Mi equipo y yo representamos la dirección de desarrollo comercial con socios de Rosbank. Hoy queremos hablar de la exitosa experiencia de automatizar un proceso de negocio bancario utilizando integraciones directas entre sistemas, inteligencia artificial en términos de reconocimiento de imagen y texto basado en GreenOCR, legislación RF y preparación de muestras para entrenamiento.

Vamos a empezar. Rosbank tiene un proceso comercial para abrir una cuenta para un prestatario representado por un banco asociado. El proceso existente, siguiendo todos los requisitos reglamentarios y los requisitos del Grupo Societe Generale, antes de la automatización, tomó hasta 20 minutos de tiempo operativo por cliente. El proceso incluye recibir escaneos de documentos por parte de la oficina administrativa, verificar la exactitud de completar cada documento y publicar los campos del documento en los sistemas de información del banco, una serie de otros cheques y solo al final: abrir una cuenta. Este es exactamente el proceso detrás del botón "Abrir cuenta".
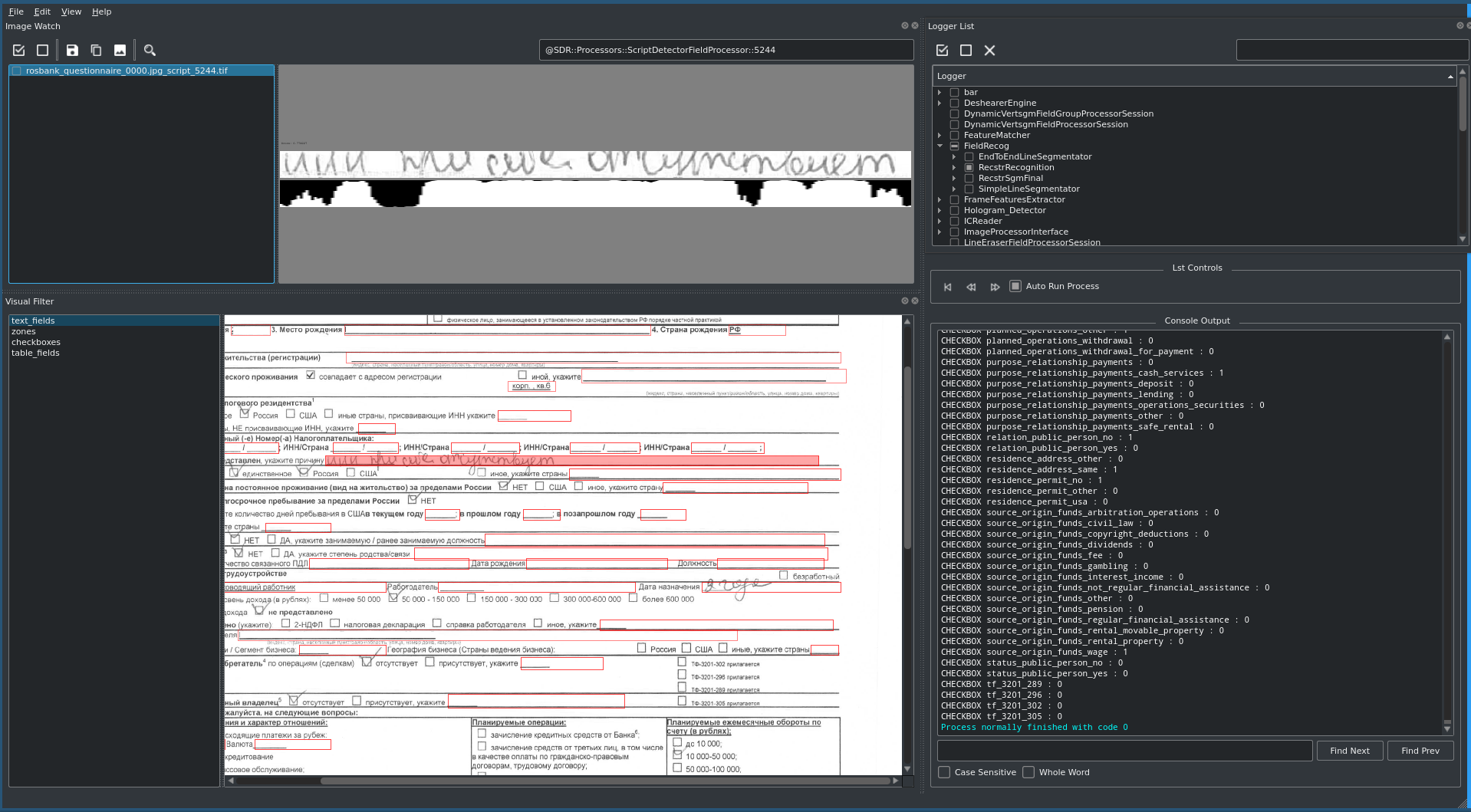
Los campos principales del documento - apellido, nombre, patronímico, fecha de nacimiento del cliente, etc. - están contenidos en casi todos los tipos de documentos recibidos y se duplican cuando se ingresan en diferentes sistemas del Banco. El documento más complejo, el cuestionario KYC (de Conozca a su cliente, conozca a su cliente), es un formato A4 imprimible con fuente de 8 puntos y contiene aproximadamente 170 campos de texto y casillas de verificación, así como vistas tabulares.
