aprendizaje automático. Redes neuronales (parte 1): El proceso de aprendizaje del perceptrón
En este artículo usaremos una red neuronal para modelar la ejecución de operaciones lógicas OR; XOR, que es una especie de aplicación "Hello World" para redes neuronales.
El artículo describirá paso a paso el proceso de dicho modelado con TensorFlow.js.
Así que construyamos una red neuronal para la operación lógica OR. En la entrada, siempre enviaremos dos señales X 1 y X 2 , y en la salida recibiremos una señal de salida Y. Para entrenar la red neuronal, también necesitamos un conjunto de datos de entrenamiento (Figura 1).

Figura 1 - Un conjunto de datos de entrenamiento y un modelo para modelar una operación OR lógica
Para entender qué estructura de una red neuronal establecer, imaginemos un conjunto de datos de entrenamiento en un plano de coordenadas con los ejes X 1 y X 2 (Figura 2, izquierda).
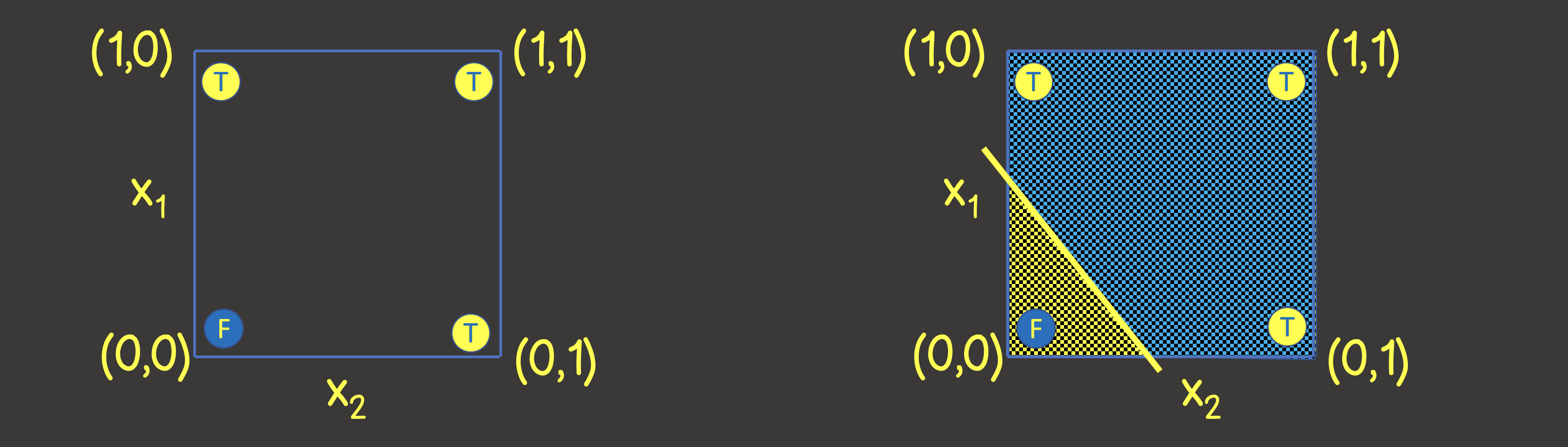
Figura 2 - Conjunto de entrenamiento en el plano de coordenadas para operación lógica OR
Tenga en cuenta que para resolver este problema, es suficiente para nosotros dibujar una línea que dividiría el plano de tal manera que en un lado de la línea hay todos los valores VERDADEROS , y en el otro, todos los valores FALSOS (Figura 2, derecha). También sabemos que una neurona en una red neuronal (perceptrón) puede hacer frente perfectamente a este propósito, cuyo valor de salida se calcula a partir de las señales de entrada como:
que es una representación matemática de la ecuación de la línea.
En vista de que nuestros valores están en el rango de 0 a 1, también aplicamos la función de activación sigmoidea. Por lo tanto, nuestra red neuronal se ve como en la Figura 3.

Figura 3 - Red neuronal para entrenar la operación lógica OR
. Resolvamos este problema con TensorFlow.js.
Primero, necesitamos convertir el conjunto de datos de entrenamiento a tensores. Un tensor es un contenedor de datos que puede tenerejes y un número arbitrario de elementos a lo largo de cada uno de los ejes. La mayoría de los tensores están familiarizados con las matemáticas: vectores (tensor con un eje), matrices (tensor con dos ejes: filas, columnas).
Para definir el conjunto de datos de entrenamiento, el primer eje (eje 0) es siempre el eje a lo largo del cual se ubican todas las instancias de muestra de datos disponibles (Figura 4).
