que mover el mapa de bits fuera de HASH JOIN no proporciona ninguna ventaja adicional sobre el mapa de bits "incrustado" dentro de la declaración HASH MATCH.
En algunas situaciones (aunque solo en un plan paralelo), el optimizador puede mover el mapa de bits más abajo del plano en el lado de la sonda de la conexión.
La idea aquí es que cuanto antes se filtren las filas, se requerirá menos sobrecarga para mover datos entre declaraciones, e incluso podría ser posible eliminar algunas operaciones.
Además, el optimizador generalmente intenta colocar filtros simples lo más cerca posible de las hojas: es más eficiente filtrar las filas lo antes posible. Sin embargo, debo mencionar que el mapa de bits del que estamos hablando se agrega después de que se completa la optimización.
La decisión de agregar este tipo de mapa de bits (estático) al plan después de la optimización se basa en la selectividad esperada del filtro (por lo que las estadísticas precisas son importantes).
Mover un filtro de mapa de bits
Volvamos al concepto de mover el filtro de mapa de bits al lado de la sonda de la conexión.
En muchos casos, el filtro de mapa de bits se puede mover a una instrucción Scan o Seek. Cuando esto sucede, el predicado del plan tiene este aspecto: se

aplica a todas las filas que coinciden con el predicado de búsqueda (para Búsqueda de índice) o todas las filas para Exploración de índice o Exploración de tabla. Por ejemplo, la captura de pantalla anterior muestra un filtro de mapa de bits aplicado a la exploración de tabla para una tabla de montón.
Profundizando ...
Si un filtro de mapa de bits se construye en una sola columna o expresión de tipo integer o bigint, y se aplica a una sola columna de tipo integer o bigint, entonces el operador Bitmap puede moverse aún más adelante, incluso más allá de los operadores de búsqueda o escaneo.
El predicado seguirá apareciendo en las declaraciones Scan o Seek como en el ejemplo anterior, pero ahora estará marcado con el atributo INROW, lo que significa que el filtro se mueve al motor de almacenamiento y se aplica a las filas a medida que se leen.
Con esta optimización, las filas se filtran antes de que el Procesador de consultas vea la fila. Solo las cadenas que coinciden con HASH MATCH JOIN se envían desde el motor de almacenamiento.
Las condiciones en las que se aplica esta optimización dependen de la versión de SQL Server. Por ejemplo, en SQL Server 2005, además de las condiciones especificadas anteriormente, la columna de la sonda debe definirse como NOT NULL. Esta limitación se ha relajado en SQL Server 2008.
Es posible que se pregunte cómo afectan las optimizaciones de INROW al rendimiento. ¿Mover al operador lo más cerca posible de Buscar o Escanear será tan eficiente como filtrar en el motor de almacenamiento? Responderé a esta interesante pregunta en otros artículos. Y aquí también veremos MERGE JOIN y NESTED LOOP JOIN.
Otras opciones de JOIN
Usar bucles anidados sin índices es una mala idea. Tenemos que escanear completamente una de las tablas para cada fila de la otra tabla, un total de 5 mil millones de comparaciones. Es probable que esta solicitud lleve mucho tiempo.
Fusionar unión
Este tipo de combinación física requiere una entrada ordenada, por lo que una MERGE JOIN forzada hace que una ordenación esté presente antes. El plan secuencial se ve así:
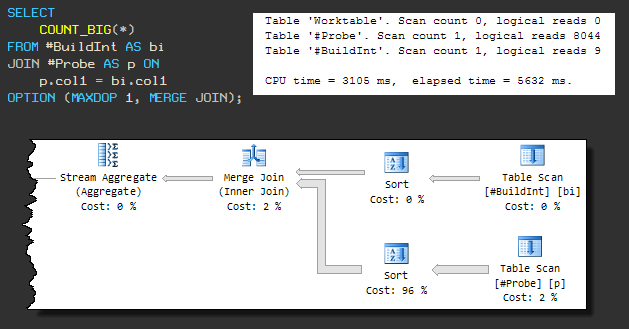
la consulta ahora usa 3105 ms de CPU y el tiempo total de ejecución es 5632 ms .
El aumento en el tiempo de ejecución general se debe al hecho de que una de las operaciones de ordenación está utilizando tempdb (aunque SQL Server tiene suficiente memoria para la ordenación).
La fuga en tempdb se produce porque el algoritmo de concesión de memoria predeterminado no reserva suficiente memoria. Hasta que no prestemos atención a esto, está claro que la solicitud no se completará en menos de 3105 ms.
Continuemos forzando el MERGE JOIN, pero permitamos el paralelismo (MAXDOP 2):