¿Qué íbamos a hacer?
Nuestro principal objetivo era reducir al mínimo el tiempo necesario para abrir una cuenta.
El análisis del proceso mostró que es necesario:
- Reducir el número de verificaciones manuales de cada documento;
- Automatizar el llenado de los mismos campos en diferentes sistemas bancarios;
- Reducir el movimiento de escaneos de documentos entre sistemas;
Para resolver los problemas (1) y (2), se decidió utilizar la solución de reconocimiento de texto e imagen basada en GreenOCR ya implementada en el banco (el nombre de trabajo es "reconocedor"). Los formatos de los documentos utilizados en el proceso empresarial no son estándar, por lo que el equipo se enfrentó a la tarea de desarrollar requisitos para el "reconocedor" y preparar ejemplos para entrenar la red neuronal (muestras).
Para resolver los problemas (2) y (3), fue necesario perfeccionar los sistemas y la integración entre sistemas.
Nuestro equipo dirigido por Julia Aleksashina
- Alexander Bashkov - desarrollo de sistemas internos (.Net)
- Valentina Sayfullina - análisis empresarial, pruebas
- Grigory Proskurin - integración entre sistemas (.Net)
- Ekaterina Panteleeva - análisis empresarial, pruebas
- Sergey Frolov - Gestión de proyectos, análisis de calidad del modelo
- Participantes de un proveedor externo ( Smart Engines en conjunto con Philosophy.it )
Entrenamiento de reconocedor
El conjunto de documentos del cliente utilizados en el proceso empresarial incluía:
- Pasaporte;
- Consentimiento - Formato A4 imprimible, 1 litro;
- Poder - formulario impreso A4, 2 l;
- Cuestionario KYC - formulario impreso A4, 1 litro;
Para empezar, se estudiaron a fondo los documentos y se desarrollaron requisitos, que incluían no solo el trabajo del reconocedor con campos dinámicos, sino también el trabajo con texto estático, campos con datos manuscritos, en general, reconocimiento de documentos a lo largo del perímetro y otras mejoras.
El reconocimiento de pasaportes se incluyó en la funcionalidad de la caja del sistema GreenOCR y no requirió modificaciones.
Para otros tipos de documentos, como resultado del análisis, se identificaron los atributos y características necesarios que el "reconocedor" debe devolver. Al mismo tiempo, hubo que tener en cuenta los siguientes puntos, que complicaron el proceso de reconocimiento y requirieron una notable complicación de los algoritmos utilizados:
- , . , «» ;
- 8- . , ;
- ( ) ;
- ;
- , , ;
- ;
Inicialmente, la tarea no nos pareció demasiado complicada y parecía bastante estándar:
Requisitos -> Proveedor -> Modelo -> Probar el modelo -> Iniciar el proceso
En caso de pruebas fallidas, el modelo se devuelve al proveedor para su reentrenamiento.
Todos los días recibimos una gran cantidad de escaneos de documentos, y preparar una muestra para entrenar un modelo no debería haber sido un problema. Todo el procesamiento de datos personales debe cumplir con los requisitos de la Ley Federal "Sobre Datos Personales" N152-FZ. El consentimiento de los clientes para el procesamiento de datos personales de los clientes está disponible solo dentro de Rosbank. No podemos transferir los documentos del cliente al proveedor para entrenar el modelo.
Se consideraron tres formas de resolver el problema:
- , , , , ;
- . , – () , ;
- () . , , , , , ;
Habiendo analizado las opciones propuestas con el equipo, en cuanto a la rapidez de su implementación y los posibles riesgos, optamos por la tercera opción, la forma de imitar documentos para entrenar el modelo. La principal ventaja de este proceso es la capacidad de cubrir la gama más amplia posible de dispositivos de escaneo para reducir el número de iteraciones para la calibración y el refinamiento del modelo.
Las plantillas de documentos se implementaron en formato html. Se preparó una matriz de datos de prueba y una macro de manera rápida y eficiente, llenando plantillas con datos sintetizados y automatizando la impresión. A continuación, generamos formularios imprimibles en formato pdf y asignamos un identificador único a cada archivo para verificar las respuestas recibidas del "decodificador".
El entrenamiento de la red neuronal, el marcado de áreas y la personalización de los formularios se llevó a cabo por parte del proveedor.
Debido al marco de tiempo limitado, el entrenamiento del modelo se dividió en 2 etapas.
En la primera etapa, el modelo fue entrenado para reconocer tipos de documentos y reconocimiento "aproximado" del contenido de los propios documentos:
Requisitos -> Proveedor -> Preparación de datos de prueba -> Recopilación de datos -> Entrenamiento del modelo en reconocimiento de formularios -> Formularios de prueba -> Configuración del modelo
En la segunda etapa Se realizó un entrenamiento detallado del modelo para reconocer el contenido de cada tipo de documentos. La formación e implementación del modelo en la segunda etapa se puede describir mediante el siguiente esquema, que es el mismo para todos los tipos de documentos:
Preparar datos de prueba en diferentes resoluciones -> Recopilar y transmitir datos al proveedor -> Entrenamiento del modelo -> Probar el modelo -> Calibrar el modelo -> Implementar el modelo -> Verificar los resultados en batalla -> Identificar casos de problemas -> Simular casos de problemas y transferirlos al proveedor -> Repetición de los pasos de la prueba
Cabe señalar que, a pesar de la amplia cobertura de la gama de escáneres utilizados, todavía no se presentaban varios dispositivos en los ejemplos para entrenar el modelo. Por lo tanto, la introducción del modelo en batalla se llevó a cabo en modo piloto y los resultados no se utilizaron para la automatización. Los datos obtenidos durante el trabajo en el modo piloto solo se registraron en la base de datos para su posterior análisis y análisis.
Pruebas
Dado que el ciclo de capacitación del modelo estaba del lado del proveedor y no estaba conectado con los sistemas del banco, después de cada ciclo de capacitación, el proveedor transfirió el modelo al banco, donde se probó en un entorno de prueba. En caso de verificación exitosa, el modelo se transfirió al ambiente de certificación, donde se hizo la prueba de regresión, y luego al ambiente industrial, para identificar casos especiales que no fueron tomados en cuenta al entrenar el modelo.
En el perímetro del banco, los datos se enviaron al modelo, los resultados se registraron en la base de datos. El análisis de la calidad de los datos se llevó a cabo utilizando el todopoderoso Excel, utilizando tablas dinámicas, lógica con fórmulas y sus combinaciones vlookup, hlookup, index, len, match y comparación de cadenas de caracteres a través de la función if.
Las pruebas con documentos simulados nos permitieron ejecutar el número máximo de escenarios de prueba y automatizar el proceso tanto como fuera posible.
Primero, en modo manual, verificamos la devolución de todos los campos para verificar el cumplimiento de los requisitos originales para cada tipo de documento. A continuación, verificamos las respuestas del modelo al llenar dinámicamente bloques de texto de diferentes longitudes. El objetivo era probar la calidad de las respuestas cuando el texto pasa de una línea a otra y de una página a otra. Al final, la calidad de las respuestas se verificó por campos en función de la calidad del documento escaneado. Para la calibración de la más alta calidad del modelo, se utilizaron escaneos de documentos de baja resolución.
Se debería haber prestado especial atención al documento más complejo que contiene la mayor cantidad de campos y casillas de verificación: el cuestionario KYC. Para él, se prepararon con anticipación scripts especiales para completar el documento y se escribieron macros automatizadas, lo que permitió acelerar el proceso de prueba, verificar todas las combinaciones de datos posibles y brindar retroalimentación de inmediato al proveedor para calibrar el modelo.
Integración y desarrollo interno
La revisión necesaria de los sistemas del banco y la integración entre sistemas se realizaron con anticipación y se mostraron en los entornos de prueba del banco.
El escenario realizado consta de las siguientes etapas:
- Aceptación de escaneos entrantes de documentos;
- Envío de escaneos recibidos al "reconocedor". El envío es posible en modo síncrono y asíncrono con hasta 10 hilos;
- Recibir una respuesta del "reconocedor", comprobar y validar los datos recibidos;
- Guardar el escaneo original del documento en la biblioteca electrónica del banco;
- Iniciación en los sistemas del banco para procesar los datos recibidos del "reconocedor" y posterior verificación por parte del empleado;
Salir
Por el momento, se ha completado la capacitación del modelo, se han realizado exitosas pruebas e implementación del proceso de negocio en el entorno de producción del banco. La automatización realizada permitió reducir el tiempo promedio para abrir una cuenta de 20 minutos a 5 minutos. Se ha automatizado la laboriosa etapa del proceso empresarial de reconocimiento y entrada de datos del documento, que anteriormente se realizaba de forma manual. Al mismo tiempo, la probabilidad de errores causados por el factor humano se reduce drásticamente. Además, se garantiza la identidad de los datos extraídos de un mismo documento en diferentes sistemas del banco.