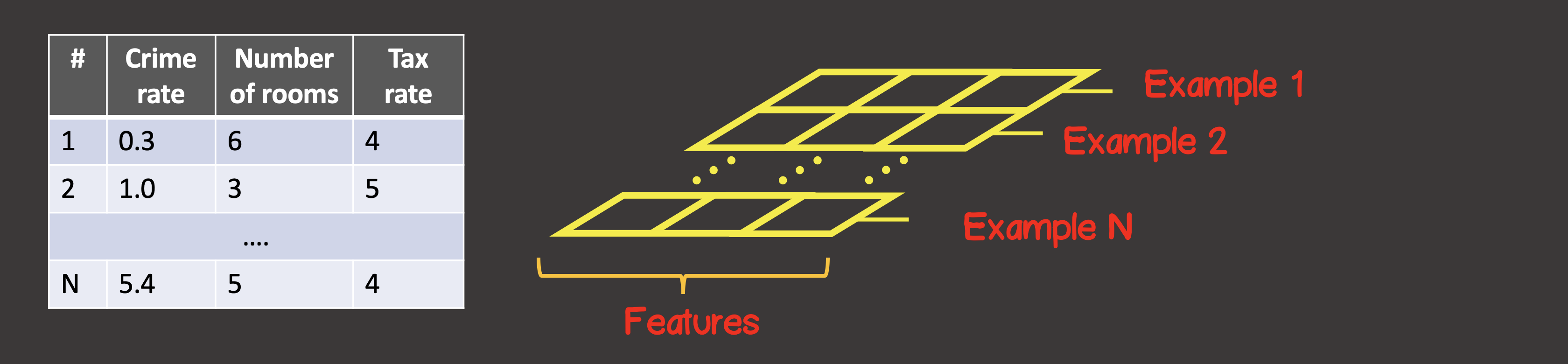
Figura 4 - Estructura del tensor
En nuestro caso particular, tenemos 4 instancias de muestras de datos (Figura 1), lo que significa que el tensor de entrada a lo largo del primer eje tendrá 4 elementos. Cada elemento de la muestra de entrenamiento es un vector que consta de dos elementos X 1 , X 2 . Por lo tanto, el tensor de entrada tiene 2 ejes (matriz), a lo largo del primer eje hay 4 elementos, a lo largo del segundo eje - 2 elementos.
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
Asimismo, convierta la salida en un tensor. En cuanto a las señales de entrada, a lo largo del primer eje tenemos 4 elementos, y cada elemento contiene un vector que contiene un valor:
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
Creemos un modelo usando la API de TensorFlow:
const model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 1, activation: 'sigmoid' })
);
La creación del modelo siempre comenzará con una llamada a tf.sequential () . El componente principal de un modelo son las capas. Podemos conectarnos al modelo tantas capas de la red neuronal como necesitemos. Aquí estamos usando una capa densa , lo que significa que cada neurona en la siguiente capa tiene una conexión con cada neurona en la capa anterior. Por ejemplo, si tenemos dos capas densas, en la primera capa neuronas, y en el segundo - , entonces el número total de conexiones entre capas será ...
En nuestro caso, como podemos ver, la red neuronal consta de una capa, en la que hay una neurona, por lo que las unidades se establecen en una.
Además, para la primera capa de la red neuronal, debemos establecer inputShape , ya que cada instancia de entrada está representada por un vector de dos valores X 1 y X 2 , por lo que inputShape = [2] . Tenga en cuenta que no es necesario establecer inputShape para las capas intermedias; TensorFlow puede determinar este valor a partir del valor de las unidades de la capa anterior.
Además, si es necesario, a cada capa se le puede asignar una función de activación, determinamos anteriormente que esta será una función sigmoidea. Las funciones de activación disponibles actualmente en TensorFlow se pueden encontrar aquí .
A continuación, necesitamos compilar el modelo (ver API aquí ), mientras que necesitamos establecer dos parámetros obligatorios: esta es la función de error y el tipo de optimizador que buscará su mínimo:
model.compile({
optimizer: tf.train.sgd(0.1),
loss: 'meanSquaredError'
});
Establecimos un descenso de gradiente estocástico con un paso de entrenamiento de 0.1 como optimizador.
La lista de optimizadores implementados en la biblioteca: tf.train.sgd , tf.train.momentum , tf.train.adagrad , tf.train.adadelta , tf.train.adam , tf.train.adamax , tf.train.rmsprop .
En la práctica, de forma predeterminada, puede seleccionar inmediatamente el optimizador adam , que tiene las mejores tasas de convergencia del modelo, en contraste con sgd : la tasa de aprendizaje en cada etapa del entrenamiento se establece en función del historial de los pasos anteriores y no es constante durante todo el proceso de aprendizaje.
Como función de error, viene dada por la función de error cuadrático medio:
El modelo está configurado, y el siguiente paso es el proceso de entrenamiento del modelo, para esto se debe llamar al método de ajuste en el modelo :
async function initModel() {
// skip for brevity
await model.fit(trainingInputTensor, trainingOutputTensor, {
epochs: 1000,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
// any actions on during any epoch of training
await tf.nextFrame();
}
}
})
}
Hemos establecido que el proceso de aprendizaje debe constar de 100 pasos de aprendizaje (número de épocas de aprendizaje); también en cada época sucesiva, los datos de entrada deben barajarse en orden aleatorio ( shuffle = true ), lo que acelerará el proceso de convergencia del modelo, ya que hay pocos casos en nuestro conjunto de datos de entrenamiento (4).
Una vez finalizado el proceso de entrenamiento, podemos utilizar el método de predicción , que, basándose en nuevas señales de entrada, calculará el valor de salida.
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
const output = model.predict(testInputTensor).arraySync();
El método generateInputs simplemente genera un conjunto de datos de muestra de 10x10 que divide el plano de coordenadas en 100 cuadrados:
El código completo se da aquí
import React, { useEffect, useState } from 'react';
import LossPlot from './components/LossPlot';
import Canvas from './components/Canvas';
import * as tf from "@tensorflow/tfjs";
let model;
export default () => {
const [data, changeData] = useState([]);
const [lossHistory, changeLossHistory] = useState([]);
useEffect(() => {
async function initModel() {
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [1]]
const outputTensor = tf.tensor(output, [output.length, 1]);
const testInput = generateInputs(10);
const testInputTensor = tf.tensor(testInput, [testInput.length, 2]);
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape:[2], units:1, activation: 'sigmoid'})
);
model.compile({
optimizer: tf.train.adam(0.1),
loss: 'meanSquaredError'
});
await model.fit(inputTensor, outputTensor, {
epochs: 100,
shuffle: true,
callbacks: {
onEpochEnd: async (epoch, { loss }) => {
changeLossHistory((prevHistory) => [...prevHistory, {
epoch,
loss
}]);
const output = model.predict(testInputTensor)
.arraySync();
changeData(() => output.map(([out], i) => ({
out,
x1: testInput[i][0],
x2: testInput[i][1]
})));
await tf.nextFrame();
}
}
})
}
initModel();
}, []);
return (
<div>
<Canvas data={data} squareAmount={10}/>
<LossPlot loss={lossHistory}/>
</div>
);
}
function generateInputs(squareAmount) {
const step = 1 / squareAmount;
const input = [];
for (let i = 0; i < 1; i += step) {
for (let j = 0; j < 1; j += step) {
input.push([i, j]);
}
}
return input;
}
En la siguiente figura, verá parte del proceso de aprendizaje:

Implementación Planker:
Simulación de la operación lógica XOR El
conjunto de entrenamiento para esta función se muestra en la Figura 6, y también organizaremos estos puntos como lo hicimos para la operación lógica O en el plano de coordenadas
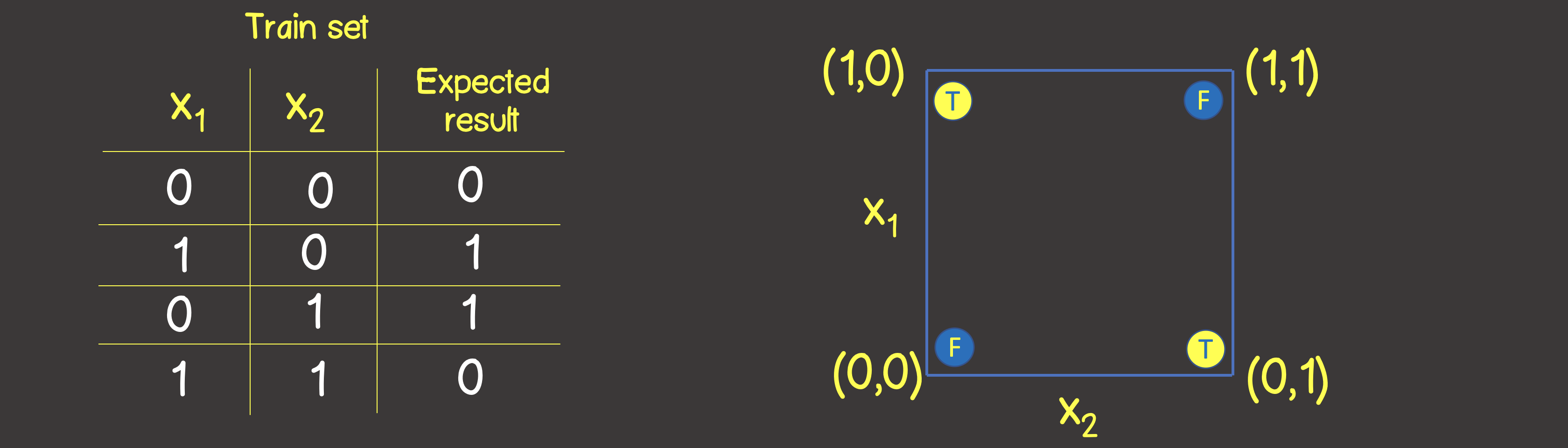
Figura 6 - Conjunto de datos de entrenamiento y modelo para modelar la operación lógica O EXCLUSIVO (XOR)
Tenga en cuenta que a diferencia de la operación lógica OR, no se puede dividir el plano con una línea recta, por lo que en un lado hay todos los valores VERDADEROS y en el otro lado todos son FALSOS . Sin embargo, podemos hacer esto usando dos curvas (Figura 7).
Obviamente, en este caso, una neurona en una capa no es suficiente; se necesita al menos una capa adicional con dos neuronas, cada una de las cuales definiría una de las dos líneas en el plano.
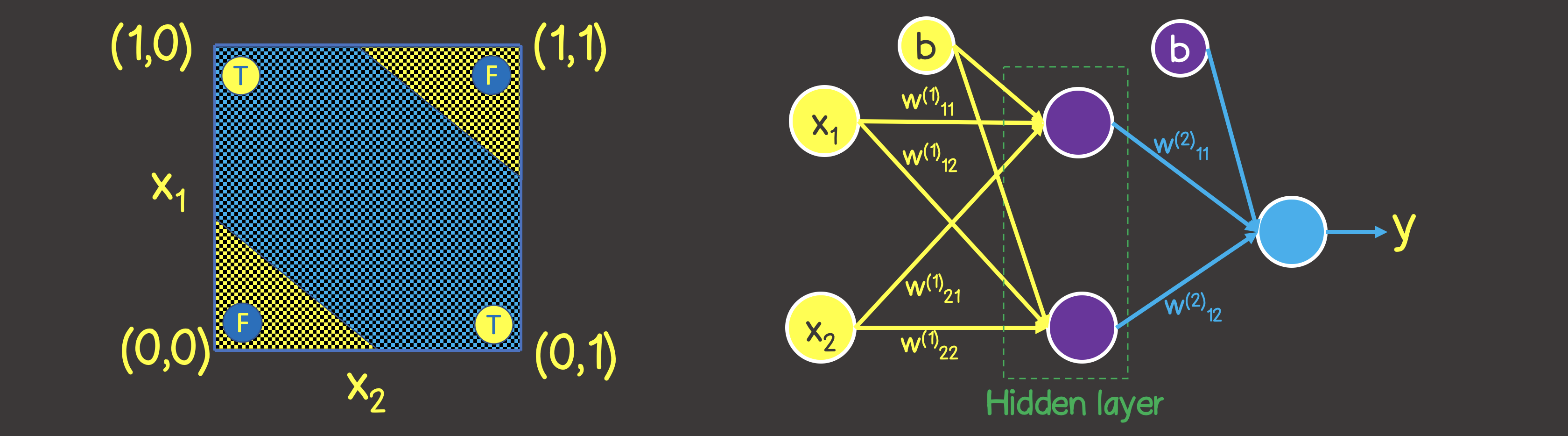
Figura 7 - Un modelo de red neuronal para la operación lógica EXCLUSIVE OR (XOR)
En el código anterior, necesitamos realizar cambios en varios lugares, uno de los cuales es el propio conjunto de datos de entrenamiento:
const input = [[0, 0], [1, 0], [0, 1], [1, 1]];
const inputTensor = tf.tensor(input, [input.length, 2]);
const output = [[0], [1], [1], [0]]
const outputTensor = tf.tensor(output, [output.length, 1]);
El segundo lugar es la estructura modificada del modelo, según la Figura 7:
model = tf.sequential();
model.add(
tf.layers.dense({ inputShape: [2], units: 2, activation: 'sigmoid' })
);
model.add(
tf.layers.dense({ units: 1, activation: 'sigmoid' })
);
El proceso de aprendizaje en este caso se ve así:

Implementación Planker:
Tema del próximo artículo
En el próximo artículo describiremos cómo resolver problemas relacionados con la clasificación de objetos en categorías, basándose en una lista de algunas características.