como en el HASH JOIN paralelo que vimos anteriormente, el filtro de mapa de bits está ubicado en el otro lado del MERGE JOIN más cerca del Table Scan y se aplica usando la optimización INROW.
Con 468 ms de CPU y 240 ms de tiempo transcurrido, un MERGE JOIN con ordenaciones adicionales es casi tan rápido como un HASH JOIN paralelo ( 436 ms / 221 ms ).
Pero el MERGE JOIN paralelo tiene un inconveniente: reserva 330 KB de memoria en función del número esperado de filas para ordenar. Dado que estos tipos de mapas de bits se utilizan después de la optimización de costes, no hay ningún ajuste en la estimación, aunque solo 2488 filas pasan por la clasificación inferior.
Una declaración de mapa de bits puede aparecer en un plan con MERGE JOIN solo con una declaración de bloqueo posterior (por ejemplo, Ordenar). El operador de bloqueo debe recibir todos los valores requeridos como entrada antes de generar la primera línea a la salida. Esto asegura que el mapa de bits esté completamente lleno antes de que las filas de la tabla JOIN se lean y se comparen con él.
No es necesario que la instrucción de bloqueo esté en el otro lado de MERGE JOIN, pero es importante en qué lado se usa el mapa de bits.
Con índices
Si se dispone de índices adecuados, la situación es diferente. La distribución de nuestros datos "aleatorios" es tal que
#BuildIntse puede crear un índice único en la tabla . Y la tabla #Probecontiene duplicados, por lo que debe arreglárselas con un índice no único:

este cambio no afectará a HASH JOIN (tanto en serie como en paralelo). HASH JOIN no puede usar índices, por lo que los planes y el rendimiento siguen siendo los mismos.
Fusionar unión
MERGE JOIN ya no necesita realizar una operación de unión de muchos a muchos y ya no requiere un operador de clasificación en la entrada.
La ausencia de un operador de clasificación de bloqueo significa que no se puede utilizar Bitmap.
Como resultado, vemos un plan secuencial, independientemente del parámetro MAXDOP, y el rendimiento es peor que el plan paralelo antes de agregar los índices: 702 ms de CPU y 704 ms de tiempo transcurrido:

Sin embargo, hay una mejora notable sobre el plan secuencial original MERGE JOIN ( 3105 ms / 5632 ms ). Esto se debe a la eliminación de la clasificación y al mejor rendimiento de las uniones de uno a varios.
Unión de bucles anidados
Como era de esperar, NESTED LOOP funciona significativamente mejor. Al igual que en MERGE JOIN, el optimizador decide no usar la simultaneidad:

este es el plan más eficiente hasta ahora: solo 16 ms de CPU y 16 ms de tiempo invertido.
Por supuesto, esto supone que los datos necesarios para completar la solicitud ya están en la memoria. De lo contrario, cada búsqueda en la tabla de sondas generará E / S aleatorias.
En mi computadora portátil, el rendimiento del caché en frío NESTED LOOP tomó 78 ms de CPU y 2152 ms, tiempo transcurrido. Bajo las mismas circunstancias, MERGE JOIN usó 686 ms de CPU y 1471 ms . HASH JOIN - CPU de 391 ms y905 ms .
MERGE JOIN y HASH JOIN se benefician de una gran E / S, posiblemente secuencial, mediante lectura anticipada.
Recursos adicionales
Unión Hash en paralelo (Craig Freedman)
Filtros de mapa de bits de ejecución de consultas (Equipo de procesamiento de consultas de SQL Server)
Mapas de bits en Microsoft SQL Server 2000 (artículo de MSDN)
Interpretación de planes de ejecución que contienen filtros de mapa de bits (Documentación de SQL Server)
Comprensión de las combinaciones de hash (Documentación de SQL Server)
Script de prueba
USE tempdb;
GO
CREATE TABLE #BuildInt
(
col1 INTEGER NOT NULL
);
GO
CREATE TABLE #Probe
(
col1 INTEGER NOT NULL
);
GO
-- Load 5,000 rows into the build table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #BuildInt
(col1)
VALUES
(CONVERT(INTEGER, RAND(1) * 2147483647));
WHILE @I < 5000
BEGIN
INSERT #BuildInt
(col1)
VALUES
(RAND() * 2147483647);
SET @I += 1;
END;
-- Load 5,000,000 rows into the probe table
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @I INTEGER = 1;
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND(2) * 2147483647));
BEGIN TRANSACTION;
WHILE @I < 5000000
BEGIN
INSERT #Probe
(col1)
VALUES
(CONVERT(INTEGER, RAND() * 2147483647));
SET @I += 1;
IF @I % 25 = 0
BEGIN
COMMIT TRANSACTION;
BEGIN TRANSACTION;
END;
END;
COMMIT TRANSACTION;
GO
-- Demos
SET STATISTICS XML OFF;
SET STATISTICS IO, TIME ON;
-- Serial
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1);
-- Parallel
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 2);
SET STATISTICS IO, TIME OFF;
-- Indexes
CREATE UNIQUE CLUSTERED INDEX cuq ON #BuildInt (col1);
CREATE CLUSTERED INDEX cx ON #Probe (col1);
-- Vary the query hints to explore plan shapes
SELECT
COUNT_BIG(*)
FROM #BuildInt AS bi
JOIN #Probe AS p ON
p.col1 = bi.col1
OPTION (MAXDOP 1, MERGE JOIN);
GO
DROP TABLE #BuildInt, #Probe;
Lee mas: